用TF2.0 复现经典推荐系统论文
Posted 程序员遇见GitHub
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用TF2.0 复现经典推荐系统论文相关的知识,希望对你有一定的参考价值。
这是阿三的第 211 期分享
作者 | 阿三
首发 | 程序员遇见GitHub
大家好,我是阿三,今天给大家带来的是一个用TF2.0重新实现一些推荐系统经典论文的仓库。
一. 推荐系统
TensorFlow和Keras都是在4年前发布的(Keras为2015年3月,TensorFlow为2015年11月)。在深度学习时代这是很长的时间!
在过去,TensorFlow 1.x + Keras存在许多已知问题:
使用TensorFlow意味着要处理静态计算图,对于习惯于命令式编码的程序员而言,这将感到尴尬且困难。
虽然TensorFlow API非常强大和灵活,但它缺乏完善性,常常令人困惑或难以使用。
尽管Keras的生产率很高且易于使用,但对于研究用例通常缺乏灵活性。
TensorFlow 2.0建立在以下关键思想之上:
让用户像在Numpy中一样急切地运行他们的计算。这使TensorFlow 2.0编程变得直观而Pythonic。
保留已编译图形的显着优势(用于性能,分布和部署)。这使TensorFlow快速,可扩展且可投入生产。
利用Keras作为其高级深度学习API,使TensorFlow易于上手且高效。
将Keras扩展到从非常高级(更易于使用,不太灵活)到非常低级(需要更多专业知识,但提供了极大灵活性)的工作流范围。
TF 2.0 的发布也会让大家重新开始使用TF,今天的这个仓库,作者利用TF2.0重新去复现了很多推荐系统的经典论文,包括如下论文:
既包括传统方法的论文
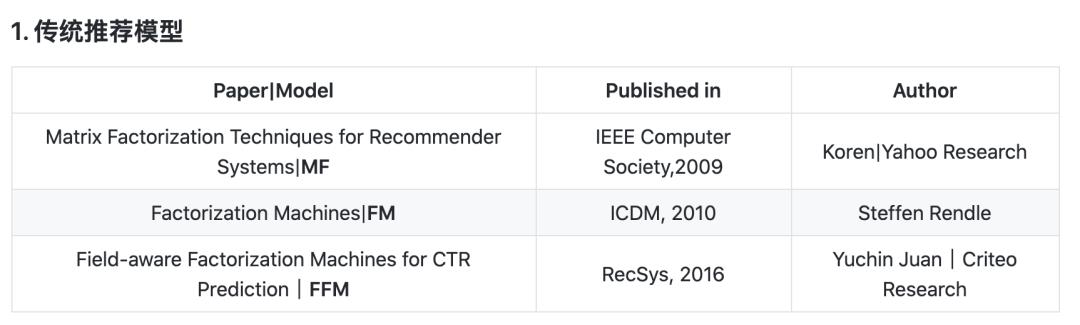
也包含使用深度学习和神经网络的文章:
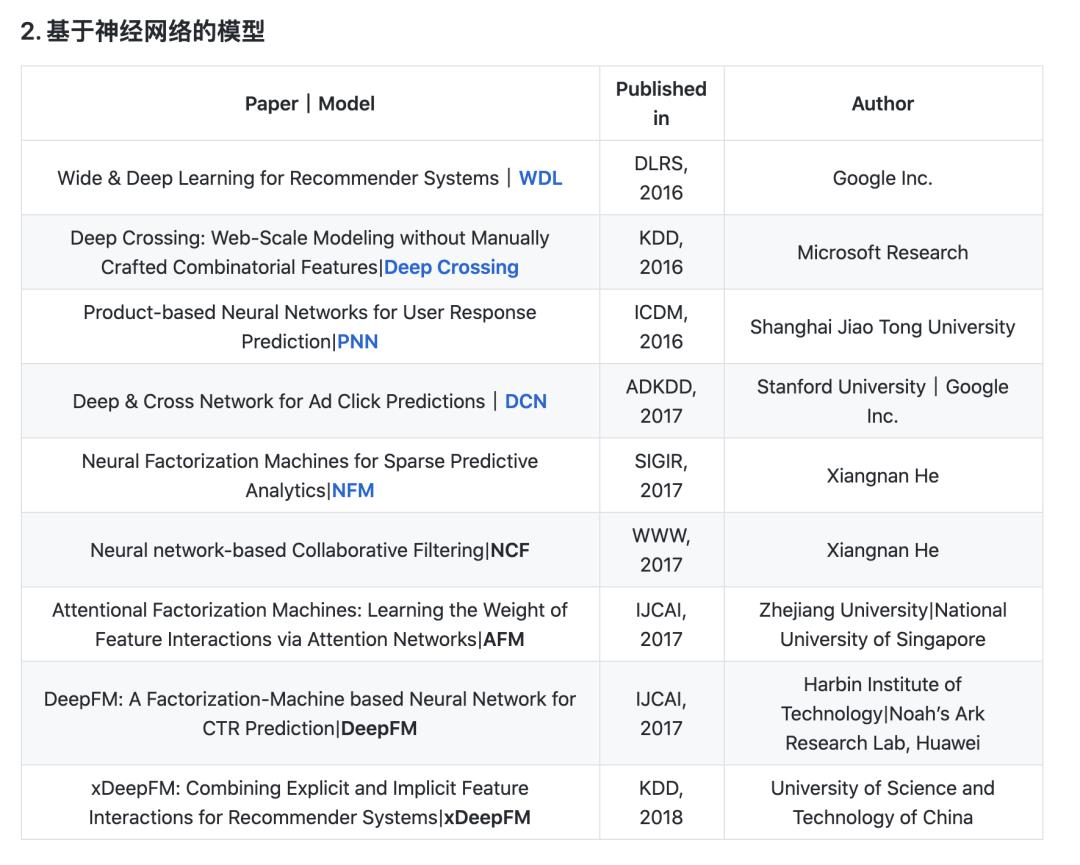
还有使用序列模型的论文:
https://github.com/ZiyaoGeng/Recommender-System-with-TF2.0
二 希望和大家有互动
本轮打卡于9月23日结束,阿三在这里感谢大家的参与,打卡满30天的同学请后台联系阿三领取红包,一共5个名额,先到先得。如果已经联系过阿三,但是阿三并没有回复的同学请再联系阿三一次。感谢大家的支持!
推荐阅读:
以上是关于用TF2.0 复现经典推荐系统论文的主要内容,如果未能解决你的问题,请参考以下文章
数十篇推荐系统论文被批无法复现:源码数据集均缺失,性能难达预期