大咖聊技术 | 推荐系统番外篇
Posted 百威亚太数据科学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大咖聊技术 | 推荐系统番外篇相关的知识,希望对你有一定的参考价值。
在中,Ting-hao Chen为大家介绍了推荐算法的一些理论,本期文章笔者会结合之前文章的两点稍作展开,分别探讨一下,
推荐过程中爆款商品的影响
推荐结果的后续处理及应用
推荐过程中爆款商品的影响
基于爆款的探讨笔者会以Item-Based Collaborate Filtering(基于商品的协同过滤)为例展开,是因为相对User-Based CF,Item-Based CF更加广泛的应用于商业场景中,原因有二,
No.1
一是基于商品的推荐会计算物品相似度,而物品相似度相对于用户相似度,更容易让用户产生共鸣,从某种程度上也是因为购物篮法则的广泛应用,在很长时间内对互联网用户产生了很好的education。
No.2
二是从工程实现角度来看,CF方法都需要维护一张相似度表,Item-Based CF 需要维护物品相似度表,User-Based CF则需要维护用户相似度表,而大部分成熟的商业场景中,用户数都是要在数量级上远大于商品数的,试想假如一个平台有1000w用户,需要一张表存储每两个用户之间的相似度得分,就需要超大的存储空间,在实际使用计算的时候更是需要超大的capacity。
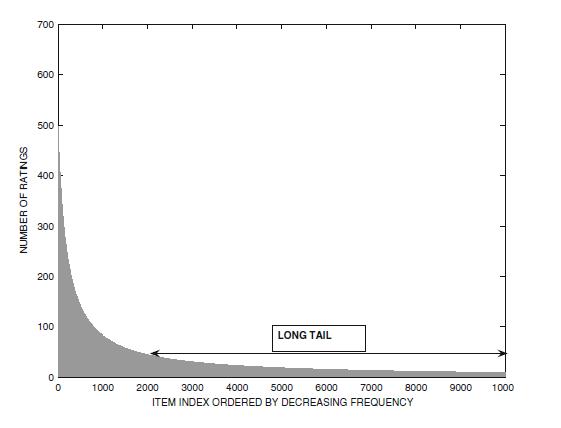
一般来说,一个平台上商品的销量,订单数,访问数等各个统计维度的分布都会符合类指数分布,如下图展示的是某视频网站各个视频打分量的分布。头部的商品称之为爆款商品,而尾部的商品则称之为长尾商品。
Item-Base CF首先要计算商品相似度,以下公式使用计算了两个商品i和j之间的余弦相似度,也是CF方法中最常见的计算物品相似度的方法,其中Ui代表购买过商品i的用户集,sui代表用户u对商品i的喜好度。
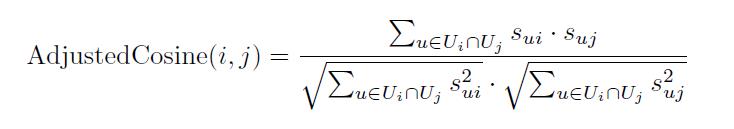
因为两个商品之间余弦相似度的计算是基于和各自发生交互的用户集的交集计算的,设想爆款商品的用户集必然很大,因此不管是爆款商品和爆款商品之间,还是爆款商品和长尾商品之间,相似度都会偏大,但是这些偏大的相似性并不能真实代表现实中的相似度。
在计算完物品相似度矩阵之后,Item-based CF 下一步就是根据一个用户已经购买过的商品,结合物品相似度矩阵,生成针对该用户的推荐列表,具体公式如下,
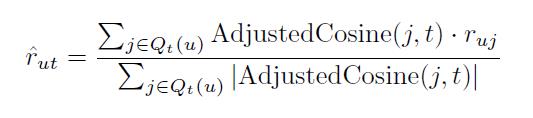
其中ˆrut代表推测的用户u对商品t的喜好度,AdjustedCosine(j,t)代表商品j和t之间的余弦相似度,Qt代表该用户购买过的商品集。设想如果未对爆款商品做任何惩罚处理,首先爆款相对物品t的AdjustedCosine项会保持偏大,其次Qt物品集中爆款商品数量会保持偏大,因此会导致最后用户对爆款商品的喜好度普遍偏大。
最普遍的对爆款商品进行惩罚的方法,就是在计算物品相似度的时候加入惩罚项,惩罚项的定义根据需求和场景多种多样,最容易理解的比如取商品流行度的倒数,乘以原本用户对该商品的喜好度,作为惩罚后的喜好度,即算法认为,如果一个用户和一个爆款商品以及一个长尾商品同时产生了同样程度的互动,那么该用户对于长尾物品的喜好要远大于对于爆款商品的喜好。
“推爆款”在推荐系统中是非常常见的现象,因为推荐爆款商品总是能带来比较稳定的点击量,是很多平台上线初期或者在整体算法不完善的情况下,用来增强用户粘性或者解决冷启动问题的首选方法,即便在平台成熟期,往往也会在推荐系统中为用户保留推爆款的模块。但是一个推荐系统长期的稳定性以及成长性,更多的会取决于整体推荐的diversity(多样性)以及novelty(创新性),因为这两点一方面可以帮助用户接触到自己熟悉领域之外的商品,其次会有几率推荐出更加贴合用户独特喜好的商品。
推荐结果的后续处理及应用
当我们对一版算法的结果做评估的时候,如果是回归问题,一般会使用MSE或者RMSE等类似指标,在推荐场景里就类似推荐结果返回了预测的用户对商品的喜好度(rating),我们用预测的rating和真实的rating来计算MSE或RMSE用以评估算法。如果是分类问题,在推荐算法里就类似算法并没有返回rating,而是直接返回了top-K的推荐结果,那么我们一般会根据返回的推荐结果和封闭测试集中用户真实的购买结果做recall来评估算法。
上述的评估方式在推荐算法的场景里会有一点局限性,因为设想平台在真正为用户做推荐的时候,界面上的推荐点位是有限的,即使假设推荐点位很长,用户也大概率只关注浏览头部几个推荐结果,所以在用户的角度看,只有排名靠前的推荐结果是有效的,而排名靠后的推荐结果不管是在应用层还是在算法层,跟用户都关系不大。
结合上一段,回顾我们一开始讨论的一般算法的评估方式,就会发现一个问题,一般的评估方法,并不会区分计算头部和尾部的结果,而是把整体放在一起计算一个指标来评估算法的表现。因此在评估推荐算法的结果的时候,我们就需要引入一个推荐位置的概念。
下面为大家介绍Normalized Discounted Cumulative Gain (NDCG),
累积增益CG,推荐系统中CG表示将每个推荐结果相关性的分值累加后作为整个推荐列表的得分
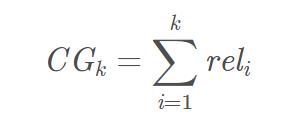
其中,reli表示位置i的推荐结果的相关性,k表示推荐列表的大小。
CG没有考虑每个推荐结果处于不同位置对整个推荐结果的影响,例如,我们总是希望相关性大大的结果排在前面,相关性低的排在前面会影响用户体验。
DCG在CG的基础上引入了位置影响因素,计算公式如下:
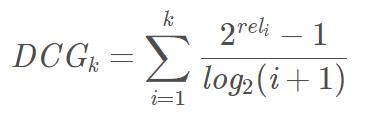
从上面的式子可以得出:
1)推荐结果的相关性越大,DCG越大。
2)相关性好的排在推荐列表前面的话,推荐效果越好,DCG越大。
DCG针对不同的推荐列表之间很难进行横向评估,而我们评估一个推荐系统不可能仅使用一个用户的推荐列表及相应结果进行评估,而是对整个测试集中的用户及其推荐列表结果进行评估。那么,不同用户的推荐列表的评估分数就需要进行归一化,也就是NDCG。
IDCG表示推荐系统某一用户返回的最好推荐结果列表,即假设返回结果按照相关性排序, 最相关的结果放在最前面,此序列的DCG为IDCG。因此DCG的值介于 (0,IDCG],故NDCG的值介于(0,1],那么用户u的NDCG@K定义为:
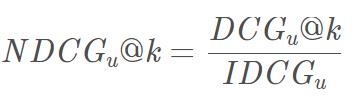
整体平均的NDCG就是:
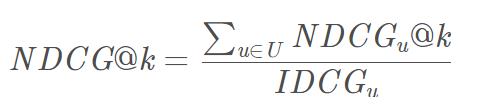
除了使用NDCG对评估指标进行修正之外,还有同属List-Wise ranking的Mean Reciprocal Ranking (MRR),以及其他多种Pair-Wise ranking的方法。目的都是相同的,就是在衡量算法表现的时候,引入推荐位置的考量,从而让最后输出的结果更贴近用户使用时的真实需求。
Reference
M. Weimer, A. Karatzoglou, Q. Le, and A. Smola. CoFiRank: Maximum margin matrix factorization for collaborative ranking. Advances in Neural Information Processing Systems, 2007.
M. Weimer, A. Karatzoglou, and A. Smola. Improving maximum margin matrix factorization. Machine Learning, 72(3), pp. 263–276, 2008.
F. Ricci, L. Rokach, B. Shapira, and P. Kantor. Recommender systems handbook. Springer, New York, 2011.
- END -
本期员工大咖
Mr. Ruofei Li
Master, Industrial and Systems Engineering, State University of New York at Binghamton
Bachelor, Electrical Engineering and Automation, Northwestern Polytechnical University
以上是关于大咖聊技术 | 推荐系统番外篇的主要内容,如果未能解决你的问题,请参考以下文章