最新综述:推荐系统的Bias问题和Debias方法 Posted 2021-05-01 PaperWeekly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新综述:推荐系统的Bias问题和Debias方法相关的知识,希望对你有一定的参考价值。
©PaperWeekly 原创 · 作者|陈佳伟
学校|中国科学技术大学博士后
研究方向|信息检索
bias 是推荐系统中普遍存在的问题,受到广大研究者和从业者的关注。本文将分享何向南老师团队最近的一篇关于推荐系统 bias 的综述文章 Bias and Debias in Recommender System: A Survey and Future Directions
论文标题:
Bias and Debias in Recommender System: A Survey and Future Directions
论文链接:
https://arxiv.org/abs/2010.03240
陈佳伟(中国科学技术大学)、董汉德(中国科学技术大学)、王翔(新加坡国立大学)、冯福利(新加坡国立大学)、汪萌(合肥工业大学)、何向南(中国科学技术大学)
在当今信息过载的时代,推荐系统对于用户越来越有用,如何构建更加有效的推荐系统、解决目前推荐系统中存在的问题具有重要意义。然而不像其他领域的任务,在推荐任务中盲目的构造模型拟合用户的历史数据往往难以取得良好的性能。
这是因为推荐系统中的 bias 广泛存在,其一,推荐数据是观测得到的而非实验干预得到的。交互数据受到曝光机理和用户选择的影响。其二,推荐数据呈现出长尾的特征。其三,推荐系统生态存在反馈闭环。推荐系统的结果会影响用户的交互行为,然而用户的行为又作为新的数据来训练推荐系统模型,从而产品并加强数据的 bias。
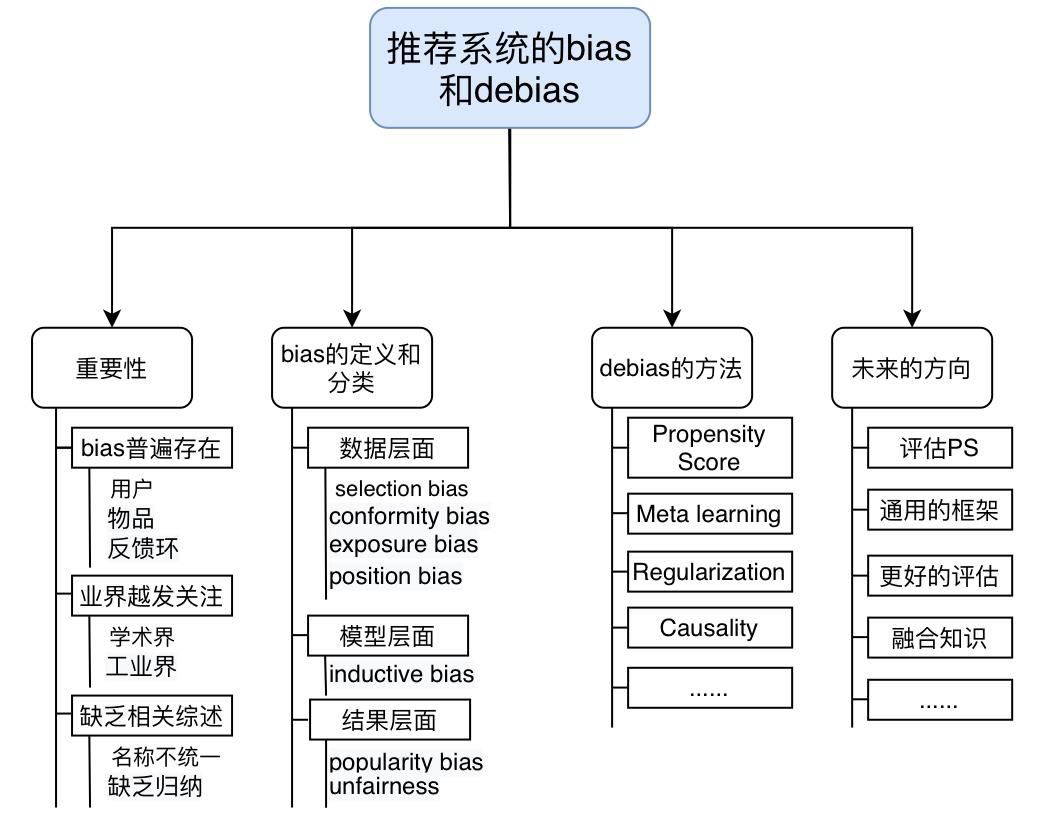
近些年,学术界越来越关注推荐系统中 bias 和 debias 的研究。图 1 展示了近些年顶刊和顶会关于推荐系统 bias 论文数量的变化趋势,我们可以发现,自从 2015 年之后,相关研究迅速增长。然而虽然推荐系统的bias领域蓬勃发展,但是目前的研究呈现出碎片化、定义不一致等现象。
为了方便后续研究和感兴趣的读者快速了解现有技术,该综述对现有技术归纳总结并给出一些未来的研究方向。
▲ 图1: 2006年以后研究推荐系统的bias的论文数量变化趋势
Bias的定义和分类
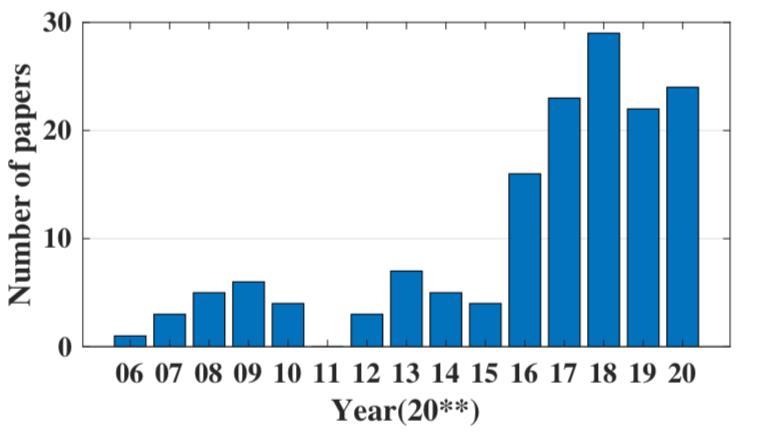
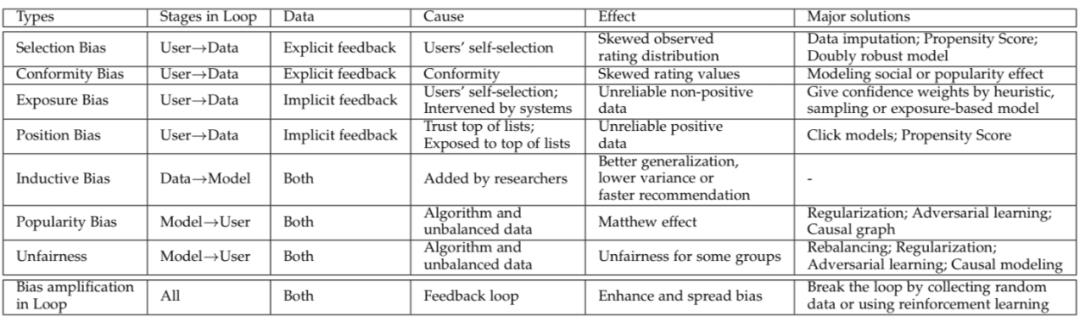
如图 2 所示,推荐系统实际上是一个环路,包括三个组成部分:用户、数据、模型。在环路的每一个部分都会引入 bias。我们根据 bias 产生的位置对其进行分类,并分别介绍。
▲ 图2: 推荐系统的反馈环路,环路的每一个环节都可能引入bias
2.1 数据中的bias
推荐系统中的数据分为显示反馈数据(多值,比如打分数据)和隐式反馈数据(二值,比如点击数据),在显示数据中,存在选择偏差(selection bias)和一致性偏差(conformity bias);在隐式数据中,存在曝光偏差(exposure bias)和位置偏差(position bias)。
Selection bias:
当用户能够自由地选择给哪些物品打分的时候,则评分数据不是随机丢失的(missing not at random, MNAR),观测到的交互数据的分布将不能代表整体数据的分布。
图 3 是用户对于随机物品和自主选择的物品的打分分布,可以明显地看出,两者的分布有较大的差异。当用户拥有自由选择权的时候,更倾向于给自己喜欢的物品打分。
▲ 图3: 用户对随机物品和自己选择的物品的打分分布
Conformity bias:
用户的打分会倾向于和群体一致,即使群体的打分有时候和用户的判断是有区别的,用户的这种倾向将使得评分并不能准确反映用户的偏好。大部分人都有从众的倾向,当用户发现自己的判断与大众不一致时,很可能改变自己的评分,而让自己的评分向大众的评分靠拢。
Exposure bias:
用户只会暴露在一部分的物品上,因此没有交互过的物品不一定是用户不喜欢的,还可能是用户没看到。用户和物品没有交互存在两种可能性:用户没看到物品、用户不喜欢物品,直接讲没有交互过的物品当作负样本(用户不喜欢)会引入偏差。
Position bias:
用户更倾向于和推荐列表中位置比较靠前的物品交互,因此在推荐列表中用户和物品的交互不仅由用户的兴趣决定,还很大程度上由物品的排名决定。相关研究表明,用户在垂直展示的列表中,更倾向于点击排名靠前的物品,而忽略排名靠后的物品。
2.2 模型中的bias
为了让模型更好地适应数据,需要对模型做各种假设,以提升模型的性能。这种假设也可以看作是一种 bias,我们称为归纳偏差(inductive bias),与数据中的 bias 不同,这种 bias 的作用是积极的。
Inductive bias:
模型可能会做一些假设,以学习更好的目标函数,产生比仅仅依靠训练集泛化性能更好的模型。模型的泛化性能可以看作是机器学习的核心目标,合理的假设能够提升模型的泛化性能,比如矩阵分解(MF)模型中的点积假设,分解机(FM)模型里的交互项假设,等等。
2.3 结果中的bias和unfairness
通过分析推荐结果,还有常见的流行度偏差(popularity bias)和不公平(unfairness)现象。
Popularity bias:
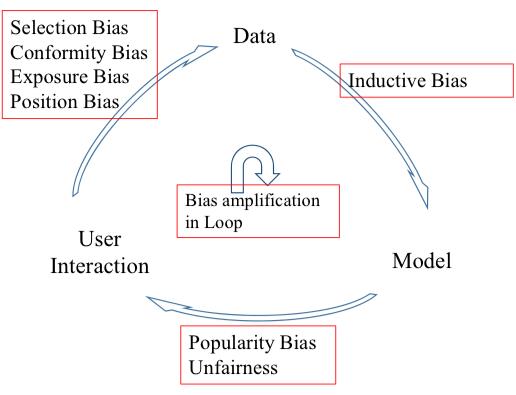
流行的物品将在推荐结果中有着比预想更高的流行度。长尾现象在推荐系统中广泛存在,即一小部分物品占据了推荐数据中大部分交互。当在长尾分布的数据上训练模型时,模型将倾向于给流行物品更高的打分,给不流行的物品更低的打分,这会导致在推荐列表中,模型也更倾向于推荐流行的物品。
如图4所示,经实验验证,模型对于流行物品的推荐频率甚至超过了其在训练集中的频率。
Unfairness:
系统为了另一部分个人或群体而给特定的个人或群体以不公平的对待。不公平的推荐系统将由于其本身的伦理问题被社会的敏感领域限制,比如可能存在的性别歧视、种族歧视等。当数据分布不均匀的时候,模型很可能学出敏感的特征(比如性别)和结果(是否给予工作机会)的相关性,这将会导致不公平现象。
2.4 反馈环路增加bias
推荐系统构成动态的反馈环路,动态的环路会增加 bias。举个例子,流行的物品在推荐结果中有更高的出现频率、展示给用户后将会有更多关于流行物品的交互、更多的交互将使得模型更容易推荐流行的物品。
▲ 表1: 推荐系统各种bias的对比
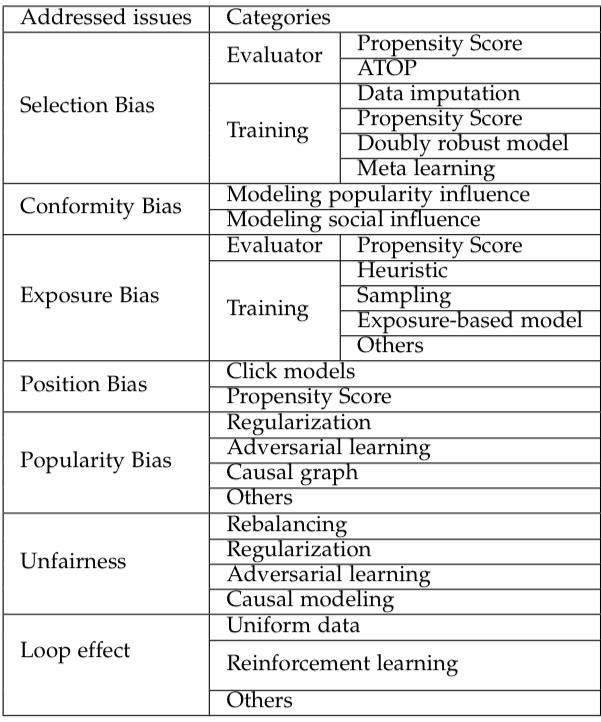
为了减弱 bias 对于推荐结果的影响,很多去偏(debias)的方法被提出来,表 2 总结了各种去偏方法。这里选取几种常用的方法进行简单介绍,对这些技术细节感兴趣的读者可以参考综述原文。
倾向评分(propensity score):
该方法来源于统计学,是处理观测数据(observational data)的常用方法。在推荐系统中应用该方法去偏的步骤:首先假设观测数据的产生机制,然后在数据中加入惩罚项(Inverse propensity score, IPS)进行去偏。在训练阶段使用该方法,可以使训练出的模型更加可靠;在测试阶段使用该方法,可以使对模型的评估更准确。
因果图(causal graph):
该方法假设产生数据的内在因果效应,并用因果图刻画该因果效应。与 IPS 方法不同,该方法显示地建模数据生成过程,在测试阶段只保留用户偏好的部分。如果对数据产生的机制假设合理,因果图将取得很好的效果。
均匀数据(uniform data):
从数据来看,bias 产生是因为数据是观测(observation)到的,那么一个直接减弱 bias 的方法在于引入更合理的实验(experiment)数据,比如引入一些随机流量、随机地调查用户对于物品的评分等等,这些均匀数据的引入将有利于减弱 bias。
倾向得分评估(propensity score, PS):
倾向得分方法的有效性依赖于对数据产生机制的假设是否正确,目前已经有不少工作做了不少,但是关于 PS 的评估仍然是一个开放性的问题,有待于进一步探索。
通用的去偏框架:
从特征可以将 bias 分成多个类别,大部分 bias 的也都有着共同的起因,即推荐系统中的数据是观测数据而非实验数据,未来有希望构建统一的去偏框架处理全部的 bias。
知识驱动型去偏:
近些年快速发展的知识图谱技术,也有希望融合到去偏中,根据知识图谱能够获得协同信息之外更广泛的信息,将知识融合进推荐模型也有助于去偏。
动态bias建模:
在实际场景中,bias 往往是随时间动态变化而不是静态不变的。动态 bias
的建模将是一个有前景的研究方向。
因果图推理:
因果图方法不仅可以挖掘数据中的 bias 产生的原因,而且可以实现知识推理、推荐解释等功能,是一个值得深入研究的方向。
推荐精度和公平性的权衡:
现有的方法在追求推荐公平性的同时往往也会造成推荐精度降低的问题,如何较好的实现两个目标依旧是一个困难的善待解决的问题。
无偏的推荐性能的评估:
由于离线场景下,获得的数据是有偏的,如何在有偏的数据上无偏的评估推荐的性能依旧是一个难题。推荐系统领域急需统一的基准数据集和评估标准。
总结
本篇综述较为系统地介绍了目前推荐系统中的 bias 问题和 debias 的方法,这是对几年来关于 bias 研究的一次归纳总结,将有助于感兴趣的读者快速了解研究现状,也有利于未来的研究。综述也提出了很多有前景的方向,以供研究者参考。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
以上是关于最新综述:推荐系统的Bias问题和Debias方法的主要内容,如果未能解决你的问题,请参考以下文章