新加坡国立大学冯福利:因果推理赋能推荐系统初探
Posted AI TIME 论道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新加坡国立大学冯福利:因果推理赋能推荐系统初探相关的知识,希望对你有一定的参考价值。
⬆⬆⬆ 点击蓝字
AI TIME欢迎每一位AI爱好者的加入!
2020 年 9 月 25 日,在由中国科协主办,清华大学计算机科学与技术系、AI TIME 论道承办的《2020 中国科技峰会系列活动青年科学家沙龙——人工智能学术生态与产业创新》上,新加坡国立冯福利博士进行了题为《因果推理赋能推荐系统初探》的主题报告,介绍了因果推理技术的实用价值,重点分析了其团队在利用反事实推理技术消除数据偏差方面的相关工作,并对因果推理研究未来的发展趋势进行了讨论。
图 1:因果推理赋能推荐系统初探
因果之梯
如图 1 所示,著名的贝叶斯网络之父、图灵奖获得者 Judea Pearl 将人类的智能划分为了三个层次(即「因果之梯」):Seeing、Doing、Imaging。Pearl 将第一层智能归纳为「关联」(Association),即观察数据并发现其中的关联关系。例如,如果我们观察超市的销售记录,可能会发现对某一种商品采取打折促销手段会导致销量上升,即发现打折和销量上升之间的关联关系。

图 1:第一层智能——「关联」
第二层的认知能力为「干预」(Intervention)。在观察销售记录的过程中,我们发现销售记录只记载了「洗发水打 5 折会导致销量上涨 20%」,但是并没有沐浴露打折对销量影响的记录。实际上,我们在进行决策时候可以推断:由于沐浴露和洗发水十分相似,如果我们对沐浴露打 5 折,可能也会增加 20% 的销量。

图 2:第二层智能——「干预」
在「因果之梯」的最上层,还具有一种认知能力——「反事实」。我们可以推测一些跟历史数据不一致的情况,预测在假定面对与现实不同的情况下会产生怎样的结果。在第二层智能「干预」中,我们可以很容易地将「洗发水打折对销量有有所提升」的结论泛化到沐浴露上。但是如果我们想要预测在打 7 折的情况下销量会增加多少,就无法简单地将历史数据泛化到目标任务上了,我们需要知晓打折和销量增加背后究竟有怎样的关系。
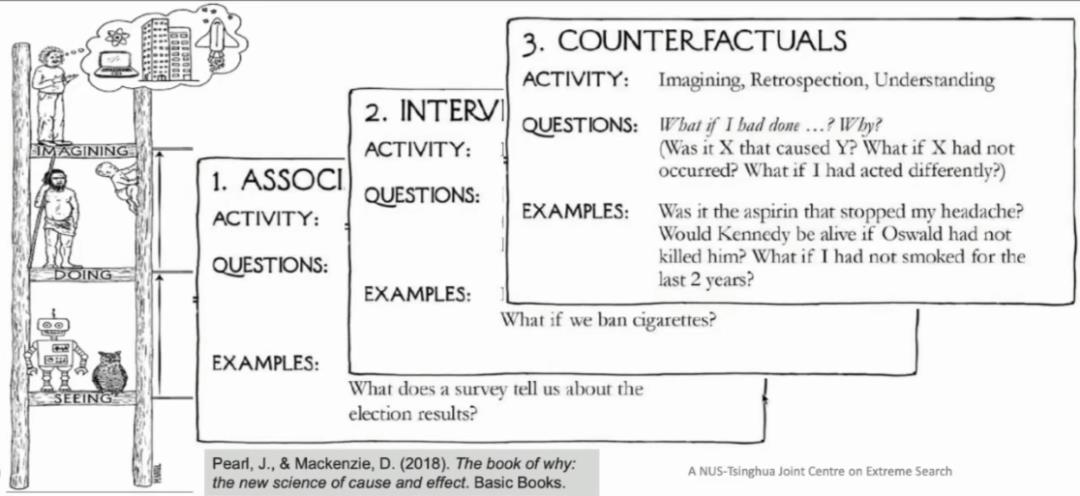
图 3:第三层智能——「反事实」
目前,大多数的机器学习模型只关注到了智能的「关联」层面,即学习出训练数据中的特征与标签之间的关联关系,但这种智能化程度仍然是远远不够的。
因果推理应用示例
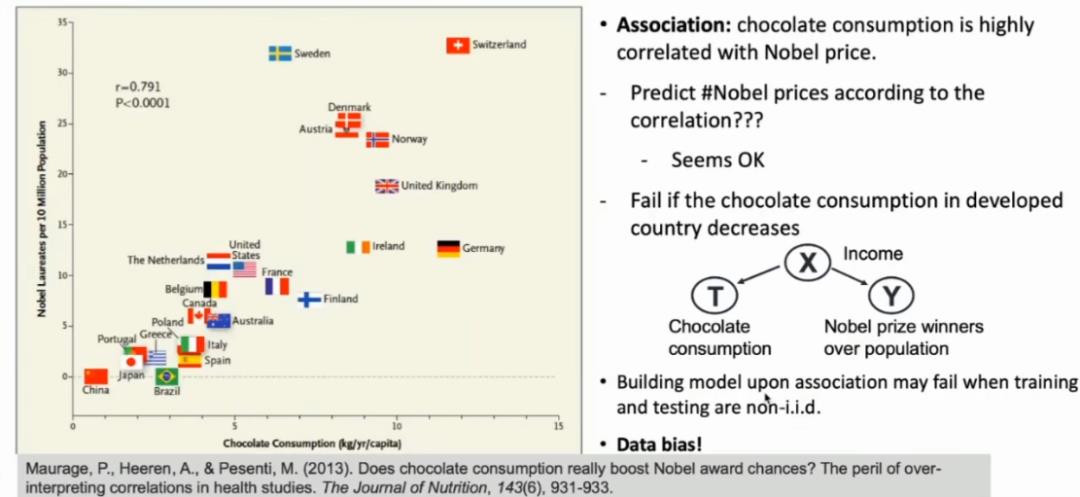
图 4:巧克力消费量 vs 获诺贝尔奖数量
如图 4 所示,横轴代表各国巧克力的消费量,纵轴为该国家每 1000 万人口中诺贝尔奖得主的数量。不难发现,该图表明巧克力消费量和获诺贝尔奖的数量是高度相关的。那么问题来了:如果我们能否根据这些特征及其之间的相关性构建一个模型,预测某个国家未来会获得多少诺贝尔奖?由于图 4 显示巧克力消费量与获诺贝尔奖数量正相关,这个思路看起来似乎是可行的,该模型会认为巧克力消费量很大的国家可能获得的诺贝尔奖也很多。那么,该模型何时会失效呢?例如,假设某些获诺贝尔奖可能性很大的发达国家的人民突然间注意到了肥胖问题,而吃很多巧克力也许会导致肥胖,此时这些国家的巧克力消费量可能就会下降。如果我们再用之前的模型预测获诺贝尔奖的数量,结果将会不够准确。
该模型为什么会失效?从数据上看,历史数据告诉我们,巧克力消费量和诺贝尔奖的获得数量是高度相关的。但是,其背后的原因可能是:在过去的几十年中,收入较高的国家对于教育、科研的投入可能更大,因此就获得了更多的诺贝尔奖。同时,收入较高的国家可能也会消费更多巧克力,所以才导致巧克力的消费量与获得诺贝尔奖的数量在表面上有高度的正相关性。然而,如果收入高的国家的国民出于健康考虑,不再吃更多巧克力,这种相关性就会产生改变。
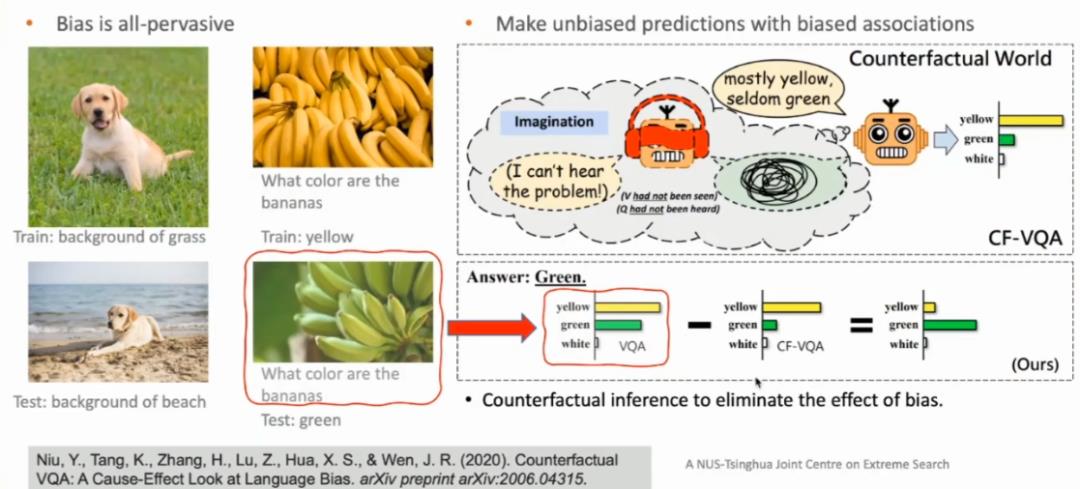
图 5:无处不在的数据偏差
总而言之,如果我们单纯依靠相关性构建机器学习模型,当训练数据和测试数据并不满足独立同分布假设时,模型就会失效。训练机器学习模型的过程离不开训练数据,尽管世界范围内的各个研究组贡献了很多高质量的数据集,但是这些数据集仍然存在很多数据偏差(bias)。以 ImageNet 数据集上的物体识别任务为例,图片的背景就是一种数据偏差。如果数据集中大多数狗的图片都是在草地上的狗(即背景为草地)。当测试样例是海滩上的狗时,使用该数据集训练出来的物体识别模型很有可能无法顺利将狗识别出来。
此外,在视觉问答系统(VQA)任务中,同样也存在数据偏差的问题。假设问答系统接收到的问题是:「香蕉是什么颜色的」?在我们的训练数据集中,大多数对于该问题答案都是「黄色」,即训练数据集中的香蕉都是熟透了的黄色。但是,当我们遇到一个测试用例为还未成熟的绿色香蕉图片时,很有可能 VQA 模型无法正确回答出该香蕉为绿色。这是因为在训练好的 VQA 模型看来,绝大多数训练样例对该问题的答案都是「黄色」,模型很难纠正这种「偏见」。
为了应对数据偏差问题,智源人工智能研究院首席科学家文继荣教授团队在论文「Counterfactual VQA: A Cause-Effect Look at Language Bias」(https://arxiv.org/abs/2006.04315)中给出了他们的解决方案。他们认为,针对有偏的数据集,我们不应该陷入费时费力纠偏的无限循环中。假如训练好的模型做出的预测是有偏的(例如,对于绿色的香蕉图片,回答其为黄色的概率更大),我们可以挖掘导致产生这种偏差的原因。当模型只有一种输入的时候,我会得到只考虑偏差数据的情况下的预测结果(即中间答案)。训练数据集中有很多因素都会对香蕉颜色的问题带来数据偏差,由于数据集中大多数香蕉都是黄色的,因此模型在不观察图像的情况下和没有看到问题的情况下都会更偏向于回答香蕉的颜色是「黄色」,如果将完全影响(TE,定义请参阅原文)与自然直接影响(NDE,定义请参阅原文)相减,就可以消除掉模型预测中的语言偏差,作者在这个框架中利用反事实推理消除掉了偏差的影响。
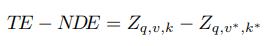
因此,解决此类问题的核心步骤为:(1)分析造成偏差的原因(2)量化估计造成偏差的因素在预测过程中的影响程度,通过消除这种因素的影响来消除偏差。
推荐系统中的因果推理
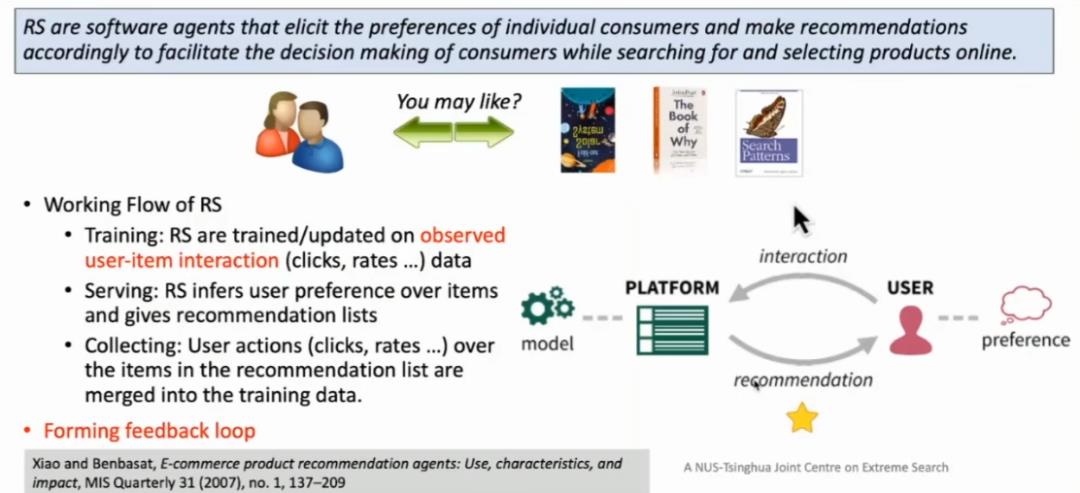
图 6:推荐系统
推荐系统旨在通过预测用户的兴趣,为用户推荐一些商品,帮助用户更快地买到自己想要的东西。在实现过程中,大多数公司的推荐系统会迭代进行以下三种操作,形成了一种用户反馈的循环:(1)模型训练:利用历史数据中用户和物料之间的交互记录训练一个推荐模型(2)通过模型输出影响用户行为:将训练好的模型上线,为用户生成推荐列表,将排序靠前的物料推送给用户(3)根据用户反馈修正训练数据:收集用户使用推荐列表的反馈信息,查看用户点击了哪些物料、跳过了哪些物料,将用户的行为反馈数据添加到训练数据中,进而开始新一轮的迭代。
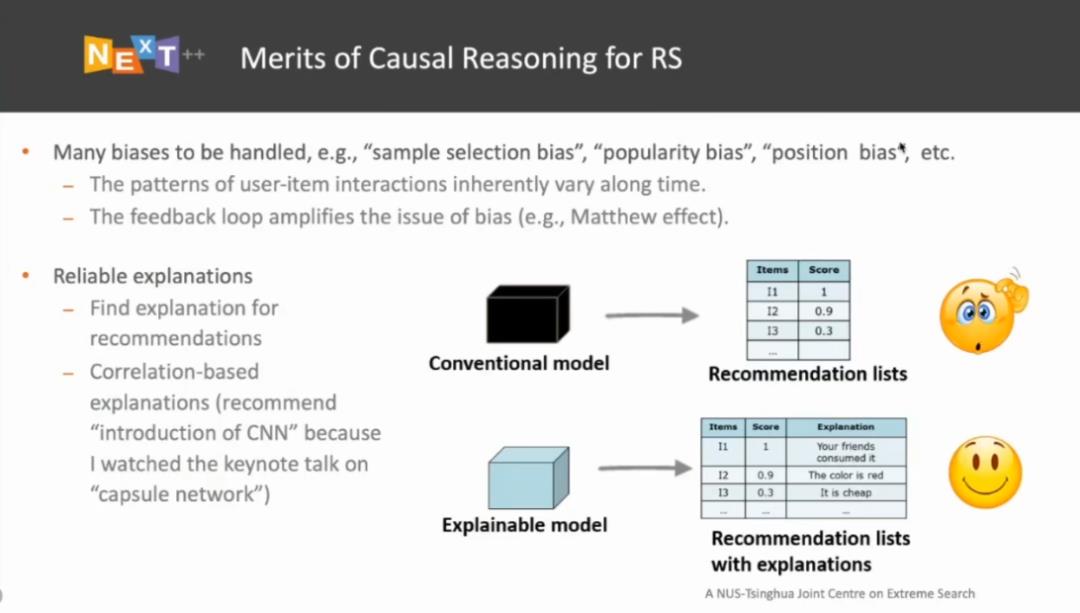
图 7:推荐系统中的数据偏差
受到上文所介绍的论文「Counterfactual VQA: A Cause-Effect Look at Language Bias」(https://arxiv.org/abs/2006.04315)的启发,冯福利博士团队考虑使用因果推理技术解决推荐系统存在数据偏差的问题。例如,推荐系统中存在数据选择偏差:我们所观察的历史记录数据可以说明用户点击了哪些我们向其展示的物料,而无法知晓用户是否会点击我们未向其展示的物料东西我不知道用户会不会点,这种点击行为本身也是有偏的。
再举一例,推荐系统中也存在流行度偏差的问题(马太效应)。如果某个物料本身十分受欢迎,那么历史数据就会记录有很多用户点击了该物料,相对于其它不流行的物料来说,该物料被推荐的概率要大很多。另一方面,由于该物料被推荐的概率更大,它会得到更多被展示的机会,因而很可能有更多被点击的机会。当用户新的点击行为记录被添加到训练数据中之后,流行的物料会变得更加流行(马太效应),即用户反馈循环会放大数据偏差。目前,越来越多的研究人员正试图通过因果推理技术处理推荐系统中存在的数据偏差问题。
除此之外,因果还能为推荐系统带来更可靠的解释性。目前,深度学习模型大多是黑盒模型。对于为终端用户服务的模型而言,如果我们可以为其赋予可解释性,将会在很大程度上有助于提升用户对系统的信任程度。当前大多数的可解释推荐方法仍然停留在为推荐结果寻找解释的层面上,它们试图通过注意力机制或者树状结构等方式构建一个可解释模型。然而,由于我们往往基于「关联」关系搭建了推荐模型,因此这些解释结果只能够反映出一些相关性层面上的推荐原因。例如,当 YouTube 等视频网站为用户推荐了一个介绍卷积神经网络(CNN)的视频,传统方法对其的解释可能是:用户观看过 Hinton 有关「胶囊网络」(capsule network)的主题演讲(注:胶囊网络与卷积神经网络之间有关联,它们都属于神经网络模型)。然而,这种解释似乎并不合理。这是因为,观看「胶囊网络」演讲的用户一般而言对于卷积神经网络已经有所了解。如果再向此类用户推荐 CNN 的入门介绍视频,这里提供的解释是没有说服力。目前,一部分研究人员正试图基于「逆倾向指数」(IPS,Inverse Propensity Score)将因果推理引入到推荐系统的可解释性研究工作中。
推荐系统中的流行度偏差
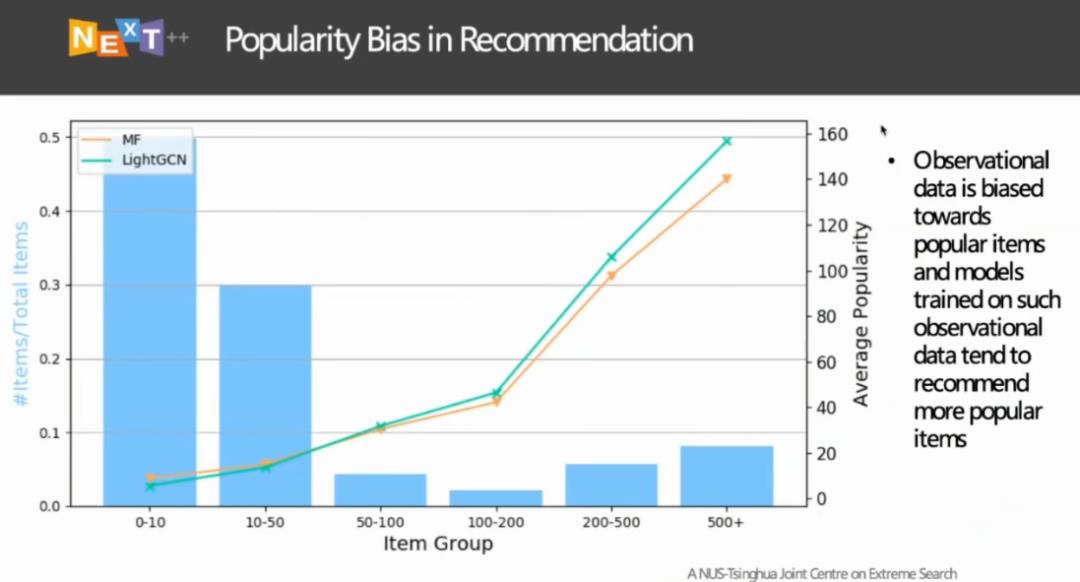
图 8:MovieLens 数据集中的流行度偏差
图 8 显示了公开的推荐系统对比基准数据集 MovieLens 中的流行度偏差情况。我们按照训练数据中的交互频率将物料分为 6 组,观察不同的推荐系统在测试阶段推荐各组物料的频率。不难发现,在训练数据中出现次数越多的物料被推荐的次数也明显越多。无论用户是否喜欢该物料,只要该物料在训练数据中出现次数多就有可能被推荐给用户,而用户自己的兴趣就被频繁出现的物料「支配」了。具体而言,如果某用户对体育十分感兴趣,用户在购物时会期望推荐系统推送一些与运动相关的物料。然而,假如用户购物的时间节点在苹果举行产品发布会前后,手机将会成为训练数据中出现次数十分频繁的物料,推荐系统可能会向用户推荐数码产品而非与运动相关的产品,这与用户的购买兴趣不符。
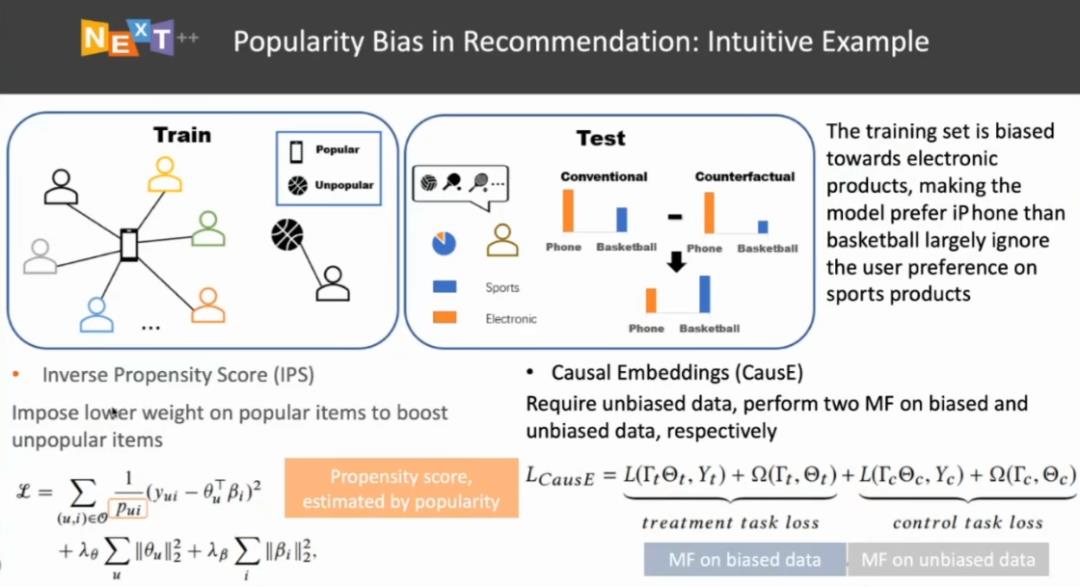
图 9:通过 IPS 解决推荐系统中的流行度偏差问题
为了解决这一问题,一些传统的基于因果推理的方法采用了 IPS 技术。简而言之,IPS 指的是:用户在训练时会产生一系列点击行为,我们用 u_i 代表用户 u 点击第 i 个物料,用户之所以点击某个受欢迎的物料,可能是因为物料具有某些使其流行起来的特性,也可能是因为该物料本身符合用户的兴趣。为了将这两层因素拆分开来,我们为流行的物料赋予一个较小的权重,使其对训练的贡献较小。还有一些研究人员采用「因果嵌入」(CausE)来解决流行度偏差问题。例如,使用无偏的数据,试图将带来流行度偏差因素与匹配用户兴趣的因素分离开来。
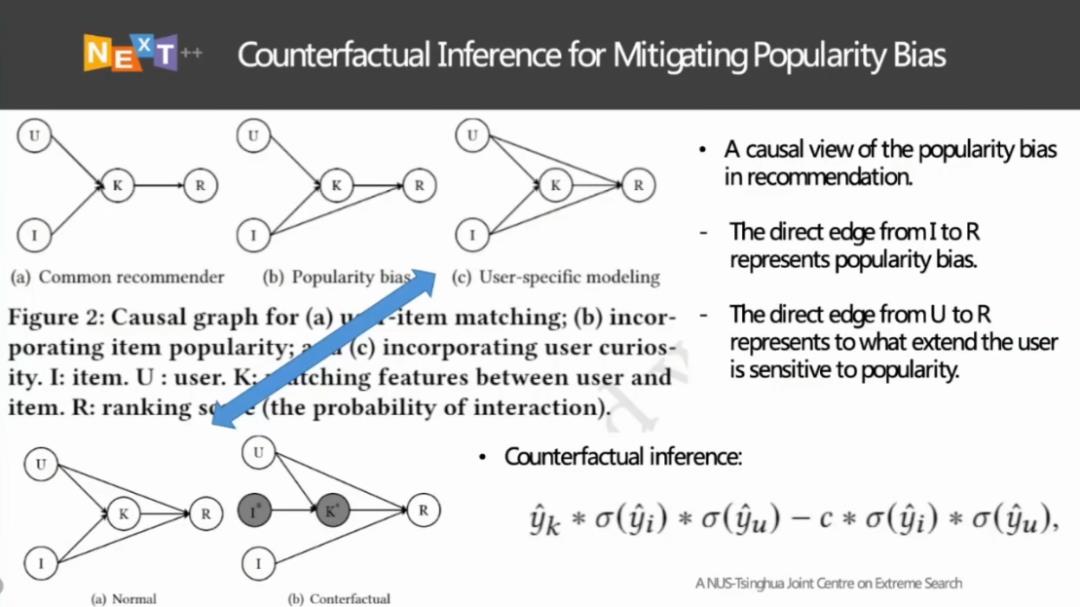
图 10:通过反事实推理技术消除流行度偏差
在冯福利博士的研究团队看来,上文提到的两种解决方案都试图在训练阶段解决流行度偏差问题。而简便起见,我们是否可以在使用有偏的数据训练,得到有偏的模型推荐结果的情况下,试图将带来流行度偏差的因素消除掉,从而得到无偏的推荐结果。
在如图 10 所示的因果图中,左侧显示了「用户-物料」的匹配、考虑物料的流行度、考虑用户的好奇心等推荐模式。其中,U 代表用户的嵌入、I 代表物料的嵌入、K 表征用户与物料之间的匹配程度,R 为根据 K 得到的推荐排序得分。
由于我们的模型使用的训练数据是用户的点击行为,则 R 本质上代表了用户点击物料的概率。我们发现,流行度偏差会对点击物料的概率产生影响。流行的物料本身带有一些使其流行起来的属性,这些物料会被多次推荐,从而被频繁点击。而另一方面,这些流行的属性也会使物料的相关得分提升,因此流行度对点击概率有直接的贡献,因此我们在 I 和 R 添加了一条边,使 I 能直接影响 R,而不是通过 I 和 U 的匹配情况(即 K)来影响 R。除此之外,不同的用户对于流行的物料、流行度偏差的反应也有所差别。有的用户受流行度偏差的影响较小,即使推荐系统频繁推荐某些流行的物料,用户也不会点击不符合自己兴趣的物料;而另一些用户的好奇心较强,会点击被持续推荐的流行物料。可见,流行度偏差对不同的用户的点击行为造成的影响是不同的。因此,我们在第三种模式中又添加了一条从 U 到 R 的边,体现用户好奇心对点击行为的直接影响。
为了估计出流行度偏差对点击概率的影响,冯博士团队通过反事实的方式,假设只考虑物料的特征,不考虑用户和物料之间的匹配,计算推荐结果排序的得分。我们从流行物料的推荐得分中减去流行度的影响就可以得到一个无偏推荐。
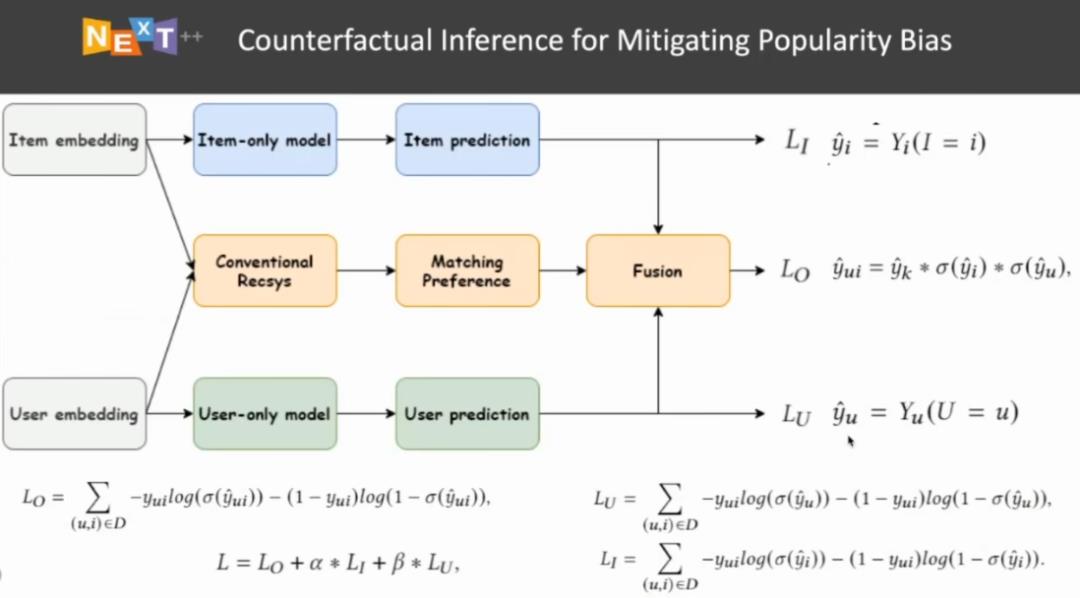
图 11:基于反事实的流行度偏差消除模型架构示意图
具体而言,图 11 中黄色的部分代表传统的推荐系统,该模型使用用户嵌入和物料嵌入作为输入,得到二者的匹配情况 y_k,并基于这种匹配得出推荐得分。除此之外,我们还额外引入了两项用于分别建模 U 和 I 对 R 的直接影响,将使用物料特征得到的预测结果记为 y_i,将使用用户特征得到的预测结果记为 y_u。
在训练层面上,我们在传统的推荐系统的二分类交叉熵(BCE Loss)中加入额外的两项监督信号,分别代表用户和物料直接影响。通过这种对损失函数的改动,我们可以得到消除流行度偏差所需的项。
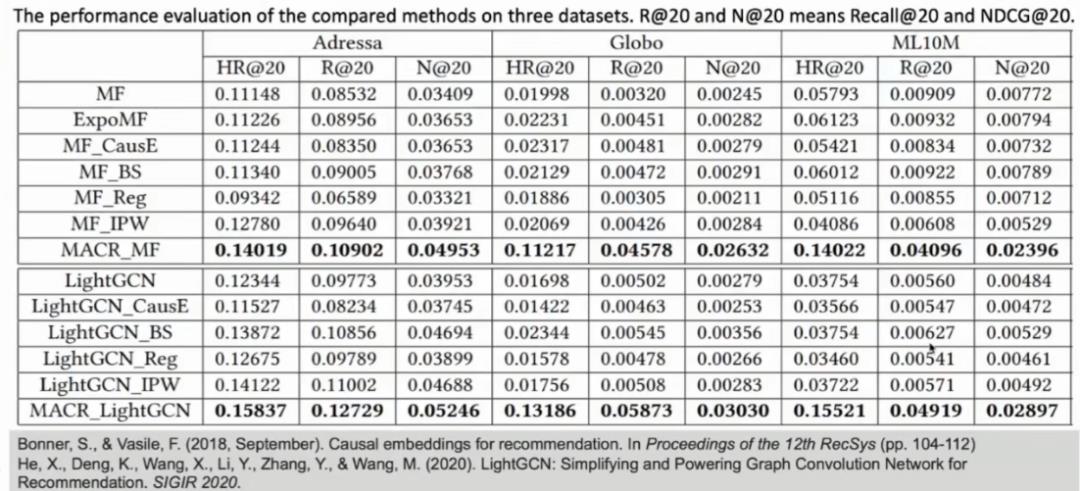
图 12:消除流行度偏差影响的实验结果
为了验证模型性能,冯博士团队在 5 个数据集上进行了对比实验,图 12 显示了在其中三个数据集上的实验结果,实验结果显示冯博士团队提出的模型大大提升了推荐系统的性能。
推荐系统中的「点击诱饵」偏差

图 13:推荐系统中的「点击诱饵」偏差
除了流行度偏差,推荐系统中还存在「点击诱饵」偏差问题(即物料中存在许多「标题党」)。「点击诱饵偏差」指的是,用户可能会由于物料标题的误导而产生一些点击行为。以视频为例,某视频的标题和封面可能是令用户十分感兴趣的 UFO,而实际上当用户打开视频后,会发现视频内容与 UFO 没有关系,从而带来了非常差的用户体验。如果说我们用基于点击行为数据集去训练推荐系统模型,会经常遇到这种「点击诱饵」偏差。
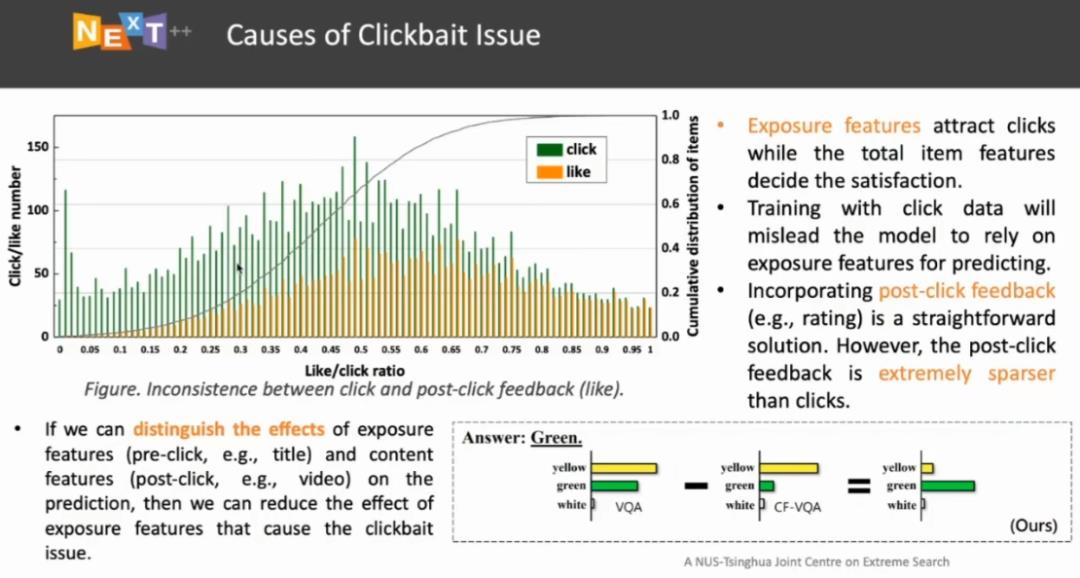
图 14:造成「点击诱饵」问题的原因
图 14 显示了「点击诱饵」对用户体验的影响。图 14 的横轴代表用户点击和用户最后是否喜欢该物料的比例。我们按照比例对点击行为进行了排序,发现用户对很多物料的点击的体验处于图的侧部分,对应于「踩」(dislike)。如果我们使用点击行为训练一个推荐系统模型,「曝光特征」(exposure features)会吸引更多的点击量,然而它并不能保证良好的用户体验。
在论文「Counterfactual VQA: A Cause-Effect Look at Language Bias」(https://arxiv.org/abs/2006.04315)的启发下,我们试图估计出标题对预测点击行为概率的贡献,并减去这种贡献,就可以得到对「标题党」无偏的推荐结果。
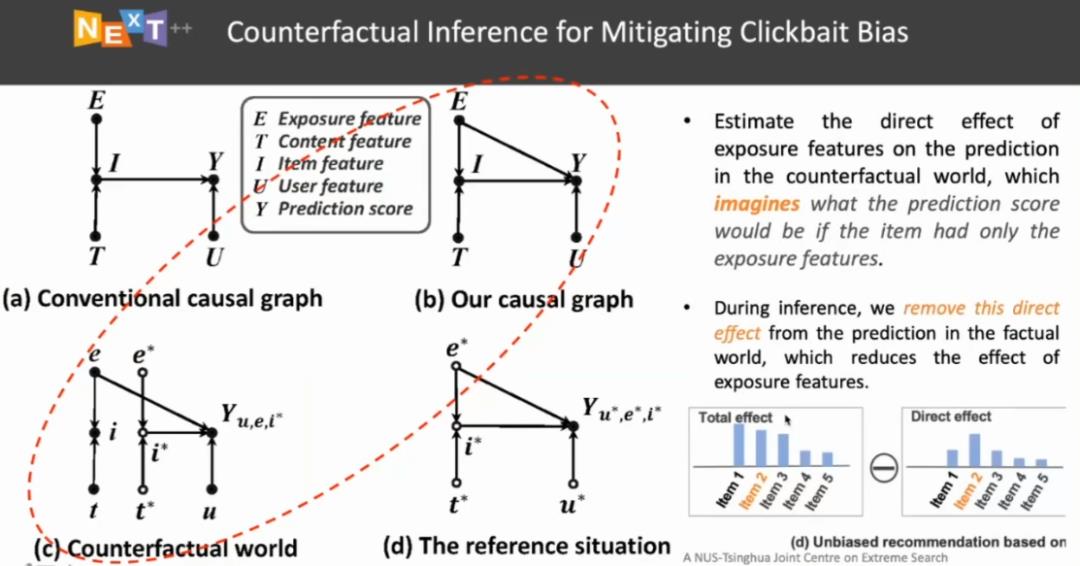
图 15:通过反事实减小「标题党」偏差
类似地,冯福利团队梳理了这一推荐过程中的因果关系,添加了曝光特征与预测得分之间直连的边,利用反事实的方法去估计曝光特征对于点击概率的贡献(即因果效应),在预测得分中减去曝光特征的贡献就可以得到相对无偏的推荐结果。例如,对于物料 2 来说,如果我们只使用曝光特征,会发现其对其点击行为的预测概率就非常高。原始的数据是有偏的,如果物料 2 存在「标题党」现象,但我们从预测得分中减去曝光特征的影响我,物料 2 的排序就会下降,从而消除了这种「点击诱饵」误差。
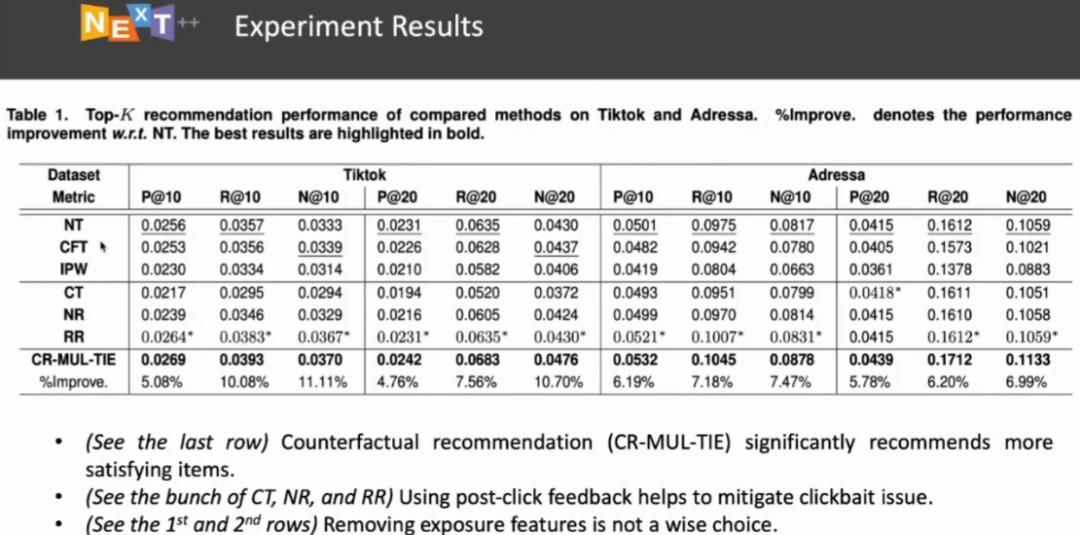
图 16:实验结果
冯福利博士进行的一系列实验为我们带来了以下启发:(1)对于有偏的模型来说,只需通过简单的反事实推理操作,就可以有效实现纠偏,得到明显的性能提升。(2)引入用户在点击物料之后的反馈情况有助于消除「标题党」偏差,在反事实推理中需要考虑用反应用户体验的行为。(3)根据图 16 第一行、第二行的结果,单纯地将导致偏差的因素减掉(例如,曝光特征),并不是明智的选择,模型的性能会有所下降。这是因为曝光特征等因素还是可以在一定程度上反映出用户的兴趣。
未来的研究方向
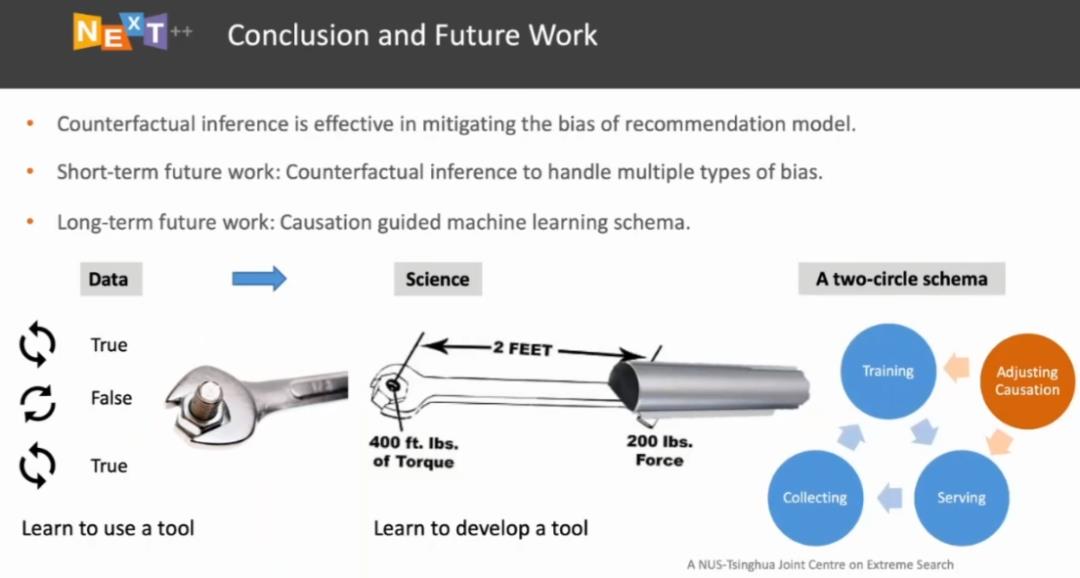
图 17:结语及未来的工作
冯福利博士指出,他们当前基于反事实推理消除数据偏差的工作都是针对每一种偏差单独设计处理方法,当我们遇到多种数据偏差时,现有的模型就可能会失效。短期之内,冯福利博士团队试图同时处理多种数据偏差,在推理阶段设计一个快速的适配器,决定针对给每一位用户的特点应该更多地消除怎样的数据偏差。未来,冯福利博士团队试图搭建一种基于因果推理的机器学习模式。他们认为,机器学习研究应该经历「数据」到「科学」的发展过程。从「数据」的角度来看,如果我们想解决拧螺丝的问题,在收集大量数据后很快就能教会机器:顺时针会将螺丝拧紧,逆时针可以将螺丝拧开。但是从「科学」的角度来说,扳手之所以可以拧开螺丝是因为杠杆定理。「数据」驱动的机器学习与「科学」驱动的机器学习的区别在于:当我们遇到拧不开的螺丝时,如果知道背后科学原理是杠杆定理,我们应该想办法延长力臂,而不是盲目地在数据中进行尝试。如图 17 所示,左图表示当前的机器学习技术实际上是学习如何使用某种「工具」;而右图指的是,当我们了解了事物背后的因果关系后,就知道如何设计一个工具。
在冯福利博士看来,在双系统模型中,System 1 旨在是学习使用工具,System 2 旨在学习制造工具。为了制造工具,我们要让机器学习知晓所有的因果关系。而在推荐系统领域中,传统的「训练」、「上线」、「收集新数据」的循环训练范式无法满足上述要求。因此,我们需要引入额外的循环整理出因果关系,从而指导模型的训练。
整理:熊宇轩
审稿:冯福利
本周直播预告:



AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。
更多资讯请扫码关注
(点击“阅读原文”查看直播回放)
以上是关于新加坡国立大学冯福利:因果推理赋能推荐系统初探的主要内容,如果未能解决你的问题,请参考以下文章