腾讯看点投放系统介绍:推荐系统的进化伙伴
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯看点投放系统介绍:推荐系统的进化伙伴相关的知识,希望对你有一定的参考价值。
大家好,我叫陈鹏,来自腾讯。
前三位老师讲得都很有深度,干货满满。相比于前三位老师的深度,我今天分享的主题将会轻松一些,主要跟大家介绍腾讯看点在投放系统的探索,没有学术和深刻的原理,也没有目录,这里只有故事,跟着我的 PPT 一起开启一段故事吧。
在介绍投放系统之前,我想做个简单的调查,有多少人用过信息流产品?比如腾讯看点、今日头条等等。还挺多,那再问一下,在浏览信息流的时候,有多少人看到过令自己反感的内容?发现刚刚举手的同学基本也都举了手。这说明信息流中出现低质内容还是件挺常见的事,那该如何解决呢?这其实是一件很难的事情,我们信息流的同学一直都在探索,其中投放系统就是探索的产物之一。
要说投放系统,推荐系统是绕不开的,因为投放系统就是为了解决推荐系统的问题而诞生的。那什么是推荐系统呢?刚刚潘老师已经做了非常详细和深入的讲解,我这里就简化一下。
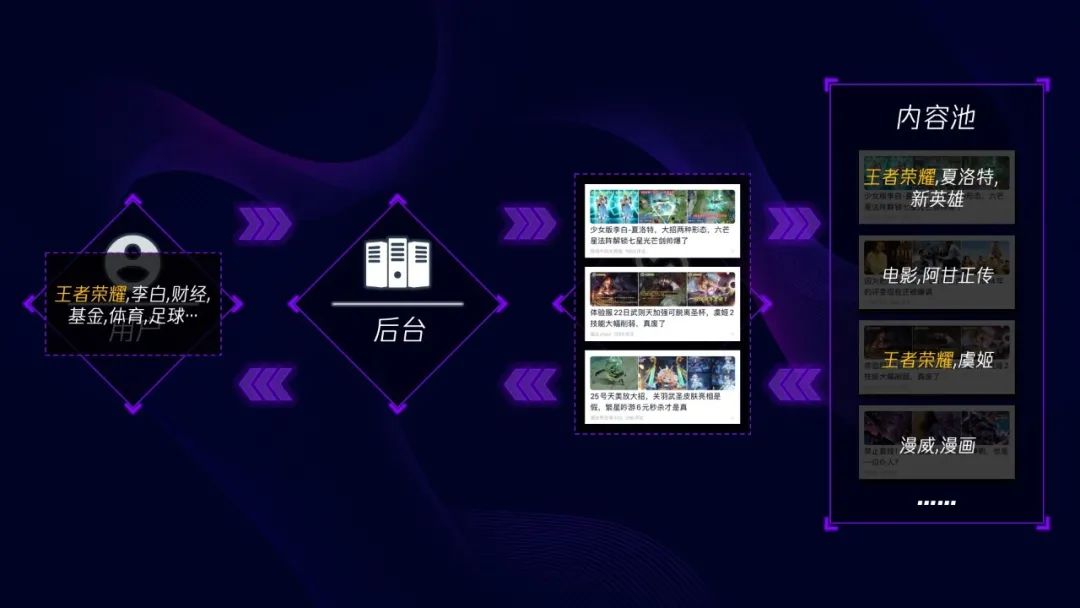
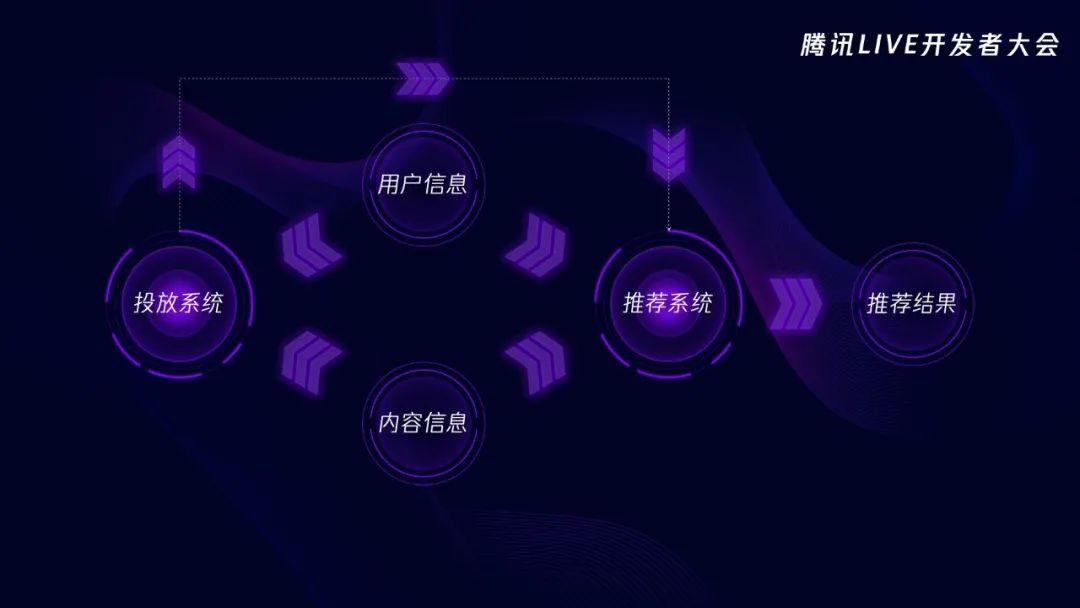
大家想象一下,现在有一位用户打开了信息流产品,那接下来会发生什么?前端会去请求后台,后台又会去请求推荐系统,推荐系统再去内容池翻箱倒柜,找几篇这名用户最有可能喜欢的内容。那推荐系统是怎么知道用户喜欢什么类型的内容的呢?用户画像,每名用户身上都会有一些标签,表示喜欢或者讨厌什么,比如这名用户的画像显示他比较喜欢王者荣耀、财经、体育等等。每篇内容也都有自己的标签,表示这是什么样的内容。推荐系统要做的呢,就是将用户和内容相互匹配,比如这名用户的画像里有“王者荣耀”,那么推荐系统就会给他推荐王者荣耀的内容。

小结一下,推荐系统做的事呢,就是将用户信息和内容信息互相匹配,然后将匹配的结果推荐给用户,就是推荐结果。这样会有什么问题吗?如果这是一名新用户,没有画像,那应该怎么办呢?推荐系统有一个内容池,专门给这些新用户准备的,因为这里面的内容是机器筛选的,所以不乏一些标题党、擦边球的内容,用户看到这类内容时,虽然眉头一皱,但还是经常忍不住去点击,不点不打紧,就这么一点,误会大了,推荐系统就会认为这名用户喜欢这类内容,后面就会使劲给用户推类似的内容,用户虽然很反感,但又忍不住不看,所以就会形成恶性循环,等到用户失去耐心的时候,就不会再用这款产品了。
那如何打破这种恶性循环呢?一种方式是人为干预,机器可能会傻乎乎给你推送看似受欢迎实际比较低质的内容,但我们的运营同学只会精选优质内容,然后连同推荐系统给的结果一起推送给用户,那这样用户是不是就可以看到优质内容了呢?

现在再来看请求数据的过程,用户访问信息流产品时,前端会向后台请求,跟之前不同的是,这时后台会向混排层请求,混排层一方面跟推荐系统请求推荐结果,比如推荐系统推荐了两篇跟王者荣耀有关的内容;另一方面混排层会查询一下运营同学有没有人工推荐的内容,比如这里运营同学人工推荐了这篇跟《三十而已》有关的内容。混排层收到推荐系统和运营配置的内容后,根据一定规则混合排列两边的数据,然后再将数据一起返回给前端用户。这样用户就可以看到推荐同学精选的优质内容了。
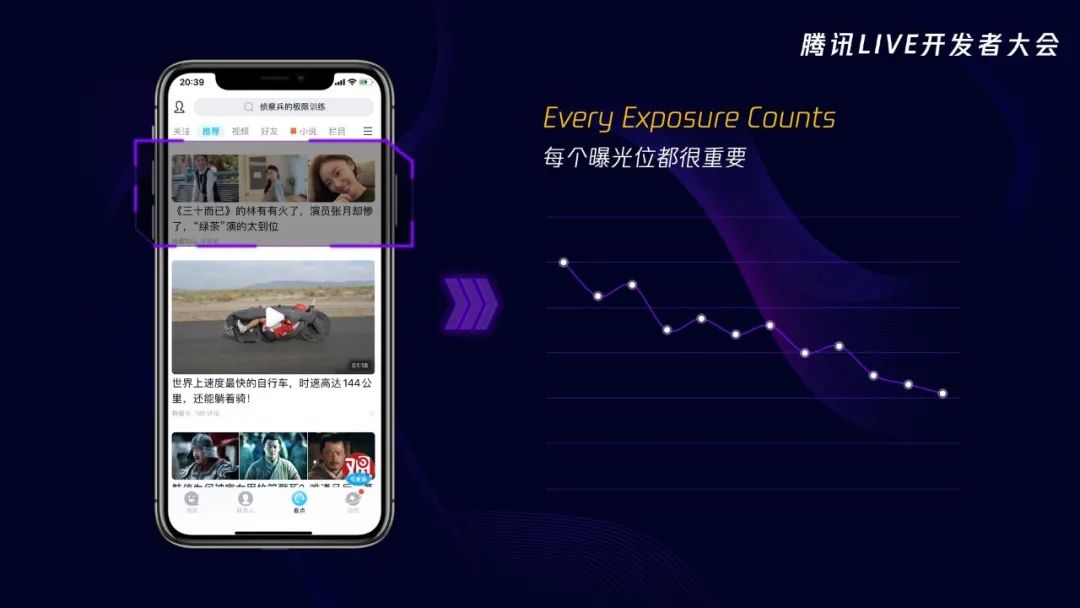
我们继续追问,这样做会有什么问题吗?内容是好内容,但不一定所有人都喜欢,比如刚刚说的,运营同学推荐了《三十而已》的内容,但其实会有相当一部分用户并不喜欢。每个曝光机会都很重要,特别是前几条,用户如果不喜欢《三十而已》,那就不会去点击,势必会导致大盘数据的下跌。那该怎么办呢?如果我们能够提高运营推送的准确性,把不同的优质内容推送给那些大概率会感兴趣的用户那里,那是不是就既能解决大盘数据下跌,又能解决运营给用户推送优质内容的问题了呢?
那如何提高运营推送的准确性呢?秘诀就是我们今天的主角:投放系统。投放系统所做的工作,用一句话概括就是,把运营同学认为优质的内容尽可能准确地投放给那些可能感兴趣的用户。这里面有两个要点,第一,投放什么内容?第二,内容投放给什么用户?分别来看。
第一要点,投放什么内容。投放系统投放的内容也是经过入库服务后进入到内容池的那些内容,我们的运营同学会在内容池中挑选出优质的内容,并且把它们进行归类。运营同学会根据他们的需要将这些优质内容聚合在一起,这些根据一定规则聚合的内容被称为“兴趣点”,这里的规则可以指同一个账号、同一个品类、同一个主题、同一个话题等等等等,只要我们的运营同学认为有相同点,就可以把这些内容聚合在一起。我们举些例子,著名歌手胡夏就是一个账号,品类的话比如美食品类,主题的话比如漫威,话题的话比如最近非常火的《三十而已》,这里的“胡夏”、“美食”、“漫威”、“三十而已”都是兴趣点。我们可以看到,兴趣点的划分实际上没有什么规则,粒度可大可小,维度灵活多样。小结一下,投放系统投放的内容是以兴趣点作为维度的,兴趣点是一个抽象的概念,代表相同种类的内容。
说完第一个要点,那继续说第二个要点:内容投放给什么用户?我们刚刚说到,内容是按照一定的相同点聚合在一起的,投放系统的工作就是把这类内容投放给可能感兴趣的用户。说到这里,我们可以更好地看出把内容聚合在一起的好处了,为一篇内容找到目标用户是很困难的,但为一类内容找到目标用户就简单许多。
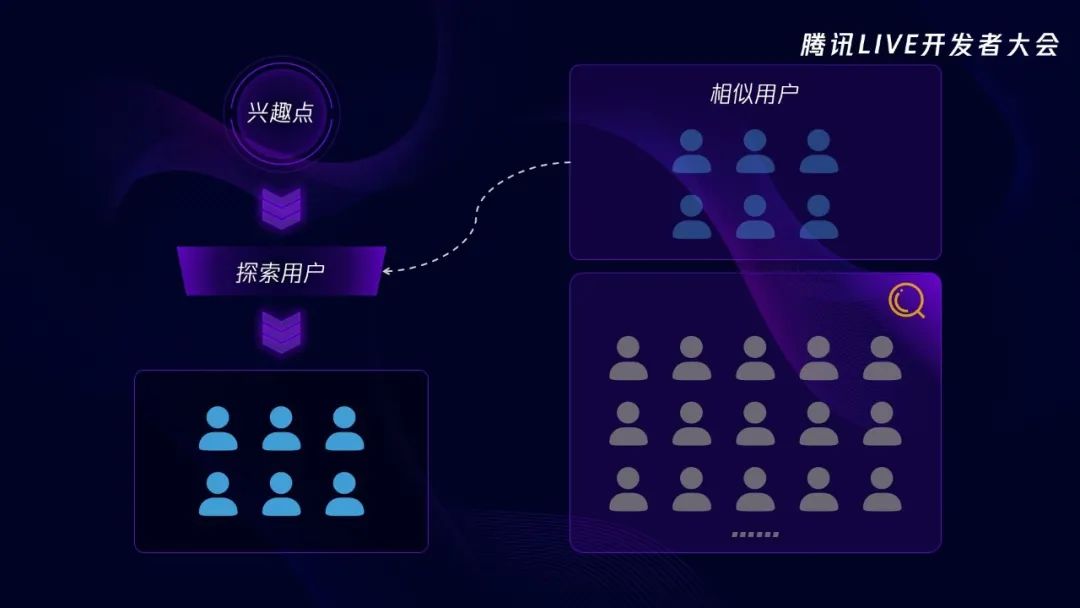
说回内容应该投放给什么用户,一开始投放系统其实也不知道,但是它会不断地探索,找到目标消费者。针对每一个兴趣点,投放系统会试探性地给一些用户投放这个兴趣点里面的内容,拿《三十而已》这个兴趣点举例,假设投放系统每天会给一批用户投放5篇左右《三十而已》的内容,有的用户对这个话题不感兴趣,可能一条都不会点,有的用户就比如我知道这么个话题,持中立态度,可能会点一两篇看一下,而有的用户如果是《三十而已》的忠诚粉丝,那很可能四五篇都会点。投放系统有一套算法,会根据用户的点击情况打分,将用户分成非受众、相关用户和核心用户三类。这是第一天的情况,投放系统会针对每一个兴趣点圈出一部分用户进行探索,然后根据探索结果将用户分成这个兴趣点的非受众、相关用户和核心用户三种类别。那第二天、第三天,一直持续探索,是不是就可以在茫茫人海中圈出这个兴趣点越来越多的相关用户和核心用户了呢?确实是的,而这两类用户正是这个兴趣点的重要资产。
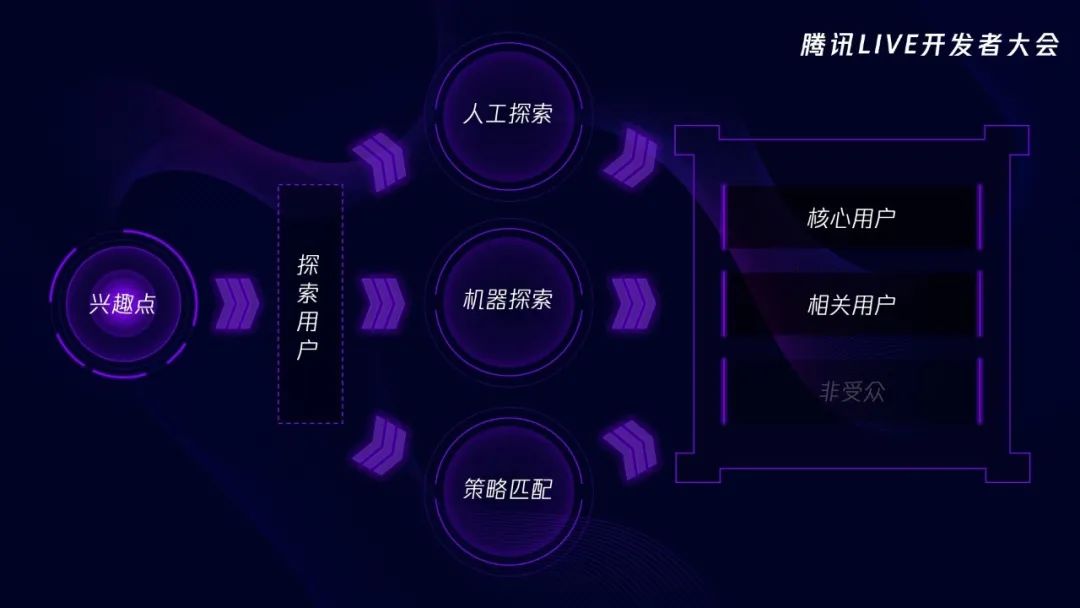
当一个兴趣点刚刚创建的时候,它是没有任何相关用户或者核心用户的,那我们就需要去探索,哪些用户可能对这个兴趣点感兴趣。那怎么探索呢?一种方法就是随机探索,随便选一些用户,然后给他们投放内容,毫无疑问,这样的效率肯定很低。有没有效率更高的方式呢?这里挑三种方法给大家介绍一下,分别是:人工探索、机器探索和策略匹配。

先来看人工探索。无论玩过没玩过,相信很多人应该知道地下城与勇士这款游戏,最近呢,地下城与勇士的手游将要上线,不过我们不谈游戏,只谈由游戏衍生出的内容。新款手游的上线肯定会产生很多相关的优质内容,我们的运营同学敏锐地抓住了这一点,提前在投放系统里面创建了一个叫“地下城与勇士手游”的兴趣点。问题来了,内容有了,目标用户呢?不要慌,我们运营同学的专业经验就能派上用场了,他们会定几个筛选条件,比如性别、年龄、收入等等,然后筛选出最有可能喜欢“地下城与勇士手游”的用户,比如性别选择男性、年龄选择15-35岁之间,地域选择一线城市、操作系统选择不限、收入水平选择月薪8000以上、用户标签选择游戏动漫类的。设定的这些条件,大大提高了探索的准确性,这就是人工探索的基本原理。
那我们的运营同学是如何知道用户的性别、年龄这些信息的呢?用户画像。目前我们用到的画像有两类,一类是腾讯看点自己的用户画像,比如财经、动漫、时尚等等,另一类是其他业务的用户画像。比如IEG游戏画像、腾讯视频画像、QQ音乐画像等等。小结一下,人工探索是依赖于运营专业经验的一种探索兴趣点新用户的投放方式。
说完人工探索,我们继续看机器探索。我们刚刚提到,当一个兴趣点刚刚创建的时候没有核心用户或者相关用户,经过运营同学的筛选圈定一部分用户进行探索后,这个兴趣点会沉淀一些核心用户和相关用户,我们用蓝色的小人表示。所谓物以类聚人以群分,这部分用蓝色表示的用户一定有一些共同的特征,我们把这些共同的特征提取出来,然后在大盘里找具有这些特征的用户,再把他们筛选出来作为我们的探索用户。这些探索用户是机器算法筛选出来的,所以被称为机器探索。小结一下,机器探索是依赖机器算法的一种探索兴趣点新用户的投放方式。

以上是机器探索,我们继续看策略匹配。假设有一名用户在QQ里面搜索了“地下城与勇士”,我们是不是很自然地认为这名用户对“地下城与勇士”感兴趣呢?那这名用户当仁不让地成了“地下城与勇士手游”这个兴趣点的探索用户。这名用户搜索的时候,触发了我们一条具体的策略:“搜索地下城与勇士”,这里搜索是行为,地下城与勇士是关键词,搜索某个关键词就是我们的一种策略。策略就是触发特定信号的行为,目前我们设置了六种策略,当然我们一直在探索其他的策略。每个兴趣点话可能会设置一些策略,如果触发了这些策略,就会成为这个兴趣点的探索用户。
以上就是我们采用的其中三种探索策略:人工探索、机器探索和策略匹配。

对于每个兴趣点来说,投放系统每天会探索出一批可能对这个兴趣点感兴趣的用户,然后给他们投放几篇这个兴趣点里面的内容。有的用户一篇没点,就是这个兴趣点的非受众;有的用户偶尔点一两篇,就成为了这个兴趣点的相关用户;而有的用户可能阅读了大部分内容,就成为了这个兴趣点的核心用户。核心用户和相关用户是这个兴趣点沉淀下来的重要资产。那这是不是一锤子买卖呢?核心用户永远就是核心用户,相关用户永远就是相关用户呢?想象一下,如果第一天给一名用户投放了5篇某个兴趣点的内容,这名用户读了4篇,那他就会被系统判定为这个兴趣点的核心用户。投放系统每天除了会给探索用户投放内容,还会持续地给以前沉淀下来的核心用户和相关用户投放内容。如果第二天、第三天持续给这名核心用户投放这个兴趣点里的内容,但这名用户可能一篇都没有点击,我们的系统就会调整他的评分,可能会把他降为这个兴趣点的相关用户甚至非受众。所以用户的身份其实并不是一成不变的,这是一个动态的变化过程。
回顾一下刚刚所讲的内容。兴趣点是按照一定规则聚合的内容,投放系统的目标是为兴趣点找到目标用户,兴趣点刚刚创建的时候,投放系统也不知道这个兴趣点的目标用户有哪些,所以需要去探索。这里介绍了三种投放系统探索新用户的方式:人工探索、机器探索和策略匹配。所谓的探索就是寻找可能对这个兴趣点感兴趣的用户,然后给他们投放内容来验证他们喜欢这个兴趣点的程度,根据程度,我们把用户分成核心用户、相关用户和非受众,我们的目标是找到更多的核心用户和相关用户。
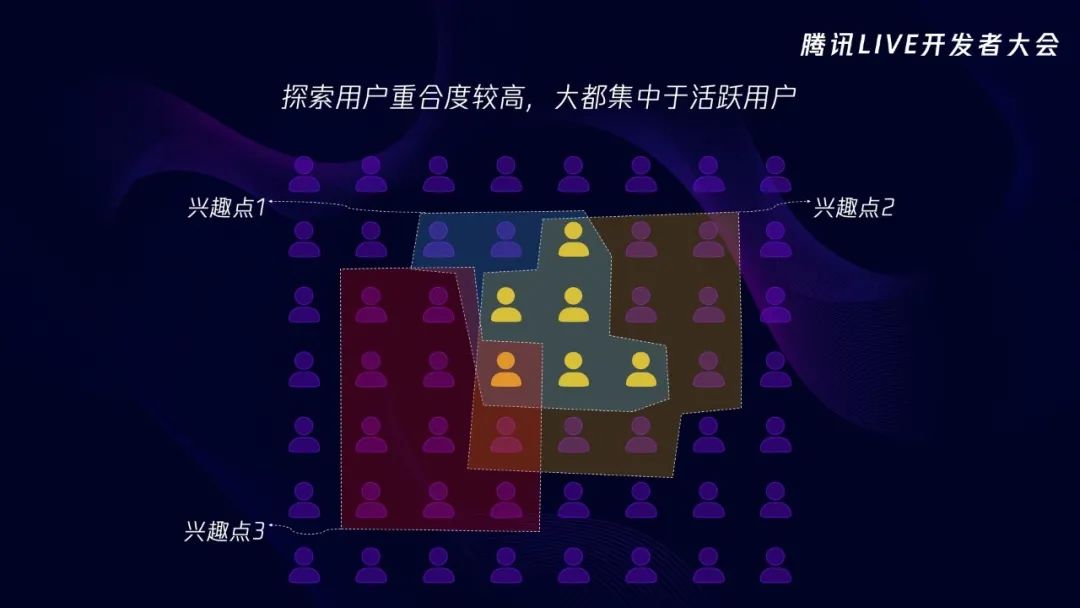
这一切看起来挺完美的,那有没有什么问题呢?假设第一个兴趣点先去探索,探索出了一批用户,第二个兴趣点再去探索,又探索出一批用户,第三个兴趣点还去探索,又探索出一批用户。活跃用户看的内容多,身上积累的画像多,越是可能会被系统判定为探索用户,这样的话,很多兴趣点都会去把活跃用户探索一遍,然后宣称这些用户是这个兴趣点的核心用户或者相关用户。这样会导致各个兴趣点始终围绕着活跃用户探索,对长尾的用户探索远远不够,,不利于增加长尾用户的活跃度和粘性。
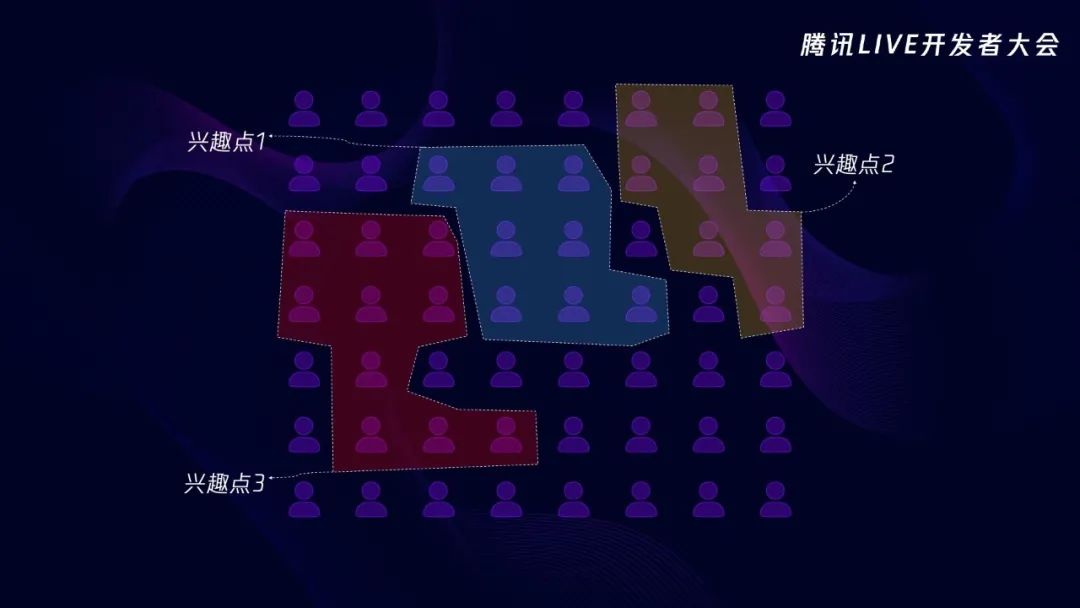
那有什么办法可以解决呢?这里介绍一种我们采用的策略:设置探索用户的互斥性。现在探索的方式就变成了,第一个兴趣点探索了一部分用户,第二个兴趣点探索时需要避开第一个兴趣点探索出的核心用户和相关用户,第三个兴趣点探索时需要避开之前兴趣点探索出的用户。这样就强制后面的兴趣点在探索用户时,能够尽量把探索范围往长尾低活用户偏移。
刚刚我们一直在聊投放系统,那推荐系统和投放系统是什么关系呢?
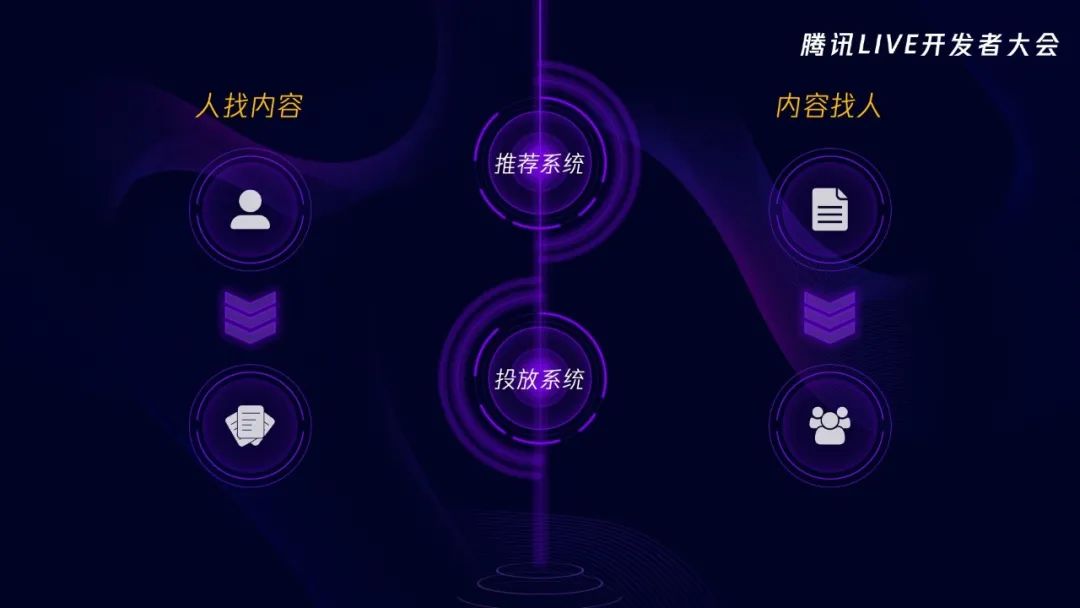
首先,这两个系统有个本质的差别。一个用户打开腾讯看点或者其他的信息流产品,是希望推荐能够给自己推荐几篇感兴趣的内容,这是一个用户主动寻找内容的过程。而投放系统呢,恰好相反,运营同学觉得系统里面有很多优质的长尾内容没有被推荐出去,想要给这些优质内容找到合适的用户群体,所以这是一个内容找人的过程。
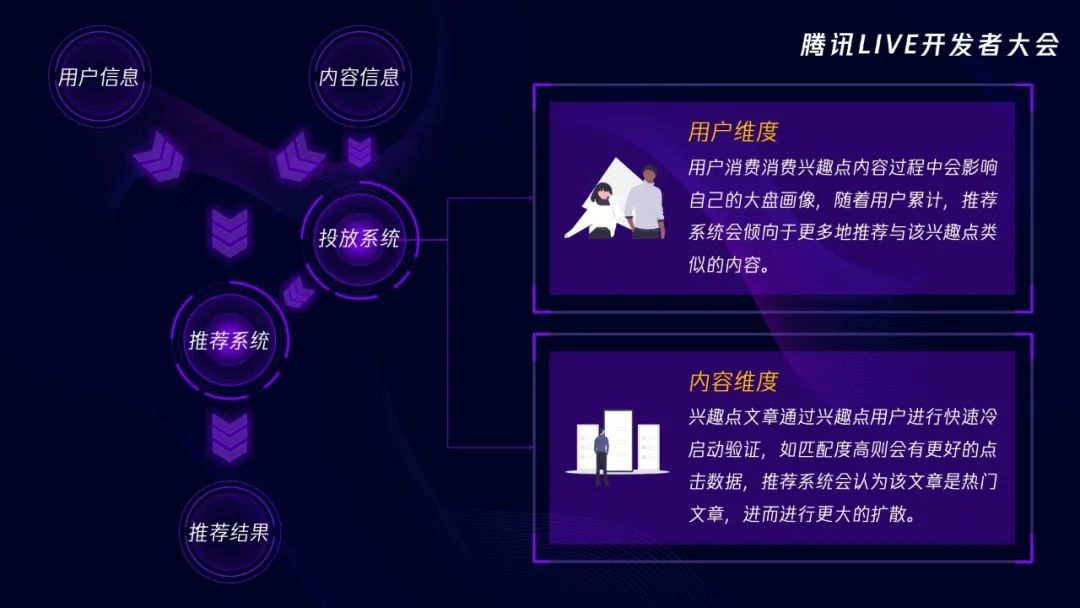
另一方面,投放系统又深刻地影响着推荐系统,我们从两个方面来看。第一方面是用户维度,当用户消费了投放系统投放的内容的时候,他的用户画像就会受到影响,比如投放系统给用户投放了几篇《三十而已》的内容,用户消费了之后,身上的画像会更新,就会带有“三十而已”的标签,这种画像会被推荐系统所采用,所以后面推荐系统也会给这名用户推荐更多的“三十而已”的内容。投放系统影响推荐系统的第二个方面是内容维度,对于一些长尾冷门的内容,我们的运营如果觉得优质的话,会通过投放系统投放出去,如果投放的目标人群比较准确,那么很快就会有很多用户阅读这些内容,推荐系统就会认为这些内容是热门内容,进而进行更大的推广。
好的,我们回到一开始说的问题,因为用户点击了几篇低质庸俗的内容,推荐系统会误以为用户对这类内容感兴趣,然后就会持续地给用户推荐类似的内容,其实用户可能并不是真的感兴趣,相反很可能还很反感,只是忍不住点击了而已,然后就会陷入恶性循环。其中的一种解决方案就是投放系统,运营会精选一些优质的长尾内容,通过投放系统投放给用户,这样就可以打破恶性循环,提高用户的体验和粘性。
讲到这里,关于投放系统的原理部分基本就介绍完了。听起来好处多多,那如何量化投放系统带来的收益呢?互联网人常用的工具就是 A/B 测试。最后的几分钟,我想跟大家分享一下投放系统采用的 A/B 测试所暗含的玄机。
当产品有了新功能之后,我们会选择两拨用户,一拨用户使用最新版本,另一拨用户继续使用旧版本。实验一段时间后,进行实验分析,如果新版本效果好就会发布新版本,旧版本效果好就保持旧版本。实际的 A/B 测试过程非常复杂,刚刚伍老师跟我们做了深入的分享,我也不班门弄斧。我这里主要想跟大家分享一下的是选取样本的方式。
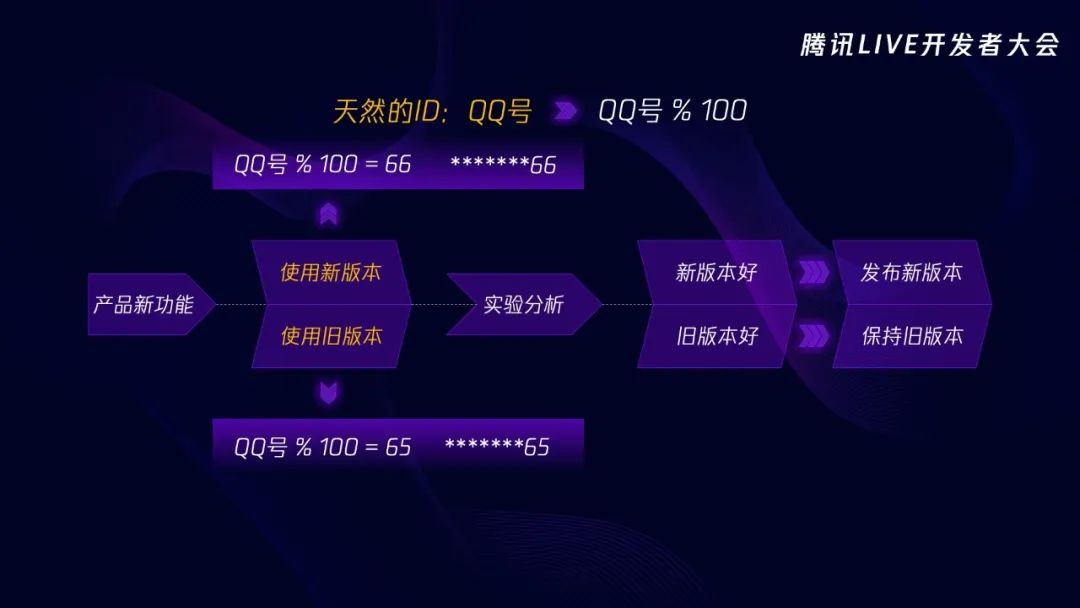
QQ 中有个天然的用户 ID 就是我们的 QQ 号,那如何选取两拨用户呢,一种方式就是对 QQ 号取模,比如模 100。那么根据取模的结果可以将用户随机分成了 100 份,结果为 65 的那拨用户保持旧版本,结果为 66 的那拨用户使用新版本,这两拨用户的 QQ 号分别以 65 结尾和以 66 结尾。这样的做法真的好吗?我们从两方面来看。
第一方面,随机吗?看这两拨用户,一拨以 65 结尾另一拨以 66 结尾,需要注意的是 QQ 中是存在靓号的,而靓号是需要购买的,所以跟普通 QQ 号相比,靓号用户的基本属性、使用活跃度总体都要好。这两拨用户看起来是随机分配的,两者之间应该基本没有差异,但实际上以 66 结尾的用户很多都是靓号,这种内在的差异会影响实验结果,所以直接取模的方式是种伪随机的方式。
第二方面,够用吗?将 QQ号模 100,最多只能进行 99 次 A/B 实验,还有一组是用来对照的。即使模 1000 甚至 10000,那也始终是有限的,所以这种取样的方式并不够用。
既然给 QQ 号取模的方式是伪随机的、不够用的,那应该如何正确地划分用户组?这里介绍一下我们所采用的一种方式,它可以同时满足三方面的需要:分桶均匀、足够分桶和互不干扰,我们分别简单的聊一聊。

第一方面是分桶均匀。我们不会对 QQ 号直接取模,而是先计算 QQ 号的 Hash 值,然后再对 Hash 值取模。这样做的好处是,哈希函数可以充分地打散用户,避免靓号聚集的情况,同时在 QQ 这么大的体量下,我们几乎可以认为对 Hash 结果取模的结果是均匀的,不会出现有的分组用户很多有的分组很少的情况。

第二方面是足够分桶。刚刚我们提到需要对 QQ 号进行哈希处理,但这样也避免不了实验桶被用完的情况,那如何处理呢?我们可以加一个 salt 值,当 99 次实验桶用完的时候,我们可以换一个 salt 值,可以把用户重新打乱再分组。这有点像打牌,第一次所有牌会被均分成 4 份,然后重新洗牌再均分成四份。因为 salt 值是无穷无尽的,所以理论上我们可以得到无穷无尽的实验桶。
第三方面是互不干扰。相比于前两方面,这个比较难以理解,我们简化一下。假设某款产品有 81 名用户,分 9 组进行 A/B 实验,那每组就有 9 名用户,其中我们对 0 号桶的用户进行编号,0 到 8。有没有可能出现这样一种情况,重新打散用户再分组后,上一次同一个分组里面的用户大部分这次又进入了同一个组,好比洗牌没有洗好的话,我这次拿到了一个炸,下一次很可能又拿到了同一个炸。出现这种情况会有什么问题吗?假设分层 1 的1号桶有非常好的正向效果,同时也发现分层 2 的 0‘ 号桶也有非常好的正向效果,那你就说不清 0' 号桶的正向效果是在 0 号桶里面的实验带来的还是 0‘ 号桶里面的实验带来的。那有什么办法可以解决这个问题呢?正交。所谓的正交就是将上一个分层中每个桶的用户打算重新分组后,均匀地分配到下一分层中的每个桶中。这样说有点抽象,我们看 PPT,分层 1 中 0 号桶里面的 9 个用户,在重新打散后,被均匀地分配到了分层 2 的每一个桶里面。同样的,分层 1 中 1 号桶的所有的用户也会被均匀分配到分层 2 的每一个桶里面。

以上就是采样的三个注意点以及我们采用的解决方案。最终的 A/B 测试的实验结果也表明,收到投放内容的那部分用户的数据确实有明显提升。
最后我想以我们腾讯看点线的老大在一次大会上给我们分享的一句话作为结尾:多数人因看见而相信,少数人因相信而看见。自从 Facebook 2006 年创造了信息流这种新型的内容形式,信息流迄今已经发展了 14 年,作为信息流背后的核心引擎 -- 推荐系统也已经进入了发展的深水区,如何为用户提供更好的内容、创造更大的价值,我们一直都在探索,今天跟大家分享的投放系统就是一个探索的产物。因为相信,所以我们可以看到胜利的彼岸。
谢谢大家!
以上是关于腾讯看点投放系统介绍:推荐系统的进化伙伴的主要内容,如果未能解决你的问题,请参考以下文章
腾讯看点基于 Flink 构建万亿数据量下的实时数仓及实时查询系统
腾讯看点基于 Flink 构建万亿数据量下的实时数仓及实时查询系统