机器学习 | 创建自己的电影推荐系统
Posted 数艺学苑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 | 创建自己的电影推荐系统相关的知识,希望对你有一定的参考价值。

前言

“每次看电影,无论电影是什么,这都是魔术。” – 史蒂文·斯皮尔伯格
不论年龄,性别,种族,肤色,每个人都喜欢看电影。所有人都可以通过这种惊人的媒介相互联系。有些人挑选电影时喜欢特定类型的电影,比如科幻片、惊悚片、爱情片等。有些人则更关注于主角和导演。我们考虑所有因素时很难概括一部电影并说每个人都喜欢它。尽管如此,仍然可以为相似用户推荐其可能喜欢的电影。
在这里,我们要做的电影推荐系统开始发挥作用,主要是从电影、观众以及其交互行为中提取信息。接下来,让我们直接进入推荐系统的基础吧。
什么是推荐系统
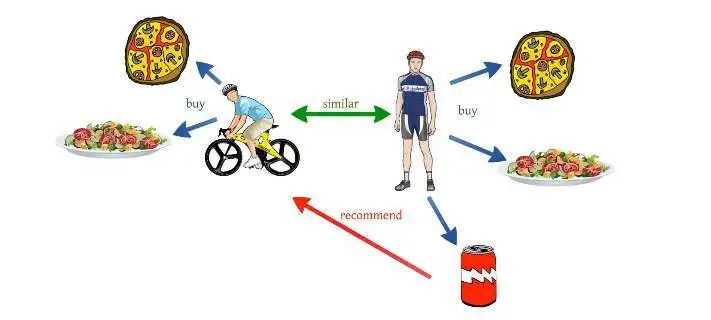
简言之,推荐系统是一个过滤程序,其主要目标是预测用户对特定领域的项目“评分”或“偏好”。现在我们以电影为栗子,主要重点是仅过滤和预测用户在给定有关数据的情况下用户更喜欢的电影。
推荐系统的分类
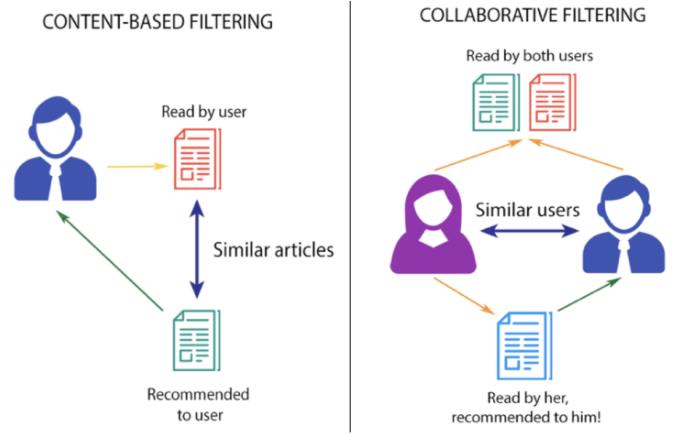
基于内容的推荐:
顾名思义,它是利用项目的属性来进行推荐,比如电影的风格、类别等,不需要构建用户项目矩阵。它是建立在项目的内容信息上作出推荐的,不需要依据用户对项目的评分,更多地需要用机器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。
例如,如果用户喜欢《威望》等电影,那么我们可以向他推荐《克里斯蒂安·贝尔》的电影或类型为《惊悚》的电影,甚至是《克里斯托弗·诺兰》导演的电影。推荐系统检查用户过去的喜好并找到电影“ The Prestige”,然后尝试使用数据库中可用的信息(例如主角,导演,电影类型,制作公司,等,并根据此信息找到与“ The Prestige”相似的电影。
基于协同过滤的推荐:
顾名思义,它是通过集体智慧的力量来进行工作,过滤掉那些用户不感兴趣的项目。协同过滤是基于这样的假设:为特定用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用户。
它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐,通常需要用到UI矩阵的信息。协同过滤推荐又可以根据是否运用机器学习的思想进一步划分为基于内存的协同过滤推荐(Memory-based CF)和基于模型的协同过滤推荐(Model-based CF)。
基于用户的协同过滤:
这里的基本思想是找到具有与用户“ A”相似的过去偏好模式的用户,然后推荐“ A”尚未遇到的相似用户喜欢的他或她的商品。这是通过根据每个任务将每个用户已评分/观看/喜欢/点击的项目矩阵制成矩阵,然后计算用户之间的相似度得分,并最终推荐相关用户不知道但用户知道的项目来实现的和他/她相似,并且喜欢它。
例如,如果用户“ A”喜欢“蝙蝠侠开始”,“正义联盟”和“复仇者联盟”,而用户“ B”喜欢“蝙蝠侠开始”,“正义联盟”和“雷神”,那么他们有相似的兴趣,因为我们知道这些电影属于超级英雄类型。因此,用户“ A”想要“ Thor”而用户“ B”想要“复仇者联盟”的可能性很高。
基于项目的协同过滤:
在这种情况下,该概念是查找相似的电影而不是相似的用户,然后推荐与“ A”过去的喜好相似的电影。这是通过查找同一用户被评分/查看/喜欢/点击的每对项目,然后测量所有被评分/查看/喜欢/点击的用户中所有被评分/查看/喜欢/点击的项目之间的相似性来执行的,并且最后根据相似度分数推荐它们。
例如,在这里,我们拍摄了2部电影“ A”和“ B”,并检查了所有对这部电影都进行过评分的用户的评分,并根据这些评分的相似度,以及根据对这两部电影进行评分的用户的评分相似度,我们找到类似的电影。因此,如果大多数普通用户对“ A”和“ B”的评价都差不多,那么“ A”和“ B”的可能性很高,因此,如果有人看过并喜欢“ A”,就应该推荐“ B”,反之亦然。
开始编写自己的电影推荐系统吧
当用户使用本推荐系统搜索电影时,我们将推荐前十名相似的电影。本系统使用基于项目的协同过滤算法,所使用的数据集是movielens-small数据集。
启动并运行数据:
首先,我们需要导入将在电影推荐系统中使用的库。另外,我们将通过添加CSV文件的路径来导入数据集。
import pandas as pdimport numpy as npfrom scipy.sparse import csr_matrixfrom sklearn.neighbors import NearestNeighborsimport matplotlib.pyplot as pltimport seaborn as snsmovies = pd.read_csv("../input/movie-lens-small-latest-dataset/movies.csv")ratings = pd.read_csv("../input/movie-lens-small-latest-dataset/ratings.csv")
现在,我们已经添加了数据,让我们使用dataframe.head()命令查看文件,以打印数据集的前5行。
让我们看一下电影数据集:
movies.head()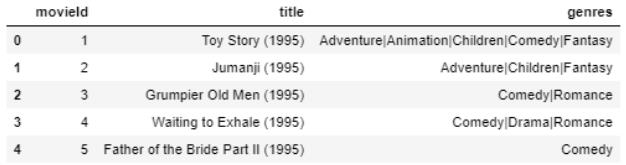
ratings.head()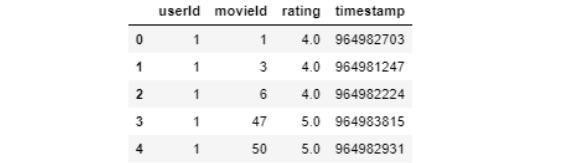
我们可以看到userId1已经看过movieId1和3,并且对他们两个的评分都为4.0,但没有对movieId2进行评分。因此,我们将创建一个新的数据框,其中每一列将代表每个唯一的userId,每一行代表每个唯一的movieId。
final_dataset = ratings.pivot(index='movieId',columns='userId',values='rating')final_dataset.head()
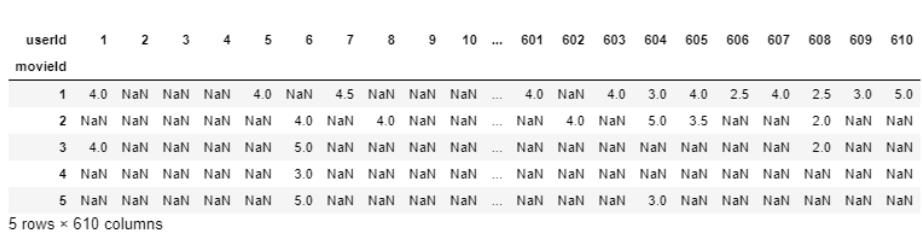
现在,更容易解释userId1已对movieId1和3 4进行了评分,但没有对movieId2、4、5进行分级(因此它们表示为NaN),因此缺少其分级数据。
让我们进行改进,将NaN赋值为0,使算法可理解,并使数据更加醒目。
final_dataset.fillna(0,inplace=True)final_dataset.head()
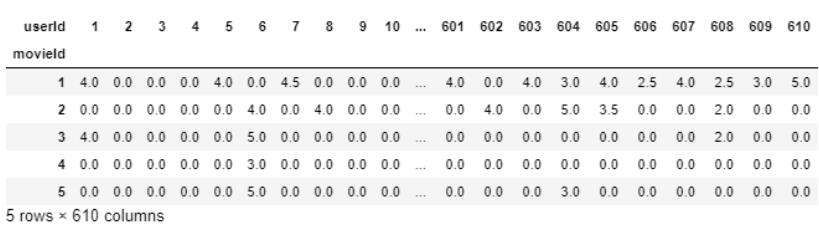
消除数据中的噪音:
在现实世界中,评分率非常稀疏,比如B站就通过硬币、收藏、转发来对视频打上相应的标签,而往往更多的用户是白嫖党比如我,因此需要将某些参考价值较小的数据消除掉。而我们要使用的数据大多是从非常受欢迎的电影和高度参与的用户那里收集的。因此不应考虑仅对少数电影评分的用户。
因此,考虑到所有这些因素以及一些反复试验之后,我们将通过为最终数据集添加一些过滤器来减少噪声。
要使电影合格,至少应有10位用户对电影进行投票。
为了使用户合格,该用户应至少投票50部电影。
创建过滤器:
汇总已投票的用户数量和电影数量。
no_user_voted = ratings.groupby('movieId')['rating'].agg('count')no_movies_voted = ratings.groupby('userId')['rating'].agg('count')
可视化以10为阈值投票的用户数量。
f,ax = plt.subplots(1,1,figsize=(16,4))# ratings['rating'].plot(kind='hist')plt.scatter(no_user_voted.index,no_user_voted,color='mediumseagreen')plt.axhline(y=10,color='r')plt.xlabel('MovieId')plt.ylabel('No. of users voted')plt.show()
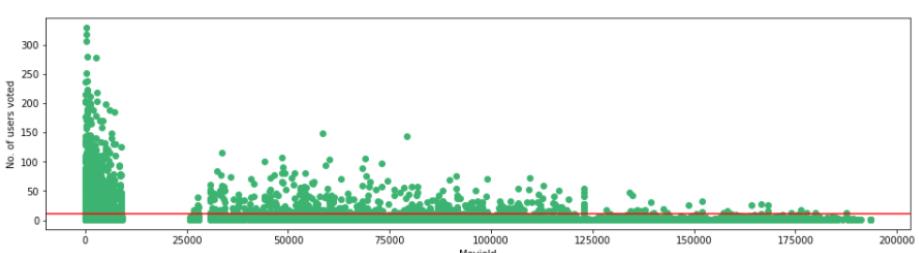
根据阈值设置进行必要的修改。
final_dataset = final_dataset.loc[no_user_voted[no_user_voted > 10].index,:]让我们以50的阈值可视化每个用户的投票数。
f,ax = plt.subplots(1,1,figsize=(16,4))plt.scatter(no_movies_voted.index,no_movies_voted,color='mediumseagreen')plt.axhline(y=50,color='r')plt.xlabel('UserId')plt.ylabel('No. of votes by user')plt.show()
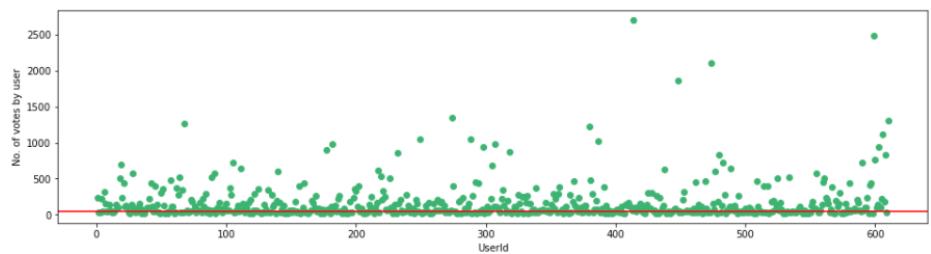
根据阈值设置进行必要的修改。
final_dataset=final_dataset.loc[:,no_movies_voted[no_movies_voted > 50].index]final_dataset
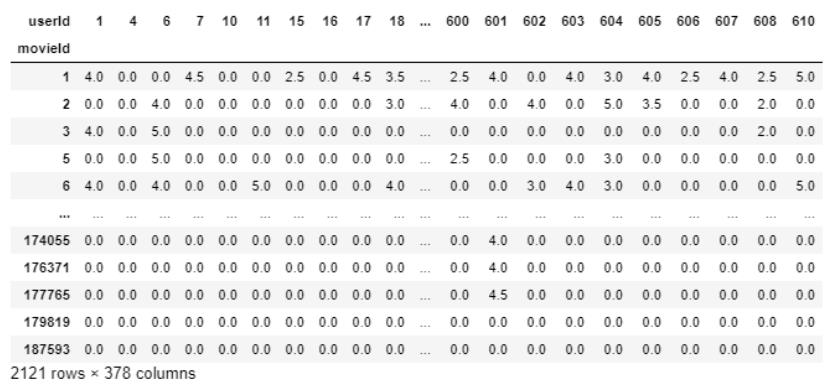
消除稀疏:
我们的final_dataset的尺寸为2121 * 378,其中大多数值都是稀疏的。我们仅使用一个小数据集,但对于具有超过100000个功能的电影镜头的原始大数据集,当将其输入模型时,我们的系统可能会用尽计算资源。为了减少稀疏性,我们使用scipy库中的csr_matrix函数。
我将举例说明它的工作方式:
sample = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]])sparsity = 1.0 - ( np.count_nonzero(sample) / float(sample.size) )print(sparsity)

csr_sample = csr_matrix(sample)print(csr_sample)

可以看到,csr_sample中没有稀疏值,并且值被分配为行索引和列索引。对于第0行和第2列,值为3。
将csr_matrix方法应用于数据集:
csr_data = csr_matrix(final_dataset.values)final_dataset.reset_index(inplace=True)
制作电影推荐系统模型:
我们将使用KNN算法来计算与余弦距离度量的相似度,该相似度非常快并且比皮尔逊系数更可取。
knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=20, n_jobs=-1)knn.fit(csr_data)
工作原理很简单。我们首先检查电影名称输入是否在数据库中,如果是,则使用我们的推荐系统查找相似的电影,并根据相似度距离对它们进行排序,并仅输出前10部电影以及与输入电影的相似度距离。
def get_movie_recommendation(movie_name):n_movies_to_reccomend = 10movie_list = movies[movies['title'].str.contains(movie_name)]if len(movie_list):movie_idx= movie_list.iloc[0]['movieId']movie_idx = final_dataset[final_dataset['movieId'] == movie_idx].index[0]distances , indices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1)rec_movie_indices = sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda x: x[1])[:0:-1]recommend_frame = []for val in rec_movie_indices:movie_idx = final_dataset.iloc[val[0]]['movieId']idx = movies[movies['movieId'] == movie_idx].indexrecommend_frame.append({'Title':movies.iloc[idx]['title'].values[0],'Distance':val[1]})df = pd.DataFrame(recommend_frame,index=range(1,n_movies_to_reccomend+1))return dfelse:return "No movies found. Please check your input"
最后,让我们推荐一些电影!
get_movie_recommendation('Iron Man')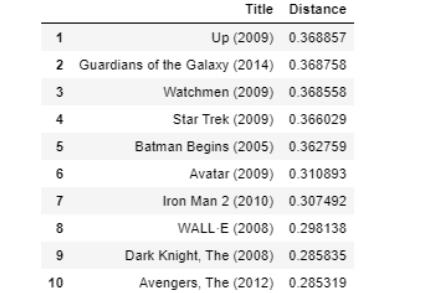
我个人认为效果不错。就像输入电影“钢铁侠”一样,顶部的所有电影都是超级英雄或动画电影,这些可能都是铁汁们的理想选择。
结语:
由此可见,通过以上的步骤就可以简单快速的推荐出相关电影啦,小伙伴们,你们学废了吗?


指 导 老 师


参考资料:
https://www.analyticsvidhya.com/blog/2020/11/create-your-own-movie-movie-recommendation-system/
https://mp.weixin.qq.com/s/o00K11aFdZXDOxClGtGiog
以上是关于机器学习 | 创建自己的电影推荐系统的主要内容,如果未能解决你的问题,请参考以下文章