推荐系统之Bloom Filter
Posted 育学园技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统之Bloom Filter相关的知识,希望对你有一定的参考价值。
背景
推荐系统中的经常出现的情况是,可能在召回的过程中将已经推给过用户的数据召回过来,如果直接推送给用户的话,会引起用户的反感,如何一好的过滤系统也是推荐系统设计的一部分。网上一搜索的话很多人就会说用Bloom Filter,但是你是真正了解Bloom Filter?直接使用Bloom Filter 就能解决问题,其实不然,要充分考虑到Bloom Filter 的特性和应用场景才能够用好。
为什么要Bloom Filter
从推荐的角度来说,要推荐出的东西,从程序员的角度来讲,最直接的方式是:将所有推出的物品编码,用一个bit位表示,推出去设置为1,没有推出去的话为0。这个想法看上去很不错,但是实际情况是物品是不断增加的,导致这个串变的不可控,另外还有有些物品删除了,还会占用对应的位置,如果要回收的话非常麻烦。
这有什么了不起的,我们还有招数,你不是说串长度不可控嘛,不用按照顺序编码一个位来对应,我们直接采用一个hash函数映射到一个固定长度的串上不久可以了,但是,在物品n非常大的情况下,冲突怎么解决,这个解决方案也不优雅。
bloom在1970年创造性的提出了使用多个hash函数映射到一个串上,2019年新的发表在Neural Computing and Applications 的一篇Autoscaling Bloom filter: controlling trade-off between true and false positives 的论文,针对Bloom Filter进行了构建后的可以更改hash函数的改进,文中很重要的一点,作者认为:多个hash函数映射到一个串上的设计像一个单层的神经网络,通过这个网络将对应的输入映射到一个空间上,所以说牛人的的角度和视角就是不一样。
Bloom Filter 算法
1、原理
bloom filter的过程其实是使用多个hash函数映射到一个空间上,每个hash函数出的结果对应记录的位置为1

图1
插入过程
本例中选择2个hash函数来讨论,可以看到x1通过hash函数分别映射到0和4的位置,x2通过hash函数映射到4和8的位置,对应的位置分别设置为1
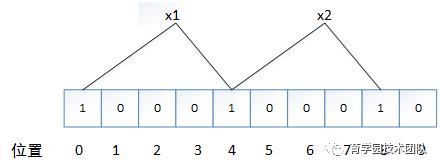
图2
你会发现一个问题,位置4二个数都映射过去,在这个位置上是有冲突的,但是因为x1另外一位映射在0,x2映射在8,整体上看是没有冲突的。
查找过程
查找的过程非常简单,以图2举例:x1通过函数映射为k1和k2,只需要判断对应的位置是否为1即可
如果全部为1,说明x1包含在这个bloom filter中
如果有一个位置不为1,说明x1包不含在这个bloom filter中
删除过程
从图2中删除x1,能做的方法就是将和x2不公用的0设置为0,但是这是简单的情况,复杂的情况是不可以的,比如下图:
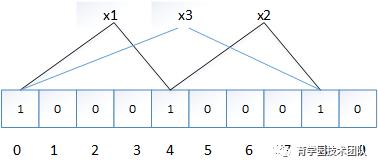
图3
2、评价指标
bloom filter不是一个严格意义上的完全没有错误的过滤方案,我们必须形式的针对这个映射过程进行评价,bloom filter的主要参数为:
Bloom Filter中的元素数目: n
Bloom Filter误判率: P(true)
BitArray数组的大小: m
Hash Function的数目: k
误判率 P(true)

从上式可以看出,当BitArray数组的大小m增大 或 欲插入Bloom Filter中的元素数目n 减小时,均可以使得误判率P(true)下降
Hash Function的数目 k
前文已经看到Hash Function数目k的增加可以减小误判率P(true),但是随着Hash Function数目k的继续增加,反而会使误判率P(true)上升,即误判率是一个关于Hash Function数目k的凸函数。所以当k在极值点时,此时误判率即为最小值,求解如下:

可以利用上式的结果,通过m和n来确定最优的Hash Function数目k
BitArray数组的大小 m


可以利用上式的结果,通过P(true)和n来确定最优的BitArray数组的大小 m
Bloom Filter的改进
bloom filter的改进主要包括二个方面:
支持删除
支持动态变化,主要把包括存储空间的缩放,hash函数在构建后更改不影响整体的效果
我们以下讨论的更改主要讨论支持删除的操作
1、Counting bloom filter(CBF)
Counting bloom filter的思想2010年发表在:Summary cache a scalable wide-area Web cache sharing protocol,Counting bloom filter和bloom filter的区别在于:对应每个hash函数出来的位置在原有的数上+1,图3的数据添加进去的情形如下:

Delte(x)就定义为删除x ,做插入的逆向操作,将对应的位置减1,举例:删除x1后的结果:

删除的时候将对应hash的位置减1,删除x2类同,这个改变后的结果就是判断是否包括在CBF定义发生了变化:
Query(x)定义为根据K个hash函数后的位置,如果每个位置上都>=1,那么确定CBF包含这个值
评价:
原来每个位置为bit来表示,现在换做数字后,存储空间要求大了n倍,当然n的取值可以优化,可以在错误容忍和存储空间中做一个平衡
2、The Deletable Bloom filter (DlBF)
改进的思想其实很简单,将bloom filter的空间段:
冲突区域记录段
实际数据记录段
下面拿官方文档举例说明;

图6
数据分段:
m取32,其中r=4也就是将32个bit中,取4个bit来记录各个区域的冲突(冲突区域段),剩下的28个字节,(m-r)/r=m'/r也就是(32-4)/4=7,也就是数据部分的分段7为一个长度。
当前插入x,y,z后,在第2个区域和第4个区域后有冲突,冲突区域段的1和3位置设置为1
结构变化后的操作变化
插入数据Insert(x):如果插入的数据映射到N个数据记录段,如果对应的位置有冲突,需要在冲突区域将对应的区域设置为1
查询数据是否包含Query(x):保持老的流程不变,对应位置全为1就为包含
删除数据Remove(x):将x映射到各个数据段,如果映射到的数据段为无冲突段,直接将对应无冲突段为1的位置设置为0即可,比如:当前例子中删除x,只需要将第1个数据段中的1设置为0就使数据失效
评价:
直观的评价感觉很不靠谱,论文[3]给出的结论是在选择合适的r的情况下,中等数据量正确的删除率还是可以的,实际上在r的选择上是个学问,极端的情况下是

图7
其实相当于每个位记录了一下冲突,对应改进需要有一个形式化的描述和计算,如下:
删除的概率:

其中pc=1-p0-p1,其中p0为一个单元设置为0的概率,1为单元设置为1的概率,具体原理见论文[3]
无效结果概率:
因为只是减少了r位参与数据的落地,也就是传统的bloom filter(bf)的无效结果公式的一个变化,如下:

当前无效结果的概率其实就是当前公式少了r位的概率
3、小结
我们讨论的二种解决方案是否能解决删除的问题,实际上不能100%保证,下面的这种情况就不可:

图8
本身出现这种情况下,使用CBF和DIBF都无法处理,但是你可以想一想,如果hash函数选择的好,并且足够多,是能大概率的避免这类问题的。
Bloom Filter的改进
1、总结
推荐的业务场景确定要过滤的数据包括二类
用户点击过的不要给我推荐
用户近期看过的不要给我推荐
从需求的角度来说,一般情况下看过的不给推荐很正常,用户看过的量级也不会很大,我们年轻人不讲武德,啪的一下直接上一个Bloom filter即可,确实能解决问题,但是用户近期看过的不给我推荐这就困难了,直接上个Bloom filter就犯难了,因为
如果要避免误判断率,在n很大的情况下,m需要很大,这需要很大的存储空间啊
如果m取的很小,那么误判率很高
怎么办呢?其实要仔细分析需求,要推出的n很大,但是在一段时间内用户看到的n'还是不大的,在n对应的映射空间冲突,但是在n'的空间不大,所以,直接使用一个bloom filter也可以。因为有个时间区间的问题,那么涉及到每天的bloom filter重新计算的问题,在大数据量的情况下这也非常麻烦,那我们采用时间差上的双缓存,假设当前最近一天和今天看过的数据不能看,以今天26日进行举例:
用户近期不推荐的过滤策略如下:
最近bloom filter A(简称BF_a)保存26当前和25日已经看过的hash,bloom filter N(简称BF_b)保存26日看过的hash,当天看过的数据同时写入BF_a和BF_b
26日当天过滤用户已经看过的消息使用BF_a过滤
到下一天27日,BF_a=BF_b,新建一个BF_b,当天看过的数据同时写入BF_a和BF_b
27日当天过滤用户已经看过的消息使用BF_a过滤
重复上面的过程
假设用户点击过的不要给我推荐对应的bloom filter为BF_read,那么整体的流程可以从这几个层次描述:
过滤:使用BF_read和BF_a
用户点击写入BF_user
服务端推送同时写入BF_a和BF_b
切换一天,将BF_a=BF_b,重建一个新的BF_b
结构图如下:
图9
2、小结
推荐系统中如果考虑服务端推荐出的物品是否在app端曝光,虽然推荐出去了,但是还没有曝光的商品是否还可以再次推荐出去,结构上要更加复杂一些,但是一般情况下图9的结构基本够用
工程化方面要考虑bloom filter hash的存储,当然你可以一下子想到redis,如果value比较大的话放在redis其实不是特别合适的,可以考虑基于rocketdb的pika, ssdb,hbase,主要考虑到具体实际使用的并发量,说白了技术就是解决现实问题的,不是越高级越好
总结
bloom Filter从1970年发明以来作为一种算法,出现了各种改进和变体,是非常非常多,应用到:过滤、缓冲、权限验证等等各个方面,虽然推荐过滤中使用了一下,下但是还是远远了解的不够,就像算法中的排序,随便举出一个经典的算法,各种改进有很多,那种场景下使用那种改进的方法是个非常考虑技术能力的事情,所以,对技术人员来说,精通一个东西任重而道远,我们有空再分析下开源的bloom Filter以及常用的变体的各种实现。
参考文档
[1] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Commun. ACM, vol. 13, no. 7, pp. 422–426, 1970.
[2]L. Fan, P. Cao, J. Almeida, and A. Z. Broder, “Summary cache: a scalable wide-area web cache sharing protocol,” IEEE/ACM Trans. Netw., vol. 8,no. 3, pp. 281–293, 2000.
[3]C. E. Rothenberg, C. A. B. Macapuna, F. L. Verdi and M. F. Magalhães, "The deletable Bloom filter: a new member of the Bloom family," in IEEE Communications Letters, vol. 14, no. 6, pp. 557-559, June 2010, doi: 10.1109/LCOMM.2010.06.100344.
[4]Tim Kaler,Cache Efficient Bloom Filters for Shared Memory Machines,2013,Kaler2013CacheEB
[5]程序员干货铺,https://zhuanlan.zhihu.com/p/140545941,2020,知乎
以上是关于推荐系统之Bloom Filter的主要内容,如果未能解决你的问题,请参考以下文章