一文梳理工业界大规模推荐系统Serving架构分析
Posted 深度传送门
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文梳理工业界大规模推荐系统Serving架构分析相关的知识,希望对你有一定的参考价值。
作者 | Peter潘
知乎 | https://zhuanlan.zhihu.com/p/335116835
整理 | 深度传送门
在“一切”算法皆可被深度模型替换的大背景下,模型的在线服务变得越来越重要。随着在不同项目中工程经验的积累,渐渐发现问题的表象、需求常常显得非常的复杂多样,而背后的真像却不容易搞清楚。
从技术领域分,有CV,NLP,语音,排序等。从部署场景分,有服务端,嵌入式设备,浏览器(js)等。另外还有联邦式模型部署,雾计算式协同计算部署等各种可能的方式。为了避免打字太多,这里主要讨论最近关注的推荐系统的各种Serving架构。
经典Serving架构
下面贴了两个Serving系统,分别是NSDI 2017年发表的Clipper和广泛使用的TF Serving接口。经典的Serving架构通常包含以下设计。
1. 独立的服务化部署。独立的服务化部署提供了灵活的扩所容能力。解偶了复杂的上游系统。可以比较独立的开发,运营。
2. 统一的RPC/Http接口,搭配插件化的框架。统一抽象的接口基本能适配主流场景的Tensor-In/Tensor-Out需求。同时又能统一抽象封装不同的计算框架,满足用户使用TensorFlow, Pytorch, TensorRT等不同框架的需求。
在无量Serving系统的设计时也基本参考了这套设计思路。同时融合了K8S里面声明式配置,控制器模式等改进,希望能够更好的适配云上部署。但是。。。问题没这么简单。

推荐系统Serving
在大规模推荐场景,整个系统呈现一种漏斗架构。不同阶段的数据量,计算量,精确度需求都不一样,是一个绝佳的思考系统设计trade-off的场景。很多时候需要考虑易用性、性能、成本和业务场景,综合作出判断。
召回
召回面向的是百万级,甚至亿级的候选item池。如果每次用户请求都对所有item进行精细计算打分,在当前成本和算力情况下是基本是不现实的。
一般会通过通过聚类和索引的方法分割搜索空间,减少计算量。比如基于KNN的聚类,基于NSHW的图索引,基于局部敏感Hash的索引,或者是基于树结构的索引。
召回Serving的关键词是:索引,局部,海量。
召回的Serving架构有如下特点:
1. 预计算
通过图,树或者其他一些聚类算法,提前切分搜索空间,建立索引。这样在每次进行匹配的时候,只需要处理一小部分候选集。
2. 计算跟随数据。
因为数据的规模很大(千万),难以挪动,而计算的量比较小(比如余弦,内积计算),所以匹配计算一般是在数据所在的机器上进行的。类似OLAP引擎的MPP架构,或者是MapReduce架构,数据在哪里,计算就在哪里。在多个数据节点上完成匹配和过滤。
基于以上两点,召回模型的Serving架构一般如下:
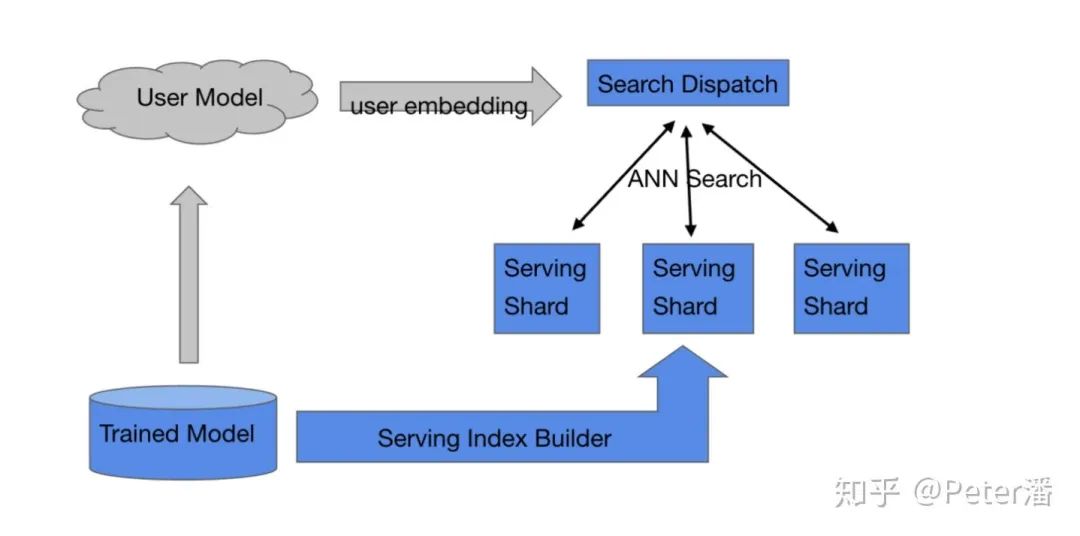
训练后的模型一般是拆分上线的。user侧的embedding是在线实时计算的(比如考虑用户当时的浏览历史),然后user embedding会用来匹配item。关于这部分模型的Serving先不讨论。
海量item特征的上线一般需要经过一个索引构建的过程。比如基于item向量做聚类,产生N个聚类中心,这样ANN Search只需要关心一部分聚类中心就可以了。也可以基于NSHW的方法构建图索引,这样能够更快速的找到最“匹配”的item向量。
索引建完之后需要一个sharding和replication的过程。目标是尽量能够将workload在多个物理节点上进行balance,同时做到fault-tolerance和scale-out。这里面可能涉及到扩所容,动态增删等高级能力,需要通过分布式一致性协议处理,本文不深入讨论。
对于每个请求,需要并发的调用candidate shards进行匹配,然后将匹配后的结果组装形成召回结果。
经过召回后还有数千,甚至上万个候选item。通常需要对所有item进行排序。这个阶段有两个选择:
1. 直接使用最精确的模型对所有item排序,一步到位。使用先进的硬件、付出比较昂贵的计算成本,是有可能做得到的。
2. 分成粗排和精排两个阶段。先对这些item再进行一轮粗筛,比如过滤90%的item,同时确保剩下的10%的item“大致”包括了所有item中最好的那一部分,后续再进行精排。
通常需要具体实验,再结合业务本身的场景规模,成本预算,线上性能等因素,综合考虑后选择。本文关注Serving架构,不详细讨论这两种选择。
粗排
假如选择了粗排,那么就必须确保粗排是真的能够“相对快速”的对item进行“相对准确”的过滤。这里“相对”是和精排对比。
粗排模型Serving必须比精排快很多,否则就没有存在的意义了。另外粗排的Serving结果不能和精排差距太大。粗排选出来的item(比如前10%)在精排看来应该也是相对靠前的(比如前15%)。假如粗排结果在精排看来是随机的,那还不如减少召回量,直接使用精排。
粗排Serving的关键是:相对精排更加快速,和精排准确度差距不是太大。
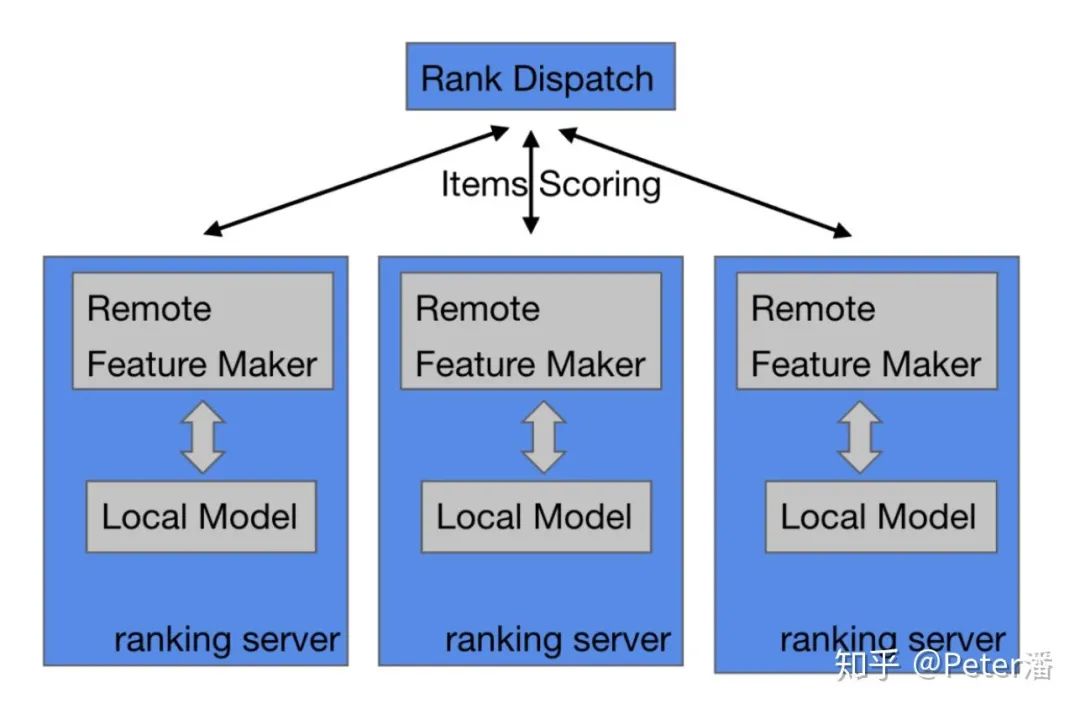
基于以上考虑。粗排的模型常常是耦合在业务系统内部。换句话说Feature Maker和模型计算是在一台机器上完成的。更具体的:
1. Rank Dispatch获得了所有召回的item id后,分发给各个Ranking服务器。
2. Ranking服务器Feature Maker从线上存储服务获得需要的相关特征和Embedding,拼接出模型的完整输入。
3. 调用本地的模型计算框架库,完成模型打分计算。
如果Feature Maker不从中心化的存储服务获得特征,还有另一个变种如下图:提前把Item和它们的特征做Sharding,然后把召回的item根据item sharding路由,分发到各个Item Shard上去做特征拼接和模型计算。是不是跟上文说的召回架构,MPP架构非常像,或者是说Share-Nothing架构?
和召回的区别是,1. 粗排被计算的item是提前知道的,2. 也是全部都需要计算的(不是局部索引)。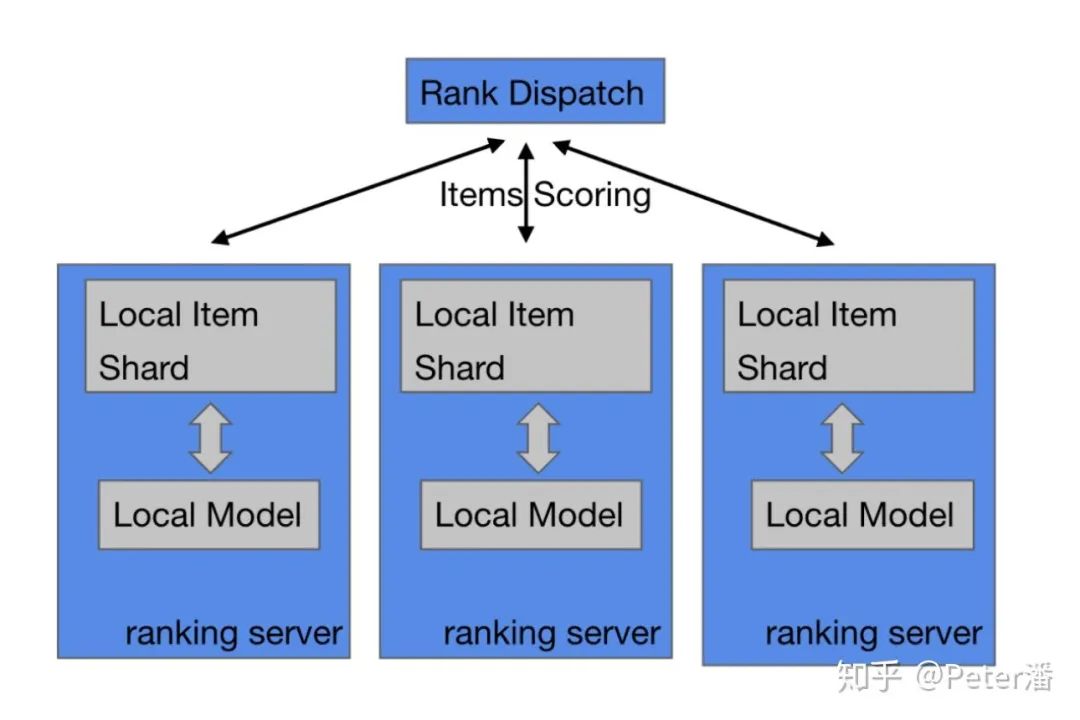
粗排使用经典Serving架构理论上是可以的,但是和上图中的本地化架构相比,经典架构有个明显劣势:Ranking Server需要通过RPC调用远程Serving服务,如果优化不够极致,会导致“比较显著”的额外开销。
1. 推荐的模型输入有大量稀疏特征,每个item会有成百上千个feature。RPC的请求的构造成本,序列化和反序列化成本都会比较高,需要进行非常定制化的设计来优化。Serving服务剩下用来做计算的时间预算就很少了。导致发每个Serving容器的batch size需要减少(比如本地计算是30, Serving容器是15)。比如:bs=30, iteam feature=1000, 800qps, 主调带宽可能到200~300MB/s,视优化情况有不同。通过压缩手段,理想情况能控制在100MB/s附近。如果优化不好可能成为性能瓶颈。
2. 几千个item需要被切分到上百个batch,同时发送到Serving容器上同时打分。超大扇出且高QPS的情况下,必然会有慢机。这样延迟预算要按P99来算。进而又压缩batch size,进而导致需要被切分出更多的请求,陷入恶性循环。
精排
假如经过了粗排阶段对成千上万个item进行过滤,最终还会剩下数百个item。上文提到粗排的精确度相对精排还是又差距的。所以粗排的结果还有进一步的优化空间(在计算和成本可以承受的前提下)。
所以精排Serving的关键词是:精确,少量。
下图的架构就和前文的经典Serving架构就非常相似了。Ranking的业务逻辑和底层平台Serving逻辑做了比较好的解偶。
1. 精排模型的计算量比较大,所以相对而言,远程调用和请求数据传输的额外开销占比较少。
2. 精排模型需要排序的item个数较少,所以需要被拆分的并行请求包也会比较少,慢机延迟的问题不是特别严重。
3. 精排模型的体积也比较大,可以达到几百GB到TB,更适合拆分到独立的服务上解决分布式存储、运营部署等相关问题。
综上,数据被发送到计算节点上,在精排场景是比较合理的。这和召回的Serving架构正好是相反的。
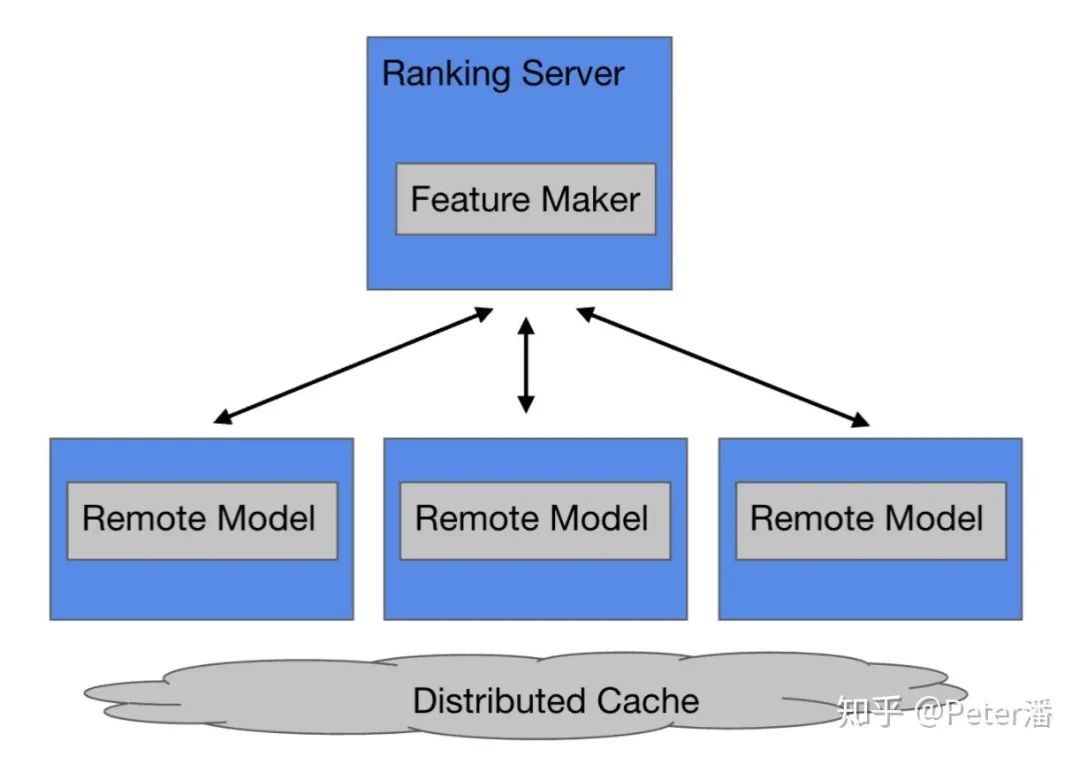
中台视角
复杂系统的架构除了考虑性能、成本这些因素,还要考虑团队分工,运营成本等问题。
下图一种很有争议的方案。绿色的是业务系统。蓝色的中台Serving系统。如果将DNN嵌入到业务系统里面,可以将DNN Inference计算进行本地化。Feature Maker生成样本后可以直接计算。和经典架构相比,省去了样本通过RPC发送给远程服务。通过本地Cache可以命中90%的远程Embedding请求。理论上是一种比较高性能的方案。
然而,假如中台支持的业务场景达到几十个,甚至上百个,部署和运营问题会变得比较复杂。1. Dnn Lib的升级需要和上百个业务方沟通协调,需要重新编译发布。2. 由于同一个模型拆分到不同团队管理,Serving Controller很难自动化的进行新服务部署,模型上线,扩缩容。
从长期趋势上看,1. 数据中心网络速度发展非常迅速,网络开销逐渐下降。2. DNN模型变得更加复杂,迭代更加敏捷,计算量更大。考虑到以上两点,我们更倾向于通过经典架构来解决精排模型的Serving问题。
变数
上面介绍的只是常见的几个架构。不同业务场景间的差异很大,没有可以自动套用的最佳Serving方案。更多是知己知彼,随机应变。举几个例子。
1. 长视频的item候选集可能要比短视频少几个数量级。图文和视频的特征规模可能也不太一样。
2. 大业务的主场景对性能和成本的要求更高,倾向于舍弃一些灵活性。而小场景更关注的是算法人员快速应用。
3. 有些业务更倾向于自己定制Serving,投入较大的工程团队。有些业务倾向于关注业务效果和算法,而将工程交给中台团队。
4. 不同场景处在很不同的阶段。有些场景没有粗排,有些场景使用了简单的模型和复杂的特征,有些场景使用了复杂的模型和较少的特征。
Serving系统优化
Serving系统在代码实现的微观层面有非常大的优化空间。优化的好的Serving系统可以有几倍的性能提升和成本优化空间,进而影响最终的架构选型。比如
1. Embedding的计算可以是a. 拆分成Emb拉取,矩阵构造,Tensor计算等细粒度算子。b.也可以通过配置化的融合算子一步完成。两者有数倍的性能差距
2. Serving服务调用RPC接口可以是a. 多层嵌套Request { repeated Sample { repeated FeatureGroup { map Feature { repeated float }}}; b. 也可以是拍平后的bytes&index,比如Request { bytes data, list FeatureGroupOffset, list FeatureOffset }。前者有相对结构化且易理解,后者有更高的序列化/反序列化效率和更高的计算效率。
3. 另外在线程池调参,框架优化,RPC数据压缩等方面还有许多可以Profile和优化的地方。
GPU Serving
前面提到,在大量item打分时,需要将item分成多个batch。大量batch远程调用Serving服务时会有显著的额外开销。额外开销本身不产生价值,可是压缩了模型计算的时间预算。模型计算时间预算压缩导致每个batch需要更小才能完成目标,导致了更多更小的batch,导致更多的额外开销。如此陷入恶性循环。
破局需要通过增大batch size来减少batch分片的个数,进而减少额外开销。GPU非常擅长大规模并行计算,在CV/NLP等场景被证明了可以在非常短的延迟内完成较大batch size的模型计算。
但是GPU在推荐场景的应用还有几个难点,需要逐一解决。1. GPU的显存是不可能放得下大的推荐模型的,这里需要一些比较巧妙的Cache设计。2. GPU本身比较贵,GPU Embedding计算效率是否足够高来产生较大的性价比优势。
合理利用存储
Serving的部署方式其实有非常大的提升空间。
1 双buffer机制虽然比较容易实现和部署,但是却要浪费一倍的内存。是否可以通过滚动发布的方式代替。
2. 单机内存可以很容易放下上百GB模型。但是现在很多模型刚到几十GB就需要部署分布式Cache存储,既提高了成本,又降低了性能。PMEM可以让单机达到TB级的规模。
3. HashMap的实现也会显著的影响Serving的资源占用和性能。
端到端推荐
关于是否能端到端的解决推荐系统的Serving,可以读下百度和阿里这两篇论文(突然发现标题惊人的类似)。
MOBIUS: Towards the Next Generation of Query-Ad Matchingin Baidu’s Sponsored Search
COLD: Towards the Next Generation of Pre-Ranking System
关于深度传送门
深度传送门是一个专注于深度推荐系统与CTR预估的交流社区,传送推荐、广告以及NLP等相关领域工业界第一手的论文、资源等相关技术分享,欢迎关注!加技术交流群请添加小助手deepdeliver,备注姓名+学校/公司+方向。
以上是关于一文梳理工业界大规模推荐系统Serving架构分析的主要内容,如果未能解决你的问题,请参考以下文章