布隆过滤器的前世今生
Posted 大数据实习生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了布隆过滤器的前世今生相关的知识,希望对你有一定的参考价值。
感谢您抽出
.

.

来阅读本文

布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
1
假设场景

假设你现在要处理这样一个问题,你有一个网站并且拥有很多访客,每当有用户访问时,你想知道这个ip是不是第一次访问你的网站。这是一个很常见的场景,为了完成这个功能,你很容易就会想到下面这个解决方案:
把访客的ip存进一个hash表中,每当有新的访客到来时,先检查哈希表中是否有改访客的ip,如果有则说明该访客在黑名单中。你还知道,hash表的存取时间复杂度都是O(1),效率很高,因此你对你的方案很是满意。
然后我们假设你的网站已经被1亿个用户访问过,每个ip的长度是15,那么你一共需要15 * 100000000 = 1500000000Bytes = 1.4G,这还没考虑hash冲突的问题(hash表中的槽位越多,越浪费空间,槽位越少,效率越低)。
于是聪明的你稍一思考,又想到可以把ip转换成无符号的int型值来存储,这样一个ip只需要占用4个字节就行了,这时1亿个ip占用的空间是4 * 100000000 = 400000000Bytes = 380M,空间消耗降低了很多。
那还有没有在不影响存取效率的前提下更加节省空间的办法呢?
有,那么我们就顺着这个问题了解一下布隆过滤器吧。

Tips:在了解布隆过滤器之前先来了解一下BitSet吧!
2
BitSet
32位无符号int型能表示的最大值是4294967295,所有的ip都在这个范围内,我们可以用一个bit位来表示某个ip是否出现过,如果出现过,就把代表该ip的bit位置为1,那么我们最多需要429496729个bit就可以表示所有的ip了。举个例子比如10.0.0.1转换成int是167772161,那么把长度为4294967295的bit数组的第167772161个位置置为1即可,当有ip访问时,只需要检查该标志位是否为1就行了。
4294967295bit = 536870912Byte = 512M。如果用hash表示所有4294967295范围内的数组的话,需要十几G的空间。
当然,这里举ip的例子不一定合适,主要目的是为了引出BitSet。
下面我们来看看BitSet具体怎样实现。
首先,比如我们有一个长度=2的byte数组,2个字节一共有16位,可以表示0-15的数字是否存在。比如我们要验证11是否出现过,那么我们先检查第11个位置是否为1,如果为0,说明11没出现过,然后我们把第11位置为1,表示11已经出现过了。
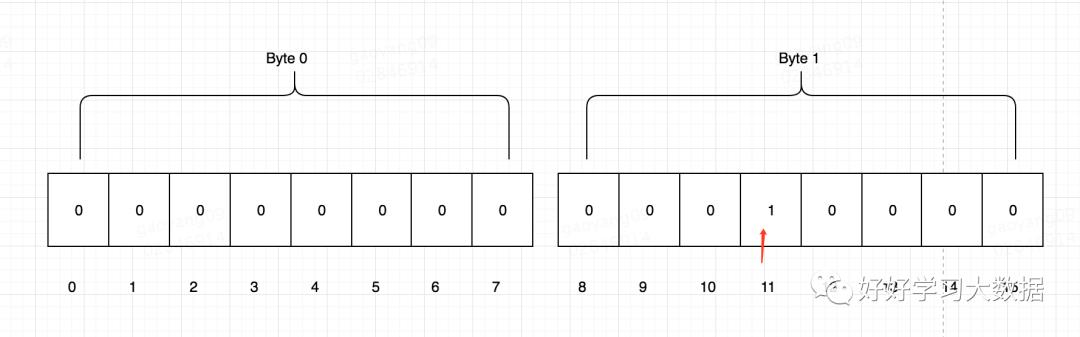
所以,BitSet基本只有两个操作,set(int value) 和 isHas(int value)
set(int value)
我们先来看set怎么实现,因为一个byte占8位,所以对于一个给定的value,我们先求出该value应该位于哪个Byte上,这很简单,int byteIndex = value / 8;
找到value在byte数组中的位置后,再就是在该字节中寻找表示value的bit位,我们知道,一个byte其实就是一个长为8的bit数组,那么value在该bit数组中的位置也就很好算了,int bitIndex = value % 8;
最后我们把该bit位设置为1就可以了:byte[byteIndex] = byte[byteIndex] | 1 << ( 7 - bitIndex)
整个流程如下面所示:
public void set(int value){int byteIndex = value / 8;int bitIndex = value % 8;byte[byteIndex] = byte[byteIndex] | 1 << (7 - bitIndex)}
isHas(int value)
同样的,isHas(int value)的推导过程和set(int value)差不多:
public boolean isHash(int value){int byteIndex = value / 8;int bitIndex = value % 8;return byte[byteIndex] & 1 << (7 - bitIndex) > 0}
Bitset的局限性
想必有同学已经意识到了BitSet使用起来似乎并不总是那么完美,BitSet有两个比较局限的地方:
当样本分布极度不均匀的时候,BitSet会造成很大空间上的浪费。
举个例子,比如你有10个数,分别是1、2、3、4、5、6、7、8、99999999999;那么你不得不用99999999999个bit位去实现你的BitSet,而这个BitSet的中间绝大多数位置都是0,并且永远不会用到,这显然是极度不划算的。
当元素不是整型的时候,BitSet就不适用了。
想想看,你拿到的是一堆url,然后如果你想用BitSet做去重的话,先得把url转换成int型,在转换的过程中难免某些url会计算出相同的int值,于是BitSet的准确性就会降低。
那针对这两种情况有没有解决办法呢?
第一种分布不均匀的情况可以通过hash函数,将元素都映射到一个区间范围内,减少大段区间闲置造成的浪费,这很简单,取模就好了,难的是取模之后的值保证不相同,即不发生hash冲突。
第二种情况,把字符串映射成整数是必要的,那么唯一要做的就是保证我们的hash函数尽可能的减少hash冲突,一次不行我就多hash几次,hash还是容易碰撞,那我就扩大数组的范围,使hash值尽可能的均匀分布,减少hash冲突的概率。
基于这种思想,BloomFilter诞生了。
3
BloomFilter
实现原理
BloomFiler又叫布隆过滤器,下面举例说明BlooFilter的实现原理:
比如你有10个Url,你完全可以创建一长度是100bit的数组,然后对url分别用5个不同的hash函数进行hash,得到5个hash后的值,这5个值尽可能的保证均匀分布在100个bit的范围内。然后把5个hash值对应的bit位都置为1,判断一个url是否已经存在时,一次看5个bit位是否为1就可以了,如果有任何一个不为1,那么说明这个url不存在。这里需要注意的是,如果对应的bit位值都为1,那么也不能肯定这个url一定存在,这个是BloomFilter的特点之一,稍后再说。
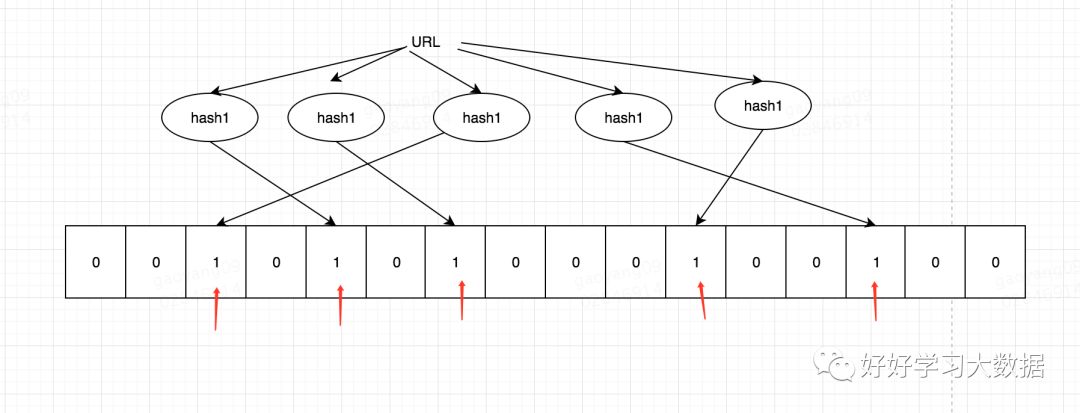
核心思想
BloomFilter的核心思想有两点:
多个hash,增大随机性,减少hash碰撞的概率
扩大数组范围,使hash值均匀分布,进一步减少hash碰撞的概率。
BloomFilter的准确性
尽管BloomFilter已经尽可能的减小hash碰撞的概率了,但是,并不能彻底消除,因此正如上面提到的:
如果对应的bit位值都为1,那么也不能肯定这个url一定存在
也就是说,BloomFilter其实是存在一定的误判的,这个误判的概率显然和数组的大小以及hash函数的个数以及每个hash函数本身的好坏有关,具体的计算公式,可以查阅相关论文,这里只给出结果:
Wiki的Bloom Filter词条有关于误报的概率的详细分析:Probability of false positives。从分析可以看出,误判概率还是比较小的,空间利用率也很高。
BloomFilter的应用
(1)黑名单
(2)排序(仅限于BitSet)
仔细想想,其实BitSet在set(int value)的时候,“顺便”把value也给排序了。
(3)网络爬虫
判断某个URL是否已经被爬取过
(4)K-V系统快速判断某个key是否存在
典型的例子有Hbase,Hbase的每个Region中都包含一个BloomFilter,用于在查询时快速判断某个key在该region中是否存在,如果不存在,直接返回,节省掉后续的查询。
END


往期回顾
●
来都来了 点个赞再走吧~~~
以上是关于布隆过滤器的前世今生的主要内容,如果未能解决你的问题,请参考以下文章