布隆过滤器你值得拥有的开发利器
Posted 全栈修仙之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了布隆过滤器你值得拥有的开发利器相关的知识,希望对你有一定的参考价值。
在程序的世界中,布隆过滤器是程序员的一把利器,利用它可以快速地解决项目中一些比较棘手的问题。如网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
一、布隆过滤器简介
当你往简单数组或列表中插入新数据时,将不会根据插入项的值来确定该插入项的索引值。这意味着新插入项的索引值与数据值之间没有直接关系。这样的话,当你需要在数组或列表中搜索相应值的时候,你必须遍历已有的集合。若集合中存在大量的数据,就会影响数据查找的效率。
针对这个问题,你可以考虑使用哈希表。利用哈希表你可以通过对 “值” 进行哈希处理来获得该值对应的键或索引值,然后把该值存放到列表中对应的索引位置。这意味着索引值是由插入项的值所确定的,当你需要判断列表中是否存在该值时,只需要对值进行哈希处理并在相应的索引位置进行搜索即可,这时的搜索速度是非常快的。
根据定义,布隆过滤器可以检查值是 “可能在集合中” 还是 “绝对不在集合中”。“可能” 表示有一定的概率,也就是说可能存在一定为误判率。那为什么会存在误判呢?下面我们来分析一下具体的原因。
布隆过滤器(Bloom Filter)本质上是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0,如下图所示。

为了将数据项添加到布隆过滤器中,我们会提供 K 个不同的哈希函数,并将结果位置上对应位的值置为 “1”。在前面所提到的哈希表中,我们使用的是单个哈希函数,因此只能输出单个索引值。而对于布隆过滤器来说,我们将使用多个哈希函数,这将会产生多个索引值。
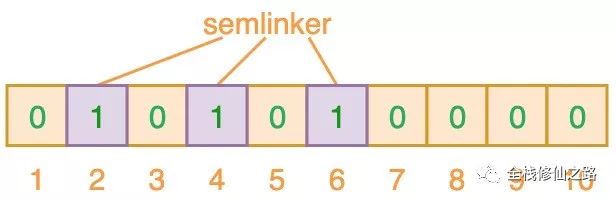
如上图所示,当输入 “semlinker” 时,预设的 3 个哈希函数将输出 2、4、6,我们把相应位置 1。假设另一个输入 ”kakuqo“,哈希函数输出 3、4 和 7。你可能已经注意到,索引位 4 已经被先前的 “semlinker” 标记了。此时,我们已经使用 “semlinker” 和 ”kakuqo“ 两个输入值,填充了位向量。当前位向量的标记状态为:
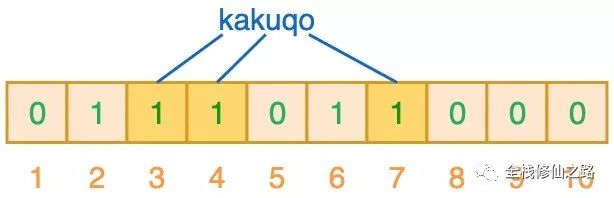
当对值进行搜索时,与哈希表类似,我们将使用 3 个哈希函数对 ”搜索的值“ 进行哈希运算,并查看其生成的索引值。假设,当我们搜索 ”fullstack“ 时,3 个哈希函数输出的 3 个索引值分别是 2、3 和 7:
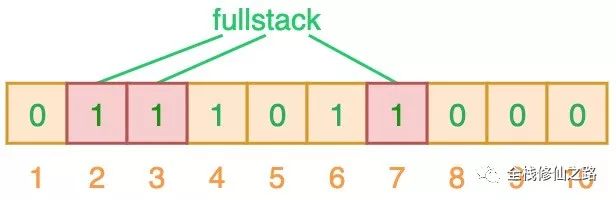
从上图可以看出,相应的索引位都被置为 1,这意味着我们可以说 ”fullstack“ 可能已经插入到集合中。事实上这是误报的情形,产生的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。幸运的是,布隆过滤器有一个可预测的误判率(FPP):
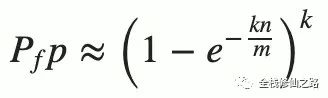
n是已经添加元素的数量;k哈希的次数;m布隆过滤器的长度(如比特数组的大小)。
极端情况下,当布隆过滤器没有空闲空间时(满),每一次查询都会返回 true 。这也就意味着 m 的选择取决于期望预计添加元素的数量 n ,并且 m 需要远远大于 n 。
实际情况中,布隆过滤器的长度 m 可以根据给定的误判率(FFP)的和期望添加的元素个数 n 的通过如下公式计算:
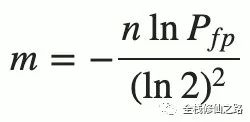
对于 m/n 比率表示每一个元素需要分配的比特位的数量,也就是哈希函数 k 的数量可以调整误判率。通过如下公式来选择最佳的 k 可以减少误判率(FPP):
了解完上述的内容之后,我们可以得出一个结论,当我们搜索一个值的时候,若该值经过 K 个哈希函数运算后的任何一个索引位为 ”0“,那么该值肯定不在集合中。但如果所有哈希索引值均为 ”1“,则只能说该搜索的值可能存在集合中。
二、布隆过滤器应用
在实际工作中,布隆过滤器常见的应用场景如下:
反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
Google Chrome 使用布隆过滤器识别恶意 URL;
Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。
除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
三、布隆过滤器实战
布隆过滤器有很多实现和优化,由 Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现。在基于 Maven 的 Java 项目中要使用 Guava 提供的布隆过滤器,只需要引入以下坐标:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
在导入 Guava 库后,我们新建一个 BloomFilterDemo 类,在 main 方法中我们通过 BloomFilter.create 方法来创建一个布隆过滤器,接着我们初始化 1 百万条数据到过滤器中,然后在原有的基础上增加 10000 条数据并判断这些数据是否存在布隆过滤器中:
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterDemo {
public static void main(String[] args) {
int total = 1000000; // 总数量
BloomFilter<CharSequence> bf =
BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), total);
// 初始化 1000000 条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put("" + i);
}
// 判断值是否存在过滤器中
int count = 0;
for (int i = 0; i < total + 10000; i++) {
if (bf.mightContain("" + i)) {
count++;
}
}
System.out.println("已匹配数量 " + count);
}
}
当以上代码运行后,控制台会输出以下结果:
已匹配数量 1000309
很明显以上的输出结果已经出现了误报,因为相比预期的结果多了 309 个元素,误判率为:
309/(1000000 + 10000) * 100 ≈ 0.030594059405940593
如果要提高匹配精度的话,我们可以在创建布隆过滤器的时候设置误判率 fpp:
BloomFilter<CharSequence> bf = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8), total, 0.0002
);
在 BloomFilter 内部,误判率 fpp 的默认值是 0.03:
// com/google/common/hash/BloomFilter.class
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03D);
}
在重新设置误判率为 0.0002 之后,我们重新运行程序,这时控制台会输出以下结果:
已匹配数量 1000003
通过观察以上的结果,可知误判率 fpp 的值越小,匹配的精度越高。当减少误判率 fpp 的值,需要的存储空间也越大,所以在实际使用过程中需要在误判率和存储空间之间做个权衡。
四、简易版布隆过滤器
为了便于大家理解布隆过滤器,我们来看一下下面简易版布隆过滤器。
package com.semlinker.bloomfilter;
import java.util.BitSet;
public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[]{7, 11, 13, 31, 37, 61};
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public SimpleBloomFilter() {
// 创建多个哈希函数
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
/**
* 添加元素到布隆过滤器中
*
* @param value
*/
public void put(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* 判断布隆过滤器中是否包含指定元素
*
* @param value
* @return
*/
public boolean mightContain(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static void main(String[] args) {
SimpleBloomFilter bf = new SimpleBloomFilter();
for (int i = 0; i < 1000000; i++) {
bf.put("" + i);
}
// 判断值是否存在过滤器中
int count = 0;
for (int i = 0; i < 1000000 + 10000; i++) {
if (bf.mightContain("" + i)) {
count++;
}
}
System.out.println("已匹配数量 " + count);
}
/**
* 简单哈希类
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}
在 SimpleBloomFilter 类的实现中,我们使用到了 Java util 包中的 BitSet,BitSet 是位操作的对象,值只有 0 或 1 ,内部维护了一个 long 数组,初始只有一个 long,所以 BitSet 最小的容量是 64 位。当随着存储的元素越来越多,BitSet 内部会动态扩容,最终内部是由 N 个 long 值来存储。默认情况下,BitSet 的所有位都是 0。
五、总结
本文主要介绍的布隆过滤器的概念和常见的应用场合,在实战部分我们演示了 Google 著名的 Guava 库所提供布隆过滤器(Bloom Filter)的基本使用,同时我们也介绍了布隆过滤器出现误报的原因及如何提高判断准确性。最后为了便于大家理解布隆过滤器,我们介绍了一个简易版的布隆过滤器 SimpleBloomFilter。
六、参考资源
理解布隆过滤器
布隆过滤器(Bloom Filter)的原理和实现
probabilistic-data-structures-bloom-filter
以上是关于布隆过滤器你值得拥有的开发利器的主要内容,如果未能解决你的问题,请参考以下文章