高级算法篇:布隆过滤器?非也,布谷鸟过滤器是也
Posted IT大咖说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高级算法篇:布隆过滤器?非也,布谷鸟过滤器是也相关的知识,希望对你有一定的参考价值。
过滤器在数据科学中的应用十分广泛,包括数据库查询、数据快速检索,数据去重等等。过滤器的出现是为了解决在大量数据的环境下,能够更好更快的(节省计算资源或者存储资源)筛查数据的需求。实际的应用场景有:
爬虫程序的URL识别:即爬虫在访问 URL 时对 URL 进行判断,如果访问过(在集合中)就不访问,如果没有访问过那么就访问然后放入已访问集合,提高爬虫效率。
在 LevelDB 数据库引擎中使用了 LSM tree,由于设计时为了优化写性能抑制了读性能,在磁盘中(sstable)查找 key 时(虽然已经使用文件索引并且定期合并文件来减少文件的数量,但是面对海量数据增量时还是捉襟见肘)使用 Bloom filter 这种在内存中的高效方法来判断文件中是否包含key。
接下来介绍最基本的两个过滤器,帮助大家理解过滤器技术的实现。
Bloom filter
Bloom filter 使用 hash 函数的散列技术存储信息的存在状态而不是存储信息本身,常常用于判断一个信息是否在一个集合中,这样只需要几个bit的空间就能解决问题。
基本原理
bloom filter作为一种海量数据处理算法,其要点在于用于存储的位数组和用于处理的hash函数(一般有多个,并且为了精确度和数据量增加)。
初始化存储空间:bloom filter首先在内存中开辟一块储存空间,并将里面的bit位全部置为0,表示尚未有数据进行处理或者储存。

映射集合中的数据:bloom filter通过设置k个hash函数,将一个集合中的所有数据或者说信息映射到储存空间中,被映射到的区域bit位设置为1。
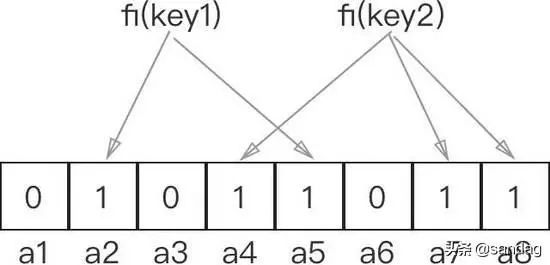
集合中的数据映射
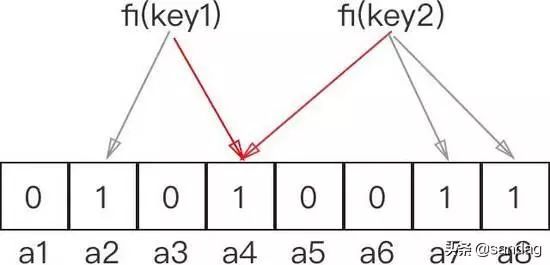
判断数据是否属于集合:假设任何一个信息或者数据key,要判断其是否在集合中,bloom filter将key带入k个hash函数进行映射(fi=fi(key)),然后判断其映射到的区域是否全部为1,如果全部为1,那么信息或者数据key表示在集合中,只要有一个映射位置为0,那么表示信息或者数据key不在集合中。
优缺点
优点:存储数据量小,节省存储及计算空间
缺点:只能对集合添加元素,无法删除(也并非完全不能,可以使用 bloom filter 的变种 CounterBloom Filte,该过滤器给每一位存储空间分配一个计数空间,每次删除时候计数减1。这个计数空间通常需要4位计数16则溢出。另外根据数据量,在满足一定错误率的情况下 hash 函数个数 k 需要变动。
Cuckoo filter理解
原理
Cuckoo filter 同样使用哈希表来实现数据到实际存储区域的映射,不同于 Bloom filer 的是Cuckoo filter中只采用两个哈希映射函数 H1 和 H2,H3用于计算数据的 fingerprint,减小存储量。他们的关系如下:
H1(key) = hash1(key)
H2(key) = H1(key) xor H1(key’s fingerprint)
H3(key) = key’s fingerprint = hash(key)
当一个数据需要存储的时候,Cuckoo filter 使用两个哈希函数进行映射,只要有一个映射到的区域为空,那么就将数据的指纹信息存储到相应的区域。如果两个区域都被占用,那么将原来占有那个存储区域的数据指纹踢出存储区用来存储新到的数据,原来的数据重新使用另外一个哈希函数映射存储,依次反复。
当然这个过程可能无限反复下去,那么一般会对踢出操作设一个阈值,超过阈值则认为过滤器容量不足,需要对其进行扩容。
这个踢出的过程类似于布谷鸟下蛋的过程,所以称其为布谷鸟过滤器。
附:散列技术
散列技术(也就是 hash 映射)因为在 bloom 过滤器 与 cuckoo 过滤器中就使用到了 hash 技术去映射,主要是散列表查找(哈希表):
引入
在顺序表查找(逐个比较)乃至有序表查找(折半查找)的时候难免需要使用比较,但这太消耗资源,考虑一种方法通过关键字Key直接得到想要查找的记录内存存储的位置: 存储位置 = f(关键字Key),这样不需要比较就能获得需要记录的储存位置,通过一个f(key)映射关系就能查找到储存位置,这种用于存储的技术称之为散列技术,其中f为hash函数。
散列技术既是存储方法,又是查找方法
最适合精确查找,也就是查找与给定值相等的记录。
不适合一个关键字对应多个记录(set is a class,key = 男)以及范围查找(set is a class,Q:18<age<20)。
设计一个简单、均匀、存储利用率高的散列函数是关键。
散列函数的构造方法
直接定址法:f(key) = keyf(key) = a * key + b( a、b为常数 )
数字分析法:数字反转(1234 -> 4321)、环形位移(1234 -> 4123)
折叠法:分解数字相加(或者别的运算)(9876543210 -> 987+654+321+0)
除留余数法:f(key) = key mod p (p<=m)
随机数法:f(key) = random(key)
如果是字符串或者中文可以转化为ASCII或者Unicode码来使用上面介绍的方法。
处理散列冲突的方法
开放定址法;
再散列函数法;
公共溢出法,就是为冲突的区域(信息)制造一个统一存储的区域;
IT大咖说 | 关于版权
感谢您对IT大咖说的热心支持!
相关推荐
推荐文章
最近活动
点击【阅读原文】更多IT技术圈干
以上是关于高级算法篇:布隆过滤器?非也,布谷鸟过滤器是也的主要内容,如果未能解决你的问题,请参考以下文章
REDIS11_布隆过滤器BloomFilter的概述优缺点使用场景底层原理布谷鸟过滤器
REDIS11_布隆过滤器BloomFilter的概述优缺点使用场景底层原理布谷鸟过滤器
REDIS07_布隆过滤器BloomFilter的概述优缺点使用场景底层原理布谷鸟过滤器