分布式任务调度架构原理和设计介绍
Posted 爪哇架构之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式任务调度架构原理和设计介绍相关的知识,希望对你有一定的参考价值。
大纲
一.核心原理和架构设计
二.实现讲解
三.例子
核心调度器
HashedWheelTimer 主要用来高效处理大量定时任务。
将超时任务根据时间轮分片算法放入时间轮的槽中,时间轮开始转动,转动N次,超过槽中超时任务应转次数就执行超时任务。
Netty 的实现:自行查看netty源码文件HashedWheelTimer.java
为什么要使用时间轮的环形结构? 因为环形结构可以根据超时时间的 hash值(这个 hash 值实际上就是ticks & mask)将 task 分布到不同的槽位中, 当 tick 到那个槽位时, 只需要遍历那个槽位的 task即可知道哪些任务会超时(而使用线性结构, 你每次 tick 都需要遍历所有 task),所以, 我们任务量大的时候, 相应的增加 wheel 的 ticksPerWheel 值, 可以减少 tick 时遍历任务的个数.
比quartz有更大任务调度吞吐量,性能更高。
可以将 HashedWheelTimer理解为一个 Set<Task>[] 数组, 图中每个槽位(slot)表示一个Set<Task>。
HashedWheelTimer有两个重要参数,tickDuration: 每 tick 一次的时间间隔, 每 tick 一次就会到达下一个槽位,ticksPerWheel: 轮中的 slot 数。
上图就是一个 ticksPerWheel = 8 的时间轮, 假如说 tickDuration =100 ms, 则 800ms可以走完一圈
在 timer.start() 以后, 便开始 tick, 每 tick 一次, timer 会将记录总的 tick 次数 ticks,我们加入一个新的超时任务时, 会根据超时的任务的超时时间与时间轮开始时间算出来它应该在的槽位.例如 timer.newTask(newTask(10, TimeUnit.SECONDS));表示加入一个 10s 后超时的任务, 那么, 先计算他应该在的槽位:
// deadline = 当前时间+ 任务延迟 - timer启动时间 = timer启动到任务结束的时间
long deadline = System.currentTime() + timeout - timerStartTime;
// calculated =tick 次数
long calculated = deadline / tickDuration;
// tick 目前已经 tick 过的次数
final long ticks = Math.max(calculated, tick); // Ensurewe don't schedule for past.
// 算出任务应该插入的 wheel 的 slot, slotIndex = tick 次数 & mask, mask = wheel.length - 1, 默认即为 511
stopIndex =(int) (ticks & mask);
// 计算剩余的轮数, 只有 timer 走够轮数, 并且到达了 task 所在的 slot, task 才会过期
remainingRounds =(calculated - tick) / wheel.length;
其中 stopIndex为它所在的槽位。
remainingRounds为它从 timer 启动时应该经过的轮数,当 timertick 到 task 所在的槽位, 并且这个槽位的 remainingRounds <= 0 , 则说明这个task 超时, 然后执行超时任务, 否则 remainingRounds—自减,表示需要走的
轮数减少一轮。继续下一轮的...
系统总体架构
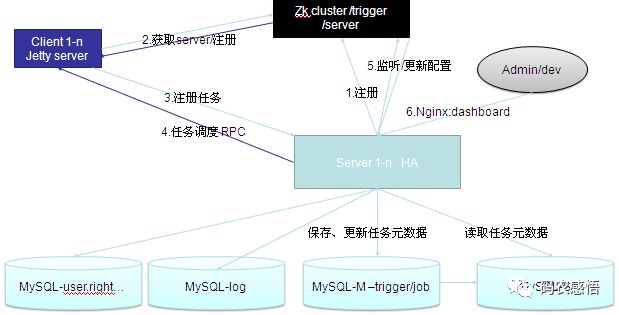
客户端:注册&被调度执行

1.包装quartz客户端api,平滑接入。
2.自定义客户端,简化配置。例如使用自定义注解。
3. 解析注解完成注册和被调度服务启动

服务端设计
见下期文章
数据库设计
以上是关于分布式任务调度架构原理和设计介绍的主要内容,如果未能解决你的问题,请参考以下文章