唯品会NoSQL平台自动化发展及运维经验分享
Posted 太平洋的土
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了唯品会NoSQL平台自动化发展及运维经验分享相关的知识,希望对你有一定的参考价值。
各位好,这篇文字是我上周在中华数据库和运维大会上分享的PPT,具体的内容是围绕唯品会NoSQL平台自动化发展过程以及一些运维经验,这里结合PPT加上文字详述。
个人介绍部分就省略了,下面是我的微博和微信,欢迎各位技术朋友微博互粉或微信交流,当然对唯品会数据库的工作感兴趣的各位也欢迎交流一下~ 我们目前招聘的重点在自动化开发相关的职位。
整个分享的提纲大概是这样一个过程:前半部主要围绕自动化运维进行介绍,后半部围绕Twemproxy改造及负载均衡相关,最后分享两个不好排查的运维问题。
在介绍自动化运维之前先看一下我们目前的平台背景。目前我们托管的业务主要是MC和Redis、中间层以及load balance服务。从图中可以看到,2015年上半年的增长超过了过去几年的积累,其中14年下半年的增长也占前几年积累的一半。全部的NoSQL实例已经接近3000,绝大多数业务是Redis.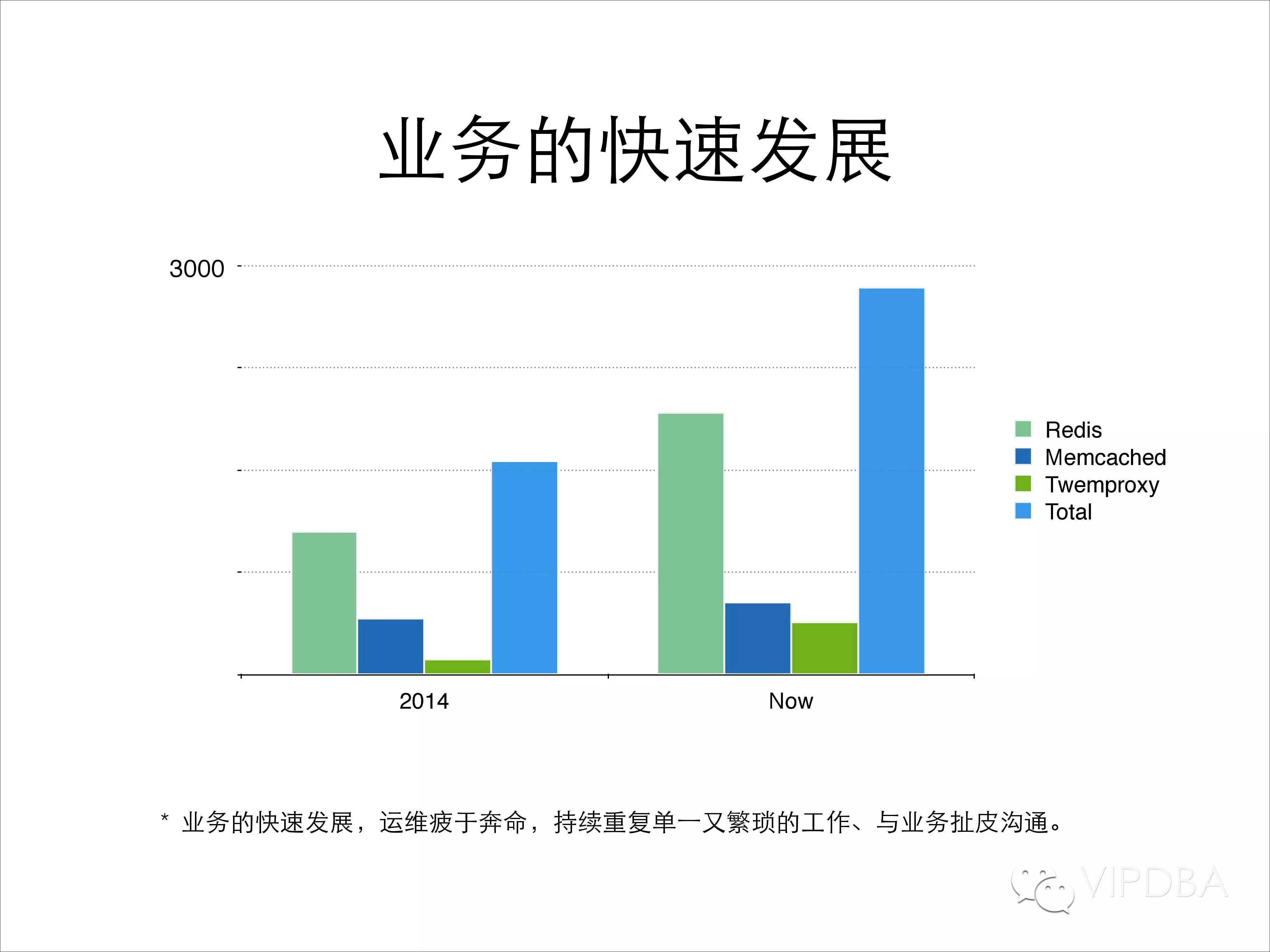
整个一年里规模翻了3倍,业务的快速发展,导致运维DBA疲于奔命,持续重复着单一而又繁琐的工作,也浪费了很多时间在和业务进行扯皮的工作,因此推行自动化运维变成了义不容辞的工作。
做自动化运维的同事应该都很清楚一点,运维标准化是运维自动化的前提,在没有标准化的情况下谈自动化基本都是在扯淡,自动化程序要适应各种不同的环境和标准会让自动化开发变得十分臃肿而且极易出错。因此在自动化推动的之前,我们设定了一些标准。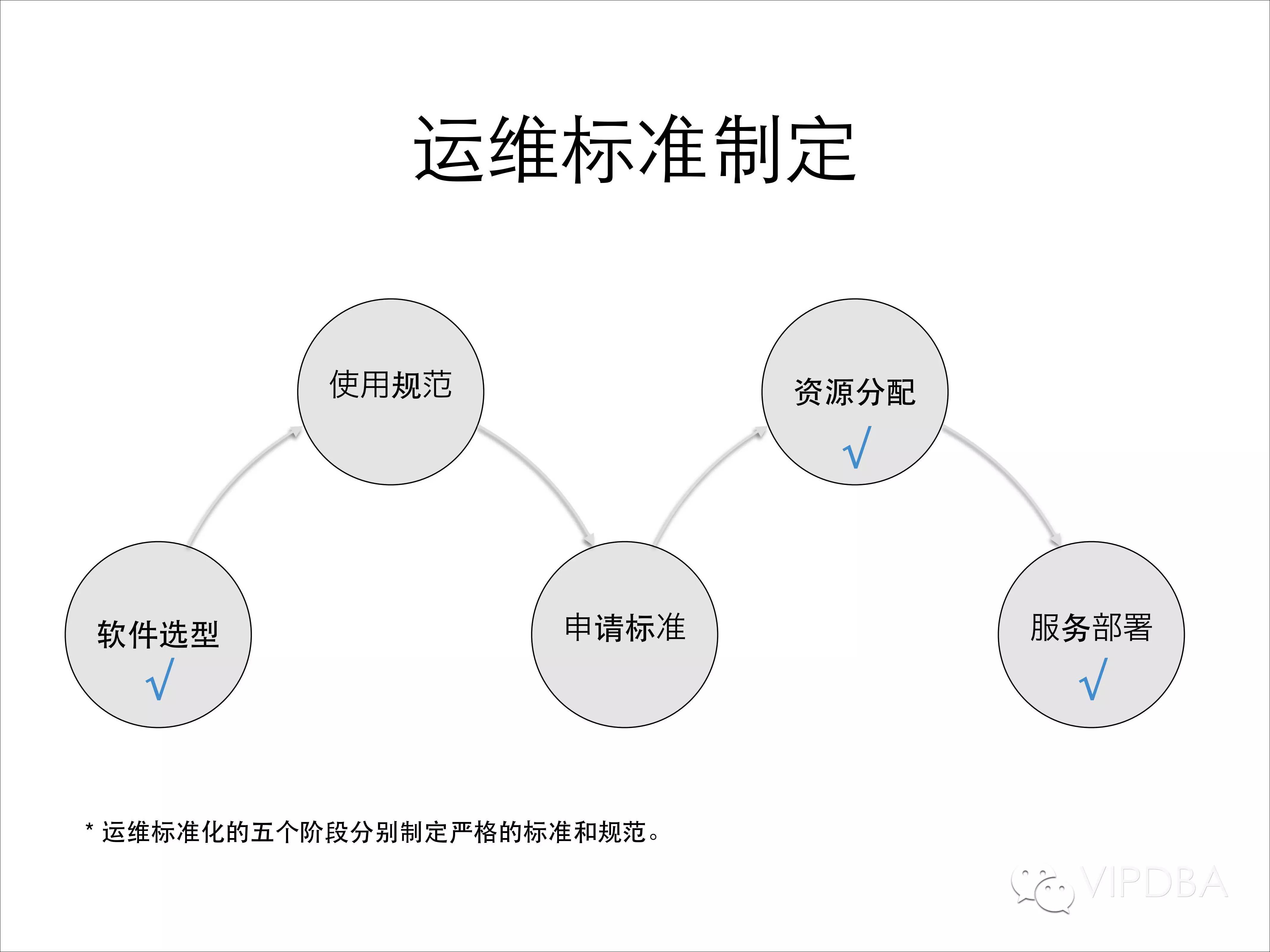
1. 软件选型标准— 告诉业务如何选择合适的服务!
目前我们负责的软件有个MC/Redis/Twemproxy,我们需要让业务知道到底要使用哪一个数据库产品。
2.服务使用规范— 告诉业务如何使用服务!
那业务选择了对应的服务之后,具体的使用方式并不会像DBA那样十分清楚,比如Redis有哪些坑需要避免,如何规避慢查询,甚至如何使用不同的数据结构等,key如何设计,哪些命令要谨慎使用。
3.申请标准制定— 告诉业务如何申请资源!
这一部分是我们业务自助门户的一部分,告知业务如何通过我们的系统进行资源申请,我们需要设定哪些业务指标来让开发填写。
4.资源分配方案— 告诉运维/程序如何分配资源!
业务申请完服务后,需要进行服务部署,到哪里去找资源,如何分配资源,如何进行资源隔离,如何自动化完成这一系列工作也需要有一套标准。
5.服务部署标准— 告诉运维/程序如何部署服务!
在业务快速发展的过程中,最大一部分工作就是进行服务部署,无论是人为还是自动化都需要将部署流程标准化。
这里简单介绍一下唯品会的软件选型标准、资源分配方案、服务部署标准。
那软件选型需要考虑哪几方面?
数据结构;业务类型;
Proxy还是client?
高可用
持久化和备份.
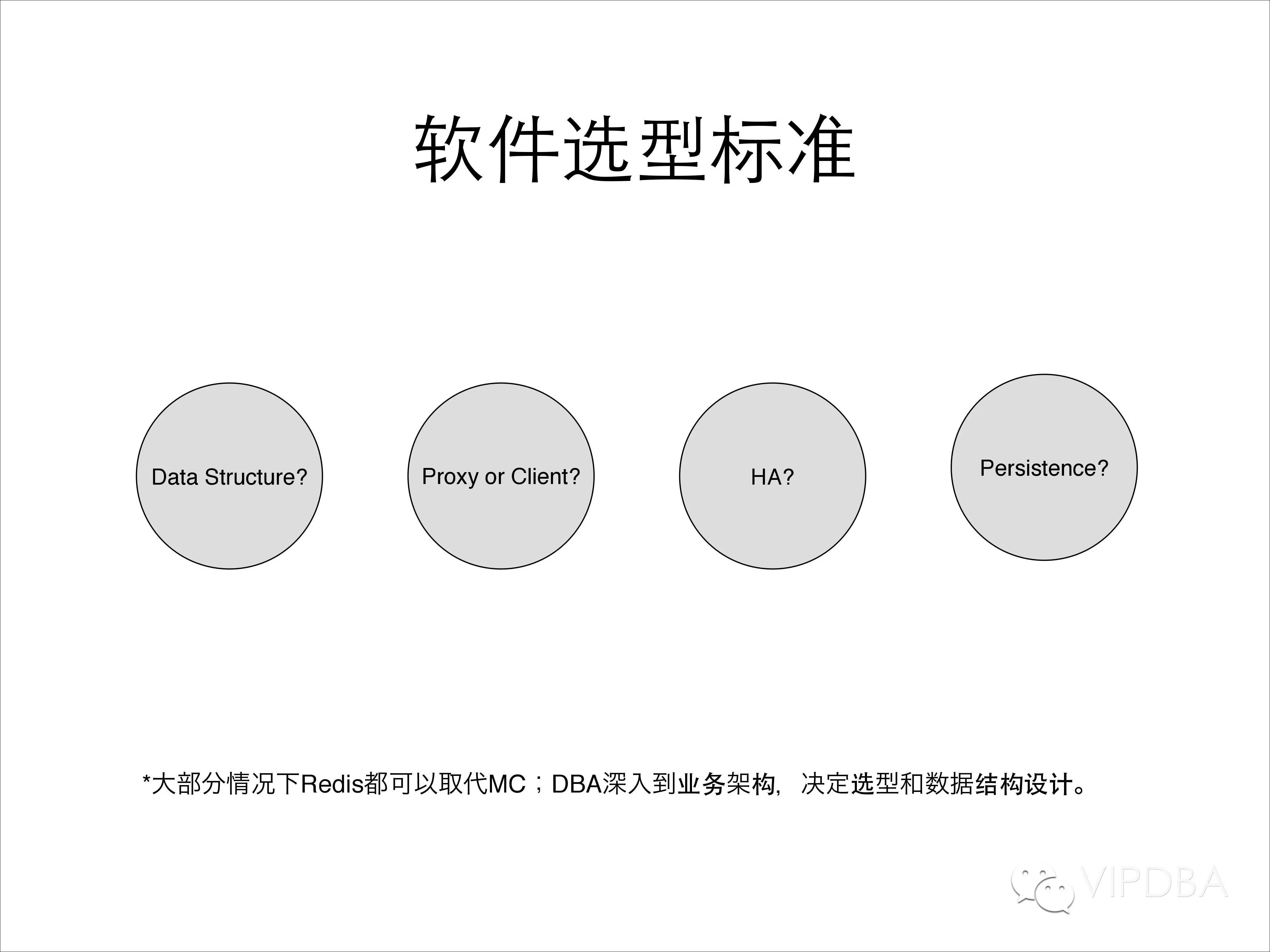
大部分情况下Redis都可以取代MC;我们都希望运维DBA可以深入到业务架构,决定选型和数据结构设计,但是这往往是最难的一部分。
资源分配方案的标准:
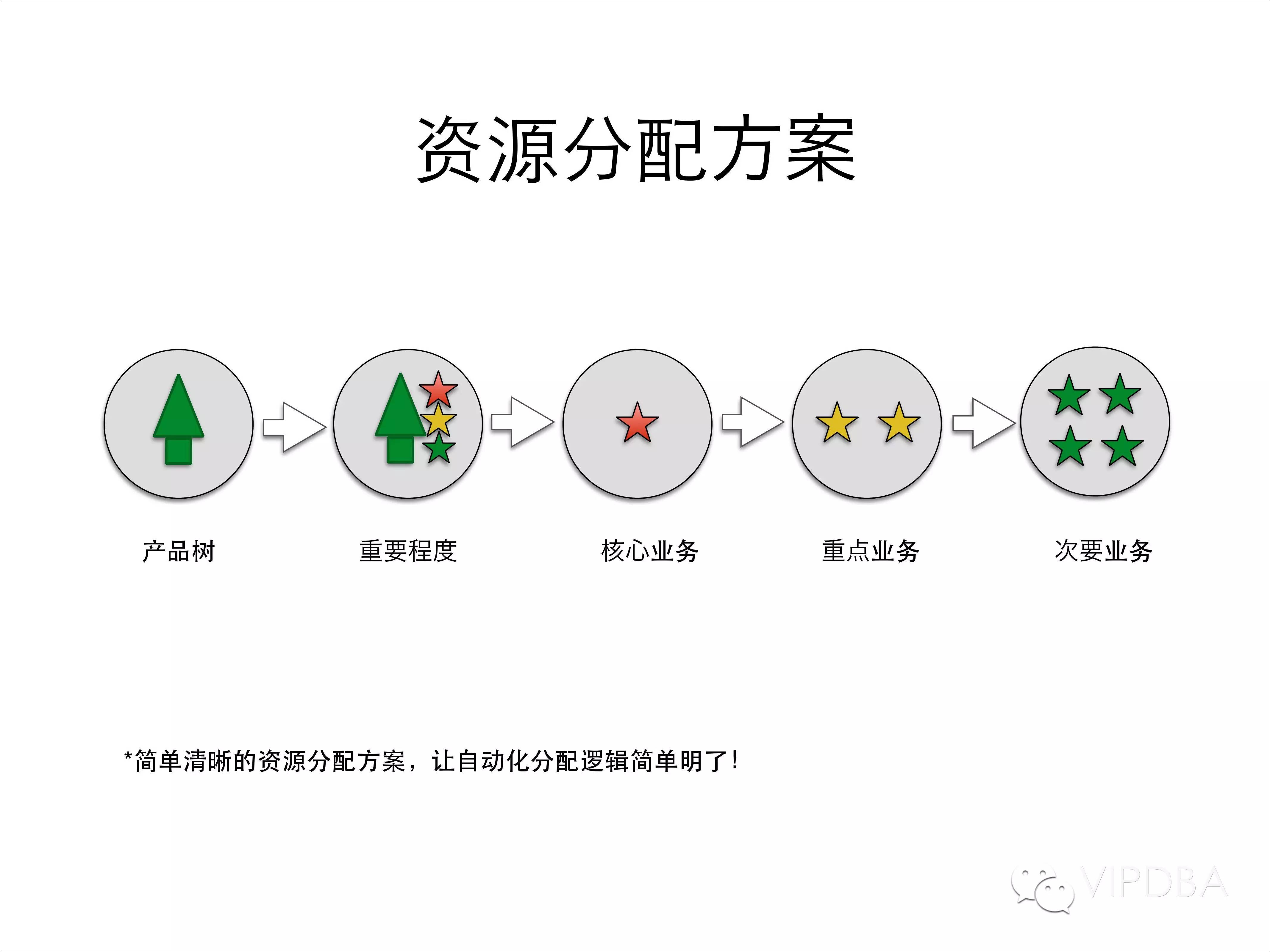
统一产品线;这是很重要的一件事,运维中的各个方面都是围绕其运作的,需要十分靠谱才行。
划分重要程度星级;业务总会有核心、非核心、重要、非重要之分,划分重要程度有助于让人了解业务,让程序识别业务,在资源分配和隔离的工作中是一个很重要的标识,在报警的时候可以安装级别进行一些筛选,甚至在处理问题的时候适当的进行一些取舍。
核心重点业务单独部署、重点业务部门混用部署、非核心业务混用部署;这就是一个简单的部署规范。无论你是否进行了资源隔离,核心业务最好都做一些物理隔离。
服务部署标准有如下几条,所有的标准都是为了让人工以及程序更简单的运维。
全局自增端口号— 适用于单机多实例场景;按照业务类型,软件类型,设定具体的端口号范围,这样单机部署多实例不会有冲突,主从同端口号,易识别。
单机多版本支持— 升级简单;支持单机多版本同时部署,不冲突,在启动路径中添加版本标识,软件包添加版本标识。如果单机单版本,升级的时候就需要一次性升级整个服务器,在配置化服务并不健全的情况下,可能需要多业务方和运维同时一起进行配置变更,十分苦逼。单机多版本支持后,可以做到单实例的升级。
统一的数据/配置文件/日志目录;这一部分大部分公司应该都有自己的规范,比如新浪使用的是统一的数据目录,配置文件和日志文件和数据文件在同一个数据目录里;而唯品会使用不同的数据目录,配置文件目录和日志目录。各有好处吧,只要有特定的规范即可。
统一RPM打包Yum安装;所有用到的软件都按照内部规范打包成RPM,然后在用yum安装,安装简单的、方便版本升级,同时也可以走一些软件环境初始化的工作。
上面这些是唯品会的一些简单的规范,大家可以参考一下,取长补短,不一定都是适用的。接下来重点讲一下唯品会自动化运维的发展:
所谓的自动化运维,我们的目标很宏伟,那就是解放人类,让程序去做人做的事,那人呢,去喝茶了么?其实人还是在运维,不过是在操作着自动化程序或者去做连自动化也做不好的事。
自动化运维四象限: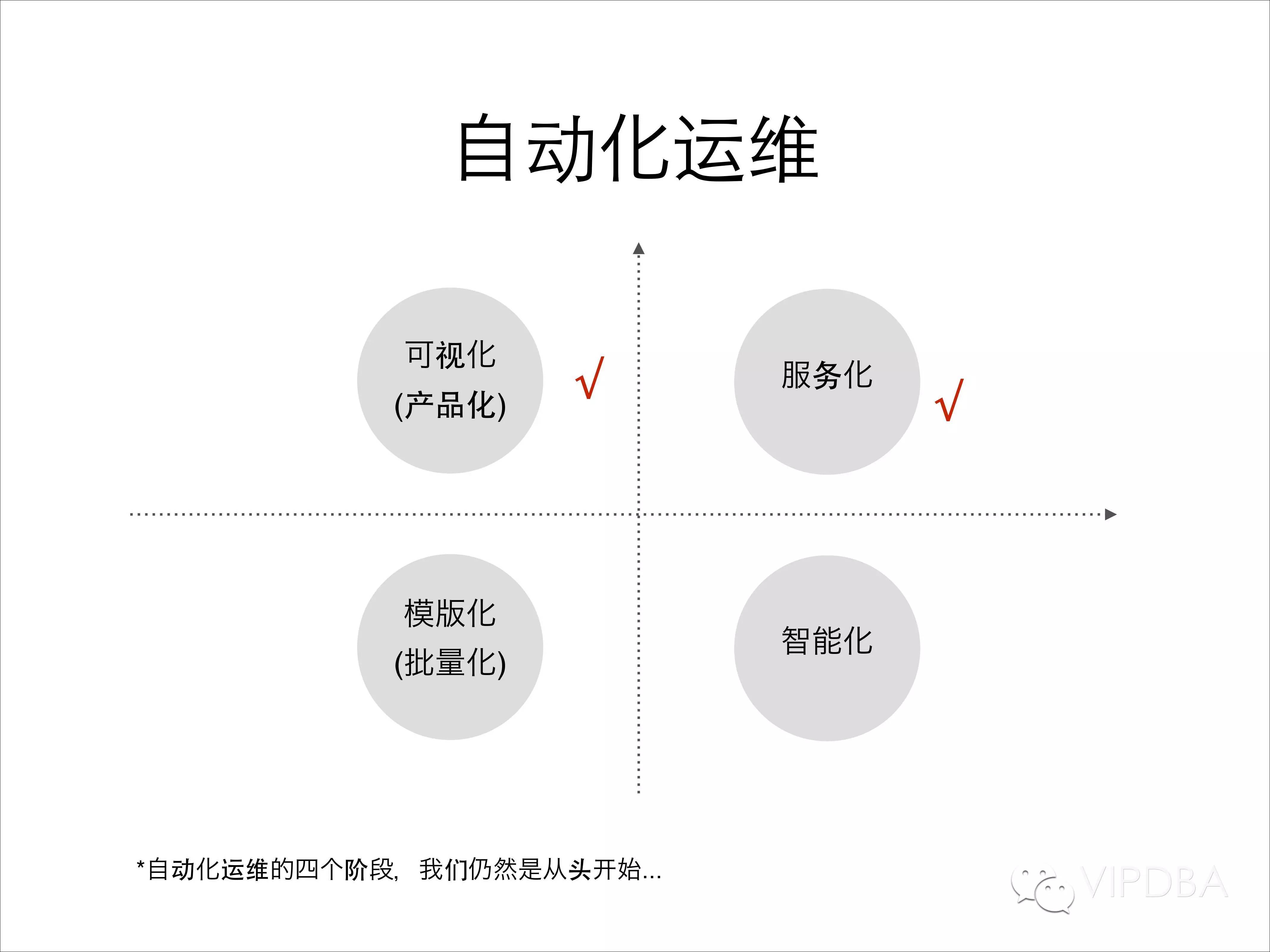
唯品会NoSQL平台的自动化也可以说是刚刚起步,几乎从头开始,主要涵盖在前两个象限里,里后面的象限的工作还差之甚远:
这里的运维服务化,说白了就是把每个运维操作API化,开发独立、简单、通用的API服务。RestfulAPI服务在业务模型里最近几年被大量使用,但是API服务化在运维领域的应用也是在公有云服务兴起之后开始广泛被使用。原来大部分自动化运维还是基于脚本化的,php调用shell或者Python脚本,有时候甚至要用PHP去SSH远程执行命令。这种方式虽然简单,但是也有很多问题,Web段的开发工作量太大,没有统一的后端入口,没有统一的配置入口等很多问题。所以我们做的第一件事就是将运维服务化。每个单独的功能设计成API服务,统一的操作入口,统一的配置入口。
首先简单介绍一下我们现在API的架构和功能模块,API分为3层架构,全部由Python开发:使用Tornado作为API的Web开发框架,现在使用tornado的人不多了,大部分Python的web开发都用django和flask,我第一次接触tornado的时候还是1.2版本,现在已经4.1版本了。Tornado和flask做Restful API都是比较简单方便的;后端的具体操作使用Fabric,Fabric在自动化运维领域使用的也很多,它在Python的paramiko库的基础上对SSH服务进行了一些封装,可以使用它简单的进行一些远程命令调用,远程部署服务之类的需求。我们没有通过在服务器上安装agent的方式,SSH更简单方便,缺点就是速度差了一点;由于Fabric的速度或者任务处理的速度问题,不能保证在秒级返回数据,因此我们使用celery,作为tornado的异步任务队列。Celery作为一个分布式的任务队列很适合这样的工作,我们所有的Fabric调用都是通过Celery异步调度的。就这样我们使用3个开源的Python框架,构造了我们的运维API服务架构。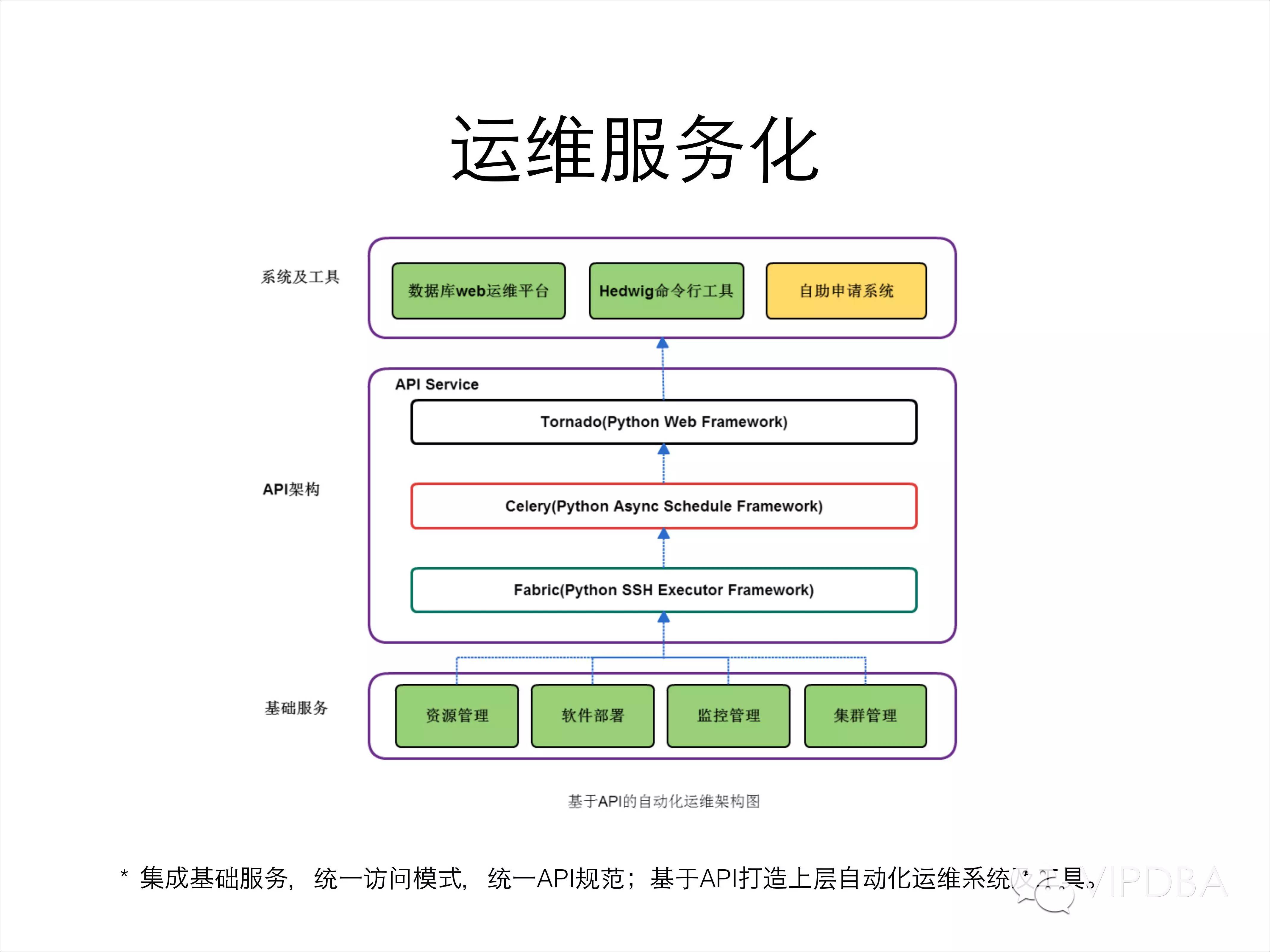
在API的上层,我们基于API开发了自己的Web管理系统、命令行运维工具以及业务自助申请及自动部署系统;API的下层是基础的功能模块,有很多,这里列举几个,比如监控管理、资源管理、集群管理、软件部署等。这些模块基本都是独立的服务,比如我们使用zabbix进行整个集群的监控,我们在zabibx API上进行二次封装,按照我们自己定义的API规范,统一格式,统一接入。
这里列举几个我们常用的API接口:
/cluster/instances -- 获取某个业务的实例配置;下层基于集群管理数据库,上层使用其实现web管理系统。
/redis/start -- 启动redis服务;web运维及命令行运维工具。
/memcached/stop -- 停止MC服务;同上。
/twemproxy/clone -- 扩容twemproxy服务;一键扩容twemproxy。
/zabbix/status -- 获取某个业务的监控状态;基于zabbix API。
/alert/send -- 发送报警;基于短信网关。
接下来分别介绍一下我们的Web管理系统及命令行工具:
我们的Web管理系统包含集群管理、服务器管理、实例管理等;集成Puppet、Zabbix及软件部署及资源展示等功能; PPT中的两个页面分别展示服务器管理及实例管理页面。在服务器管理中:可以查看服务器的硬件、软件信息;实例管理中可以查看实例的运行状态、监控信息、统计数据等。

在Web管理系统以外,基于API开发命令行工具hedwig,对于很多重复、批量的工作来说,在运维模块化未实现之前,命令行工具甚至比web工具对运维人员来说更简单好用。hedwig基本可以完成我们95%的基础运维工作。

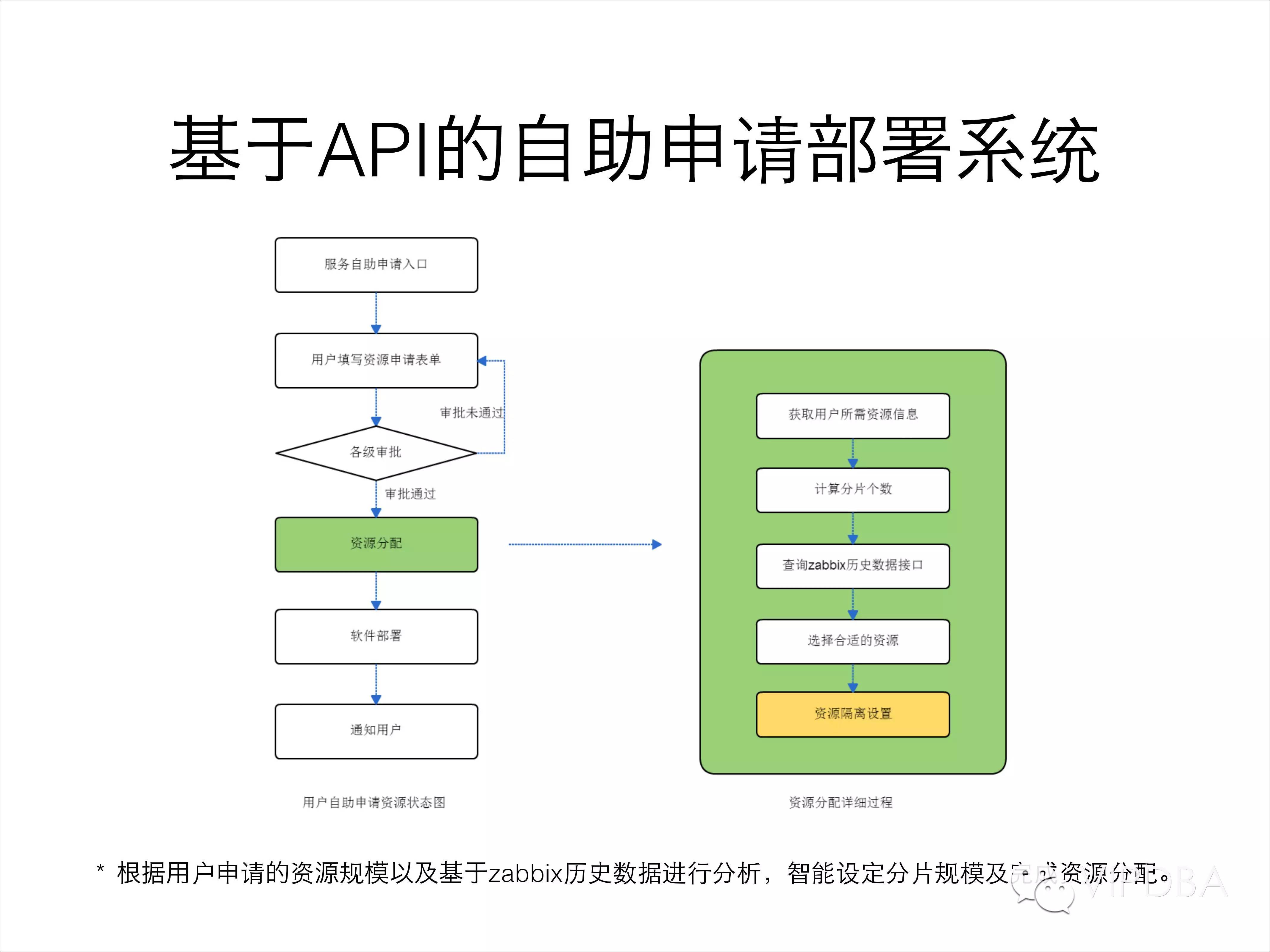
最后说一下我们基于API开发的自助申请部署系统,用户在web系统中填写申请单并审批通过后,根据用户申请的资源规模、产品线、重要程度等信息,并基于zabbix历史数据进行分析,智能设定分片规模及完成资源分配。资源分配完成后,通过上面列举的实例管理API进行软件部署、监控添加等操作,最后自动反馈给用户;整个过程中DBA所做的就是在页面中点击一个通过或拒绝而已。
说完运维服务化,再了解一下我们在运维可视化方面的一些进展:
我们的运维可视化主要在3个方向:
业务数据的多维度展示
Zabbix + 定制化Dashboard
全链路数据分析系统– Titan
我们的运维可视化的重点工作还是在业务监控上面;业务数据的多维度展示,包含我们每天的总读写量、实例规模等,这里由于私密原因不方便详述;第二个是我们基于Zabbix的数据定制化了自己的Dashboard页。最后是我们自己开发的全链路数据分析系统Ttian。
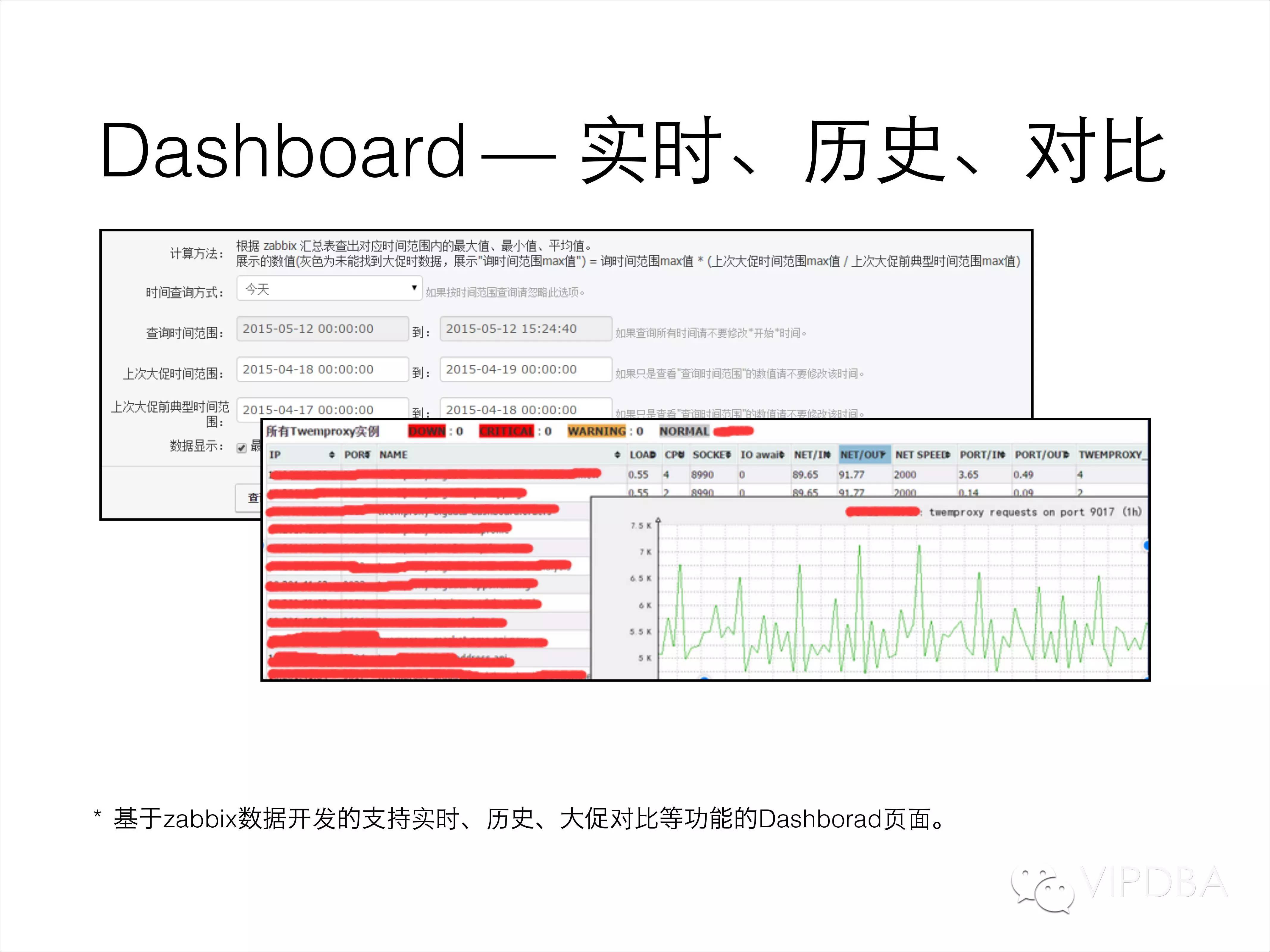
基于zabbix数据,我们开发的支持实时、历史、大促对比等功能的Dashborad系统。页面整理比较简单,但功能涵盖点很全面,NOC团队可以在Dashborad页面中看到所有在线业务的运行情况,问题业务会飘红提醒;我们在大促之前会使用Dashborad系统中的大促对比评估功能,简单预测下次大促的业务峰值,进而对可能出现问题的业务进行扩容拆分等工作。当然这里面有一个难点,不知道其他公司在业务峰值预测方面的方法如何,准确度如何,后续可以一起讨论一下。
这里我重点介绍一下我们的全链路数据分析系统TITAN,整体架构也比较清晰;在每台服务器上通过Python脚本使用tcpdump采样抓包写日志 -> flume监控日志变化将数据写入kafka集群-> 再经过spark实时分析后将结果存储在hbase中 -> 最后基于分析数据开发展示系统Logview。
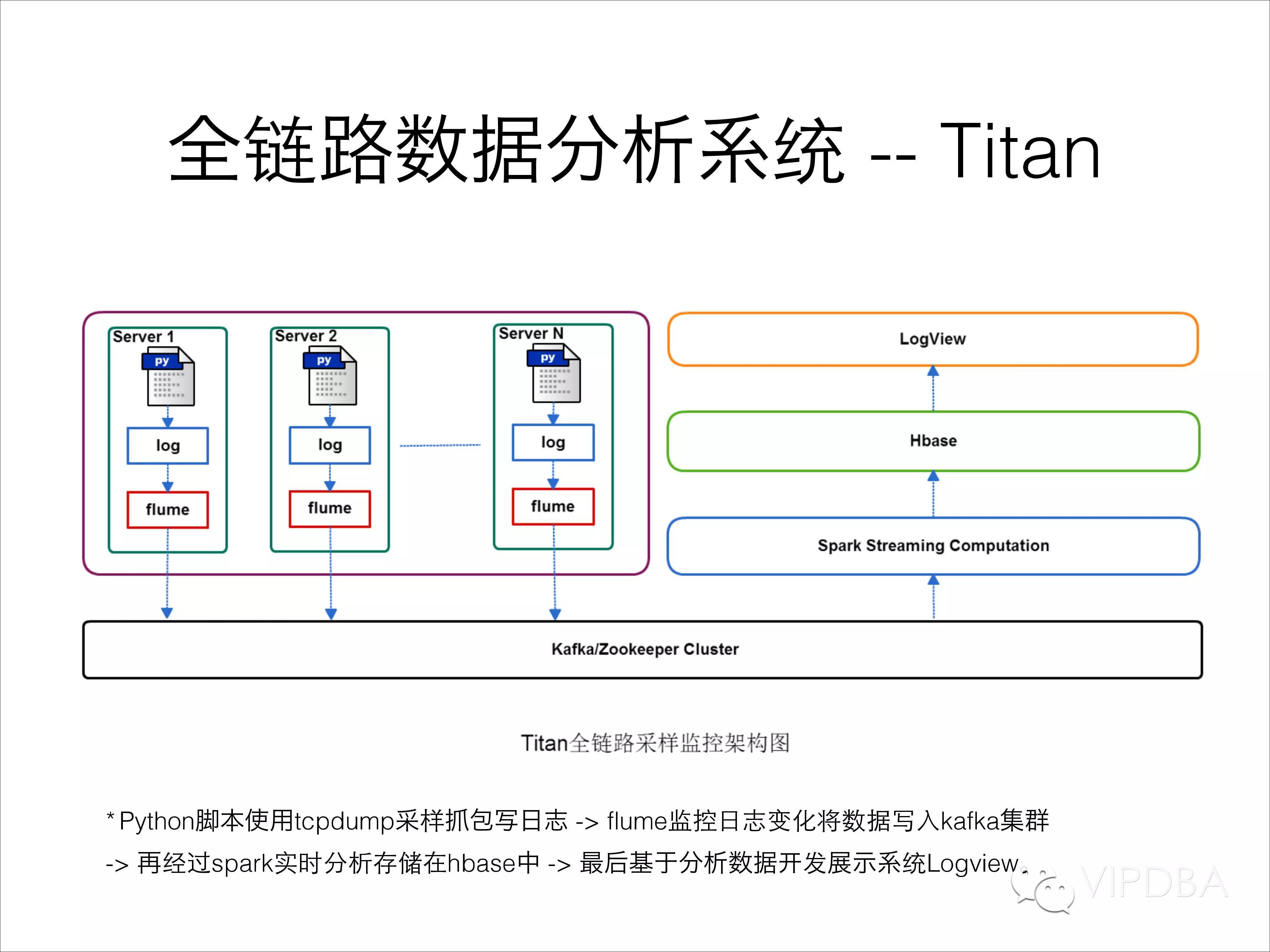
整个TiTan系统主要完成3件事:
响应时间统计
Hot/slow command/query统计
请求来源统计
日志的格式和内容是怎样的?
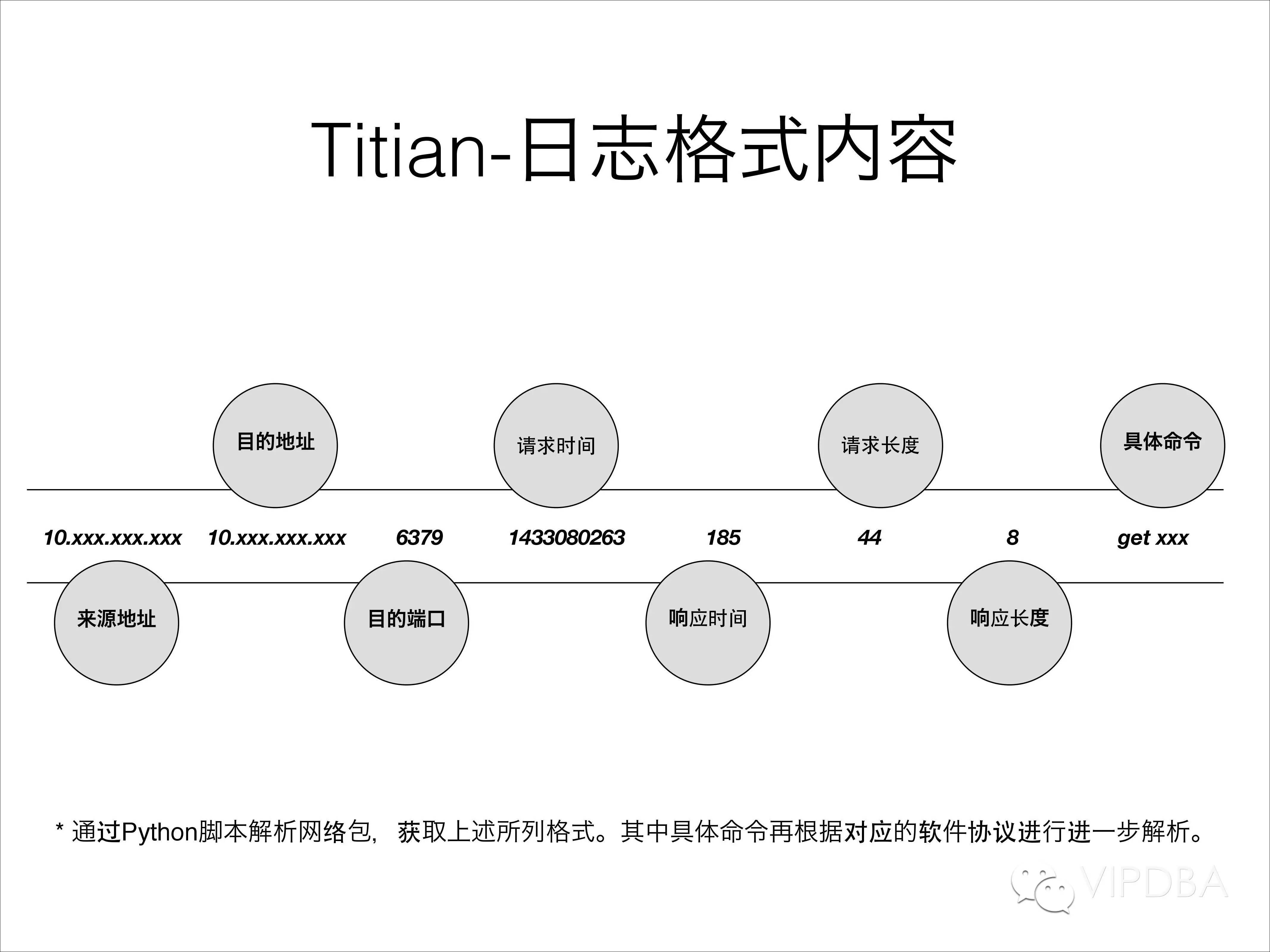
通过Python脚本解析网络包,获取下面上面几个纬度的数据:
目的端口;实例端口号
请求时间;请求发来的时间
响应时间;请求用时是多少
请求长度;命令长度;
响应长度;结果长度;
具体内容;具体的请求命令。
通过对上面日志格式的分析,可以实现哪些功能呢?
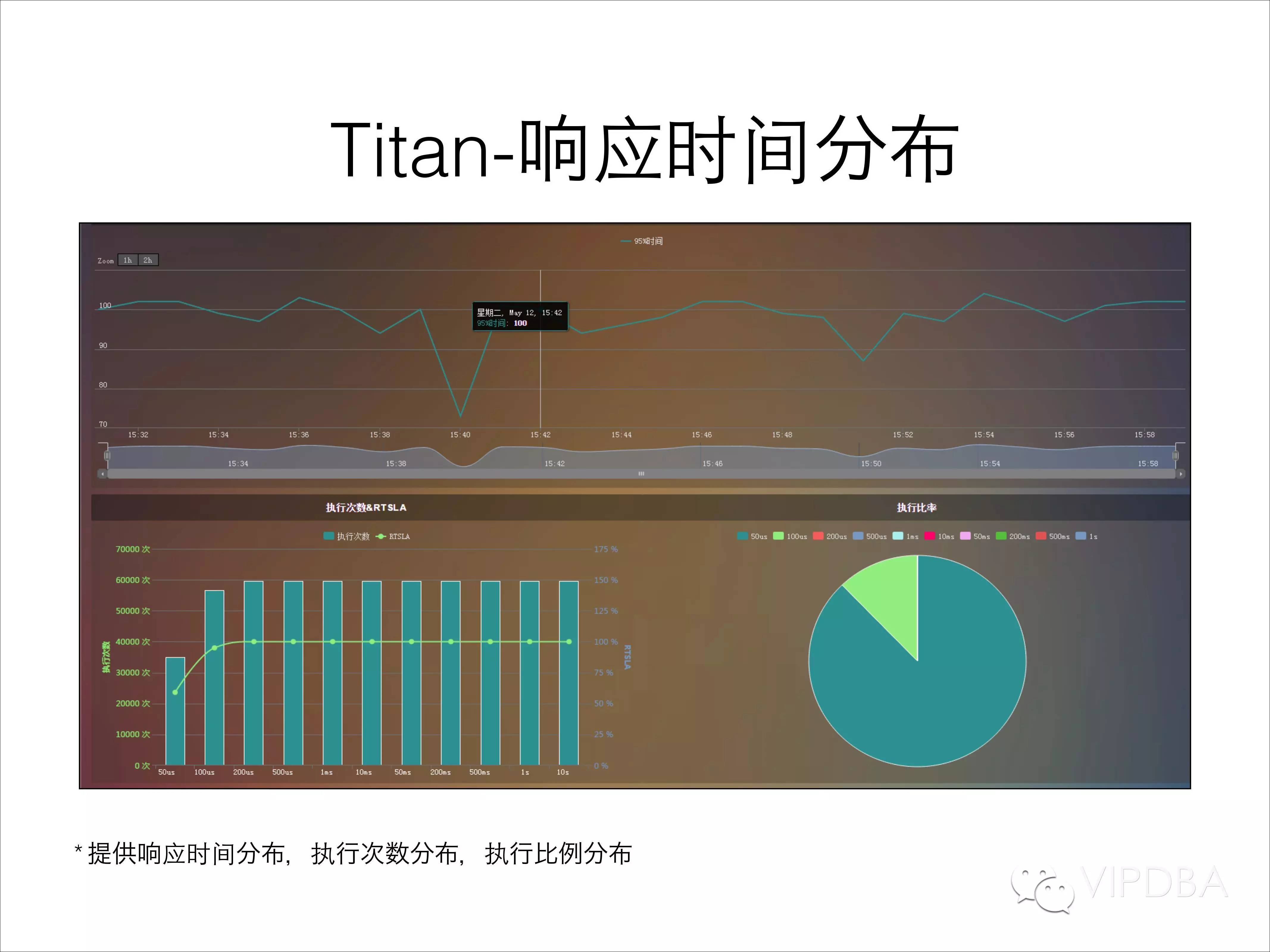
响应时间统计功能;通过对每条TCP数据包分析获取每个command/SQL的执行时间,进行各维度的统计分析,获得响应时间分布,执行次数分布,执行比例分布等。比如图中的这个业务几乎100%的请求在200us内返回。这个功能在业务运行时几乎可以实时的查看业务的响应时间,并可以根据响应的阈值进行报警。
Hot/slowcommand/query统计功能;对每条TCP包的内容解析,获取到具体的Command/SQL种类,然后统计每一个Command/SQL种类的频率和执行时间,得到业务的Hot command /query以及slow command/query;最后基于统计数据进行业务的优化处理。

请求来源统计功能;对每一条请求分析其请求来源,结合集群管理CMDB的数据,进而得到请求来源产品线信息,来源IP及产品线占比等数据。比如,在这里我们可以了解到某个业务被哪些产品线的哪些具体的服务器访问的比例,在业务混用的时候这个功能十分有用,另外在业务下线、切换的时候也是很方便的排查问题的工具。
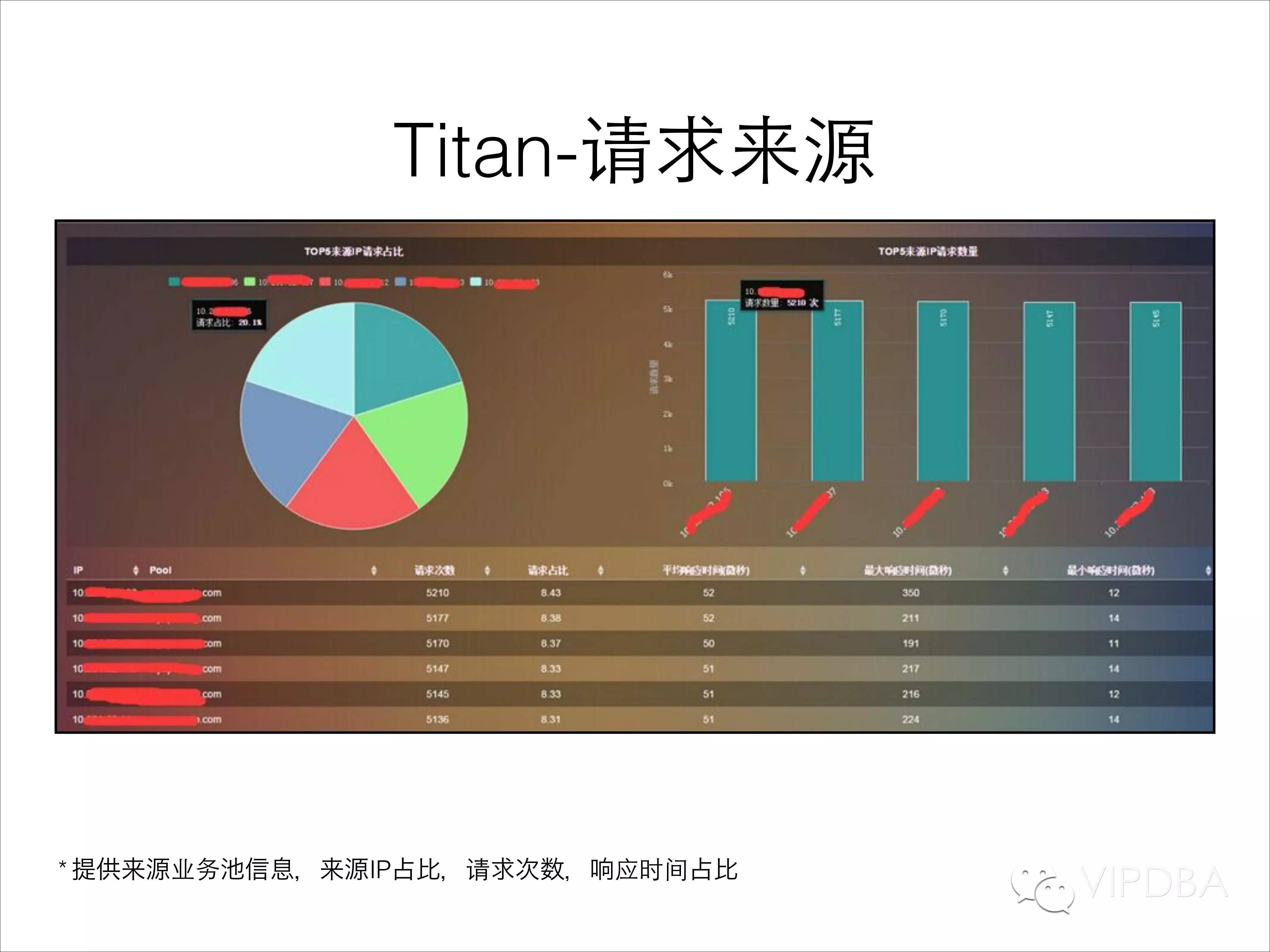
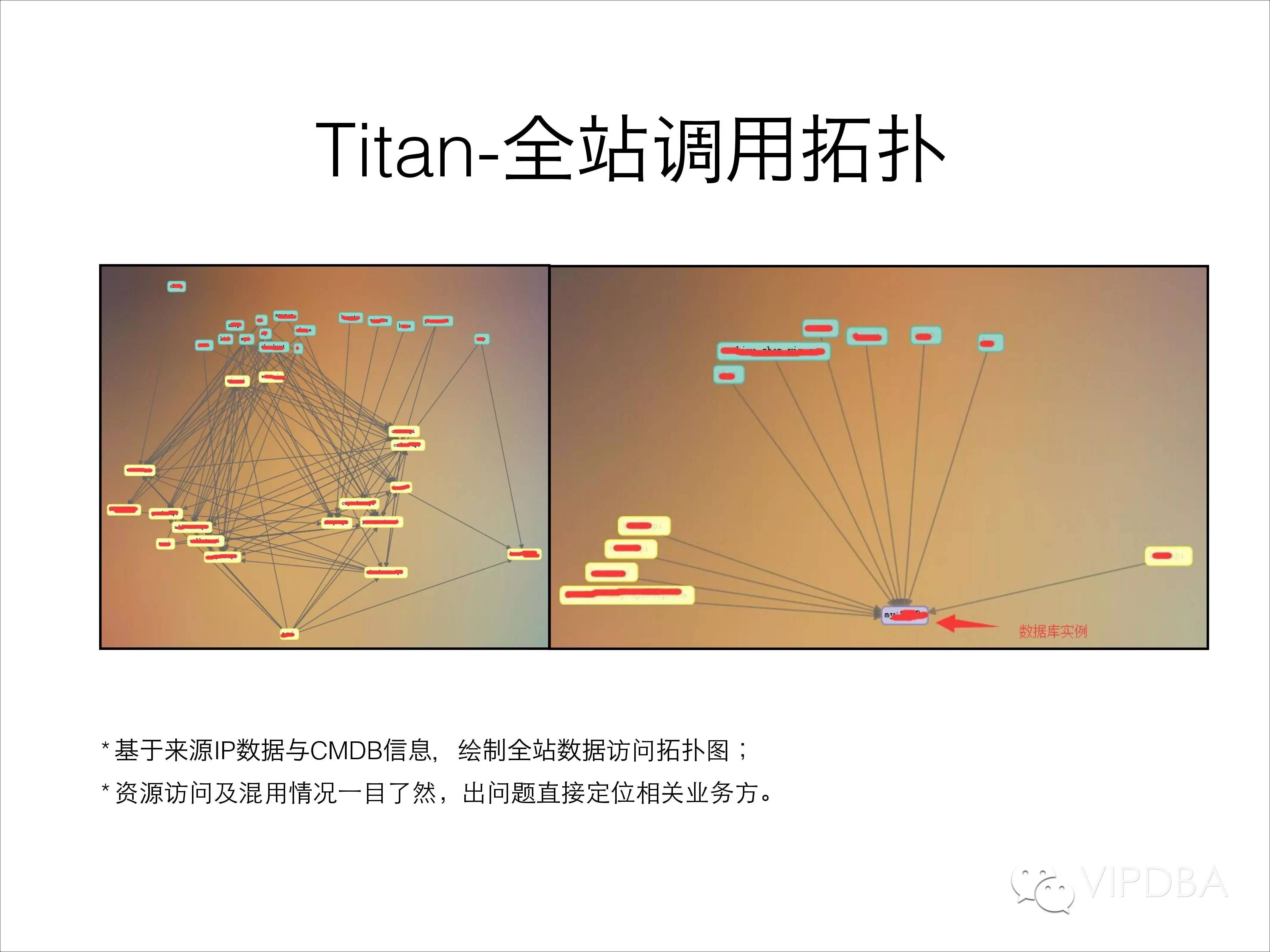
最后基于来源统计数据,我们绘制了整个数据请求的链路图,可以直接通过可视化的拓扑结构了解每个产品前端池访问了哪些数据库,也可以了解到某个业务被哪些产品线的业务池所访问。资源访问及混用情况一目了然,出问题直接定位相关业务方。
自动化相关的内容暂时就分享到这,后面我还会介绍一下我们在负载均衡服务上的自动化进展。不过接下来我先重点分享一下我们使用Twemproxy大规模上线使用的相关内容。
开始的时候有说过,在14年下半年,我们开始推进线上使用Twemproxy作为Redis及MC的中间层,在上线之前我们对比了一些大型互联网工作在中间层方面的各种方案,进行了简单的评估工作,再之后我们对Twemproxy进行了一些简单的功能改造以便更适合日常的运维工作。
先说一下我们整理的一些大型互联网公司的方案,并按照各个纬度进行了划分。这里简单提及一下,不做重点讨论。主要按照下面几个纬度划分: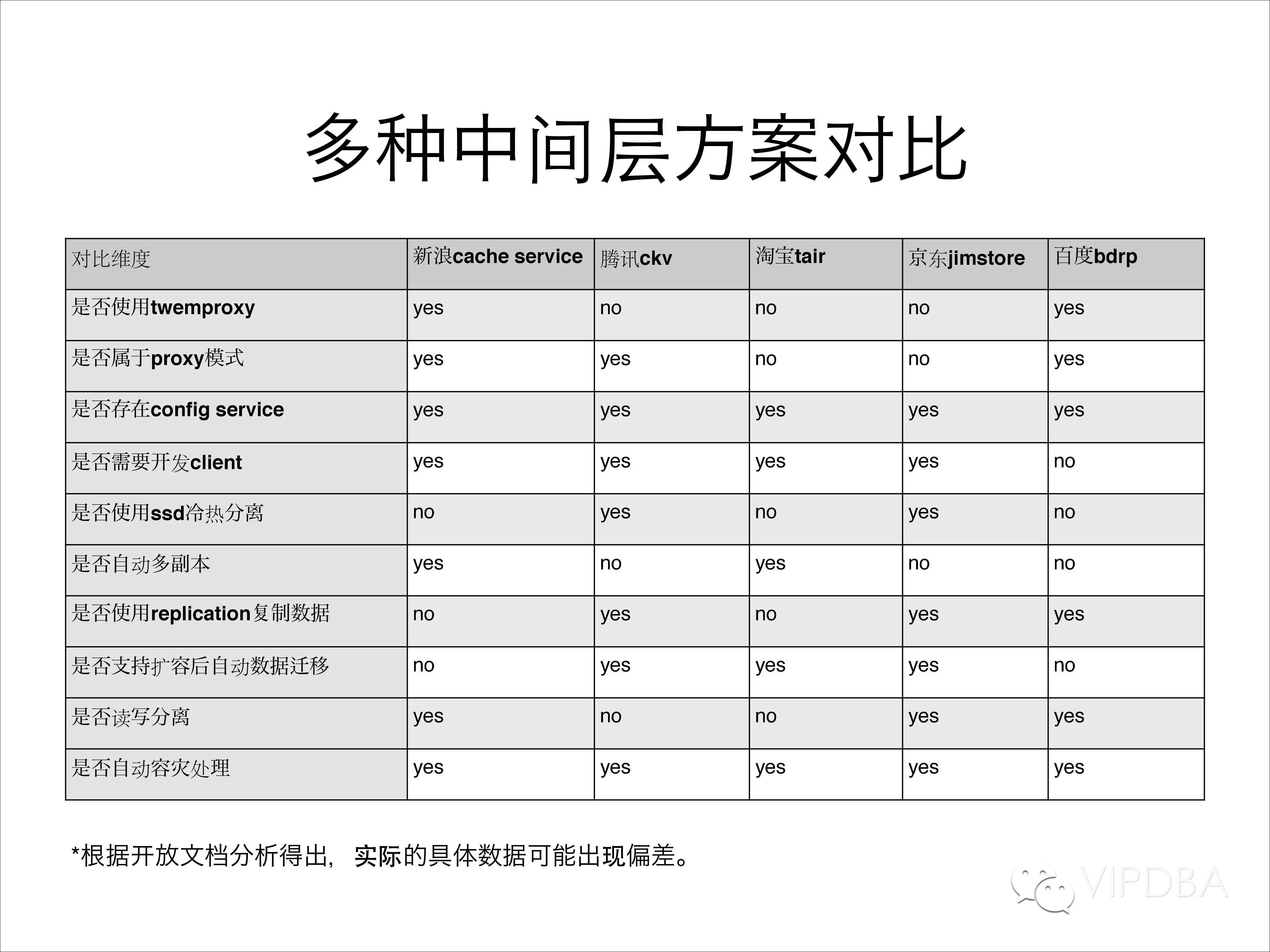
是否使用twemproxy
是否属于proxy模式
是否存在config service
是否需要开发client
是否使用ssd冷热分离
是否自动多副本
是否使用replication复制数据
是否支持扩容后自动数据迁移
是否读写分离
是否自动容灾处理
整理一下主要是几个类别:
是否是Proxy中间层模式?这一点主要是考虑数据处理模式,是否存在中间层一环。
是否需要开发定制化的客户端?这一点主要是考虑是否需要开发定制的客户端,增加开发成本。
是否存在配置中心?可以看出配置中心是各个方案的标配,这里的配置中心都是中心化管理的配置中心。
如何实现高可用?不同方案的高可用实现方式不同,主要是两种:同时写多份或基于数据库本身复制。
结合上面的几个纬度说说Twemproxy本身的优缺点:
Twemproxy带来的好处:
开发简单;业务不需要更改代码逻辑,只要更改配置即可;这是在当时的环境中促成我们使用Twemproxy的最重要的原因。
自动分片,伪分布式集群;DBA可以控制配置变更,不在需要其他部门配置。
功能简单、方便部署;只是配置文件加上简单的启动命令即可。
但同时,Twemproxy也存在几个问题:
流量问题;大流量的业务Proxy成为瓶颈。
高可用和负载均衡;我们通过在Twemproxy前面增加LVS解决,可又是额外的服务器资源,业务整体的TCO太高。
数据流层太多,风险增大;请求需要经过LVS再到Twemproxy,最后到数据库,三层的数据流层结构,增大的响应时间的同时,出现问题的风险增大。
没有配置中心,配置变更不方便。
喜忧参半,没有一劳永逸的方案,特定阶段解决特定问题! 们当时处于一种紧急上线、快速解决问题的情况;在这种情况下,我们采用了原生的Twemproxy来解决我们的问题,而且在过去的一年里,Twemproxy带给我们的好处远大与它所带来的问题。
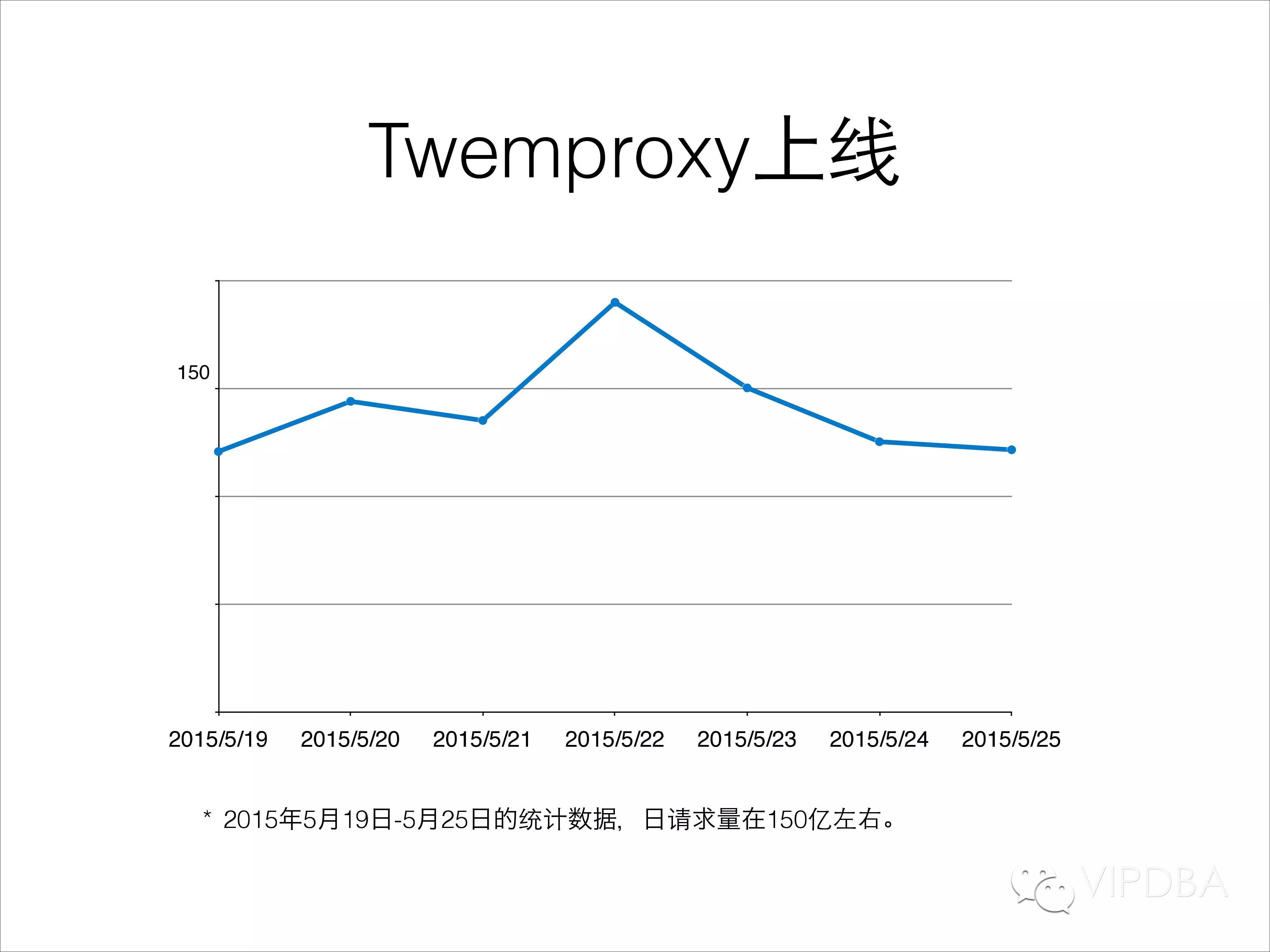
在PPT的图片中可以看到,在最近的某个星期里,我们的Twemproxy业务的日请求量在150亿左右。
为了更加方便运维,我们在使用Twemproxy的同时,逐步的对齐进行定制化开发,以满足我们的一些额外需求,比如:
日志自动切割;我们在刚上线的时候会开启debug模式,有些业务请求量较大的时候会产生大量的log,因此我们额外开发了自动切割程序,每个日志设定固定的大小和份数,超出的自动purge掉。当然使用logrotate等工具也可以做到这个功能,我们只是为了更简单方便而已,不在详述。
配置动态更新;Twemproxy不支持在线动态更新配置,我们开发了可以不停机自动配置更新功能,主要是结合Redis Sentinel配合使用。
Sentinel+配置中心;Twemproxy+Sentinel结合使用解决 Redis的HA问题,配置中心用来进行中心化的数据更改和推送。
Replication Pool;为了解决MC 穿透和动态扩容的问题,解决MCrouter的功能设计实现具有复制功能的Twemproxy。
这里主要分享一下后面两个改动的架构:
1.Twemproxy+Sentinel
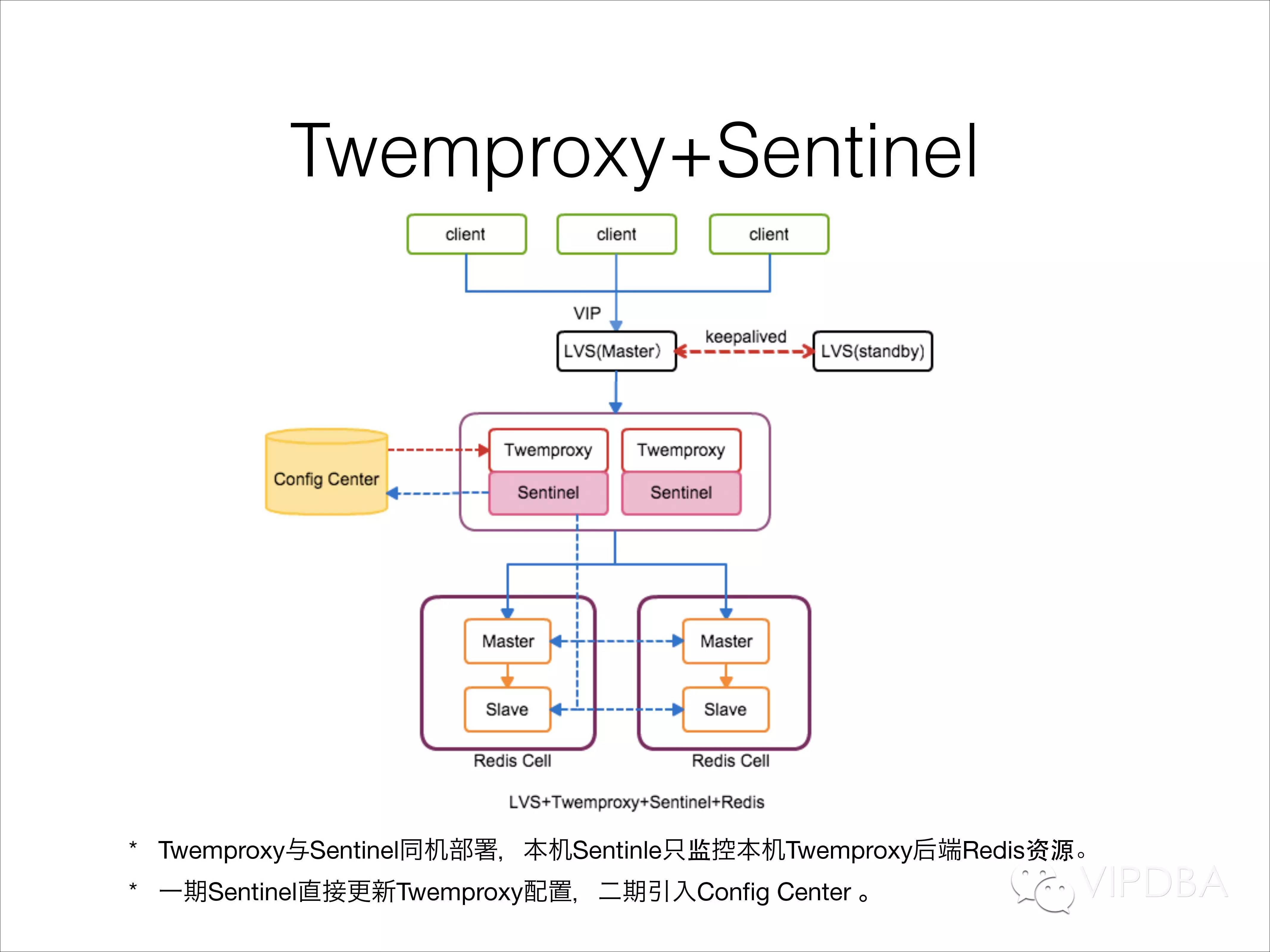
这张架构图就是目前我们整体解决方案的架构图;多个应用服务器通过访问LVS服务器的VIP和VPORT发生请求数据,我们使用keepalived保证LVS的高可用;数据经过LVS进行负载均衡后转发到后端的多个Twemproxy实例中; Twemproxy与Sentinel同机部署,本机Sentinle只监控本机Twemproxy后端Redis资源,Sentinel发现Redis Master异常后,自动提升slave,然后更新本机Twemproxy配置。我们正在开发的二期改造,引入Config Center(zk),Sentinel 发现master 异常后,不在通知Twemproxy改为通知Config Senter,Twemproxy订阅Config Center的消息后自动进行配置更新,增加配置中心后,我们可以更方便、更安全的进行配置变更工作。
2.Replication Pool;
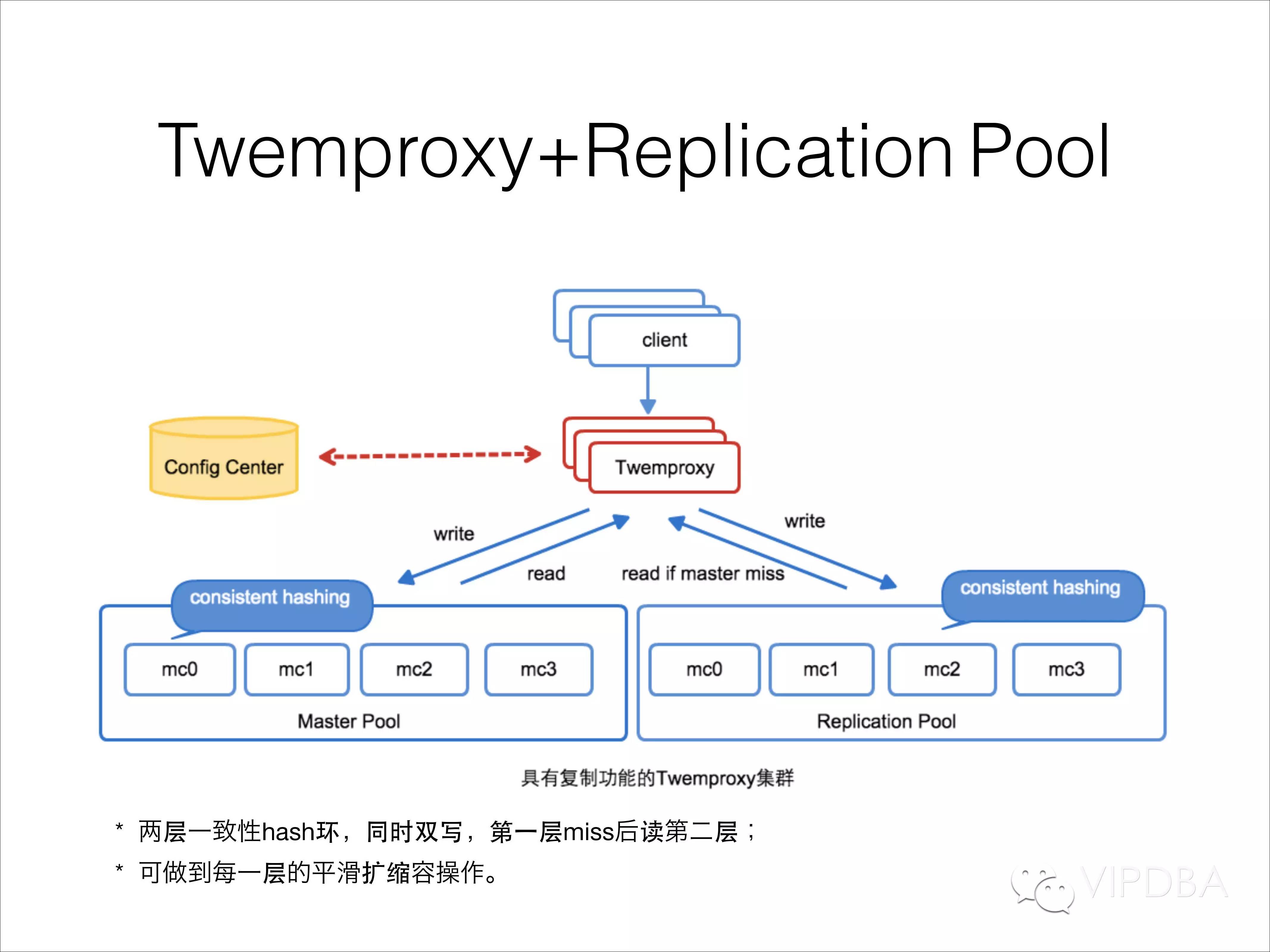
在Replication Pool的功能中,设计成两层一致性hash环,写请求同时双写两层,读请求在第一层miss后读第二层;由于每一层都是一致性hash,在第一层的扩缩容操作所带来的请求穿透都可以由第二层命中,从而降低了直接穿透到mysql的风险,另外第一层会命中大部分请求,因此第二层也可以进行安全的扩缩容;两层的容量和节点数目可以不同,第一次设置成少节点少容量,用来解决绝大部分热请求,第二层设置成多节点大容量,用来hold住第一层miss的剩余请求。
上面这些就是我们在使用Twemproxy作为中间层后所做的一些改造工作。由于使用了Twemproxy,我们需要额外面临的一个问题就是解决Twemproxy的负载均衡和高可用,前面的架构图中有说明,我们用的软负载均衡软件LVS来解决这个问题。Twemproxy的大规模使用,导致LVS配置变更的需求增加很多,纯手工更新LVS配置文件的方式,存在很多风险点而且十分繁琐,运维成本较高。为了解决这个问题,我们开发了自己的负载均衡自动化系统Libra。
这里承接之前说的运维服务化,我们称其为负载均衡服务化,把负载均衡作为一个单独的服务提供,也就是Load Balance As A Service,LBaaS. 这一部分,我简单的分享一下,唯品会数据库负载均衡服务的功能抽象设计、整体架构,最后简单展示一下我们的管理系统页面。
其实只做一个LVS配置管理系统还是比较简单的,说简单写就是页面上填写配置,然后生成配置文件,reload keepalived程序即可。不过要做一个通用的负载均衡管理系统就并不是那么简单了。Libra将负载均衡中用到的各个模块抽象化后,提供规范的Restful API接口,配置存储到MySQL中,在通过额外的配置更新程序获取配置生成配置文件并重载服务。这种方式借鉴Openstack中的负载均衡服务模型,抽象化的数据模型可以支持多种负载均衡软件,比如LVS/Haproxy等,API服务都是通用的,不同的是不同的负载均衡软件需要以插件式的形式开发特定的配置更新程序。
Libra的负载均衡抽象模型,分为3层,6个模块;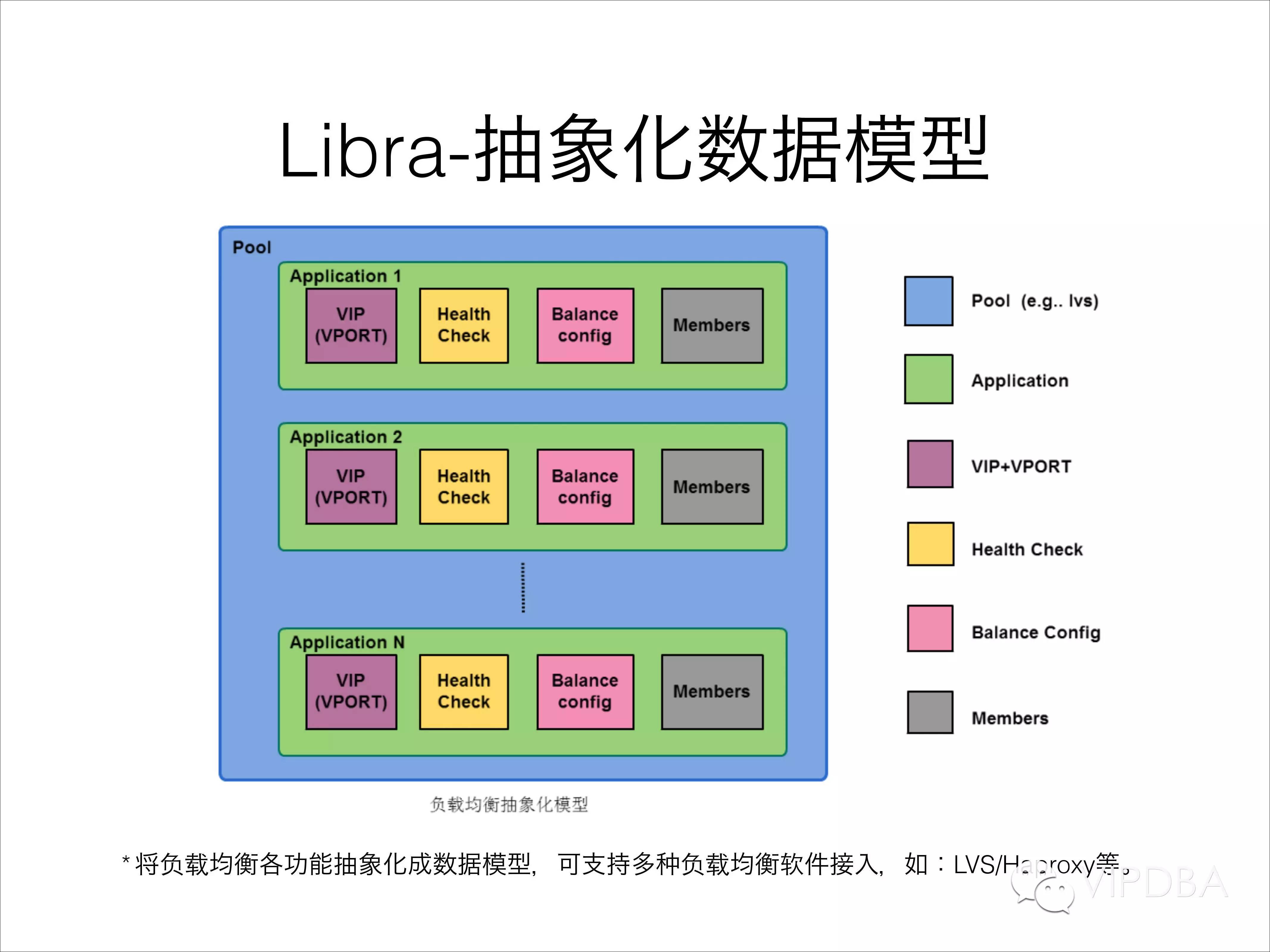
最外层是Pool,负载均衡池的抽象化,也就是具体的负载均衡服务器的配置。
第二层是Application,应用,每个应用都要部署在具体的负载均衡服务器上,所有Application需要绑定在某个Pool上。
第三层有4个,都是某个具体的应用所需的模块,4个模块组合到一起绑定到一个Application上面,构成一个完整的应用。这4个模块分别是:
VIP+VPORT模块;应用的访问入口,每个应用有一个唯一的vip+vport组合。
Health Check模块;健康检测功能,支持自定义的健康检测模式,TCP/HTTP等方法,具体的健康检测配置设置在这里。
Balance Config模块;负载均衡算法配置功能,例如LVS的DR模式、wlc的负载均衡算法等配置设置在这里。
所以在使用的时候,你需要创建一个Pool,然后创建一个Application,之后分别创建VIP+PORT,health Check,Balance Config和members,最后把他们绑定到一起形成一个完整的配置,然后插件式的配置更新程序就会获取到完整的配置完成整个配置更新到服务重载的过程。使用起来步骤可能会多一点,不过health Check,Balance Config基本上创建几个常用的就够了,几乎所有的业务都可以使用同样的配置,不同的需求不同处理即可。
那Libra的整体架构是什么样子的呢?
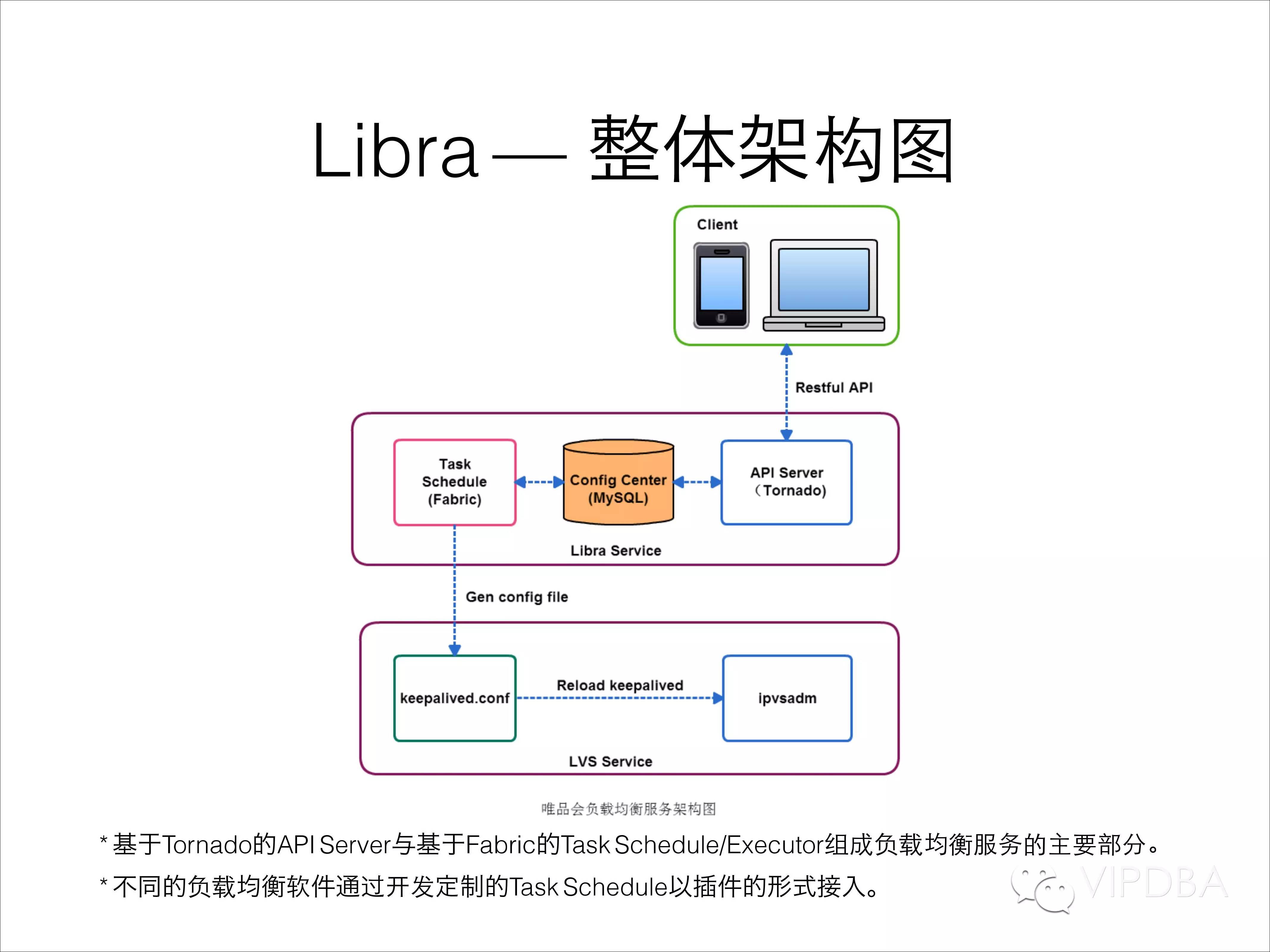
基于Tornado的API Server与基于Fabric的Task Schedule/Executor组成负载均衡服务的主要部分。不同的负载均衡软件通过开发定制的Task Schedule以插件的形式接入。
客户端通过RestfulAPI更新数据到配置数据库MySQL中,任务调度程序会周期性的获取MySQL中的配置变化情况,然后使用Fabric的SSH功能远程更新LVS服务器的配置文件,然后reload keepalived程序。
周期性的更新会有些延时存在,但是可以merge一段时间内的同时请求;当然也支持紧急情况下的实时Real Server配置变更。使用Fabric可以简单方便的解决远程配置更新的操作,使用agent稍微重了些,需要开发额外的agent还需要考虑其存活状态等问题,快速开发的情况下SSH更方便。
最后展示一下Libra的页面:
Libra的价值体现:
* 后端日志前端展示,问题处理简单明了
* LVS的各种常规运维操作不再需要再登录终端敲命令,改配置文件了,全部自动化。
Libra上线后,我们的Twemproxy架构的完整解决方案基本就完成了。
接下来给大家简单分享一下我们在实际运维中遇到的两个不容易发现的问题:
Redis TTL 为0 的问题。

搞Redis运维的应该都清楚,Redis的TTL只会有3钟情况:
TTL = -1 ;这种情况是这个key存在,但是没有设置TTL,也就是没有过期时间的一个key。
TTL = -2 ;这种情况是这个key不存在,可能就没存在过,或者是过期后被清理了。
TTL = 正整数;这种情况是这个key存在,且存在TTL过期时间,那就返回这个key的剩余过期时间。
所以当业务跟你反馈某个集群的Redis出现大量TTL = 0 的情况的时候,还是觉得很神奇的。排查问题无外乎几种方式:
登录服务器确认、自己尝试
查看官方文档
查看源代码
在登录服务器自己尝试确认问题存在,而官方文档有没有相关说明的时候,就只能去源代码中查找原因了;最后确定是Redis2.8版本的bug,Redis在从库开启slave-read-only的时候,所有已经过期的key都还能查到值,且TTL = 0,这个bug已经在Redis3.0版本中fix。
而我们当时正好在进行同步及双写的业务切换过程,所以踩到了这个坑里,在核心业务使用TTL的请务必注意这个问题。
2. Twemproxy所有请求都超时的问题。
这个问题也比较难排查,我们在线上测试的时候将Twemproxy后端的某个MC实例用iptables封住,然后发现一段时间内所有的请求都timeout了。整体的架构来说,MC是多分片,Twemproxy也是多节点,但是所有的Twemproxy都出现Timeout现象。同时所有的Twemproxy内存急速剧增(达到10几个G),在不做任何处理的情况下15分钟后又都自动恢复了。
经过我们一系列的排查发现问题是由于我们没有设置Twemproxy的Timeout参数所致,后端的单点MC hang住会导致到该请求的Twemproxy超时,而Twemproxy的处理逻辑是串行的,Request一直增加,Response没有返回的情况下,大量请求的数据存储在Twemproxy的内存里,造成了其内存剧增,只要这个Twemroxy有请求被路由到那个问题MC里面,这个Twemproxy以后的所有请求,都会超时。而15min后自动恢复的问题是因为TCP RTO的retry设置决定的,默认的超时都会在15min左右,15min之后twemproxy才认为请求超时而进行了自动剔除操作。
所有各位如果有使用Twemproxy的一定要记得设置Timeout参数,不同的业务需求可以设置不同的阈值。
两个简单的疑难问题跟大家分享一下,希望可以对各位有所帮助。
最后这个发展与展望部分,其实可以深化讨论很多内容,时间关系就简单说两句:
运维模板化、智能化;运维自动化的后面两个阶段,前面说过模版化阿里云做的挺好的,其实就是将独立的api服务通过各种拼接的方式实现多个常用的运维模版,类似ansibe的任务处理方式;而智能化应该是一个一段时间内可望而不可及的事情,不过仍然是一个需要长期关注的方向。
Redis Cluster/Tair/Gemfire/Others集群方案;前面也说过Twemproxy模式的各种问题,主流的技术实现最好还是基于客户端模式来解决,因此我们也在考虑新的集群解决方案,Redis3.0和Tair或许都是不错的解决方案。
Mesos+Docker资源隔离与资源调度;目前的资源隔离和调度都还差很多,前段时间看到芒果TV自研的类似Mesos+Docker+RedisCluster的系统后感触良多,服务资源隔离、秒级调度、弹性扩缩容等等,这也是我接下来重点关注的方向。
革自己的命 — from 诸超;我们总监总说一句话,革自己的命,其实就是说把我们日常的运维都自动化掉、产品化掉,让业务自己去管理、自己去监控,出了问题后NOC团队可以解决一部分,最后才会我们去解决,用这部分时间去做一些之前没有做过的事情。大部分团队离这个方向都很远,这也是我们不遗余力推进自动化的原因之一。
以上就是我今天分享的全部内容,有些啰嗦,内容还是比较简单基础,很多没有深入讨论,有兴趣的朋友可以关注的我微博或微信,我们私下讨论,谢谢。
以上是关于唯品会NoSQL平台自动化发展及运维经验分享的主要内容,如果未能解决你的问题,请参考以下文章
资源消耗降低2/3,Flink在唯品会实时平台的应用(有彩蛋)