技术分享武新:深度解析SQL与NoSQL的融合架构产品GBase UP
Posted IT168企业级
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享武新:深度解析SQL与NoSQL的融合架构产品GBase UP相关的知识,希望对你有一定的参考价值。
本文整理自DTCC2016主题演讲内容,录音整理及文字编辑IT168@杨璐。如需转载,请先联系本公众号获取授权!
第五批“国家千人计划” 专家,法国奥尔良大学、法国国家科研中心博士,资深数据库专家,主导设计和研发了GBase 8a 列存储数据库, GBase 8a MPP Cluster大规模并行数据库集群等一系列产品。曾在甲骨文公司(法国)工作11年。
大家上午好,我是南大通用的CTO武新,非常高兴也非常荣幸的代表公司来给大家汇报一下我们下午即将发布的一款新产品,这里我提前把产品的一些细节分享给大家。
要发布的产品是面向企业和行业的用户,我们认为是一款行业和企业用户真正需要的大数据平台产品。它的名字叫GBase UP,UP是Unified Platform,我们希望能把关系型数据库和NoSQL的一些子系统和技术融合在一个产品里面。
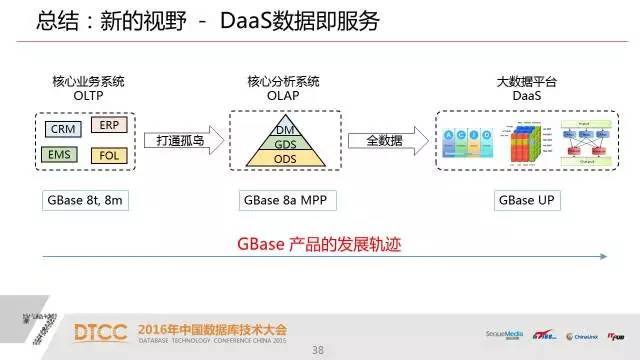
经过几十年的发展,我们其实已经建立了很多很成熟的业务系统和应用系统。这些业务系统的建设其实过去一直是以事务型的方式在建设,也就是说,首先要满足我们的业务需求,这种业务系统往往是以传统数据库,以交易型为主,其数据强调自身的、局部的完整性和一致性。
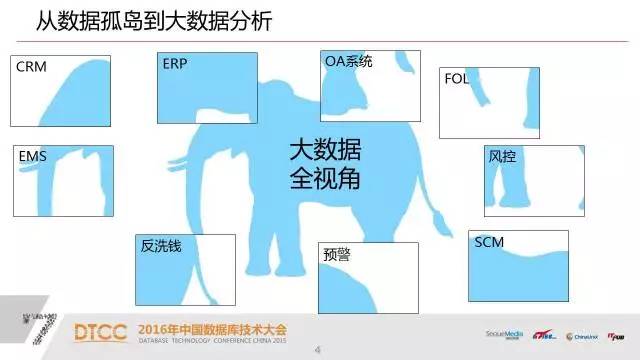
这就对我们今天的数据分析产生了一个矛盾的地方。因为每个业务系统只有我们这个企业的一部分数据,我们的数据分析需要的是在全局数据里面挖掘出信息。从大数据角度来说,我们认为可能是一个全视角的需求。
那么怎么把数据孤岛打通,汇总在一起,真正在上面进行我们全视角的大数据分析,其实这是一个我们现在的业务系统和大数据分析的一个矛盾。
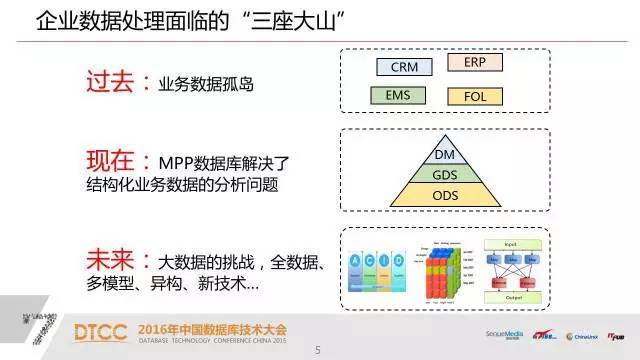
1、我们过去建立了很多数据孤岛,这些数据孤岛我们还继续在建设,因为我们的业务系统在企业里面基本上是按具体业务去设计,去应用的,他很少考虑全视角的建设;我们做这个数据分析的时候,我们就需要把这些数据孤岛打通。过去一个方法是做数据仓库,已将近二十年历史了。在做数据仓库的时候常常面临的性能问题,跟传统数据库的体系架构还是有关系的。
2、用新一代基于MPP架构的数据库产品,我们其实解决了大型数据仓库的效率问题和规模问题。这样我们可以把我们一些业务系统的数据真正汇总在一个平台上进行全视角的分析。
3、未来,其实未来也就是现在,面临着大数据的挑战,我们认为大数据不仅仅是关系型数据库产生的数据,不仅仅是当前业务产生的数据,还有其他来源的数据。这些数据和我们的业务数据怎么进行关联,这些数据可能需要不同的模型来处理,还有一些异构的技术,包括一些新的技术也层出不穷。其实这些都是我们企业今天面临的挑战。
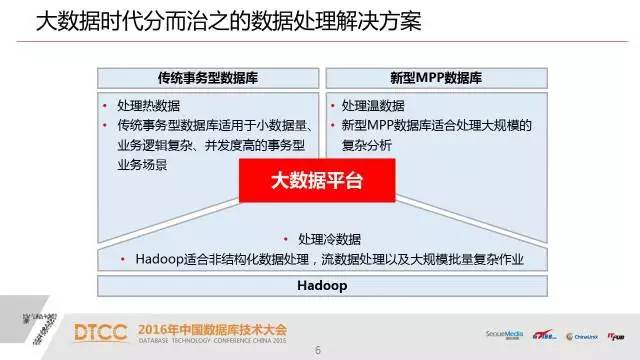
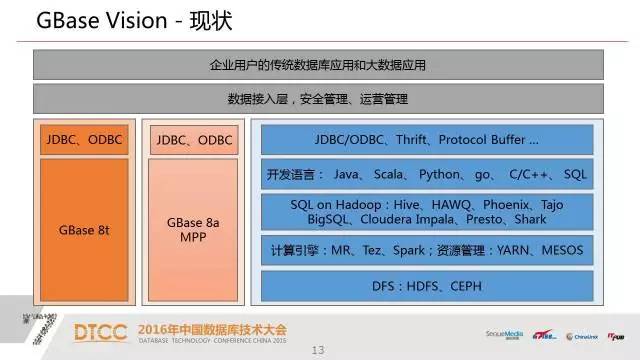
1、传统的事务型数据库,这一类数据库已非常成熟,也是目前在企业里交易系统最核心的数据库产品。
2、新型的MPP数据库产品,是基于大规模并行计算和横向扩展的架构这样一类数据库产品。
3、hadoop,hadoop长处是有些关系型数据库解决不了或者是处理不了的一些问题他能处理。
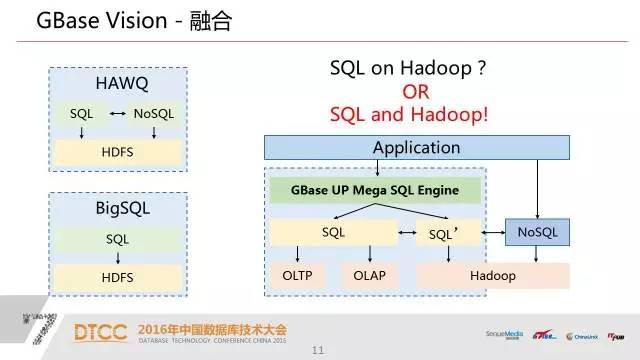
既然这三种技术之间目前还没有一种技术能完全替代其他的技术,那么对大数据平台的需求自然就是这三种技术融合在一起,这是我们的一个想法,也是我们针对这样一个想法实现了我们这个产品。
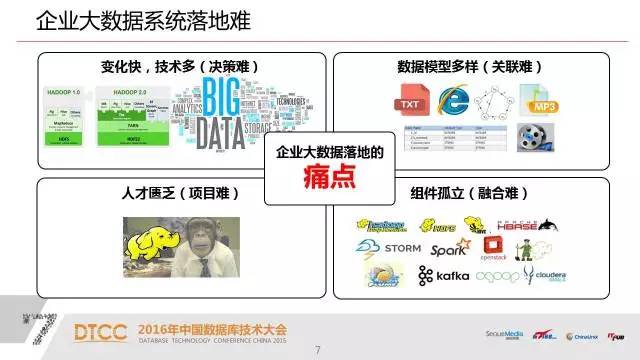
1、大数据的技术变化非常快,对于企业来说,需要一个稳定的平台和技术支持生产系统。
2、在大数据的视角下需要结构化数据和一些半结构化数据甚至非结构化数据提取出来进行各种各样的关联。
4、对于普通企业用户来说,还有一个问题就是系统开发和技术支持方面的人才匮乏。
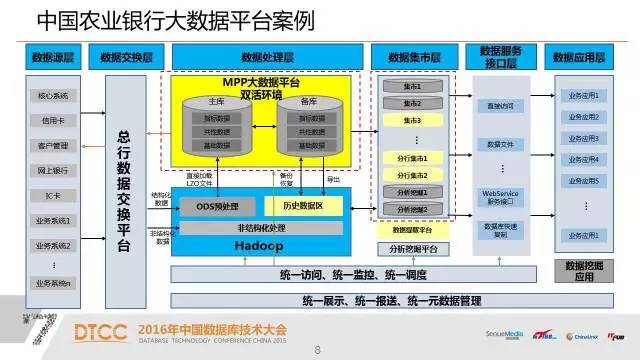
这是一个混搭的架构,左边是农行主要核心业务系统,大概有两百多个。那么这些核心业务系统都属于一些孤岛式的业务系统,他每个业务系统只是企业数据的一部分,通过我们现在这个MPP的平台来把这些所有的数据汇总在一起,放在一个平台上,建立ODS,然后进行一层一层的汇总,解决了业务数据数据孤岛的问题。
这个案例也用MPP数据库替代了整个传统的关系型数据库,有多个集群,有三到四个MPP数据库集群。从二十多个结点到三四十个结点这样一个规模。
通过UP实现能进一步的降低hadoop和关系型数据库之间融合应用的复杂度,给用户带来真正的价值。
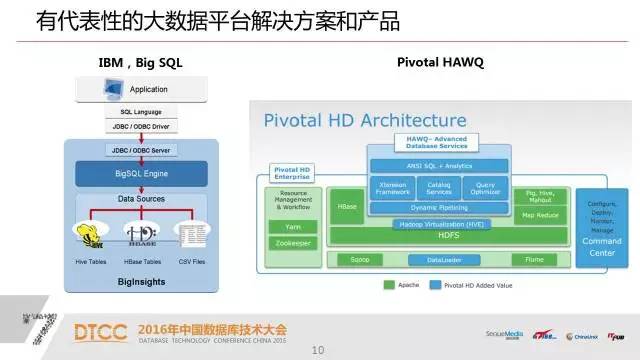
大家在把一些数据库的引擎,包括SQL层嫁接到hadoop上来,主要是嫁接到HDFS上面来。但是缺点大于优点,一是效率问题,一是对事务的支撑能力较弱。第三是处理数据的密度。目前从MPP数据库的角度来说,一个结点已经能够管理一百TB的有效数据了。在用HDFS上架SQL这一层,现在他的密度还是远远低于这样一个MPP数据库的密度。
对于用户价值更大一点的是SQL和hadoop,我们把这个成熟的关系型数据库跟hadoop的生态融合在一个平台上,这是我们UP设计的整体思想。
这样大家用SQL来处理数据会越来越丰富,其实我们丰富了关系型数据库,扩展他的疆域和能力,同时又可以利用hadoop的一些优点来达到大数据的处理效果,这是整体的设计思路。
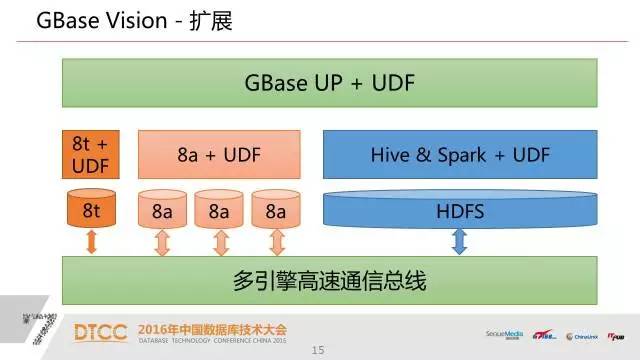
在企业开发应用,还是要用不同的产品。从应用的角度、从开发的角度来说,建立引擎之间的存储和计算通道,是一个难题。
1、UP首先通过融合来简化用户的开发和使用。在几个异构的引擎之间,上层包括统一的API和分布式调度、执行的统一SQL层,中间是异构的一些引擎,底层是数据通信总线。我们的统一SQL层,除了支持传统的SOL数据库意外,还对其他方面进行了扩展。
3、平台的扩展能力,一个是数据交换。我们实现了透明的引擎之间的数据关联和交换;第二是实现全数据的管理,除了结构化数据以外,为半结构化,非结构化数据统一的视角下进行管理;最后是扩展,通过灵活的UDF机制,对平台提供扩展功能。
4、数据生命周期管理实现透明和自动。我们看技术架构:
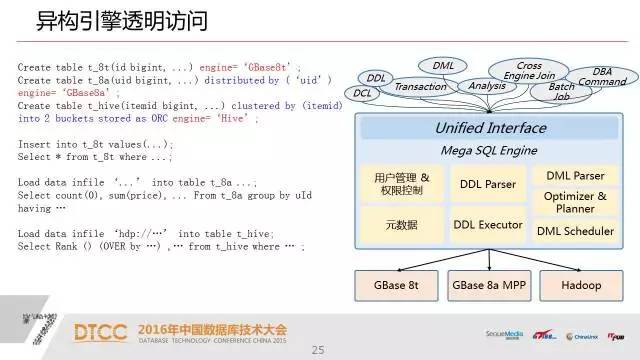
这不是一个简单的路由器或者中间件,这是一个真正的类似MPP风格的分布式数据库。我们上层是一个驱动层,解析从应用过来是SQL,包括标准的SQL和hadoop生态的方言。我们有DDL执行器,我们有DQL和DML优化机和执行器。最底层针对不同的引擎以插件的方式插入到我们这个平台里面来,这样的好处就是我们未来还可以很容易的扩展到其他引擎上面去。
很多DBA对SQL比较熟悉,因此这里用SOL来表达UP的一些能力。先来看看应用场景部分:
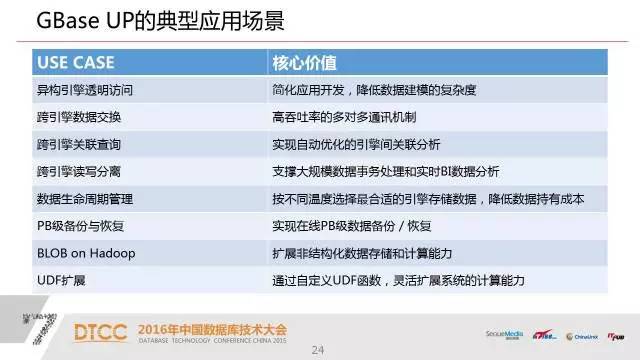
1.异构引擎透明访问 简化应用开发,降低数据建模的复杂度
4.跨引擎读写分离 支撑大规模数据事务处理和实时BI数据分析
5.数据生命周期管理 跨引擎分区表 按不同温度选择最合适的引擎存储数据 降低数据持有成本
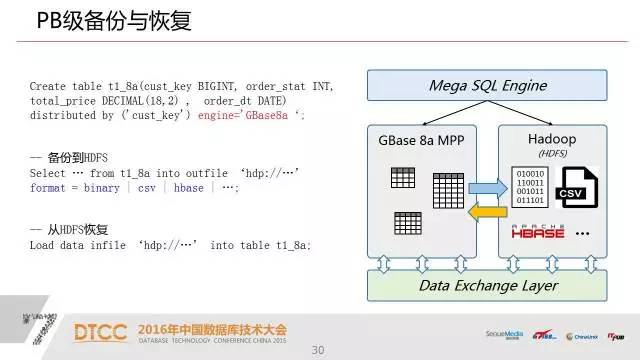
6.PB级备份与恢复 实现在线PB级数据备份与恢复
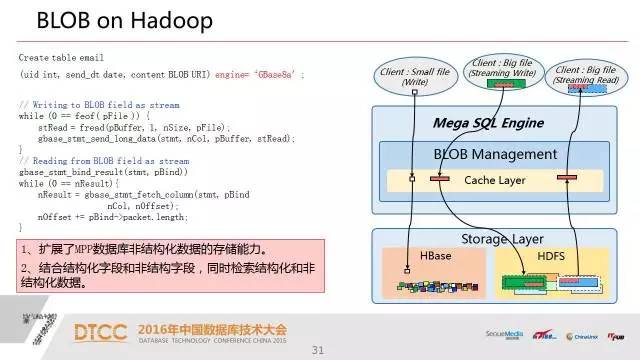
7.BLOB on Hadoop扩展非结构化数据存储和计算能力
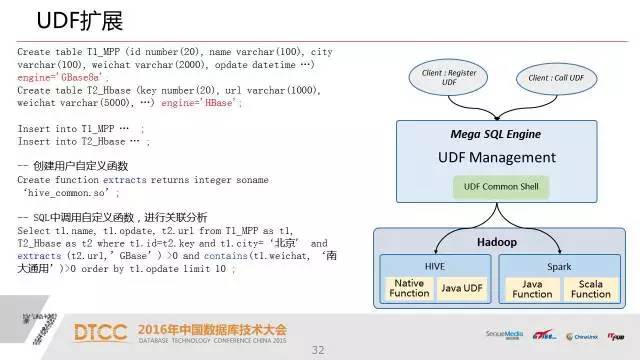
8.UDF扩展 通过自定义UDF函数 灵活扩展系统的计算能力
有了UP以后,我们在建表的时候,我们对SQL进行拓展。建这个表的过程中,他的META DATA(元数据)被我们的UP给存储、管理起来了。对用户来说就完成了,那么剩下的,无论是你做DML操作、数据的加载,还是查询这都变成了完全透明。
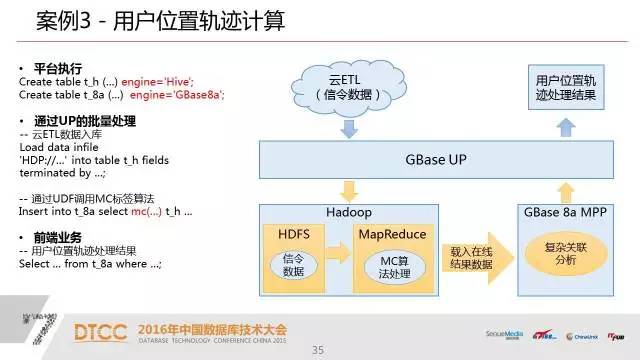
下面几个案例我们就是建了表了以后,我们通过上层的应用就可以很透明的穿透了UP去访问不同的引擎,然后我们可以进行数据的加载。
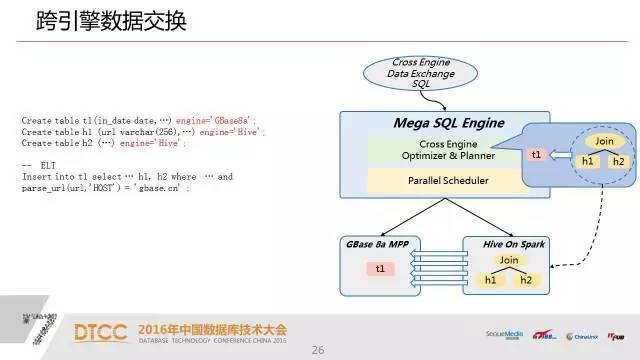
有了这样的一个元数据之后,我们可以很容易的实现跨引擎的数据交换,当然,这种跨引擎数据交换目前没有我们的UP也能做,用户主要是通过ETL,通过复杂调度程序,比如说在hadoop里面先做一些预处理,把计算的结果导入数据仓库里面去。
另外一个就是跨引擎的关联查询,因为我们建完表以后,用户来说就是透明。例如:我们有一个关联,这个关联是在Spark上有两个表,还有一个表是在数据仓库MPP里面,这三个表之间进行了一个关联。那么在这个关联的过程中我们可以看一下,我们的执行计划是在两个集群上进行的并行计算,一个是在hadoop集群上进行计算。同时在MPP上也进行计算,当然两者又都是并行计算。这样我们大大的提升了整个集群的处理的效率。
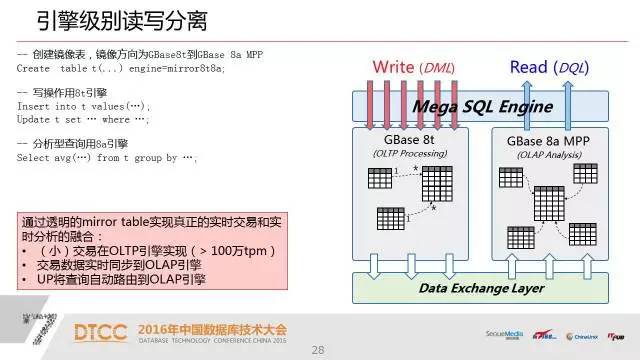
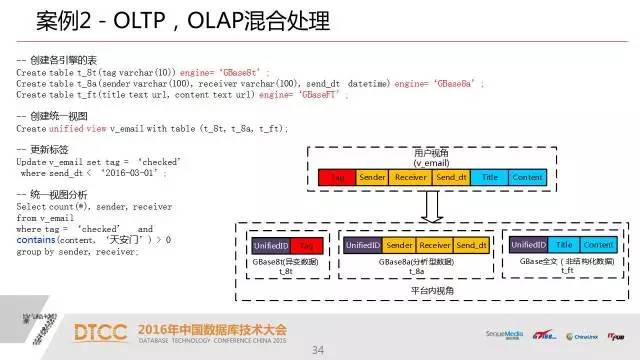
关于实现跨引擎级别的读写分离,在很多的应用场景,不一定需要事务和读的强一致性。
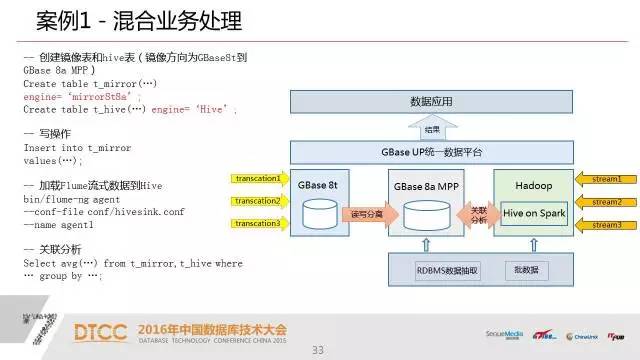
我们的事务操作要保证他的一致性,而在分析业务里面去读刚放产生的数据,而在很多应用里头,两者是可以分开的。我们通过一种叫镜像表的模式,就是同时在OLTP和OLAP两个引擎里面建立,实现一个实时同步的机制。
这就意味着我可以支撑非常高效的DML操作。这样就可以实现比如说实时的高效交易处理和数据分析并存的业务场景。我们通过自己搭积木的方式也能实现这样一个机制,但是从应用角度来说还是非常难的一件事情。
最后一点是UDF的扩展,我们知道在hadoop上,我们很容易扩展一些算法。而且这些算法在关系型数据库里面其实很难实现,效率也不高,这点我们通过UP的扩展,也就是说我们在hadoop上面可以用任何语言写一个函数。比如说写一个算法,在我们的UP上进行注册,那么我们这个函数和算法就可以用SQL来进行调用了,这样大大扩展了我们关系型数据库处理能力。
关系型数据库仍然是最成熟,处理数据效率最高的系统,是我们核心业务的支撑平台。在可见的未来我相信这个也不会很快的改变。
另外SQL也作为应用使用最广泛的数据处理语言,所以我们也看到了,除了关系型数据库的SQL在继续丰富外,我们现在把它拓展到hadoop的生态里面去了。
无论是什么类型的数据,包括一些非结构化的数据,我们把他的一些特征提取出来,就是常说的转非。这些特征数据和其他的一些数据进行关联分析也是最容易的,这也的确是我们面对的现状。
最后一点就是大数据的处理就要满足高效的数据采集和存储,这跟事务是有关系的。同时要满足全视角的数据分析,成熟的融合是大数据平台的一个核心。从GBase角度来说我们希望最终给用户提供完整的视角,其实用户不需要关心用什么样的技术去存储和管理数据。用户需要的是能不能高效存取,然后数据能有完整性和一致性,最终进行高效的各种各样的关联分析,这也是GBase UP这个产品要给用户带来的最终价值。
中国数据库技术大会(DTCC)是目前国内数据库与大数据领域最大规模的技术盛宴,于每年春季召开,迄今已成功举办了七届。大会云集了国内外顶尖专家,共同探讨mysql、NoSQL、Oracle、缓存技术、云端数据库、智能数据平台、大数据安全、数据治理、大数据和开源、大数据创业、大数据深度学习等领域的前瞻性热点话题与技术,吸引IT人士参会5000余名,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供了极具价值的交流平台。
以上是关于技术分享武新:深度解析SQL与NoSQL的融合架构产品GBase UP的主要内容,如果未能解决你的问题,请参考以下文章
SQLNewSQL和NoSQL融合研究与实践(有彩蛋)
GaussDB NoSQL架构设计分享
深度解析SQL和NoSQL数据库,掌握主流数据库两万字解析
NoSQL 之于大数据
深度解析 NoSQL 与 AWS
深度解析区块链数字票据及其优势