基于SparkNoSQL的实时数据处理实践
Posted TalkingData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于SparkNoSQL的实时数据处理实践相关的知识,希望对你有一定的参考价值。
.jpg")

本文由TalkingData原创,转载请获取授权。
本文基于TalkingData 张学敏 在公司内部KOL的分享主题《基于Spark、NoSQL实时数据处理实践》的整理,同时也在DTCC大会上做了同主题的分享。
主要介绍了项目的技术选型、技术架构,重点介绍下项目面临的挑战和解决办法,还介绍了面对多维度、多值、多版本等业务场景时,使用Bitmap与HBase特性解决问题方法。
共分为上下两篇,本次发布上篇,下篇敬请关注。
一、数据相关情况
 项目处理的数据主要来源于TalkingData的三条SASS业务线,他们主要是为移动应用开发者提供应用的统计分析、游戏运营分析以及广告监测等能力。开发者使用TD的SDK将各种事件数据发送过来,然后再通过SASS平台使用数据。
项目处理的数据主要来源于TalkingData的三条SASS业务线,他们主要是为移动应用开发者提供应用的统计分析、游戏运营分析以及广告监测等能力。开发者使用TD的SDK将各种事件数据发送过来,然后再通过SASS平台使用数据。

数据主要都和智能设备相关,包含的数据内容主要可以分为三部分,一部分是设备信息类,主要包括设备ID,比如Mac、IDFA等,还有设备的软硬件信息,比如操作系统版本号,屏幕分辨率等。另一部分是业务相关信息类,主要包括业务事件,会话信息,还有行为状态。关于行为状态,是我们在智能设备上使用算法推测终端持有者的行为状态信息,比如静止、行走、奔跑、乘车等。第三部分是上下文信息,包括设备连接网络的情况,使用的是蜂窝网络还是WiFi等,还有设备位置相关的信息,以及其他传感器相关的数据等。

关于设备体量,目前设备日活月活分别在2.5亿和6.5亿以上,每天的事件数在370亿左右,一天数据的存储量是在17T左右。
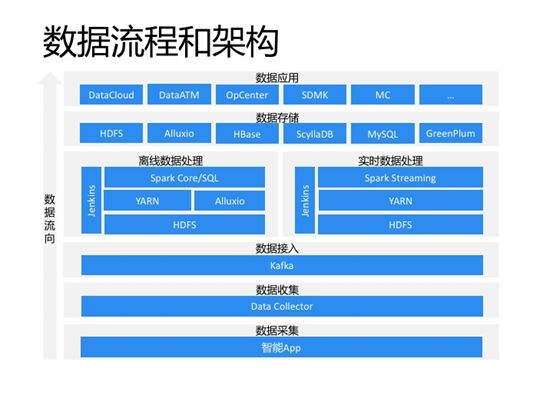
上图为整体的数据架构图,数据流向是自下往上。数据采集层使用的是TalkingData自研的SDK,通过SDK将数据发往数据收集层。数据收集层使用的是TalkingData自研的DataCollector,Collector会将数据发送到数据接入层的Kafka。每个业务线都有自己的Kafka集群,在Collector可以控制数据的流向,大多数据都是业务线一份,数据中心一份。数据处理层有两部分,一部分是使用Spark core或sql的离线计算。其中Spark是on yarn模式,使用yarn进行资源管理,中间通过Alluxio进行加速,使用Jenkins进行作业管理和调度,主要负责为业务方提供数据集和数据服务。
另一部分是使用Spark Streaming的实时计算,主要是为TalkingData管理层提供运营数据报表。数据存储层,主要功能是存放数据处理后的结果,使用分布式文件系统HDFS、Alluxio存放数据集,使用分布式数据库HBase、ScyllaDB,关系型数据库mysql以及MPP型数据库GreenPlum存放服务相关的数据。数据应用层东西就比较多了,有供TalkingData内部使用的数据分析、探索平台,也有对外内外都可的数据服务、数据模型商城,以及智能营销云、观象台等。
二、项目面临的业务诉求

主要的可总结为四部分:
首先是数据修正:离线计算是将数据存放在了HDFS上,如果数据有延迟,比如事件时间是昨天的数据今天才到,那么数据将会被错误的存放在今天的时间分区内。因为HDFS不支持随机读写,也不好预测数据会延迟多久,所以在离线计算想要完全修正这些数据,成本还是比较高的。
其次是时序数据需求:之前的业务都是以小时、天、周、月等时间周期,面向时间断面 的宏观数据分析,随着公司业务扩展,比如营销、风控等行业,面向个体的微观数据分析的需求越来越多,所以需要能够低成本的把一个设备的相关的数据都取出来做分析。而面向时间断面的数据每天十几T,想从中抽出某些设备近1个月的数据就会涉及到500多T的数据。所以需要建立时序数据处理、查询的能力,能方便的获取设备历史上所有数据。
第三是实时处理:离线计算少则延迟一个小时,多则一天或者更久,而有些行业对数据时效性要求是比较高的,比如金融、风控等业务,所以需要实时数据处理。同时,为了更多的丰富设备位置相关数据,我们还建立了WiFi、基站等实体的位置库,所以在实时数据处理时,需要实时读取这些库为那些连接了WiFi、基站但没位置数据的设备补充位置相关信息。
第四是实时查询,这里描述的是面向实体、多维度、多值、多版本,接下来我详细介绍下。

我们将事件数据抽象出了各种实体,比如设备、位置、WiFi基站等实体,其中位置实体可以使用GeoHash或者网格表达。每个实体都有唯一ID以及多个维度信息,以设备实体为例,包括ID、软硬件信息等维度。单个维度又可能会包含多个值,比如WiFi,在家我连接的是WiFi1,到公司链接的是WiFi2,所以WiFi维度有WiFi1和WiFi2两个值。单个值又可能有多个时间版本,比如我在家连接WiFi1可能6点被捕获到一次,7点被捕获到两次。所以,最终建立可以通过指定实体ID,查询维度、列及时间窗口获取数据的能力。
三、技术选型和架构
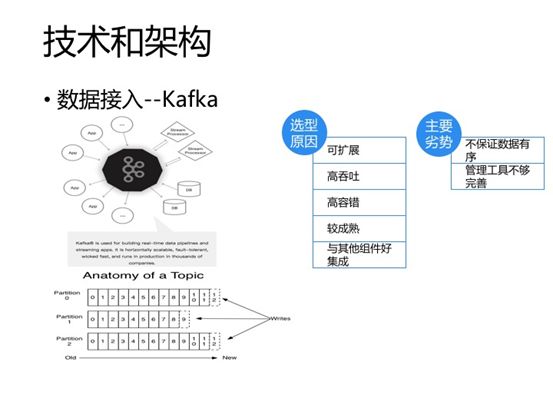
数据接入层我们选择的是Kafka,Kafka在大数据技术圈里出镜率还是比较高的。Kafka是LinkedIn在2011年开源的,创建初衷是解决系统间消息传递的问题。传统消息系统有两种模型,一种是队列模型,一种是订阅发布模型。两者各有优缺,比如队列模型的消息系统可以支持多个客户端同时消费不同的数据,也就是可以很方便的扩展消费端的能力,但订阅发布模型就不好扩展,因为它是使用的广播模式。另一个就是,队列模型的消息只能被消费一次,一旦一个消息被某个消费者处理了,其他消费者将不能消费到该消息,而发布订阅模型同一消息可以被所有消费者消费到。Kafka使用Topic分类数据,一个Topic类似一个消息队列。Kafka还有个概念,叫consumer group,一个group里可以有多个消费者,同一个topic可以被一个group内的多个消费者同时消费不同的消息,也就是类似队列模型可以方便的扩展消费端能力。一个Topic也可以被多个group消费,group之间相互没有影响,也就是类似发布订阅模型,Topic中的一条消息可以被消费多次。所以Kafka等于说是使用Topic和Consumer group等概念,将队列模型和订阅发布模型的优势都糅合了进来。
现在Kafka官方将Kafka的介绍做了调整,不再满足大家简单的将其定位为消息队列,新的介绍描述是:可以被用来创建实时数据管道和流式应用,且具有可扩展、高容错,高吞吐等优势。另外,经过7年的发展,kafka也比较成熟了,与周边其他组件可以很方便的集成。但目前也有两个比较明显的劣势,一个是不能保证Topic级别的数据有序,另一个是开源的管理工具不够完善。
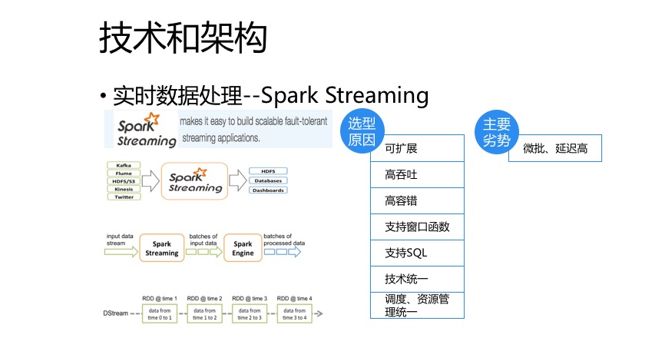
Spark现在听起来不像前几年那么性感了,但因为我们离线计算使用的Spark,有一定的技术积累,所以上手比较快。另外,Spark Streaming并不是真正意义上的流式处理,而是微批,相比Storm、Flink延迟还是比较高的,但目前也能完全满足业务需求,另外,为了技术统一,资源管理和调度统一,所以我们最终选用了Spark Streaming。
Spark Streaming是Spark核心API的扩展,可实现高扩展、高吞吐、高容错的实时流数据处理应用。支持从Kafka、Flum、HDFS、S3等多种数据源获取数据,并根据一定的时间间隔拆分成一批批的数据,然后可以使用map、reduce、join、window等高级函数或者使用SQL进行复杂的数据处理,最终得到处理后的一批批结果数据,其还可以方便的将处理结果存放到文件系统、数据库或者仪表盘,功能还是很完善的。
Spark Streaming将处理的数据流抽象为Dstream,DStream本质上表示RDD的序列,所以任何对DStream的操作都会转变为对底层RDD的操作。

HBase是以分布式文件系统HDSF为底层存储的分布式列式数据库,它是对Google BigTable开源的实现,主要解决超大规模数据集的实时读写、随机访问的问题,并且具有可扩展、高吞吐、高容错等优点。HBase这些优点取决于其架构和数据结构的设计,他的数据写入并不是直接写入文件,当然HDFS不支持随机写入,而是先写入被称作MemStore的内存,然后再异步刷写至HDFS,等于是将随机写入转换成了顺序写,所以大多时候写入速度高并且很稳定。
而读数据快,是使用字典有序的主键RowKey通过Zookeeper先定位到数据可能所在的RegionServer,然后先查找RegionServer的读缓存BlockCache,如果没找到会再查MemStore,只有这两个地方都找不到时,才会加载HDFS中的内容,但因为其使用了LSM树型结构,所以读取耗时一般也不长。还有就是,HBase还可以使用布隆过滤器通过判存提高查询速度。
HBase的数据模型也很有意思,跟关系型数据库类似,也有表的概念,也是有行有列的二维表。和关系型数据库不一样一个地方是他有ColumnFamily的概念,并且一个ColumnFamily下可以有很多个列,这些列在建表时不用声明,而是在写入数据时确定,也就是所谓的Free Schema。
HBase的缺点一个是运维成本相对较高,像compact、split、flush等问题处理起来都是比较棘手的,都需要不定期的投入时间做调优。还有个缺点是延迟不稳定,影响原因除了其copmact、flush外还有JVM的GC以及缓存命中情况。
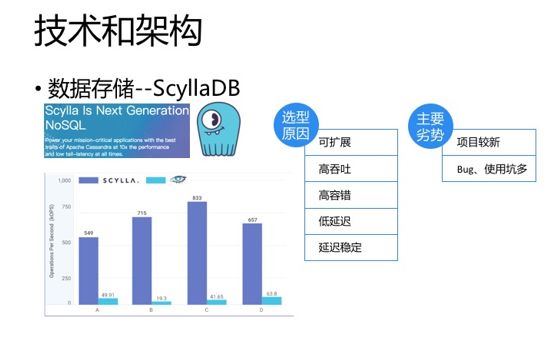
ScyllaDB算是个新秀,可以与Cassandra对比了解,其实它就是用C++重写的Cassandra,客户端完全与Cassandra兼容,其官网Benchmark对标的也是Cassandra,性能有10倍以上的提升,单节点也可以每秒可以处理100万TPS,整体性能还是比较喜人的。与HBase、Cassandra一样也有可扩展、高吞吐、高容错的特点,另外他的延迟也比较低,并且比较稳定。
他和Cassandra与HBase都可以以做到CAP理论里的P,即保证分区容忍性,也就是在某个或者某些节点出现网络故障或者系统故障时候,不会影响到整个DataBase的使用。而他俩与HBase不一样的一个地方在于分区容忍性包证的情况下,一致性与高可用的取舍,也就是CAP理论里,在P一定时C与A的选择。HBase选择的是C,即强一致性,比如在region failover 及后续工作完成前,涉及的region的数据是不能读取的,而ScyllaDB、Cassandra选择的A,即高可用的,但有些情况下数据可能会不一致。所以,选型时需要根据业务场景来定。
ScyllaDB的劣势也比较明显,就是项目比较新,Bug和使用的坑比较多, 我在这里就不一一去说了。
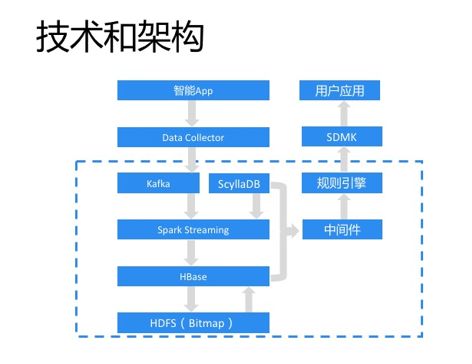
前面分别简单介绍了选定的技术组件,及他们的优缺点,最终项目整体架构如上图所示,数据流向用灰色箭头代表,数据采集和收集都与离线计算一样,不同的是在Spark Streaming从Kafka消费数据时,会同时实时从ScyllaDB读取wifi、基站定位库的数据参与位置补充的计算,然后将处理的结果数据写入HBase。再往下类似Lambda架构,会对HBase中的数据离线做进一步的处理,然后再将数据离线通过Bulkload方式写入HBase,关于其中的Bitmap应用,后边再聊。
架构右边部分是服务相关的,首先是中间件,主要屏蔽了异构数据库对应用层服务的影响,再往上是规则引擎服务,因为我们上线在SDMK的应用服务有100多个,导致服务管理成本很高,并且也不利于物理资源的合理运用,所以上线了规则引擎服务,将所有服务的业务逻辑都通过规则表达,这样上线新服务就不需要重新申请服务器,只需要添加一条规则即可。等于是就将一百多个服务转换成了一个服务,当规则引擎负载较高时或者大幅降低后,可以很方便的进行资源的扩充和减少。SDMK是TalkingData研发的类似淘宝的交易平台,公司内、外的数据服务、数据模型都可以像商品一样在上面进行售卖。
推荐阅读
以上是关于基于SparkNoSQL的实时数据处理实践的主要内容,如果未能解决你的问题,请参考以下文章