NoSQL之Redis入门
Posted Linux土著运维攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NoSQL之Redis入门相关的知识,希望对你有一定的参考价值。
Redis
1.Redis介绍
1.1 NoSQL:一类新出现的数据库(not only sql),它的特点
不支持sql语法
存储结构跟传统关系型数据库中的那种关系表完全不同,nosql中存储的数据都是key value形式
NoSQL的世界中没有一种通用的语言,每种nosql数据库都有自己的api和语法,以及擅长的业务场景
NoSQL中的产品种类相当多:
MongoDB
Redis
Hbase hadoop
Cassandra hadoop
1.2 Redis简介
Redis是一个开源的使用ANSI C语言编写,支持网络,可基于内存亦可持久化的日志型,key-value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作有Vmware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
Redis是NoSQL技术阵营中的一员,它通过多种键值类型来适应不同场景下的存储需求,借助一些高层级的接口使用其可以胜任,如缓存、队列系统的不同角色
1.3 Redis特性
Redis与其他key – value 缓存产品由以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
1.4 NoSQL和SQL数据库的比较
适用场景不同:sql数据库适合用于关系特别复杂的数据查询场景,nosql反之
“事务”特性的支持:sql对事务的支持非常完善,而nosql基本不支持事务
两者在不断地取长补短,呈现融合趋势
1.5 Redis优势
性能极高-Redis能读的速度是110000次/s,写的速度是81999次/s。
丰富的数据类型-Redis支持二进制案例的strings,lists,hashes,sets及ordered sets数据类型操作。
原子-Redis的所有操作都是原子性的,同时还支持对几个操作全并后的原子性执行。原子性就是操作没有多进程多线程。
丰富的特性-Redis还支持publish/subscribe 通知,key过期等等特性。
1.6 Redis应用场景
用来做缓存(ehcache/memcached)--redis的所有数据是放在内存中的(内存数据库)
可以在某些特定应用场景下替代传统数据库—比如社交类应用
在一些大型系统中,巧妙地实现一些特定的功能:session共享,购物车
只要你有丰富的想象力,redis可以给你无限的惊喜
2.Redis安装
我们安装两台为之后的主从和集群做准备
系统:CentOS 7
服务器:2台
关闭selinux,关闭防火墙...基础优化~
安装目录:/usr/local/
安装包版本:redis-3.2.12.tar.gz(比较稳定的3.2)
cd /usr/local/
wget http://download.redis.io/releases/redis-3.2.12.tar.gz
tar xf redis-3.2.12.tar.gz
cd redis-3.2.12
make && make install
mkdir /etc/redis
cp redis.conf /etc/redis/redis.conf
/usr/local/bin 下会出现这些程序
redis-server redis服务器启动命令
redis-cli redis命令行客户端
redis-benchmark redis性能测试工具
redis-check-aof AOF文件修复工具
redis-check-rdb RDB文件检索工具
redis-sentinel redis哨兵进程(用于主从自动切换)
3.Redis核心配置
我修改成适合学习的环境
绑定ip:默认本地访问,我们方便连接先绑定本地ip访问,正式环境可以按需求绑定ip
bind 172.16.1.74
端口,默认为6379,正式环境可以改成其他端口,增加安全性
port 6379
是否以守护进程运行,当然要,好处是退出终端程序不会停止默认是no,这里我们设置成yes
daemonize yes
数据文件
dbfilename dump.rdb
数据文件存储路径 默认./ 我们修改自己指定的路径
dir /backup/redis
日志文件
logfile /var/log/redis/redis-server.log
数据库,默认有16个
database 16
主从复制配置,先不打开
#slaveof
我们创建一下需要的目录
mkdir /backup/redis/ /var/log/redis -p
其他详细配置介绍参考
https://blog.csdn.net/ljphilp/article/details/52934933
4.服务器和客户端命令
服务器端的命令为redis-server
可以使用help查看帮助文档
redis-server –help
启动
redis-server /etc/redis/redis.conf
停止
ps -ef|grep redis 查看pid
kill -9 pid
连接
redis-cli
测试:输入ping 返回PONG为OK
PONG
默认用第一个数据库
切换数据库 数据库没有名称,默认有16个 通过0-15来标识,连接redis默认选择第一个数据库
select n #n为数据库编号
其他详细配置介绍参考
https://blog.csdn.net/ljphilp/article/details/52934933
5.数据操作
5.1数据结构
redis是key-value的数据结构,每一条数据都是一个键值对
键的类型是字符串
注意:键不能重复
值得类型分为五种:
字符串string
哈希hash
列表list
集合set
有序集合zset
数据库操作行为
保存
修改
获取
删除
中文网参考:http://redis.cn/commands.html
5.3string类型
5.3.1保存值
如果设置的键不存在则为添加,如果设置的键已经存在则修改
设置键值
set key value
例:设置键为name 值为wsy的数据
set name wsy
设置键值及过期时间,以秒为单位
setex key seconds value
例:设置键为age 值为20过期时间为3秒的数据
设置多个键值
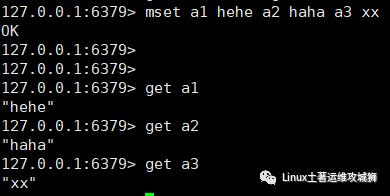
mset key1 value1 key2 value2
例:设置键为a1值为haha、键为a2值为hehe、键为a3值为xx
追加值
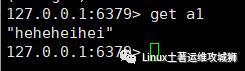
append key value
例:向a1 中追加值 heihei
append a1 heihei
5.3.2获取值
获取:根据键获取值,如果不存在此键则返回nil
get key
例:获取键name的值
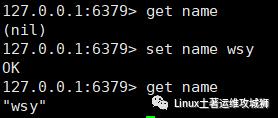
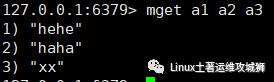
根据多个键获取多个值
mget key1 key2
例:获取键a1、a2、a3的值
5.4键命令
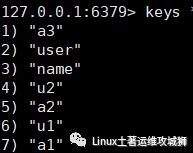
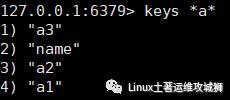
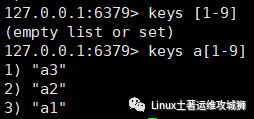
查找键,参数支持正则表达式
keys pattern
例:查看所有键
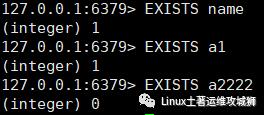
判断键是否存在,如果存在返回1,不存在返回0
exists key1
例:判断键是否存在
删除键及对应的值
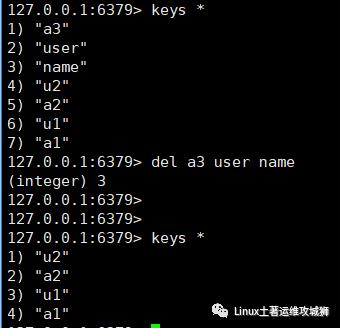
del key1 key2
例:删除键a3 user name
设置过期时间,以秒为单位,如果没有指定过期时间则一直存在,直到使用DEL移除
expire key seconds
例:设置键u2 过期时间为5秒
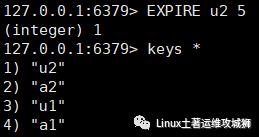
五秒后
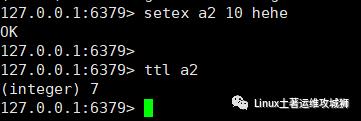
查看有效时间,以秒为单位
ttl key
例:查看键a2的有效时间
5.5hash类型
hash用于存储对象,对象的结构为属性、值
值得类型为string
5.5.1增加修改
设置单个属性
hset key field value
例:设置键user得属性name为wsy
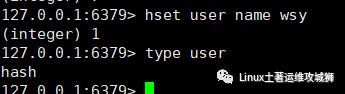
FAQ:

原因:
强制关闭redis快照导致不能持久化。解决方案:
运行config set stop-writes-on-bgsave-error no 命令后,关闭配置想stop-writes-on-bgsave-error解决该问题。
设置多个属性
hmset key field1 value1 field2 value2
例:设置键u2的属性name为wsy、属性age为20

5.5.2获取
获取指定键所有的属性
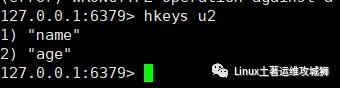
hkeys key
例:获取键u2的所有属性
获取一个属性的值
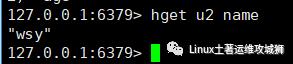
hget key field
例:获取键u2属性name的值
获取多个属性的值
hmget key field1 field2
例:获取键u2属性name、age的值

获取所有属性的值
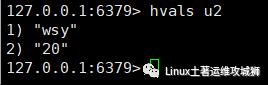
hvals key
例:获取键u2所有属性的值
5.5.3删除
删除整个hash键及值,使用del命令
删除属性,属性对应的值会被一起删除
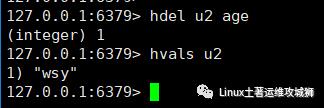
hdel key field1 field2...
例:删除键u2的属性age
5.6 list类型
列表的元素类型为string
按照插入顺序排序
5.6.1 增加
在左侧插入数据
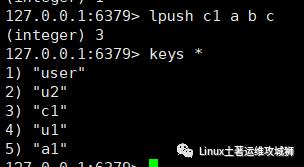
lpush key value1 value2 ...
例:从键为c1的列表左侧加入数据a,b,c
在右侧插入数据
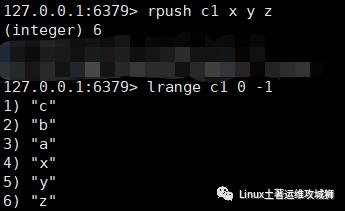
rpush key value1 value2 ...
例:从键为c1的列表右侧加入数据x,y,z
在指定元素的前或后插入新元素
linsert key before 或after 现有元素 新元素
例:在键为c1的列表中元素b前加入3
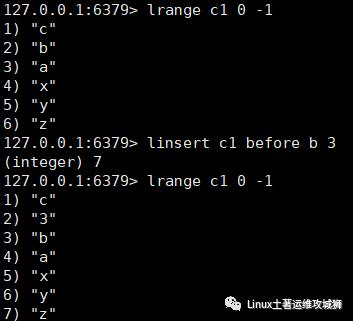
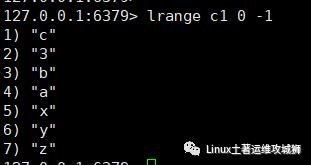
5.6.2 获取
返回列表例的指定范围内的元素
start,stop为元素的下表索引
索引从左侧开始,第一个元素为0
索引可以是负数,表示从尾部开始计数,如-1表示最后一个元素
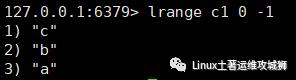
lrange key start stop
例:获取键为c1的列表所有元素
lrange c1 0 -1
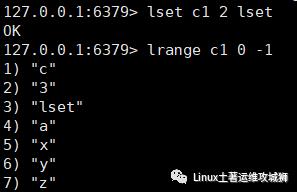
5.6.3 设置指定索引位置元素值
索引从左侧开始,第一个元素为0
索引可以是负数,表示尾部开始计数,如-1表示最后一个元素
lset key index value
例:修改键为c1的列表中下标为2的元素值为lset
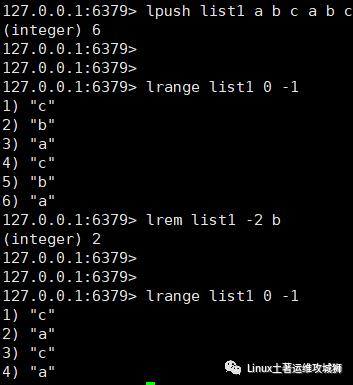
5.6.4 删除
删除指定元素
将列表中前count次出现的值为value的元素移除
count>0:从头往后移除
count<0:从后往前移除
count=0:移除所有
lrem key count value
例:向列表list1中加入元素a,b,c,a,b,c,然后从列表右侧开始删除2个b
5.7 set类型
无序集合
元素为string类型
元素具有唯一性,不重复
说明:对于集合没有修改操作
5.7.1 增加
添加元素
sadd key member1 member2 ...
例:向键set1的集合中添加元素mayun,mahuateng,leijun

5.7.2 获取
返回所有元素
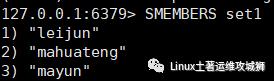
smembers key
例:获取键set1的集合中所有元素
5.7.3 删除
删除指定元素
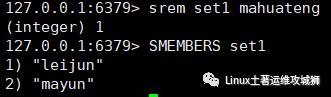
srem key
例:删除键a3的集合中元素mahuateng
5.8 zset类型
sorted set 有序集合
元素为string类型
元素具有唯一性,不重复
每个元素都会关联一个double类型的score,表示权重,通过权重将元素从小到大排序
说明:没有修改操作
5.8.1 增加
添加
zadd key score1 member1 score2 member2
例:向键zset1的集合中添加元素a b c d 权重分别为4 3 5 2

5.8.2 获取
返回指定范围内的元素
start、stop为元素的下表索引
索引从左侧开始,第一个元素为0
索引可以是负数,表示从尾部开始计数,如-1表示最后一个元素
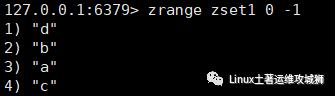
zrange key start stop
例:获取zset1的集合中所有元素
返回score值在min和max之间的成员
zrangebyscore key min max
例:获取zset1集合中score 2-3之间得成员

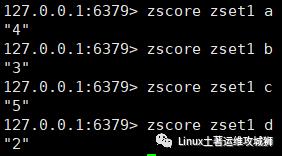
返回成员member的score值
zscore key member
例:获取zset1集合中a b c d 的score值
5.8.3 删除
删除指定元素
zrem key member1 member2 ...
例:删除集合zset1中元素b
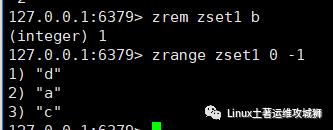
删除权重在指定范围的元素
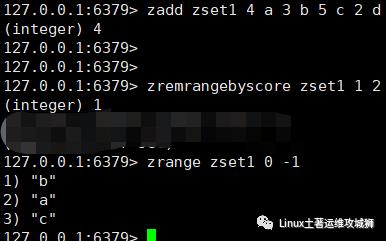
zremrangebyscore key min max
例:删除集合zset1中权限为1,2的元素
命令参考文档:http://doc.redisfans.com/
6.redis主从多实例配置
6.1主从概念
一个master可以有多个slave,一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构
master用来写数据,slave用来读数据,每次主写入数据都会同步到从服务器,经统计:网站的读写比率时10:1
通过主从配置可以实现读写分离
master和slave都是redis实例(redis服务)
6.2多实例
同一个服务用不同的配置文件启动,监听不同的端口,不同的pid等。
6.3主从配置
主配置文件
其他默认即可,很随意
bind 172.16.1.74
port 6379
pidfile /var/run/redis_6379.pid
cd /etc/redis/
从配置文件
cp redis.conf slave.conf
vim slave.conf
bind 172.16.1.74
port 6380 #同一台服务器监听其他端口
pidfile /var/run/redis_6380.pid
daemonize yes
slaveof 172.16.1.74 6379 #这步必须要加
启动两个实例
redis-server /etc/redis/redis.conf
redis-server /etc/redis/slave.conf
查看主
redis-cli info Replication
# Replication
# 角色 主
role:master
# 几个从
connected_slaves:1
# 从服务的IP 端口
slave0:ip=127.0.0.1,port=6380,state=online,offset=141,lag=1
master_repl_offset:141
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:140
查看从
redis-cli -p 6380 info Replication
# Replication
role:slave
master_host:0.0.0.0
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:211
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
测试
连接主从
因为从库只读所以写入的时候会报错
可以获取到我们在主库set的数据
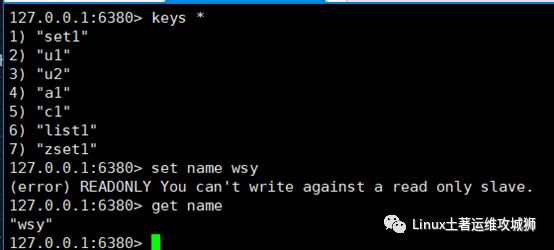
主从配置完毕
7.redis集群
之前我们已经掌握主从的概念,一主可以多从,如果同时的访问量过大(1000w),主服务器肯定会挂掉,数据服务就怪掉了或者发生自然灾难
概念:集群是一组相互独立的,通过高速网络互连的计算机,它们构成了一个组,并以单一系统的模式加以管理,一个客户与集群相互作用时,集群像是一个独立的服务器,集群配置时用于提高可用性和可缩放性,一句话概括集群:一组通过网络连接的计算机,共同对外提交服务,像一个独立的服务器。
7.1 搭建集群
7.1.1 创建节点
我们创建6个节点(实例):监听端口分别为 7000-7005
主机 redis-01
ip:172.16.1.74
创建节点1配置文件
cd /etc/redis/
vim 7000.conf
port 7000
bind 172.16.1.74
daemonize yes
pidfile 7000.pid
cluster-enabled yes
cluster-config-file 7000_node.conf
cluster-node-timeout 15000
appendonly yes
创建节点2配置文件
cp 7000.conf 7001.conf
修改配置如下
port 7001
bind 172.16.1.74
daemonize yes
pidfile 7001.pid
cluster-enabled yes
cluster-config-file 7001_node.conf
cluster-node-timeout 15000
appendonly yes
创建节点3配置文件
cp 7000.conf 7002.conf
修改配置如下
port 7002
bind 172.16.1.74
daemonize yes
pidfile 7002.pid
cluster-enabled yes
cluster-config-file 7002_node.conf
cluster-node-timeout 15000
appendonly yes
三个文件的配置区别在port pidfile cluster-config-file三项
使用配置文件启动redis服务
启动并检查:
redis-server 7000.conf
redis-server 7001.conf
redis-server 7002.conf

主机 redis-02
创建节点4配置文件
cd /etc/redis/
vim 7003.conf
port 7003
bind 172.16.1.111
daemonize yes
pidfile 7003.pid
cluster-enabled yes
cluster-config-file 7003_node.conf
cluster-node-timeout 15000
appendonly yes
创建节点5配置文件
vim 7004.conf
port 7004
bind 172.16.1.111
daemonize yes
pidfile 7004.pid
cluster-enabled yes
cluster-config-file 7004_node.conf
cluster-node-timeout 15000
appendonly yes
创建节点6配置文件
vim 7005.conf
port 7005
bind 172.16.1.111
daemonize yes
pidfile 7005.pid
cluster-enabled yes
cluster-config-file 7005_node.conf
cluster-node-timeout 15000
appendonly yes
启动并检查:
redis-server 7003.conf
redis-server 7004.conf
redis-server 7005.conf

7.1.2 创建集群
安装ruby
FAQ:不装会失败

ruby编译安装
wget https://cache.ruby-lang.org/pub/ruby/2.5/ruby-2.5.3.tar.gz
tar xf ruby-2.5.3.tar.gz
cd ruby-2.5.3
./configure --prefix=/usr/local/ruby
make && make install
ln -s /usr/local/ruby/bin/ruby /usr/bin/ruby
ln -s /usr/local/ruby/bin/gem /usr/bin/gem
gem install redis #安装ruby的redis接口
开始创建
cp /usr/local/redis/src/redis-trib.rb /usr/local/bin/
redis-trib.rb create --replicas 1 172.16.1.74:7000 172.16.1.74:7001 172.16.1.74:7002 172.16.1.111:7003 172.16.1.111:7004 172.16.1.111:7005
命令replicas 1 :创建1个集群:会分配三个节点,每个节点主从服务 一共6个redis服务
如图 三个主: 172.16.1.74:7000 三个从: 172.16.1.111:7004
172.16.1.74:7001 172.16.1.111:7005
172.16.1.111:7003 172.16.1.74:7002
主节点的槽slots 用于存储数据 一共有16384个槽
172.16.1.74:7000 槽 0-5460
172.16.1.74:7001 槽 5461-10922
172.16.1.111:7003 槽 10923-16383
7.1.3 redis集群写数据原理
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态,每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据
redis集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽(hash slot)的方式来分配的。redis cluster默认分配了16384个slot,当我们set一个key时,会用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是CRC16(key)% 16384。所以我们在测试的时候看到set和get的时候直接跳转到那个端口的节点
redis集群会把数据存在一个master节点,然后在这个master和其对应的salve之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的master节点获取数据,只有当一个master挂掉之后,才会启动一个对应的salve节点,充当master
需要注意的是:必须要三个或以上主节点,否则在创建集群时会失败,并且当存活的主节点数小于总结点的一半时,整个集群就无法提供服务了。
7.1.4 连接集群
任意连接一个节点就进入集群了
redis-cli -h 172.16.1.74 -c -p 7002
写入数据
写入到另一台节点了


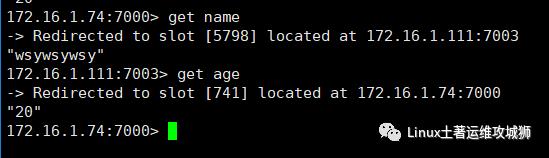
8.python操作redis和redis集群交互
8.1python操作redis
依赖:
yum -y install zlib zlib-devel
yum -y install bzip2 bzip2-devel
yum -y install ncurses ncurses-devel
yum -y install readline readline-devel
yum -y install openssl openssl-devel
yum -y install openssl-static
yum -y install xz lzma xz-devel
yum -y install sqlite sqlite-devel
yum -y install gdbm gdbm-devel
yum -y install tk tk-devel
yum -y install libffi libffi-devel
安装python3和安装redis模块:
wget https://www.python.org/ftp/python/3.6.7/Python-3.6.7.tgz
tar xf Python-3.6.7
cd Python-3.6.7
./configure --prefix=/usr/local/python3
make && make install
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
pip3 install redis
安装python3和redis模块
#!/usr/bin/env python3
import redis
if __name__ == "__main__":
try:
sr = redis.StrictRedis()
"""
#增加key
res = sr.set("name","wsy")
print(res)
#修改
res = sr.set('name','www')
#删除
res = sr.delete('name')
print(res)
#获取
res = sr.get('name')
print(res)
# del duo ge keys
res = sr.delete('user','www')
print(res)
"""
# huoqu suoyou jian
res = sr.keys()
print(res)
except Exception as e:
print(e)
PS:这里的模块操作方法和redis数据类型的命令基本一致
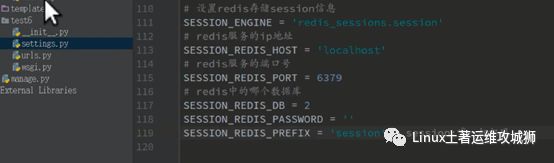
8.2用redis存储django的session
安装包
pip3 install django-redis-sessions
在项目的__init__.py中导入模块
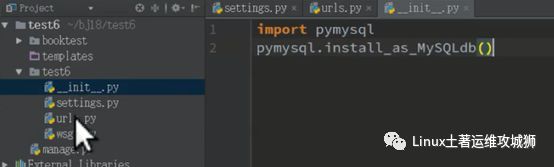
设置settings.py
设置urls
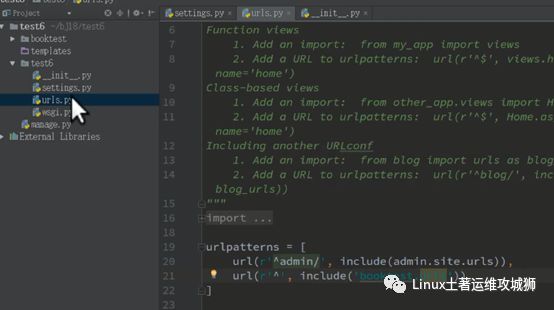
app名称为booktest
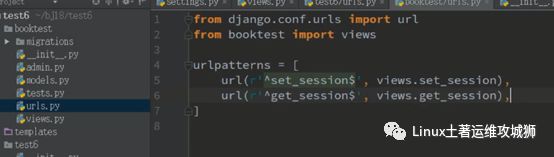
写views设置session读取session
运行,然后去redis查看
session是通过base64加密的,存储在数据库里是一串加密的字符串,我们可以通过在线解码工具来解码
Base64在线解码 http://base64.xpcha.com
8.3python和集群交互
安装redis集群的模块
pip3 install redis-py-cluster
代码:
#!/usr/bin/env python3
from rediscluster import StrictRedisCluster
if __name__ == "__main__":
try:
startup_nodes = [
#连接三个主节点
{'host': '172.16.1.74', 'port': '7000'},
{'host': '172.16.1.111', 'port': '7003'},
{'host': '172.16.1.74', 'port': '7001'},
]
src = StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) #实例化这个redis对象,之后就可以调用所有里边的方法
# 插入数据
result = src.set('name','wwwwwww')
print(result)
# 查询数据
name = src.get('name')
print(name)
except Exception as e:
print(e)
python和redis集群交互
PS:增删改查数据的方法都是redis命令
先就到这里了,更多深入的redis知识已经给出网站自己去挖掘吧。 PS:手指头瑟瑟发抖...
以上是关于NoSQL之Redis入门的主要内容,如果未能解决你的问题,请参考以下文章