用NoSQL给高并发系统加速
Posted 数据库开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用NoSQL给高并发系统加速相关的知识,希望对你有一定的参考价值。
来自公众号: 架构师修行之路
随着互联网大潮的到来,越来越多网站,应用系统需要海量数据的支撑,高并发、低延迟、高可用、高扩展等要求在传统的关系型数据库中已经得不到满足,或者说关系型数据库应对这些需求已经显得力不从心了。关系型数据库经过几十年的发展已经很成熟,强大的sql语句支持,完美的ACID属性的支持,使得关系型数据库广泛应用于各种各样的应用系统中,但是应用的场景广泛并非意味着完美。
-由于关系型数据库是按行进行存储的,在某些只统计一列的需求场景下,也需要把整行读入内存,导致了一个小小的统计需求高IO的缺点
-关系型数据库无法存储数据结构,比如:一个商品可以从属于多个分类,业务上的从属关系体现到存储上是一个列表而已,但是关系型数据库需要把这些关系存储为多行,无法直接存储为一个列表。
-关系型数据库中的存储单位表的架构是强约束,操作不存在的列会报出异常,而且添加、更新、删除列必须执行DDL语句,如果表的现存数据量比较大,会出现长时间锁表的现象。
-关系型数据库全文搜索功能普通比较弱,用like去匹配关键词的时候,数据量比较大的情况下会出现慢查询的现象。
-关系型数据库基于表格的关系模型使得很难添加新的或不同种类的关联信息。
由于以上这些诸多问题,便诞生了以“NOSQL”为口号的很多解决方案。在某些关系型数据库不擅长的领域,Nosql表现的很出色。上天是公平的,给你打开了一扇窗户,必会给你关上半扇门,NoSql是以牺牲ACID某个或者某些特性为代价的。
NoSQL并不是银弹,更多的时候是关系型数据库一个有力补充,或者是特定场景下优于关系型数据库的一种解决方案


NoSQL,泛指非关系型的数据库。现在大家更喜欢翻译成:not only sql


根据NoSQL的存储等特性,大体可以分为以下几类
-键值(Key-Value)存储数据库。相关的产品:Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached。主要解决关系数据库无法存储数据结构的问题。
-列存储数据库。相关产品:BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS。解决关系数据库大数据场景下的 I/O 问题
-文档数据库。相关产品:MongoDB、CouchDB、ThruDB、CloudKit、Perservere、Jackrabbit。解决关系数据库强 schema 约束的问题。
-图形数据库。相关产品:Neo4J、OrientDB、InfoGrid、GraphDB。主要解决大量复杂、互连接、低结构化的图结构场合,如社交网络、推荐系统等
-全文搜索引擎。相关产品:Elasticsearch。主要解决关系数据库的全文搜索性能问题。
由此可见,没有哪一种NoSql是完美的,每一种Nosql都有自己擅长的领域,这也是我们做系统架构中要考虑的重要因素。
场景1
电商的商品设计过程中,每种商品的属性都不同,属性数目不同,属性名不同,同一个商品有可能会属于多个分类,而且随着业务的发展,很多商品会增加新的属性,而且最令程序员头疼莫过于每种属性都有可能有搜索的可能性(当然搜索可以利用搜索引擎来实现)。遇到这样的需求场景,如果利用关系型数据库来存储的话,表的字段会非常多,而且字段的定义非常令人头疼。
这样的场景非常适合NOsql中的文档型数据库,比如MongoDB。文档型数据库新增字段非常简单,不像关系型数据库需要先执行DDL来增加字段,直接可以利用程序来进行读写,历史数据就算是没有相应的字段也不会有异常的情况发生。最重要的一点,文档型数据库很擅长存储复杂结构的数据,一般情况下业务上可以利用表现能力很强的json数据结构。
{
"Id":1,
"ProductName":"杜蕾斯加强版",
"Price":100,
"Type":[
1,
2,
4
],
"Length":20,
"Height":2
}如果所有商品信息都用mongodb来存储的话,有的场景并不是十分完美。比如商品被成功购买之后扣库存的问题,联合查询的问题,由于Nosql天生对ACID支持不足的原因,一个事务性的操作很难在Nosql中实现,所以设计系统的时候在很多情况下是关系数据库+Nosql 来共同实现业务。
场景2
很多具体的业务中都有记录数据然后进行统计的需求场景,比如那些统计uv,pv的系统。日志型的数据量非常大,而且还有可能有峰值的出现,如果用关系型数据库来存储,很有可能在IO上会出现瓶颈,而且有可能会影响其他正常的业务,更不幸的是当执行统计语句的时候,性能更是差强人意。这样的日志型统计业务很适合HBase这样的列式Nosql,业务上要统计一天的uv,pv数据,HBase很适合统计某一列数据的场景,因为只需要把对应的列进行统计即可,不像关系型数据库那样需要把所有行都加载进内存,而且列式存储一般比行式存储拥有更大的压缩比例,占用的磁盘空间会更少。
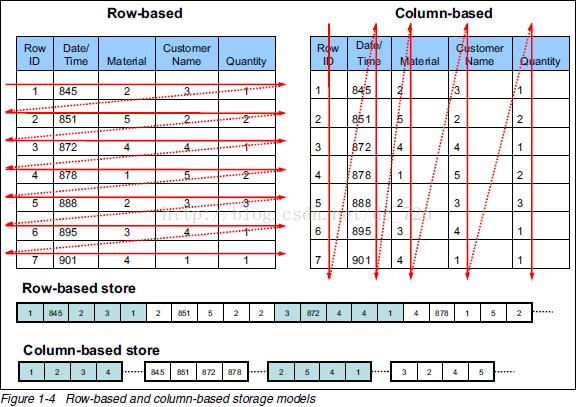

列式存储的应用场景有一定的限制,一般用于统计和大数据的分析中。
场景3
在多数高并发系统中都存在缓存的设计,而缓存的一般数据结构都是K-V结构。缓存是一种提高系统性能的有效手段,因其需要提供快速访问的特性,一般缓存都放置于内存当中。比如现在我们要设计一个用户管理系统,每个用户信息可以做缓存以便提供高速的访问,由于很多系统都采用分布式的部署方式,所以采用进程内的缓存方式并不可取,这个时候就需要有一种高速的外部存储来提供这种业务,这正是kv型Nosql的典型应用场景之一。其中以redis为代表,具体的业务中可以以用户id为key,用户的信息为value存储在redis中,而且redis在3.0之后可以做集群了,在高可用和扩展上更能助力业务方。redis支持的数据类型很多,在不同的场景下选择不同的数据类型。
场景4
当一个系统有搜索的业务时候,如果搜索的条件是一些简单的类型搜索,关系型数据库还可以满足,但是如果有全文搜索,就是我们平时sql写的like ‘%xx%’这样的搜索,关系型数据库可能并不是最好的选择,全文搜索引擎类型的Nosql也许是一个更好的解决方案,其中以Elasticsearch 为代表。全文搜索引擎的搜索的条件可以随意排列组合,并且可以实现关系型数据库like方式的模糊匹配。
全文搜索引擎的技术原理称为“倒排索引”(inverted index),是一种索引方法,其基本原理是建立单词到文档的索引。与之相对是,是“正排索引”,其基本原理是建立文档到单词的索引。
场景5
在社交系统中最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷,解决关系型数据库存储和处理复杂关系型数据功能较弱的问题。其中以Neo4j为代表。想深入研究的同学请移步百度。
无论是关系型数据库还是nosql数据库都不是银弹,每一种事物都有它最善长的领域。设计一个好的系统,需要综合考虑各种因素,根据具体的业务场景来选择最合适的解决方案。
●编号640,输入编号直达本文
●输入m获取文章目录
Web开发
以上是关于用NoSQL给高并发系统加速的主要内容,如果未能解决你的问题,请参考以下文章