分布式文档型NoSQL数据库——MongoDB初探
Posted 畅游DT时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式文档型NoSQL数据库——MongoDB初探相关的知识,希望对你有一定的参考价值。
引言
NoSQL的意思是Not only SQL,泛指非关系型数据库,是一种在集群环境中易于编程且执行效率高的大数据处理技术,它的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。文档型数据库作为NoSQL数据库中的一大分支,与键值存储数据库类似,它的数据模型是版本化的文档,以半结构化的文档以JSON等特定的格式存储。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。文档型数据库可以看作是键值数据库的升级版,通常比键值数据库的查询效率更高。
MongoDB命名来源于英文单词“humongous”,即“奇大无比的”,可见这款数据库的目标是提供海量数据的存储以及管理能力。MongoDB是目前最为主流的分布式文档型数据库,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似JSON的BSON格式,因此可以存储比较复杂的数据类型。Mongo支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。同时MongoDB具备较好的扩展性以及高可用性。

功能特点
MongoDB经过几个版本的迭代,目前最新的稳定版为3.4.4。它具备的高性能、高扩展性、Auto-Sharding、Replica-Set、Free-Schema、类SQL的丰富查询和索引等特性,吸引越来越多的企业用户。
Free Schema的文档模型,提供简单灵活的动态模式,适合快速开发和迭代场景;
BSON文档结构可以直接表达复杂结构对象,非常接近In Memory数据模型;
支持Master-Slaver(主从)和Replica-Set(副本集)两种方式,保证数据高可靠、服务高可用,实现自动容灾和多并发的读写分离功能;
Auto-Sharding为存储容量和服务能力提供水平扩展的能力,增加集群的吞吐量;
存储引擎使用的内存映射文件(MMAP的方式)提供高性能的查询,可作为缓存数据库使用;
具备丰富的查询支持,支持实时的update、insert、delete等操作,提供位置索引、文本索引、TTL索引、地理索引等多类型的索引;
能够很好的兼容Hadoop、MapReduce。
对于初步接触MongoDB的用户而言,文档模型BSON、分片Shard和副本集Replica-Set是3个陌生但是很重要的概念,下面着重说明。
(1) 文档模型BSON
MongoDB是面向文档的弱结构化存储方案,使用文档来展现、查询和修改数据。文档是MongoDB中数据的基本单位,类似于关系数据库中的“行”,是一组键-值对。键用于唯一标识一个文档(document),为字符串类型,而值则可以是各种复杂的文件类型,比如String、Integer、Double、List、Array、Date甚至嵌套文档(即一个文档里面的Key值可以是另外一个文档)等等。我们称这种存储形式为BSON(Binary Serialized Document Format),是一种和JSON类似但是比JSON更高效的二进制对象格式,多个键及其关联的值有序地放在一起就构成了文档。
——用一个例子说明:
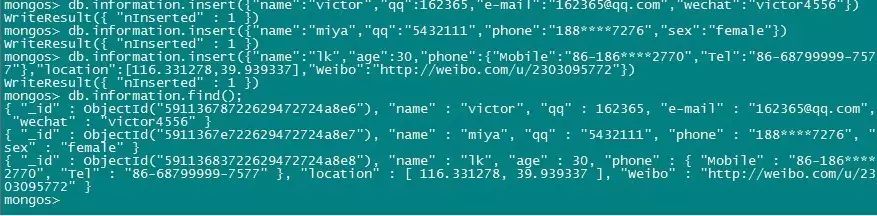
如上图所示,每一条insert后的内容就是一个BSON文档,一共插入了三条记录到集合“information”中:
{"name":"victor","qq":162365,"e-mail":"162365@qq.com","wechat":"victor4556"}
{"name":"miya","qq":"5432111","phone":"188****7276","sex":"female"}
{"name":"lk","age":30,"phone":{"Mobile":"86-186****2770","Tel":"86-68799999-7577"},"location":[116.331278,39.939337],"Weibo":"http://weibo.com/u/2303095772"}
每个文档大括号中逗号隔开的就是键-值对,“:”前为键,可以理解为传统关系型数据库表的列,即表头的概念;“:”后为值,可以理解为传统关系型数据库表的行。可以看到文档模型BSON和关系型数据库中表有几个明显不同的地方:一是无需预先定义表结构,进行额外的建表操作;二是每条记录的键、值、文档类型都可以完全不同,内容格式随意,即可以将完全不同类型、内容的数据储存在一张“表”中。这张类似传统关系数据库中的“表”在MongoDB中被称作“集合(collection)”,集合是无模式(Free Schema)的,集合中的文档可以是各式各样的。这就是为什么MongoDB可以提供随时增加、修改结构的数据动态存储功能,非常适合快速开发和迭代场景。
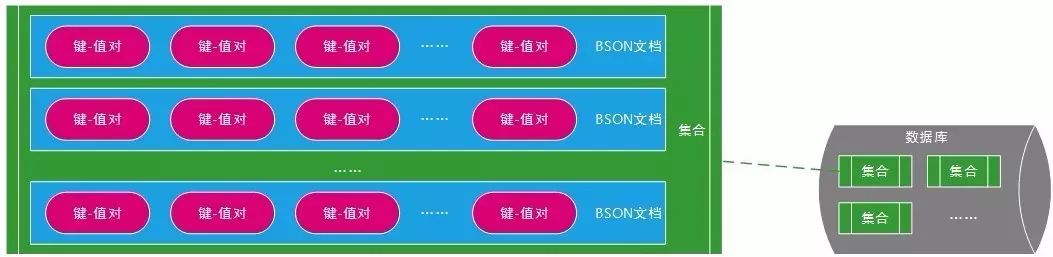
MongoDB中多个键-值对组成BSON文档,多个文档组成集合,多个集合组成数据库,MongoDB “文档-集合-数据库”的逻辑结构对应传统关系型数据库的“行-表-数据库”。一个MongoDB实例可以承载多个数据库,它们之间可以看作相互独立,每个数据库都有独立的权限控制。
(2) 分片Shard
在MongoDB中,分片集群(shardedcluster)是一种水平扩展数据库系统性能的方法,为了解决随着数据量的增加和读写请求的增加,单个MongoDB实例无法应对的问题。MongoDB能够将数据集分布式存储在不同的分片(shard)上,每个分片只保存数据集的一部分,MongoDB保证各个分片之间不会有重复的数据,所有分片保存的数据之和就是完整的数据集。分片集群将数据集分布式存储,能够将负载分摊到多个分片上,每个分片只负责读写一部分数据,充分利用分布式特效以及各个shard的系统资源,提高数据库系统的吞吐量。
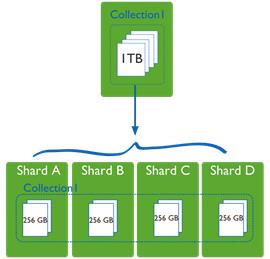
如上图所示,1T的集合Collection1 存储在一台服务器时硬盘读写、网络IO、CPU和内存的负荷都影响着MongoDB的性能,Auto-Sharding将1T的数据拆分给4台服务器,数据达到分而治之的效果,随着集群的扩大,整个集群的吞吐量和容量都会扩大。
(3) 副本集Replica-Set
在MongoDB数据库集群中,启动Auto-Sharding功能会将数据分片存储在不同的服务器上,如果每个分片在每台服务器上只有一份的话,那么一旦某一台服务器发生故障产生宕机,这台服务器上的分片就变得不可用了,数据完整性无法得到保障。因此,MongoDB数据库集群提供副本集Replica-Set模式保证数据的可靠性和容错性。副本集是一个带有故障转移的主从集群,是从现有的主从模式演变而来,增加了自动故障转移和节点成员自动恢复。
副本的概念在网游中经常出现,玩过魔兽世界的人都知道下副本可以获得丰富的经验、装备和道具等,副本的设定是由于玩家集中在高峰时间去一个场景打怪,会出现玩家暴多怪物少的情况,游戏开发商为了保证玩家的体验度,就为每一批玩家单独开放一个同样的空间同样的数量的怪物,这一个复制的场景就是一个副本,不管有多少个玩家各自在各自的副本里玩不会互相影响。MongoDB副本集的概念类似,多个副本保证了数据库集群的容错性,只有还有一个副本正常,挂掉再多副本也不影响数据的完整性,集群会自动切换到那个正常的副本。
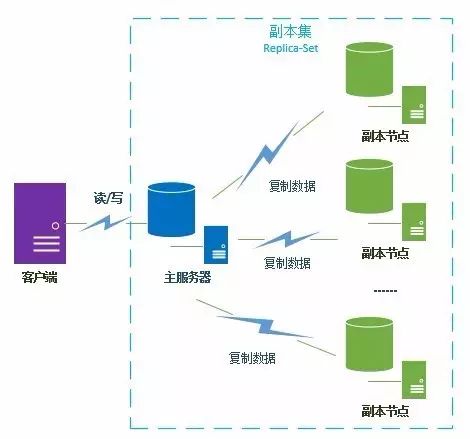
由上图可以看到客户端连接到整个副本集,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份,一旦主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应用服务器不需要关心。副本集模式中没有固定的主节点,在启动后,多个服务节点间将自动选举产生一个主节点。该主节点被称为Primary,一个或多个从节点被称为Secondaries。Primary节点类似Hadoop中的Master节点,不同之处在于Primary节点在不同时间可能是不同的服务器。
(4) 高可用的MongoDB集群架构
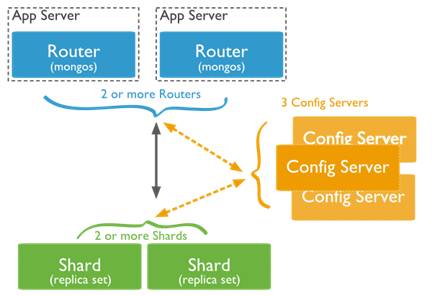
如上图所示,高可用的MongoDB集群包括以下几个组件:
Routers (mongos实例):数据库集群请求的入口,用于与应用程序交互,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上,然后将请求结果返回给客户端。在生产环境会将mongos实例部署在应用服务器App Server上,而且通常会有多个Routers作为请求的入口,用于分摊客户端的请求压力。
Config Server(配置服务器):存储整个数据库集群的元数据信息,包括数据路由、分片和副本集等配置信息以供将客户端请求定位到后端相应的Shards。mongos启动时就会从Config Server加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。由于Config Server一旦全部挂掉,整个MongoDB集群将不可用,因此在生产环境通常有多个放置在不同服务器上的Config Server。
Shard(Replica-Set): 上文中已提到过,分片和副本集用来存储实际数据,为MongoDB集群提供服务的高可用性和数据的一致性。生产环境中,每个Shard都是一个Replica-Set。
应用场景
MongoDB的定位是一种通用型数据库,它的应用场景包括内容管理、移动应用、游戏、电商仓储管理、物联网、实时分析、存档和日志管理等等,但不适用于那些需要SQL、关联和高度事务性的应用,例如银行或会计系统。
为网站提供数据的实时插入、更新与查询功能,并具备网站实时数据存储所需的复制及高度伸缩性;
游戏开发需求变化很快,MongoDB作为游戏后端数据库,无固定schema的模式可以免去变更表结构的痛苦,大幅度缩短版本迭代周期;
MongoDB当作缓存服务器使用,合理规划热数据,其性能与其他常用缓存服务器相当,同时还能提供更丰富的查询方式;
MongoDB的副本集数据库服务能够实现读写分离,可根据需求配置主库写入从库读取的模式来满足大量读应用需求,减轻主库压力;
MongoDB支持二维空间索引,提供异构数据的动态存储模式,完美支撑基于位置查询的移动类APP的业务需求。
如上图所示,MongoDB凭借其优秀的特性在国外各行业已有相当成熟的应用,国内使用MongoDB的互联网公司包括58同城、淘宝、京东、360、百度、大众点评等。下面分享两个MongoDB的成功应用案例。

案例一:东方航空的“空间换时间”
中国东方航空作为国内的三大航空公司之一,每天有1000多个航班,需要服务26万多乘客。顾客在网站上订购机票,平均要查询1.2万次才会发生一次订购行为,东航的运价系统需要支持每天16亿的运价请求。如果这16亿的运价请求通过实时计算返回结果,东航需要对已有系统进行100多倍的扩容才能满足。如果采用“空间换时间”的思路,与其对每一次的运价请求进行耗时300ms的运算,不如事先把所有可能的票价查询组合穷举出来并进行批量计算,然后把计算结果存入MongoDB里面。当需要查询运价时,直接按照“出发+目的地+日期”的方式做一个快速的查询,响应时间应该可以做到几十毫秒。
之所以使用MongoDB,一是看重它处理海量数据的能力,二是它基于内存缓存的数据管理方式决定了对并发读写的响应可以做到很低延迟,水平扩展的方式可以通过多台节点同时并发处理海量请求。
东航这一做法也是借鉴了全球最大的航空分销商Amadeus,管理着全世界95%航空库存的他们也正是使用MongoDB作为其1000多亿运价缓存的存储方案。

案例二:58同城百亿量级数据处理
58同城作为中国最大的生活服务平台,涵盖了房产、招聘、二手、二手车、黄页等核心业务,这些业务具有事务性低、数据量级巨大、高并发的特点,需要一款高性能且稳定,能够按照业务进行垂直拆分,同时根据业务存储量和访问量进行横向扩展的数据库——MongoDB的优势与此不谋而合。
在使用方面,针对MongoDB的Free Schema特性带来的部分key重复存储占用空间的问题采取减少key长度和数据存储压缩的方法,尽可能减少数据存储占用空间;用库级Sharding和大文档手动Sharding的方式替代默认的Auto-Sharding功能,对数据有针对性的进行分片;架构方面采用的是前文提到的Sharding+Replica-Set的高可用集群,并使用mongosniff、mongostat、mongotop、db.xxoostatus、Web控制台监控等多种监控相结合的方式。
58同城在处理百亿量级的数据时,是将业务热点数据和索引的总量要能全部放入内存中,并通过Scale Up或者Scale Out的扩展方式避免内存瓶颈;将频繁更新删除的表放在一个独立的数据库下,减少操作产生的空洞和碎片,从而提高性能;对于大量数据的删除操作带来的数据库性能降低的问题,通过物理文件定时离线删除的方式解决;而大量删除数据产生的数据空洞、大量碎片无法利用的问题,通过碎片整理、空洞合并收缩等方案加以解决。
总结
-END-
声明:
本文为中国联通网研院网优网管部IT技术研究团队独家提供。
如需转载或合作,请联系管理员(luxin@dimpt.com)
长按既可添加关注
以上是关于分布式文档型NoSQL数据库——MongoDB初探的主要内容,如果未能解决你的问题,请参考以下文章