MongoDB应用与实践之优化篇
Posted 360云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB应用与实践之优化篇相关的知识,希望对你有一定的参考价值。
女主宣言
上期我们介绍了《》,本篇我们将就实际应用中遇到的问题及优化展开介绍。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!
常见连接问题
合理配置连接资源
1
thread per connection
网络模型如图:
• 每个连接对应一个线程,每个线程需要分配1M内存资源
• 大量连接的创建与销毁数据库开销较大
2
连接资源控制
• 实例限制最大连接数。MongoDB启动时,可通过maxConns参数控制实例的最大连接数。
• 限制连接池大小,客户端连接数据库时,可通过maxPoolSize配置连接池大小。例如:
mongoClient = new MongoClient("mongodb://root:****@host1:port1,host2:port2/admin?replicaSet=repl00& maxPoolSize=100");
登录失败问题
默认情况下,MongoDB不开启鉴权,出于安全考虑,建议开启数据库认证。开启安全认证后,连接数据库时则需要提供安全认证库,如图php连接中配置db=>’xxx’(xxx表示认证库通常为admin);
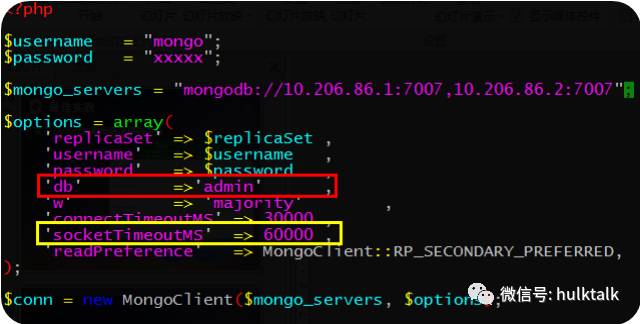
命令行登录:
mongodb30/bin/mongo -uxyz -pxyz 10.142.1.1:7003/abc (abc为业务库) --authenticationDatabase admin(admin为认证库)。
另外mongodb不同版本客户端通常不兼容故不同版本数据库请采用对应版本客户端登陆否则可能出现不可预知的问题
游标超时设置
数据库连接的生命周期可由驱动指定。以PHP举例:连数据库时,通过socketTimeoutMS(全局级别)与cursorTimeoutMS(cursor级别)控制超时时间。
SCRAM-SHA-1认证模式说明
优势
更强的加密散列函数SHA-1
Client和Server端双向认证
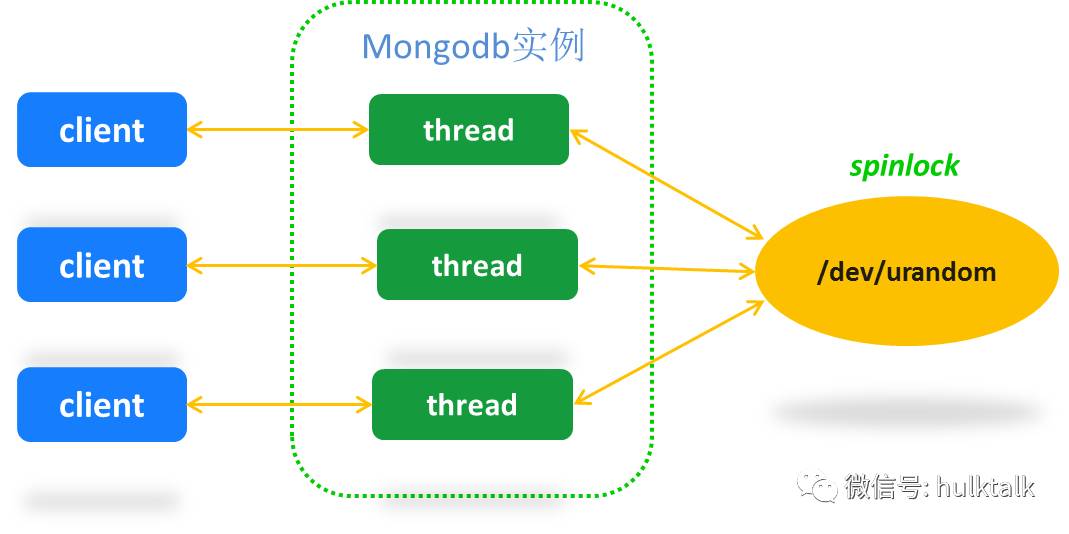
问题
SCRAM-SHA-1认证过程中需要生产一串叫做server-nonce的随机字符串。
SCRAM-SHA-1认证过程中需要生产一串叫做server-nonce的随机字符串。在Linux平台下是通过/dev/urandom 设备来生成,该设备生成的随机效果较好但性能相对较差。使用这个设备涉及到用户态至内核态的切换,为了避免高并发读返回同样的随机串在内核中使用了spinlock来做控制。
解决方式
弃用SCRAM-SHA-1选择MONGODB-CR。
客户端:配置MONGODB-CR认证模式,命令行登录举例:
mongodb30/bin/mongo -uxyz -pxyz 10.142.1.1:7003/abc --authenticationDatabase admin --authenticationMechanism MONGODB-CR
服务端:系统库admin下system.version集合currentVersion设置为3。
查询优化
读优先级控制(readPrefence)
primary
只读主节点(默认),适合读实时性要求高的业务
primaryPreferred
主节点优先,适合高并发写入的业务
secondary
只读从节点,实际业务基本不推荐
secondaryPreferred
读从库优先,常见业务优先推荐模式
nearest
就近原则,以ping响应速度为准选择可读主从库
通常情况下,配置secondaryPreferred即可,高并发写入建议配置primaryPreferred (高并发写入情况下,从节点可能会被oplog apply阻塞)。
索引优化
1
常见索引类型
unique(唯一索引)
由数据库维护数据一致性高并发可能存在性能问题
hashed(哈希索引)
仅支持单个字段,不保证唯一性
sparse(稀疏索引
索引仅包含拥有索引字段的文档相对解压索引空间
geo(地理位置索引)
分为2d索引(二维平面)及2dsphere(球面)索引
TTL(过期索引)
依据过期时间,由数据库定期清理过期数据。
text(文本索引)
支持字符串内容的文本搜索查询,其字段值可以是字符串或者字符串元素数组。(text对资源消耗非常大且开源版本不支持,建议采用其他方案)。
2
索引说明
高并发场景下,唯一索引可能极大降低数据库性能,建议程序里优先处理。
索引创建时强烈建议添加{background: true}属性,例如:
db.test.ensureIndex({"column1": 1}, {"unique": true, "sparse": true, background: true})
{background: true}表示在后台构建索引,避免写锁阻塞数据库。
3
索引最左前缀原则
索引查询以索引创建顺序为准,与查询字段无关,索引检索遵循最左前缀原则,满足业务需求的情况下,索引越少越好,尽量避免一个查询一个索引。如图:索引{a: 1, b:1, c: 1}可以满足1、2、3及4这四类查询。

4
读懂查询计划
explain()用于查看命令的执行情况:
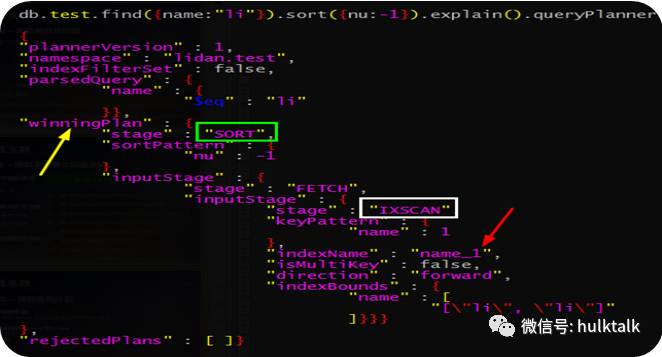
winningPlan
查询优化器选中的执行计划详情:
• IXSCAN:表示查询进行了索引扫描,可从indexName字段查看查询计划真实选中的索引信息。
• COLLSCAN:全集合扫描,执行计划出现COLLSCAN,表示该查询没有合适索引。
• SORT:表示查询过程需要进行排序,可能的情况是查询没有走索引或索引不是最优。
rejectedPlans
查询优化器丢弃的候选执行计划列表,当优化器没有多个可选索引的情况下,此列表显示为空。
5
干掉慢查询
• 避免使用Ctrl+c:对于MongoDB 多数情况采用Ctrl+c并不会真正终止对数据的操作,建议优先使用db.currentOp()获取想要终止执行命令的opid,然后通过db.killOp(opid)终止具体操作。
• 考虑使用cursor.maxTimeMS(N):根据业务具体情况设置数据库操作的执行时间(单位:毫秒)。N 毫秒如果操作不返回结果,数据库自动终止该操作。
6
查询优化
Find优化
db.test.find({ name : /i/ },{ _id : 0 , birthday : 1 }).limit(10) 返回birthday字段并限制返回10条记录。
• 控制查询条件:
db.test.find({id:{$in:[1,2,3,4,5,6,7,8,9……...]}}),最好限制in条件的个数,巨量条件可分批执行。
• 业务端排序:
db.test.find({ name : /i/ },{ _id : 0 }).sort({birthday:1}),高并发情景下sort操作最好由业务端程序进行。
Insert优化
• 增加冗余字段以空间换时间
商品数量*单价=商品总价,记录商品信息时,可添加总价字段以减小数据库的计算开销。
• 超长文本优先压缩或HASH处理
小说类文本优先程序端压缩;url 类文本建议hash计算后存储。
• 不常检索的大字段可独立拆分存储。
• 批量插入请考虑bulkWrite()。
update、delete优化
• 批量更新与删除
• 尽量走索引:减少更新查找的时间开销
• 分批处理:分批多次操作以降低数据库负载
• 适当sleep:批量操作每条记录产生一条日志,日志需同步至从库,适当休眠可避免同步延迟。
• 记录存在更新,不存在则插入
建议使用{upsert:true},{upsert:true}可保证操作的原子性。
db.test.update({"name": "lidan"}, {"name": "lidan","sex": "male"}, {upsert: true})
7
优化之分页查询
普通分页查询
db.test.find({name:”lidan”}).skip(10000).limit(3)
• 优点:使用简单粗暴
• 缺点:大偏移量查询时会对性能产生较大影响
一种新的思路
条件查询+sort+limit+取上一页最后一条记录后:db.test.find({ name : "li",num:{$gt:305} }).limit(3)
• 优点: 高效的顺序分页
• 缺点: 跳跃分页第一次效率相对较低

8
数组说明
数组尾部追加元素时:oplog仅记录追加的元素及位置。
数组非尾部插入元素时,oplog将记录完整的数组字段信息。
对数组建立索引时,数据相对于对数组每一个元素创建索引,如数组元素过多,索引维护成本非常高。
使用注意点:
• 控制元素个数
• 尽量不对数组建索引(并不完全禁止)
• 推荐尾部$push或$push+$slice方式,
其中slice:0 将清空整个数组
正数 保留数组最前n个元素
负数 保留数组最后n个元素
总结
本次分享主要针对开发人员在实际业务中最常遇到的一些问题及使用上的一些误解进行了简单介绍,希望对大家有所帮助。如有其他问题也可以留言,我们会及时解答。
以上是关于MongoDB应用与实践之优化篇的主要内容,如果未能解决你的问题,请参考以下文章