MongoDB执行计划图文详解 | MongoDB干货02
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB执行计划图文详解 | MongoDB干货02相关的知识,希望对你有一定的参考价值。
编辑
周李洋(E叔)(原创)
刘玉强(文章整理 & 发布)
嘉宾介绍
周李洋,现就职于DeNA(社区常用ID eshujiushiwo),关注于mysql与MongoDB技术,数据架构等,mongo-mopre,mongo-mload作者,任CSDN mongodb版主,MongoDB官方翻译组核心成员,MongoDB中文站博主,MongoDB Contribution Award获得者,曾任MongoDB Days Beijing 2014演讲嘉宾。
写在之前的话
作为近年最为火热的文档型数据库,MongoDB受到了越来越多人的关注,但是由于国内的MongoDB相关技术分享屈指可数,不少朋友向我抱怨无从下手。
《MongoDB干货系列》将从实际应用的角度来进行MongoDB的一些列干货的分享,将覆盖调优,troubleshooting等方面,希望能对大家带来帮助。
如果希望了解更多MongoDB基础的信息,还请大家Google下。
要保证数据库处于高效、稳定的状态,除了良好的硬件基础、高效高可用的数据库架构、贴合业务的数据模型之外,高效的查询语句也是不可少的。那么,如何查看并判断我们的执行计划呢?我们今天就来谈论下MongoDB的执行计划分析。
点击文末的“阅读原文”,即可欣赏本文的网站版。
正文
MongoDB 3.0之后,explain的返回与使用方法与之前版本有了不少变化,介于3.0之后的优秀特色,本文仅针对MongoDB 3.0+的explain进行讨论。
现版本explain有三种模式,分别如下:
queryPlanner
executionStats
allPlansExecution
queryPlanner
queryPlanner是现版本explain的默认模式,queryPlanner模式下并不会去真正进行query语句查询,而是针对query语句进行执行计划分析并选出winning plan。

先来看queryPlanner模式的各个返回意义。
explain.queryPlanner
queryPlanner的返回。
explain.queryPlanner.namespace
顾名思义,该值返回的是该query所查询的表。
explain.queryPlanner.indexFilterSet
针对该query是否有indexfilter(会在后文进行详细解释)。
explain.queryPlanner.winningPlan
查询优化器针对该query所返回的最优执行计划的详细内容。
explain.queryPlanner.winningPlan.stage
最优执行计划的stage,这里返回是FETCH,可以理解为通过返回的index位置去检索具体的文档(stage有数个模式,将在后文中进行详解)。
explain.queryPlanner.winningPlan.inputStage
explain.queryPlanner.winningPlan.stage的child stage,此处是IXSCAN,表示进行的是index scanning。
explain.queryPlanner.winningPlan.keyPattern
所扫描的index内容,此处是w:1与n:1。
explain.queryPlanner.winningPlan.indexName
winning plan所选用的index。
explain.queryPlanner.winningPlan.isMultiKey
是否是Multikey,此处返回是false,如果索引建立在array上,此处将是true。
explain.queryPlanner.winningPlan.direction
此query的查询顺序,此处是forward,如果用了.sort({w:-1})将显示backward。
explain.queryPlanner.winningPlan.indexBounds
winningplan所扫描的索引范围,此处查询条件是w:1,使用的index是w与n的联合索引,故w是[1.0,1.0]而n没有指定在查询条件中,故是[MinKey,MaxKey]。
explain.queryPlanner.rejectedPlans
其他执行计划(非最优而被查询优化器reject的)的详细返回,其中具体信息与winningPlan的返回中意义相同,故不在此赘述。
executionStats
executionStats的返回中多了如下:

executionStats模式中,我们主要需要注意的返回有如下几个
executionStats.executionSuccess
是否执行成功
executionStats.nReturned
查询的返回条数
executionStats.executionTimeMillis
整体执行时间
executionStats.totalKeysExamined
索引扫描次数
executionStats.totalDocsExamined
document扫描次数
以上几个非常好理解,我们就不在这里详述,后文的案例中会有分析。
executionStats.executionStages.stage
这里是FETCH去扫描对于documents
executionStats.executionStages.nReturned
由于是FETCH,所以这里该值与executionStats.nReturned一致
executionStats.executionStages.docsExamined
与executionStats.totalDocsExamined一致
executionStats.inputStage中的与上述理解方式相同
还有一些文档中没有描述的返回如:
“works” : 29862,
“advanced” : 29861,
“isEOF” : 1,
这些值都会在explan之初初始化:
mongo/src/mongo/db/exec/plan_stats.h
struct CommonStats {
CommonStats(const char* type)
: stageTypeStr(type),
works(0),
yields(0),
unyields(0),
invalidates(0),
advanced(0),
needTime(0),
needYield(0),
executionTimeMillis(0),
isEOF(false) {}以works为例,查看源码中发现,每次操作会加1,且会把执行时间记录在executionTimeMillis中。
mongo/src/mongo/db/exec/fetch.cpp
++_commonStats.works;
// Adds the amount of time taken by work() to executionTimeMillis.
ScopedTimer timer(&_commonStats.executionTimeMillis);而在查询结束EOF,works又会加1,advanced不加。
mongo/src/mongo/db/exec/eof.cpp
PlanStage::StageState EOFStage::work(WorkingSetID* out) {
++_commonStats.works;
// Adds the amount of time taken by work() to executionTimeMillis.
ScopedTimer timer(&_commonStats.executionTimeMillis);
return PlanStage::IS_EOF;
}故正常的返回works会比nReturned多1,这时候isEOF为true(1):
mongo/src/mongo/db/exec/eof.cpp
bool EOFStage::isEOF() {
return true;
}
unique_ptr<PlanStageStats> EOFStage::getStats() {
_commonStats.isEOF = isEOF();
return make_unique<PlanStageStats>(_commonStats, STAGE_EOF);
}advanced的返回值在命中的时候+1,在skip,eof的时候不会增加如:
mongo/src/mongo/db/exec/skip.cpp
if (PlanStage::ADVANCED == status) {
// If we're still skipping results...
if (_toSkip > 0) {
// ...drop the result.
--_toSkip;
_ws->free(id);
++_commonStats.needTime;
return PlanStage::NEED_TIME;
}
*out = id;
++_commonStats.advanced;
return PlanStage::ADVANCED;IndexFilter
IndexFilter决定了查询优化器对于某一类型的查询将如何使用index,indexFilter仅影响查询优化器对于该类查询可以用尝试哪些index的执行计划分析,查询优化器还是根据分析情况选择最优计划。
如果某一类型的查询设定了IndexFilter,那么执行时通过hint指定了其他的index,查询优化器将会忽略hint所设置index,仍然使用indexfilter中设定的查询计划。
IndexFilter可以通过命令移除,也将在实例重启后清空。
IndexFilter的创建
可以通过如下命令为某一个collection建立indexFilter


上图针对orders表建立了一个indexFilter,indexFilter指定了对于orders表只有status条件(仅对status进行查询,无sort等)的查询的indexes,故下图的查询语句的查询优化器仅仅会从{cust_id:1,status:1}和{status:1,order_date:-1}中进行winning plan的选择

indexFilter的列表
可以通过如下命令展示某一个collecton的所有indexFilter

indexFilter的删除
可以通过如下命令对IndexFilter进行删除

Stage的意义
如explain.queryPlanner.winningPlan.stage和explain.queryPlanner.winningPlan.inputStage等。
文档中仅有如下几类介绍
COLLSCAN
全表扫描
IXSCAN
索引扫描
FETCH
根据索引去检索指定document
SHARD_MERGE
将各个分片返回数据进行merge
但是根据源码中的信息,个人还总结了文档中没有的如下几类(常用如下,由于是通过源码查找,可能有所遗漏)
SORT
表明在内存中进行了排序(与老版本的scanAndOrder:true一致)
LIMIT
使用limit限制返回数
SKIP
使用skip进行跳过
IDHACK
针对_id进行查询
SHARDING_FILTER
通过mongos对分片数据进行查询
COUNT
利用db.coll.explain().count()之类进行count运算
COUNTSCAN
count不使用用Index进行count时的stage返回
COUNT_SCAN
count使用了Index进行count时的stage返回
SUBPLA
未使用到索引的$or查询的stage返回
TEXT
使用全文索引进行查询时候的stage返回
PROJECTION
限定返回字段时候stage的返回
部分源码如下:
mongo/jstests/libs/analyze_plan.js
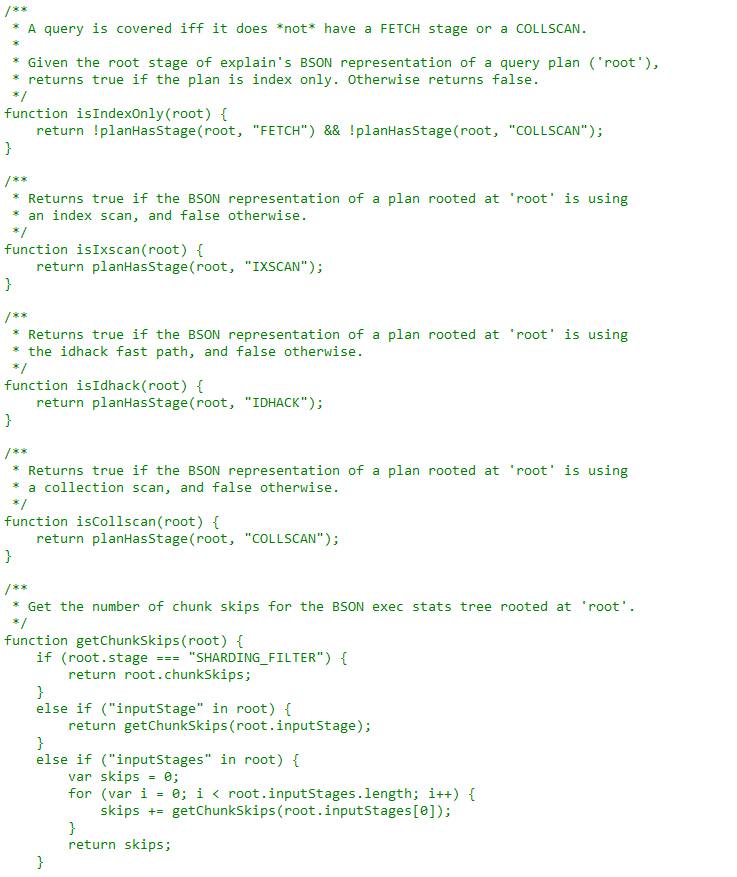
mongo/jstests/concurrency/fsm_workloads/explain_count.js
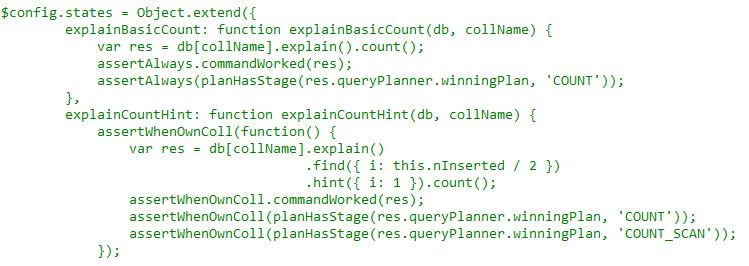
mongo/jstests/concurrency/fsm_workloads/explain_find.js

以上便是explain的主要返回解析,那么,针对这么多返回项,我们应该关注什么呢?
逐层分析
第一层,executionTimeMillis。
首先,最为直观explain返回值是executionTimeMillis值,指的是我们这条语句的执行时间,这个值当然是希望越少越好。
且executionTimeMillis 与stage有同样的层数,即:

其中有3个executionTimeMillis,分别是
executionStats.executionTimeMillis
该query的整体查询时间
executionStats.executionStages.executionTimeMillis
该查询根据index去检索document获取29861条具体数据的时间
executionStats.executionStages.inputStage.executionTimeMillis
该查询扫描29861行index所用时间
这三个值我们都希望越少越好,那么是什么影响这这三个返回值呢?
抛开硬件因素等不谈,我们来进行下一层的剥离。
第二层,index与document扫描数与查询返回条目数
这里主要谈3个返回项,nReturned,totalKeysExamined与totalDocsExamined,分别代表该条查询返回的条目、索引扫描条目和文档扫描条目。
很好理解,这些都直观的影响到executionTimeMillis,我们需要扫描的越少速度越快。
对于一个查询, 我们最理想的状态是
nReturned=totalKeysExamined & totalDocsExamined=0
(cover index,仅仅使用到了index,无需文档扫描,这是最理想状态。)
或者
nReturned=totalKeysExamined=totalDocsExamined(需要具体情况具体分析)
(正常index利用,无多余index扫描与文档扫描。)
如果有sort的时候,为了使得sort不在内存中进行,我们可以在保证nReturned=totalDocsExamined
的基础上,totalKeysExamined可以大于totalDocsExamined与nReturned,因为量级较大的时候内存排序非常消耗性能。
后面我们会针对例子来进行分析。
第三层,Stage状态分析
那么又是什么影响到了totalKeysExamined与totalDocsExamined呢?就是Stage的类型,Stage的具体含义在上文中有提及,如果认真看的同学就不难理解为何Stage会影响到totalKeysExamined 和totalDocsExamined从而影响executionTimeMillis了。
此前有讲解过stage的类型,这里再简单列举下(具体意义请看上文)
COLLSCAN
IXSCAN
FETCH
SHARD_MERGE
SORT
LIMIT
SKIP
IDHACK
SHARDING_FILTER
COUNT
COUNTSCAN
COUNT_SCAN
SUBPLA
TEXT
PROJECTION
对于普通查询,我们最希望看到的组合有这些:
Fetch+IDHACK
Fetch+ixscan
Limit+(Fetch+ixscan)
PROJECTION+ixscan
SHARDING_FILTER+ixscan
等
不希望看到包含如下的stage:
COLLSCAN(全表扫),SORT(使用sort但是无index),不合理的SKIP,SUBPLA(未用到index的$or)
对于count查询,希望看到的有:
COUNT_SCAN
不希望看到的有:
COUNTSCAN
Explain分析实例
表中数据如下(简单测试用例,仅10条数据):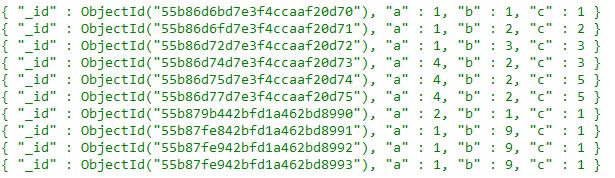
查询语句:
db.d.find({a:1,b:{$lt:3}}).sort({c:-1})首先,我们看看没有index时候的查询计划

nReturned为2,符合的条件的返回为2条。
totalKeysExamined为0,没有使用index。
totalDocsExamined为10,扫描了所有记录。
executionStages.stage为SORT,未使用index的sort,占用的内存与内存限制为”memUsage” : 126, “memLimit” : 33554432。
executionStages.inputStage.stage为COLLSCAN,全表扫描,扫描条件为

很明显,没有index的时候,进行了全表扫描,没有使用到index,在内存中sort,很显然,和都是不可取的。
下面,我们来对sort项c加一个索引
db.d.ensureIndex({c:1})再来看看执行计划

我们发现,Stage没有了SORT,因为我们sort字段有了index,但是由于查询还是没有index,故totalDocsExamined还是10,但是由于sort用了index,totalKeysExamined也是10,但是仅对sort排序做了优化,查询性能还是一样的低效。
接下来, 我们对查询条件做index(做多种index方案寻找最优)
我们的查询语句依然是:
db.d.find({a:1,b:{$lt:3}}).sort({c:-1})使用db.d.ensureIndex({b:1,a:1,c:1})索引的执行计划:

我们可以看到
nReturned为2,返回2条记录
totalKeysExamined为4,扫描了4个index
totalDocsExamined为2,扫描了2个docs
此时nReturned=totalDocsExamined<totalKeysExamined,不符合我们的期望。
且executionStages.Stage为Sort,在内存中进行排序了,也不符合我们的期望
使用db.d.ensureIndex({a:1,b:1,c:1})索引的执行计划:
我们可以看到
nReturned为2,返回2条记录
totalKeysExamined为2,扫描了2个index
totalDocsExamined为2,扫描了2个docs
此时nReturned=totalDocsExamined=totalKeysExamined,符合我们的期望。看起来很美吧?
但是,但是,但是!重要的事情说三遍!executionStages.Stage为Sort,在内存中进行排序了,这个在生产环境中尤其是在数据量较大的时候,是非常消耗性能的,这个千万不能忽视了,我们需要改进这个点。
最后,我们要在nReturned=totalDocsExamined的基础上,让排序也使用index,我们使用db.d.ensureIndex({a:1,c:1,b:1})索引,执行计划如下:
我们可以看到
nReturned为2,返回2条记录
totalKeysExamined为4,扫描了4个index
totalDocsExamined为2,扫描了2个docs
虽然不是nReturned=totalKeysExamined=totalDocsExamined,但是Stage无Sort,即利用了index进行排序,而非内存,这个性能的提升高于多扫几个index的代价。
综上可以有一个小结论,当查询覆盖精确匹配,范围查询与排序的时候,
{精确匹配字段,排序字段,范围查询字段}这样的索引排序会更为高效。
allPlansExecution
顾名思义,allPlansExecution模式是将所有的执行计划均进行executionStats模式的操作,不在此赘述了。
后文
执行计划分析一文,到此便告一段落了,希望大家能够对于MongoDB的执行计划有所了解。
如何一起愉快地发展
以上是关于MongoDB执行计划图文详解 | MongoDB干货02的主要内容,如果未能解决你的问题,请参考以下文章