北美全栈开发必读:深入解读MongoDB
Posted BitTiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了北美全栈开发必读:深入解读MongoDB相关的知识,希望对你有一定的参考价值。
欢迎回看本文原始视频:http://t.cn/RTmzEbl
谈到MongoDB,我们首先看一个真实的场景:如何从华为的应用市场里抓取关于APP的详细信息。

在这个页面里,我们要抓取的是华为应用市场里关于微信的详细信息。在数据抓取后,我们能获取一些基本元素,比如网页的URL、源码等。
URL = “appstore.huawei.com/app/C5683”
PageSource = “...<title>微信免费下载_华为应用...”
ID = 5683
Name = 微信
从这个源码中,可以抽取出应用的ID是5683,而应用的名字是“微信”。实际上,我们每抓下来这样一份数据,就可以称之为一个Document,这就是基于Document的设计。
要如何保存这些document的content呢?
最基本的问题是,如何将其存到一个文件里。假设蓝色代表一个文件,那么每个document都可以顺序存在里面。比如第一块Document是微信,第二块Document是微博,第三块Document是支付宝,这些都顺序地存储下来。

当我们顺序存储之后,如何增加一个新的版本?
如何将版本号5.7.0的信息存放在微博的Document里面呢?
Add Version=“5.7.0” to Weibo
在这个文件里,第二块数据是微博Document,但是因为这些数据都是连续地在硬盘上写的,所以就没有任何新的空间来存Version的信息。于是我们就需要在后面新写一个数据,把已有的Document信息全部拷过来,然后在最后加上版本号5.7.0去实现。
然后,把已有的Document删掉,保证数据一致。但我们可以看到,这个方法会带来一个很大的问题:当我们的数据在遍历的时候,中间会出现很大的Gap。


这个Gap出现以后,遍历的过程中就得读取很多无用的数据。当系统来回变动比较多的时候,就会有越来越多的Gap,从而造成读取速度的低效。
当出现这些Gap或碎片时,如何能够读得更快呢?
一个很简单的方法,就是建立指针。
每一个Document都存一个指针,指向下一个Document的位置。这样当我们读取一个Document的时候,就可以很快地找到下一个Document。同理,我们可以建立一个反向的指针,这样也可以快速地反向遍历。

有没有方法能够减少这些碎片呢?
如何做到当我们修改微博的Version信息时,不需要把整个数据块全部移动呢?方法是在每个Document之后加一个空白的Padding。
当我们有新的数据需要添加的时候,就可以把数据写到Padding里。比如我们把Version写到微博的Padding里,就可以不用迁移整块数据。

怎么将这些文件存到硬盘上?
首先我们需要理解什么是硬盘。
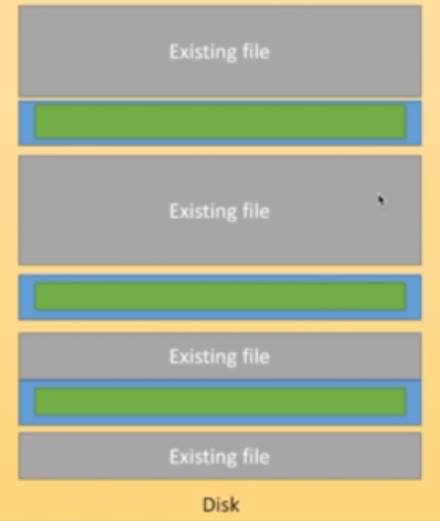
上图中的黄色代表整个硬盘。在硬盘中,有很多已经存在的文件(灰色)占据了空间。如果我们要往里面写东西,就只能在这些文件之间的空白处写(绿色)。这时我们会发现另一个问题:所有的Document都零散地存在硬盘的夹缝里,造成了另一种形式的碎片。
怎么减少这样的碎片呢?
如果数据是零散地存在在硬盘上的,就会造成读取时磁盘无法顺序读取,从而出现很多随机寻到的事件、影响读取速度。针对这个问题,一个方法是预先申请一块大的空间。申请到一块大空间(蓝色部分)以后,就能连续地写很多Document(绿色部分),从而减少了之前提到的碎片问题。

那如何选择预先申请的空间大小呢?
如果空间选得不够大,还是会出现很多碎片。如果选得太大,又会浪费空间。因此,我们采用double上升的方法来选择空间。从最基本的16M空间申请,当16M写满的时候,再申请32M、64M、128M的空间。当然这个数字不能够无限上升。我们选择2G作为申请上限,达到2G以后,再申请也只能是2G了。

解决了写的问题以后,我们再来解决读的问题。读的问题中最经典的就是查找问题。
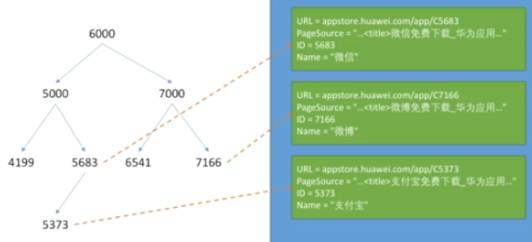
如何找到ID在5000到7000之内的所有数据呢?
最基本的方法就是用二叉搜索树,因为二叉树的遍历复杂度和插入复杂度都是logN。我们在ID的空间范围内存一个二叉树,每个节点的左侧是比该节点数小的所有ID的集合,右侧是比它大的ID集合。按这种规律不断扩展,就会得到整个二叉搜索树。
接下来,在二叉树的每个节点上放一个指针,指向对应该数字的ID在硬盘上具体的位置。通过这种方式,我们就能快速遍历,更快地进行范围查找。
但是在实际使用中,我们一般用的是二叉树的升级版本,即B树和B+树。在MongoDB里用的就是B树。
总结

MongoDB是将Documents存到硬盘上,这些Documents的属性可以随便修改。
这一点又称之为Scheme-free,即不受某一个模式的限制。
MongoDB通过在Document尾部添加Paddings来减少碎片及挪移。
MongoDB使用前向、后向的双向指针来增加查询效率。
MongoDB在存储到硬盘的过程中,会将Document聚合到16M、32M、64M上升的文件里,以此减少碎片。
MongoDB采用升级版的二叉树——B树来建立索引,提高查找的效率。
参考资料:
http://www.youtube.com/watch?v=bLTNAsrWzOI 关于MongoDB底层结构
http://blog.nosqlfan.com/html/3515.html MongoDB相关信息聚合
http://www.amazon.com/MongoDB-Definitive-Guide-Krsitina-Chodorow/dp/1449344682 介绍MongoDB的一本书
以上是关于北美全栈开发必读:深入解读MongoDB的主要内容,如果未能解决你的问题,请参考以下文章
老卫拆书009期:Vue+Node肩挑全栈!《Node.js+Express+MongoDB+Vue.js全栈开发实战》开箱
资源更新Vue+Node+MongoDB高级全栈开发全套教程