多数据中心环境下的 MongoDB 部署
Posted 架构头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多数据中心环境下的 MongoDB 部署相关的知识,希望对你有一定的参考价值。
现如今的互联网应用,我觉得应当称之为数据应用。在为用户提供服务之后,首先要考虑的就是如何利用用户数据来设计下一阶段的产品。为了获得数据,各大 IT 主管,技术总监,CTO 可谓是较劲脑汁,哪怕是一丁点儿的数据,只要用户数量足够庞大,都能产生有价值的业务信息。当你的数据面越来越广,用户数量越来越多的时候,存储这些数据就成了产品发展的瓶颈。于是,各种大数据存储,私有云、公有云存储不断涌现。有的企业为了存储大数据不惜重金搭建自己的数据服务中心。与传统关系型数据库相比,NoSQL 在这方面具有得天独厚的优势,没有数据库表的约束,没有严格的结构定义,备份恢复灵活,数据迁移方便,在 NoSQL 里 MongoDB 又是一款普遍采用的数据库类型。本文将讨论在多数据中心环境下,如何发挥 MongoDB 的优势。
众所周知,企业各种信息化管理都采用数据库来作为存储方案,企业对这些数据访问的连续性要求越来越高,尤其是最近几年国内企业的快速发展,不少企业的业务范围已经发展到了海外市场,我们除了为中国企业骄傲之外,应当考虑更多的是如何满足并支持这种发展趋势。作为 IT 从业人员,我们的出发点更多的是从技术角度开始,在技术上保持领先地位才是保证企业业务不受局限的必要条件之一。为了避免因为数据的中断导致各种损失,数据库高可用构架已经成为企业信息化建设中的重中之重。
那么什么是数据库的高可用?我们先从业务场景分析一下。我们以银行业为例,假如你去一家银行存钱,银行柜台工作人员会把数据录入进银行数据库,等你下次查询或者取款时可以看到这比存款纪录。好了,目前为止没有什么意外发生。但是,对于任何一家银行来说,他们不可能只有一个营业窗口,也不可能只有一台 ATM 取款机。银行的营业网点遍布在全国各个城市、大街小巷。你在一台机器上进行的操作可以在其他任何一个城市、网店查询到。任何一台服务器或者数据库都不可能保证常年正常运行,每台机器都会有一定时间的宕机,而这个时间通常是在允许的范围之内。当数据库宕机时,我们如何保证数据的正常录入和读取呢?
当所有数据库服务器都存储在一个数据中心时,我们可能会担心如果该数据中心整个瘫痪怎么办,瘫痪有可能是由供电系统导致,也有可能是人为破坏,还有可能是收到战争攻击。不论是什么原因,我们不想把所有赌注都压到一个数据中心上。此时,就有了多个数据中心部署的解决方案。那么,当一套数据库集群部署到多个数据中心时,我们如何保证数据的同步,或者说如何处理当一台服务器宕机导致的服务不可用呢?
在 MongoDB 世界中,高可用是通过 Replica 来实现的,Replica 这个单词的字面意思是“复制品”,所以说在 Replica Set 中每一台数据库都存储了一份全部数据的拷贝,所有数据库的存储内容都是一样的。对外来说整个 Replica Set 只有一个入口,应用程序服务器只需要通过这一个入口来进行数据库操作。Replica Set 内部是由多台角色不同的 MongoDB 服务器组成,每台服务器相当于是一个mongod进程,共分为Primary, Secondary和Arbiter。
Primary:提供所有数据库的写操作
Secondary:存储 Primary 上全部数据库的备份。当 Primary 不可访问时,Secondary 会接替 Primary 的工作继续对外提供服务
Arbiter:这是一个比较独特的成员,他并不存储任何数据库,当 Primary 无法访问时,他只作为推选新 Primary 的一个投票成员。下面我先给大家简单介绍一下这些概念,然后深入的分析 Replica Set 中各种场景的原理和注意要点。
一般一个 Replica Set 最少有 3 个成员负责存储数据,一个 Primary,两个 Secondary。从 MongoDB 3.0 以后,一个 Replica Set 中最多可以有 50 个成员,但是其中 Arbiter 只能有 7 个。下图是一个拥有三个成员的 Replica Set,一个 Primary,两个 Secondary。
Primary 负责所有数据库写操作。看到这里有可能你会认为,这样的 Replica Set 可以自动实现读写分离,Primary 负责写操作,Secondary 负责读请求,但实际上并不一定是这样,为什么说不一定呢?MongoDB 提供了另外一个参数用来设置是否是读写分离,Read Preference。默认情况下,Replica 中的所有 Primary 和 Secondary 都可以处理读请求,只有 Primary 可以处理写请求。在下面我会给大家详细介绍Read Preference的使用场景。当一台 Primary 不可访问时,一次选举将会在剩下的 Replica 成员中进行,每个成员有一个投票表决权,得票最多的成员将成为新的 Primary,在后面我会详细介绍选举的原理。
Secondary 数据库存储了 Primary 上的所有数据,每当 Primary 上进行一次数据更新时,都会产生一条 oplog 纪录,secondary 根据 Primary 上的 oplog 来同步数据。一台 Primary 可以连接多台 secondary 数据库。多台 secondary 之间通过心跳检测来保持连接。虽然 secondary 不允许写操作,但是它允许客户端读取纪录,从而实现数据库的读写分离。在 primary 服务器不可使用的情况下,一台 secondary 可以成为 primary 接替数据写操作的任务。除了读写分离之外,secondary 还可以被配置成一下几种类型的数据库:
由于某些原因,你有可能不希望某一台 secondary 成为 primary 服务器,这种情况下你可以配置这台 secondary 的 priorty 使它永远不能成为 prmary。
你也可以禁止用户从 secondary 读取数据,这样的 secondary 可以被用在一些独立的场景,例如报表数据库,它会在一个独立的环境运行,不影响应用程序的正常使用。
还有一种配置被称为
延时 Secondary,你可以个他配置一个延时时间,在这个时间内他不会同步任何数据,这样的好处是个你一个反悔的时间。例如,你不小心丛 Prmary 上删除了一些重要数据,在一定时间内,你可以从延时 Secondary 上把这些数据恢复回来。
这是一种比较特殊的服务器,他不会存储任何纪录,也不会成为 Primary。他的作用是在 Replica Set 选择 Primary 时作为一个投票成员。当你的 Primary 不可用时,Replica 中的每个 Secondary 成员都有为新 Primary 投票的权利,但是如果你的成员个数是偶数,有可能两个候选 Primary 的得票数一样,此时 Arbiter 的存在会使投票个数是奇数,这样不会存在得票数一样多的情况。
上面已经提到,MongoDB 的高可用是通过 Replica Set 来完成的,简单来说,当 Replica Set 中的 Primary 不可用时,其中一个 Secondary 将会成为新的 Primary。但是这个过程也许并没有你想象的那么简单,这一节中我们来谈谈高可用的内部实现原理。
Replica Set 通过公开选举来选出当前某个成员为 Primary 成员。这个选举过程发生在两个地方,一个地方是当一个 Replica Set 在初始化的时候进行,另一个场景是当当前的 Primary 不可用时。下面显示了一个选举过程。
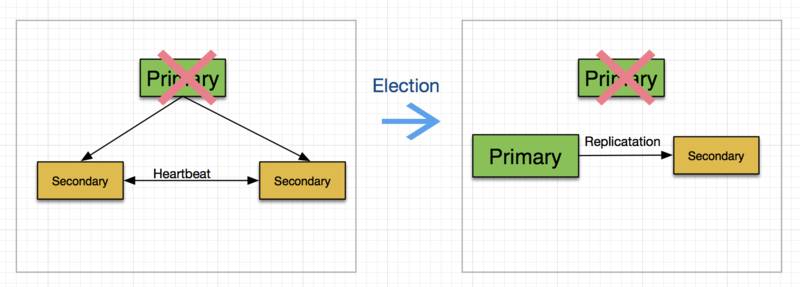
一次选举过程需要一定的时间,在这段时间内 Replica 不支持写操作,所有成员都将成为只读成员。这里需要介绍一个重要的概念,“大多数”,他的意思很简单就是一半以上成员选出的才算数。换句话说,只有当大多数成员选出来的服务器才能算是新的 Primary。上面的例子中,Replica Set 一共有三个成员,当一个 Primary 不可用时,另外两个 Secondary 构成了 Replica Set 中的“大多数”,因此他们选出来的服务器可以称为新的 Primary。如果在选举过程中没有构成“大多数”选票,则该 Replica Set 将成为没有 Primary 成员的 Replica,此时其他成员成为 Secondary 并只提供只读服务。注意上图中右侧新的 Replica Set 中,以前的 primary 并没有从 Replica 中删除,他仍然纪录在 Replica 里只不过状态被标记为”不可用“。为什么要强调这一点,其实这和刚刚提到的“大多数”成员的概念有关系,通常认为只要是 Primary 不可用直接将一台 Secondary 作为 Primary 就可以了,其实并不是这么简单。如果你盲目的认为一台 Primary 挂掉就直接从 Replica 里删除的话,你有可能永远不能理解“大多数”的概念。在这个例子中,如果剩下的两台服务器中的 Primary 挂掉以后,将不会有新的 Primary 被选出来,原因是这个 Replica Set 一共有三个成员,目前只剩下一个 Secondary,他并不能构成“大多数“成员,所以选举过程失败,将不会有新的 Primary 产生。如果此时,前面挂掉的两台 Primary 中的任何一台恢复工作,他的状态会自动变成可执行,这样就和剩下的那台 Secondary 组成了新的”大多数“,从而可以成功的再选出一个 Primary。
看到这里有的同学可能会问,为什么不设计成只要有一个成员可用就让它成为 Primary 呢?这样不是可以更好的保证数据库的高可用吗?其实在一开始学习 MongoDB 的时候我也有类似的问题,答案在下面的多数据中心部署中。
Replica Set 为 MongoDB 高可用提供了基本构架支持,但是当一个 Replica 中所有成员全部来自一个数据中心时,这种高可用在整个数据中心失效时并不能起到任何修复作用。数据中心的失效可以归结为自然灾害、供电不足、网络故障等原因。所以,将 Replica Set 成员部署到不同地理位置的数据中心中是灾难恢复的一个常用手段。
我们现回到上一节中提到的问题,为什么说选举一定要通过“大多数”来投票。先看下面的服务器构架:
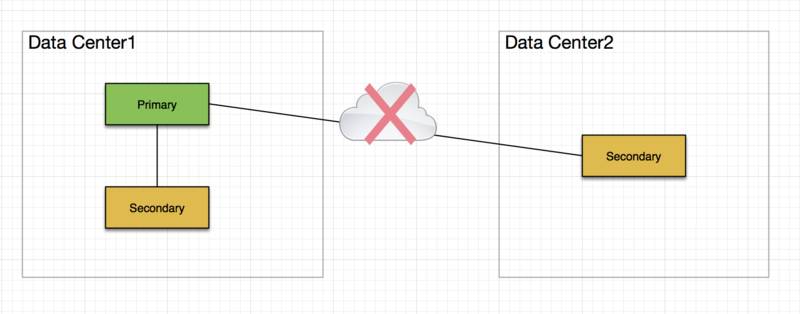
图中的 Replica Set 部署在两个数据中心,Data Center1 包含一个 Primary 一个 Secondary;Data Center2 包含一个 Secondary。如果两个数据中心之间的网络出现故障,此时的 Replica Set 被分割成了两个部分,如果没有“大多数”成员这个概念,那么大家可以想一下会出现什么情况,会有两个 Replica Set 同时提供服务,Data Center1 中的两个成员继续提供数据服务,因为 Primary 还在继续运行;但是 Data Center2 中仅剩的一台 Secondary 会把自己选成 Primary 并认为另两个成员不可用。当这两个 Replica Set 接收来自客户端的更新操作后,他们会各自更新个字的数据,那么如果两个数据中心之间的网络恢复以后,谁的数据才是准确的数据,他们之间应当按照什么样的逻辑来同步,可能这个问题并不能完美解决。所以,为了避免这种情况,MongoDB 工程师提出了“大多数”的概念,在这个概念下 Data Center2 中的 Secondary 由于它不构成“大多数”成员,因此它只能提供只读服务,而 Data Center1 中的两个成员可以构成“大多数”选票,他们继续承担 Replica 的职责。
好了,明白了“大多数”的概念以后我们看看在多数据中心情况下如何分配部署 MongoDB。还是以上面的例子,我们有一个三个成员 Replica Set 要部署在两个数据中心上。通常我们把一台 Primary 和一台 Secondary 放到一个数据中心,另外一个 Secondary 放到另一个数据中心。如果其中一个成员是 Arbiter,不要把它单独放在一个数据中心,他要和一个有数据的服务器放到一起。此时:
如果第一个数据中心失效,这个 Replica Set 会成为只读服务器;
如果第二个数据中心失效,这个 Replica Set 可以继续正常工作。
如果要把他们部署到三个数据中心上,此时如果任何一个数据中心实效,剩下的两个仍然可以构成一个完整的 Replica Set。
在处理 MongoDB Replica Set 时,不得不提的一个关键要素就是 Write Concern / Read Preference。由于数据库的全部数据在所有的 Replica Set 服务器中都有一份拷贝,那么当我们进行一次数据库更新时,是不是需要更新到所有数据库呢?这样做当然理想,因为他可以保证数据的一致性。但是人们对一致性的要求根据不同的需求和应用会有很大区别。有时,我们需要保证集群中的所有数据库都进行了同样的写操作,这样可以保证数据在不同服务器上存储是一致的。但是这样做带来的缺点是此次写操作会花费更多的时间,因为他要通知 Replica Set 中其他服务器,并且同样的操作也有在其他所有服务器中运行。也有一些对一致性要求不高的场景,此时我们可以在损失一致性的基础上提高数据库性能。那么 MongoDB 如何控制数据一致性的呢?这就是本节要提及的一个概念:Write Concern / Read Preference。下面我们分别介绍一下他们的在 Replica Set 中起到的作用。
Write Concern 定义了 MongoDB 在进行一次写操作时需要作出的确认级别。在默认情况下,一次数据库写操作只要在 Primary 服务器上执行完毕后就会返回。如下图所示:
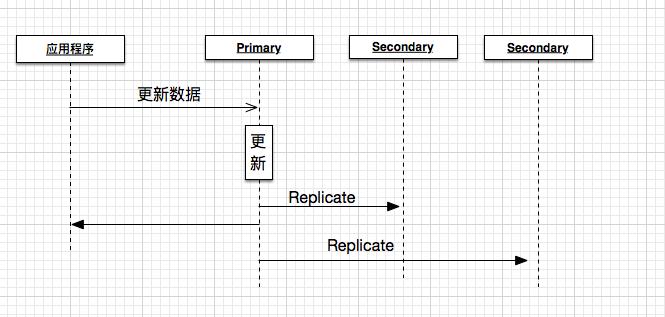
当服务器对 Primary 发起一次请求时,Primary 根据请求更新自身数据,然后返回更新结果,于此同时将本次操作广播到其他 Secondary 中。所以,应用程序在得到操作完成时并不能保证其他 Secondary 也做了同样的更新。此时如果另外一个应用程序向其中一台 Secondary 读取数据,有可能他得到的是更新前的数据。也许你会觉得这种现象的概率很小,设想一下在一个有上千万用户的应用中,每秒都会有若干次数据库读写操作,在这样庞大的负载量环境下,刚刚提到的场景时时刻刻都在发生。Write Concern 就是为这种需求而设计的。通过 Write Concern 我们可以设计一下几个场景,我们可以指定,
在一个 Replica Set 中,只有当一定数量的服务器进行了相应操作才确认此次更新完成;
或者,只要 Primary 获得了更新就算操作完成;
或者,大多数服务器进行了操作就确认更新完成;
或者,具有某个标签的服务器操作成功就确认。
除了这几个场景之外,我们还可以设置超时时间,当操作在一定时间内没有完成就认为操作失败。
于 Write Concern 类似,Read Preference 指的是在对数据库进行读取操作时,Replica Set 会将改操作转发给哪个服务器。默认情况下,所有的操作都会由 Primary 服务器来处理,但是在大应用程序构架中,我们要尽量降低 Primary 服务器并发访问次数,因此很多人会通过设置 Read Preference 来分发数据库请求到其他 Secondary 服务器上,有以下集中模式可供我们选择:
primary: 默认模式,所有请求都会发送到 Primary 上。
primaryPreferred:大部分读请求都会发送到 Primary,但是当 Primary 无法访问时,改请求会被转发到 Secondary 上。
secondary: 所有请求都会发送到 Secondary 上。
secondaryPreferred: 大部分情况下,读请求被发送到 Secondary 中,但是如果 Replica 中没有 Secondary,请求会发送到 Primary 上。
nearest: 请求会被发送到网络最近的服务器上。该模式在多数据中心上非常有效。
对于 secondary 和 secondaryPreferred 两种模式我们需要注意,特别是在多数据中心环境中,用户读到的数据有可能不是最新的。原因在上一节 Write Concern 中已经提到。在 shard 环境中,如果允许 Balancer,从 Secondary 中读到的数据有可能有重复。原因是 Balancer 的运行可能会导致一些 Chunk 是不完整的,而一些 Chunk 是重复的。关于 Shard 的应用,情参考我的另一篇文章MongoDB 的水平扩展,你做对了吗?。
通过上面的介绍,我想大家对多数据库中心部署 MongoDB 有了新的认识。希望大家能够在自己的测试环境上多测试一下 Read Preference 和 Write Concern 的组合应用。另外,大多数成员的概念也是一个很重要的因素。不断的调整参数和服务器数量是保证服务器构架不断稳定的前提。只有了解了构架底层的原理才能更好的应用到日常开发环境中。
MongoDB 的水平扩展,你做对了吗?
dbKoda
如何通过 MongoDB 自带的 Explain 功能提高检索性能?
MongoDB Docker Cluster
CAP theorem
Read Preference
Write Preference
作者简介:赵翼, 毕业于北京理工大学,目前就职于 SouthbankSoftware,从事 NoSQL,MongoDB 方面的开发工作。曾在 GE,ThoughtWorks,元气兔担任项目开发,技术总监等职位,接触过的项目种类繁多,有 Web,Mobile,医疗器械,社交网络,大数据存储等。
12 月初 ArchSummit 上的一系列 DevOps 分享,邀请了阿里、百度、微博、Pinterest 等顶尖专家前来答疑解惑,更多详情欢迎点击 阅读原文 进一步了解,如在报名过程出问题,可联系票务经理豆包(微信:aschina666)或直接致电 010-84780850
以上是关于多数据中心环境下的 MongoDB 部署的主要内容,如果未能解决你的问题,请参考以下文章