干货满满 | MongoDB集群实战攻略
Posted ITPUB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货满满 | MongoDB集群实战攻略相关的知识,希望对你有一定的参考价值。
文 | 杨荣康
转自 | 中兴大数据
简介
MongoDB是一个开源的,基于分布式的,面向文档存储的菲关系型数据库。可以运行在Windows、Unix、OSX、Solaris系统上,支持32位和64位应用,提供多种编程语言的驱动程序。MongoDB支持的数据结构非常松散,是类似JSON的BSON格式,通过键值对的形式存储数据,可以存储复杂的数据类型。
基本概念
文档(document):文档是MongoDB的核心概念,是数据的基本单元,类似于关系数据库中的行。在MongoDB中,文档表示为键值对的一个有序集。文档一般使用如下的样式来标记:
{"title":"hello!"}
{"title":"hello!","recommend":5}
{"title":"hello!","recommend":5,"author":{"firstname":"paul","lastname":"frank"}}
从上面的例子可以看到,文档的值有不同的数据类型,甚至可以是一个完整的内嵌文档(最后一个示例的author就是一个文档)
集合(collection):集合是一组文档的集合,相当于关系型数据库中的数据表,MongoDB数据库不是关系型数据库,没有模式的概念。同一集合中的文档可以有不同的形式。比如:
{"name":"jack","age":19}
{"name":"wangjun","age":22,"sex":"1"}
可以存在同一个集合当中。
数据库(database):多个文档构成集合,多个集合组成数据库。一个MongoDB实例可以承载多个数据库,每个数据库可以拥有0到多个集合。
MongoDB 的主要目标是在键值对存储方式(提供了高性能和高度伸缩性)以及传统的 RDBMS(关系性数据库)系统,集两者的优势于一身。MongoDB适用于以下场景:
网站数据:Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
缓存:由于性能很高,Mongo 也适合作为信息基础设施的缓存层。在系统重启之后,由 Mongo 搭建的持久化缓存可以避免下层的数据源过载。
大尺寸、低价值的数据:使用传统的关系数据库存储一些数据时可能会比较贵,在此之前,很多程序员往往会选择传统的文件进行存储。
高伸缩性的场景:Mongo非常适合由数十或数百台服务器组成的数据库
用于对象及JSON数据的存储:Mongo的BSON数据格式非常适合文档格式化的存储及查询。
当然 MongoDB 也有不适合的场景:
高度事务性的系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量事务的应用程序。
传统的商业智能应用:针对特定问题的 BI 数据库能够提供高度优化的查询方式。对于此类应用,数据仓库可能时更适合的选择(如Hadoop套件中的Hive)。
需要SQL的问题。
集群攻略
MongoDB在商用环境中,为了高可用性,通常都是以集群形式使用的,MongoDB的集群环境搭建非常简单,下面就作一个介绍。
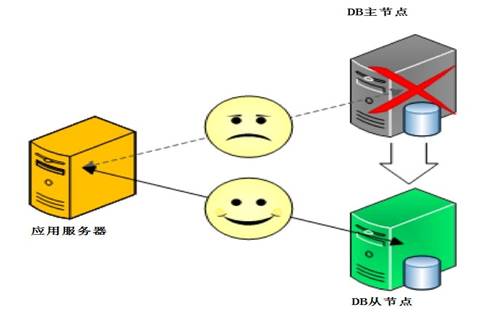
主从模式
我们在使用mysql数据库时广泛采用的模式,采用双机备份后主节点挂掉了后从节点可以接替主机继续服务。所以这种模式比单节点的要可靠得多。
下面看一下怎么一步步搭建MongoDB的主从复制节点:
1. 准备两台机器 10.43.159.56 和 10.43.159.58。 10.43.159.56当作主节点, 10.43.159.58作为从节点。
2. 分别下载MongoDB安装程序包。在10.43.159.56上建立文件夹/data/MongoDBtest/master,10.43.159.58建立文件夹/data/MongoDBtest/slave。
3. 在10.43.159.56启动MongoDB主节点程序。注意后面的这个 “ –master ”参数,标示主节点:
mongod –dbpath /data/MongoDBtest/master–master
输出日志如下,成功:
[initandlisten] MongoDB starting :pid=18285 port=27017 dbpath=/data/MongoDBtest/master master=1
mongod –dbpath /data/MongoDBtest/slave–slave –source 10.43.159.56:27017
输出日志如下,成功:
[initandlisten] MongoDB starting : pid=17888port=27017 dbpath=/data/MongoDBtest/slave slave=1
日志显示从节点从主节点同步复制数据 :
[replslave] repl: from host: 10.43.159.56:27017
这样,主从结构的MongoDB集群就搭建好了,是不是很简单?
下面我们来看看这个集群能做什么?先登录到从节点shell上,执行插入数据:
mongo 127.0.0.1:27017
> db.testdb.insert({"test3":"testval3"});
not master
可以看到 MongoDB的从节点是只能读,不能执行写操作的。
那么如果主服务器挂掉,从服务器可以接替工作吗?
可以试一下,强制关掉主节点上的MongoDB进程,登录在从节点上,再次执行插入数据:
> db.testdb.insert({"test3":"testval3"});
not master
看来从节点并没有自动接替主节点的工作,那就只有人工处理了,停止从节点,再以master的方式启动从节点,由于从节点上数据跟主节点一样,此时从节点是可以替代主节点工作的,这属于人工切换。
此外,我们可以搭建多个从节点,实现数据库的读写分离,比如主节点负责写,多个从节点负责读,对于移动APP,绝大部分操作都是读操作,可以实现负荷分担。
那么,搭建了这套主从结构的集群是不是就能应付商用环境呢?我们发现还是有几个问题亟待解决的:
主节点挂了能否自动切换连接?目前需要手工切换。
主节点的写压力过大如何解决?
从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大?
就算对从节点路由实施路由访问策略能否做到自动扩展?
解决这几个问题就要靠下面介绍的副本集模式了。
副本模式
MongoDB官方已经不建议使用主从模式了,替代方案是采用副本集的模式,那什么是副本集呢?简单地说,副本集就是有自动故障恢复功能的主从集群,或者说主从模式其实就是一个单副本的应用,没有很好的扩展性和容错性。而副本集具有多个副本保证了容错性,就算一个副本挂掉了还有很多副本存在,更棒的是副本集很多地方都是自动化的,它为你做了很多管理工作。聪明的读者已经发现,主从模式的第一个问题手工切换已经得到解决了,难怪MongoDB官方强烈推荐使用这种模式。我们来看看MongoDB副本集的架构图:
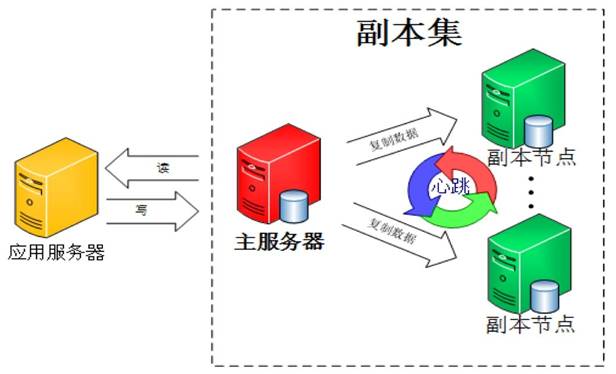
由图可以看到客户端连接到整个副本集,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份,一旦主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应用服务器不需要关心。我们看一下主服务器挂掉后的架构:
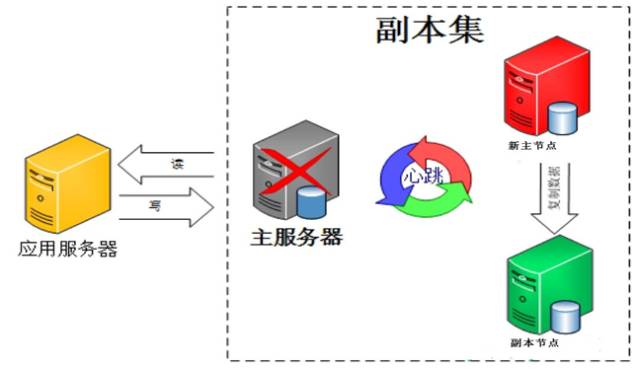
副本集中的副本节点通过心跳机制检测到主节点挂掉后,就会在集群内发起主节点的选举机制,自动选举一位新的主服务器。So Cool!让我们赶紧来部署一下!
官方推荐的副本集机器数量为至少3个(官方说副本集数量最好是奇数),那我们也按照这个数量配置测试。
1. 准备三台机器 10.43.159.56、 10.43.159.58、10.43.159.60。10.43.159.56当作副本集主节点,10.43.159.58、10.43.159.60作为副本集副本节点。
2. 分别在每台机器上建立MongoDB副本集测试文件夹
3. 下载安装MongoDB的安装程序包
4. 分别在每台机器上启动MongoDB
给你的副本集取个名字吧,比如这里叫test:
/data/MongoDBtest/MongoDB-linux-x86_64-2.4.8/bin/mongod --dbpath /data/MongoDBtest/replset/data --replSet test
从日志可以看出副本集还没有初始化。
5. 初始化副本集
在三台机器上任意一台机器登陆MongoDB:
/data/MongoDBtest/MongoDB-linux-x86_64-2.4.8/bin/mongo
使用admin数据库:
use admin
定义副本集配置变量,这里的 _id:”test” 和上面命令参数“ –replSet test” 要保持一致:
config = { _id:"test", members:[
... {_id:0,host:" 10.43.159.56:27017"},
... {_id:1,host:" 10.43.159.58:27017"},
... {_id:2,host:" 10.43.159.60:27017"}]
... }
初始化副本集配置:
rs.initiate(config);
输出成功:
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
查看日志,副本集启动成功后,56为主节点PRIMARY,58、60为副本节点SECONDARY,注意这里是三个节点共同选举出的主节点,有一定随机性。
查看集群节点的状态:
rs.status();
整个副本集已经搭建成功了。是不是超级简单?
副本集模式的MongoDB不仅搭建简单,而且功能强大。现在回头看看这种模式能否解决我们前面遗留的问题:主节点挂了能否自动切换连接?
先测试副本集数据复制功能是否正常
首先在主节点56上插入数据,然后再副本节点上查看数据,发现日志报错:
error: { "$err" : "not master and slaveOk=false", "code" : 13435 } at src/mongo/shell/query.js:128
这是因为默认只从主节点读写数据,副本不允许读,只要设置副本可以读即可。在副本节点上执行:rs.slaveOk(),然后查询数据,发现主节点的数据已经同步过来了。
再测试下副本集的故障转移功能
先停掉主节点56上的进程,可以看到58和60节点上的日志显示的就是投票过程。再执行rs.status()可以看到集群状态更新了,56为不可达,58成为主节点,60还是副本。再启动56节点,发现还是58为主节点,56变为副本节点。这样就解决了第一个故障自动转移的问题。
那么,对于主节点读写压力过大,如何解决呢?常见的解决方案是读写分离,MongoDB副本集的读写分离如何做呢?
看图说话:
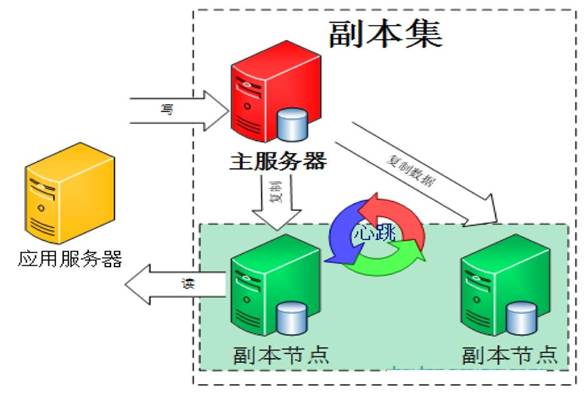
对于移动APP的场景,通常写操作远没有读操作多,所以一台主节点负责写,两台副本节点负责读。从哪个节点读,完全可以由客户端选择,数据读取参数一共有五类(Primary、PrimaryPreferred、Secondary、SecondaryPreferred、Nearest):
Primary:默认参数,只从主节点上进行读取操作;
PrimaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从Secondary节点读取数据。
Secondary:只从Secondary节点上进行读取操作,存在的问题是Secondary节点的数据会比Primary节点数据“旧”。
SecondaryPreferred:优先从Secondary节点进行读取操作,Secondary节点不可用时从主节点读取数据;
Nearest:不管是主节点、Secondary节点,从网络延迟最低的节点上读取数据。
典型的副本集组网中,除了有副本节点,还有其他角色,比如仲裁节点,如下图:
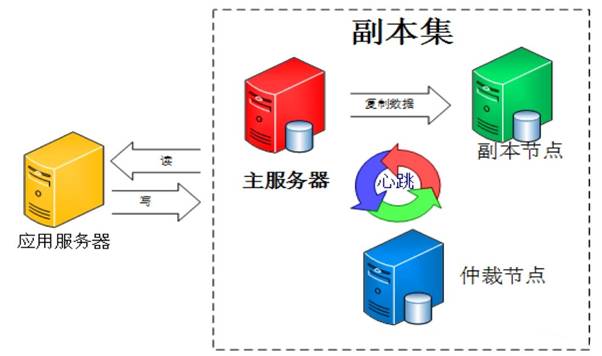
其中的仲裁节点不存储数据,只是负责故障转移的群体投票,这样就少了数据复制的压力。此外还有Secondary-Only、Hidden、Delayed、Non-Voting等角色。
Secondary-Only:不能成为Primary节点,只能作为Secondary副本节点,防止一些性能不高的节点成为主节点。
Hidden:这类节点是不能够被客户端制定IP引用,也不能被设置为主节点,但是可以投票,一般用于备份数据。
Delayed:可以指定一个时间延迟从Primary节点同步数据。主要用于备份数据,如果实时同步,误删除数据马上同步到从节点,恢复又恢复不了。
Non-Voting:没有选举权的Secondary节点,纯粹的备份数据节点。
总结及思考
到此整个MongoDB副本集搞定了两个问题:
主节点挂了能否自动切换连接? //咱用副本集
主节点的读写压力过大如何解决? //读写分离
还有两个问题待后续解决:
从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大?
如果数据压力大到机器支撑不了的时候能否做到自动扩展?
这个可以通过MongoDB的分片功能来解决,我们下次再说。Bye Bye!
本周Daily
◦
◦
◦
◦
以上是关于干货满满 | MongoDB集群实战攻略的主要内容,如果未能解决你的问题,请参考以下文章