MongodbGFS存储大文件(java版)
Posted 林老师带你学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongodbGFS存储大文件(java版)相关的知识,希望对你有一定的参考价值。
Mongodb 是一个开源的no-sql分布式数据库,Mongodb也为我们提供了基于文件的GFS分布式存储系统。因此利用Mongodb我们完全可以实现一个分布式的文件存储以及管理。
下面的内容主要为大家介绍,如何利用java,将大文件存入Mongodb数据库中。我们这里所说的大文件,是指大小在16M以上的文件,这也符合MongodbGFS的说明。
首先我们创建一个java工程,这里我们使用gradle初始化一个java工程,工程结构如下图。
当然这里你也可以使用maven来构建一个java工程,对我们后续工作并不会有影响。
接下来我们去mongodb的官网下载其基于java的驱动包。Mongodbjava驱动程序。
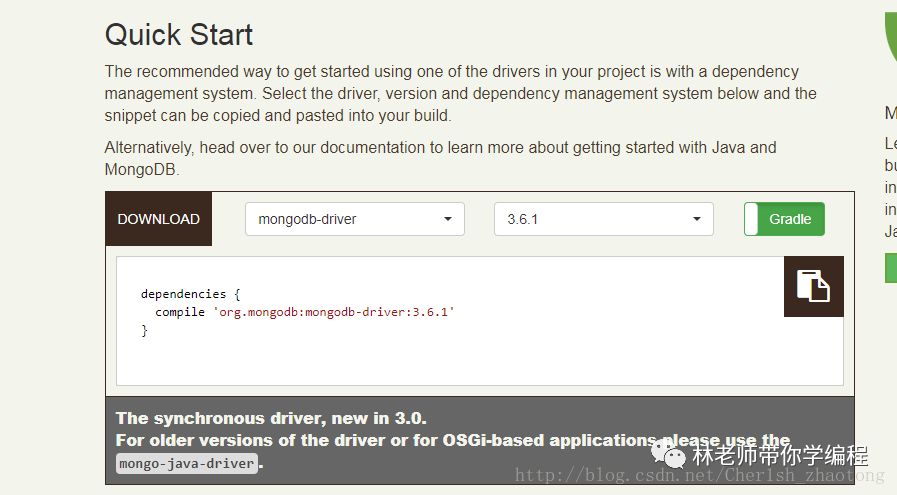
这里我们只需要将这一行,复制到我们工程的build.gradle 文件。
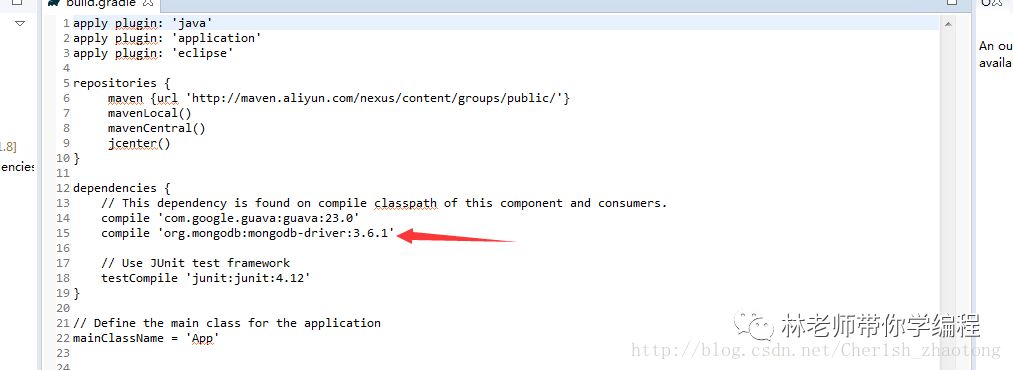
然后刷新gradle,我们可以看到jar包已经添加到我们的程序里。
接下来我们编写调用的示例,我们新建一个类叫做MongdbGFS.java。然后获取一个Mongodb的连接,代码如下:
[java] view plain copy
package mongodbGfs;
import com.mongodb.MongoClient;
import com.mongodb.client.MongoDatabase;
/**
*
* @author zhaotong
*
*/
public class MongodbGFS {
private MongoClient mongoClient;
//我们进行操作的数据库
private MongoDatabase useDatabase;
//初始化
{
mongoClient=new MongoClient("localhost",27017);
useDatabase=mongoClient.getDatabase("zhaotong");
}
}
接下来,我们先不着急写下面的代码,我们先找到一个文件放到我们工程里面,为了我们之后的测试。我在src下面新建了一个文件夹file,里面存放了一个大约21M的pdf文件。
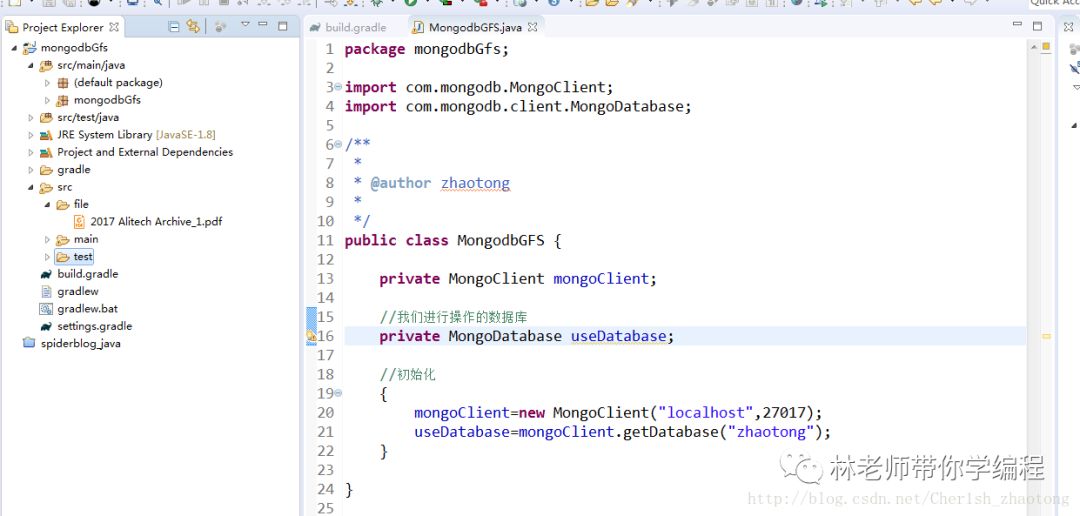
接下里我们开始进行mongodbGFS文件的存储。
GridFS is a specification for storing and retrieving files that exceed the BSON document size limit of 16MB. Instead of storing a file in a single document, GridFS divides a file into parts, or chunks, and stores each of those chunks as a separate document.
When you query a GridFS store for a file, the Java driver will reassemble the chunks as needed.
从上面这段话可以简单的了解到,mongodb是将文件进行分块,存储,当查询时,mongodb会帮你把你所需要的块进行组合然后展示给你,因此结合mongodb分布式的特性,我们可以轻易的构建一个分布式的文件存储。
在利用java驱动存储时,当我们获得需要存储的数据库连接之后,我们需要先创建一个bucket,官方的说明如下:
Create a GridFS Bucket
GridFS stores files in two collections: a chunks collection stores the file chunks, and a files collection stores file metadata. The two collections are in a common bucket and the collection names are prefixed with the bucket name.
通过上面的这段话,我们可以知道,mongodb是将文件分为两部分存储,一个是chunks,另一个是files。并且在collection 的名字将会有你bucket的前缀。mongodb支持自定义的bucket的名字,当然也有默认,默认是files。
[java] view plain copy
* @author zhaotong
*
*/
public class MongodbGFS {
private MongoClient mongoClient;
//我们进行操作的数据库
private MongoDatabase useDatabase;
//bucket
private GridFSBucket gridFSBucket;
//初始化
{
mongoClient=new MongoClient("localhost",27017);
useDatabase=mongoClient.getDatabase("zhaotong");
// 自定义bucket name
gridFSBucket= GridFSBuckets.create(useDatabase,"zt_files");
// 使用默认的名字
//gridFSBucket=GridFSBuckets.create(useDatabase);
}
}
接下来就是对应的具体操作,代码如下:
[java] view plain copy
package mongodbGfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.List;
import org.bson.Document;
import org.bson.types.ObjectId;
import com.mongodb.Block;
import com.mongodb.MongoClient;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.gridfs.GridFSBucket;
import com.mongodb.client.gridfs.GridFSBuckets;
import com.mongodb.client.gridfs.GridFSUploadStream;
import com.mongodb.client.gridfs.model.GridFSFile;
import com.mongodb.client.gridfs.model.GridFSUploadOptions;
/**
*
* @author zhaotong
*
*/
public class MongodbGFS {
private MongoClient mongoClient;
// 我们进行操作的数据库
private MongoDatabase useDatabase;
// bucket
private GridFSBucket gridFSBucket;
// 初始化
{
mongoClient = new MongoClient("localhost", 27017);
useDatabase = mongoClient.getDatabase("zhaotong");
// 自定义bucket name
gridFSBucket = GridFSBuckets.create(useDatabase, "zt_files");
// 使用默认的名字
// gridFSBucket=GridFSBuckets.create(useDatabase);
}
// 将文件存储到mongodb,返回存储完成后的ObjectID
public ObjectId saveFile(String url) {
InputStream ins = null;
ObjectId fileid = null;
// 配置一些参数
GridFSUploadOptions options = null;
// 截取文件名
String filename = url.substring((url.lastIndexOf("/") + 1), url.length());
try {
ins = new FileInputStream(new File(url));
options = new GridFSUploadOptions().chunkSizeBytes(358400).metadata(new Document("type", "presentation"));
// 存储文件,第一个参数是文件名称,第二个是输入流,第三个是参数设置
fileid = gridFSBucket.uploadFromStream(filename, ins, options);
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
try {
ins.close();
} catch (IOException e) {
}
}
return fileid;
}
// 通过OpenUploadStream存储文件
/**
*
* The GridFSUploadStream buffers data until it reaches the chunkSizeBytes and
* then inserts the chunk into the chunks collection. When the
* GridFSUploadStream is closed, the final chunk is written and the file
* metadata is inserted into the files collection.
*
*/
public ObjectId saveFile2(String url) {
ObjectId fileid = null;
GridFSUploadStream gfsupload = null;
// 配置一些参数
GridFSUploadOptions options = null;
// 截取文件名
String filename = url.substring((url.lastIndexOf("/") + 1), url.length());
try {
options = new GridFSUploadOptions().chunkSizeBytes(358400).metadata(new Document("type", "presentation"));
// 存储文件,第一个参数是文件名称,第二个是输入流,第三个是参数设置
gfsupload = gridFSBucket.openUploadStream(filename, options);
byte[] data = Files.readAllBytes(new File(url).toPath());
gfsupload.write(data);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
gfsupload.close();
fileid = gfsupload.getObjectId();
}
return fileid;
}
// 查询所有储存的文件
public List<String> findAllFile() {
List<String> filenames = new ArrayList<>();
gridFSBucket.find().forEach(new Block<GridFSFile>() {
@Override
public void apply(GridFSFile t) {
filenames.add(t.getFilename());
}
});
return filenames;
}
// 删除文件
public void deleteFile(ObjectId id) {
gridFSBucket.delete(id);
}
// 重命名文件
public void rename(ObjectId id, String name) {
gridFSBucket.rename(id, name);
}
// 将数据库中的文件读出到磁盘上,参数,文件路径
public String downFile(String url, ObjectId id) {
FileOutputStream out = null;
String result=null;
try {
out = new FileOutputStream(new File(url));
gridFSBucket.downloadToStream(id, out);
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally {
try {
out.close();
result=out.toString();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
}
对应的单元测试类,大家可以下载运行:
[java] view plain copy
import org.bson.types.ObjectId;
import org.junit.Before;
import org.junit.Ignore;
import org.junit.Test;
import mongodbGfs.MongodbGFS;
public class MongodbGFSTest {
private MongodbGFS mgfs;
@Before
public void init() {
mgfs=new MongodbGFS();
}
// 测试存储
@Ignore
public void saveFile() {
ObjectId id=mgfs.saveFile("src/file/2017 Alitech Archive_1.pdf");
System.out.println(id);
}
//测试存储二
@Ignore
public void saveFile2() {
ObjectId id=mgfs.saveFile2("src/file/2017 Alitech Archive_1.pdf");
System.out.println(id);
}
// 测试查询所有在当前数据库存储的文件
@Ignore
public void findAllFile() {
System.out.println(mgfs.findAllFile());
}
// 测试下载文件,存数据库
@Ignore
public void downFile() {
System.out.println(mgfs.downFile("src/file/alibaba.pdf",new ObjectId("5a6ec218f9afa00c086d94bb")));
}
// 测试删除文件
@Ignore
public void deleteFile() {
mgfs.deleteFile(new ObjectId("5a6ec218f9afa00c086d94bb"));
}
//测试重命名文件
@Test
public void rename() {
mgfs.rename(new ObjectId("5a6ec218f9afa00c086d94bb"), "zhaotong.pdf");
}
}
我们可以在管理工具中看到,我们存储的文件结构如下:
其每个块的存储如下:
以上是关于MongodbGFS存储大文件(java版)的主要内容,如果未能解决你的问题,请参考以下文章