阿里项目的高可用Mongodb集群部署
Posted 开发者交流圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里项目的高可用Mongodb集群部署相关的知识,希望对你有一定的参考价值。
数据副本
MongoDB中的一组副本是一群mongod进程,这些进程维护同样的数据集。副本集提供了冗余和高可用性,是生产环境部署的基础。
数据冗余和可用性
通过在不同的服务器上存储相同的数据,副本机制保证了一定程度的容错,即在一个数据库挂掉后,数据服务仍然可用。
在某些情况下,副本可以提升数据的读性能,因为用户可以从不同的数据库读取数据。在不同的数据中心维护数据的拷贝,能够提高分布式应用程序的可用性。也可以维护额外的副本用于其他的目的,比如灾难恢复,告警或者是备份。
Mongo中的副本
一个Mongo副本集包括几个数据轴承节点和一个可选的仲裁者。在这些节点中,有且只有一个主节点,其他的节点都被认为是辅助节点。
主节点接收所有的写操作。一套副本中,只有主节点能够确认
{ w: "majority"}
;虽然在一些情况下,另外的mongod进程会在短时间内认为自己是主节点。主节点将所有数据的变动记录在日志中,比如oplog
.
从节点复制主节点的oplog,然后根据日志重放数据集的变动,通过这样的方式达到和主节点的数据一致。如果主节点挂掉,一个合格的从节点将发起一次选举将自己选举为新的主节点。
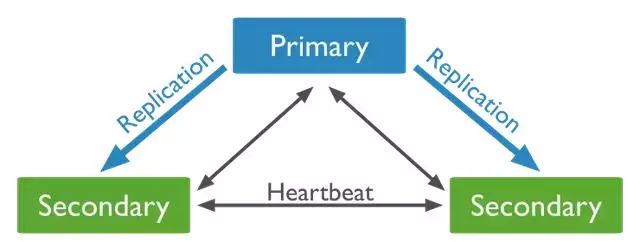
可以在副本集中添加一个额外的mongod实例作为仲裁者。仲裁者不维护数据集,它的主要功能是维护节点间的心跳和响应其他副本集成员的请求。因为仲裁者不维护数据,因此和一个完整节点相比,占用的资源会更少。如果副本集中节点数量是偶数,添加一个仲裁者可以在主节点的选举中添加多数选票的能力。
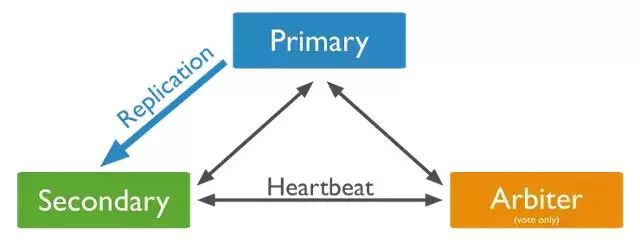
仲裁者的角色不会变,主节点有可能会降级成从节点,从节点也可能升级为主节点。
异步复制
从节点异步从主节点应用操作。在从主节点同步数据后,即使有部分节点挂掉,副本集依然可以保持工作。
自动故障转移
当一个主节点和副本集中的其他节点有超过10秒中的连接断开时,一个合格的从节点将发起选举,将自己提升为主节点。第一个发起选举并且得到副本集中大多数选票的节点会成为主节点。
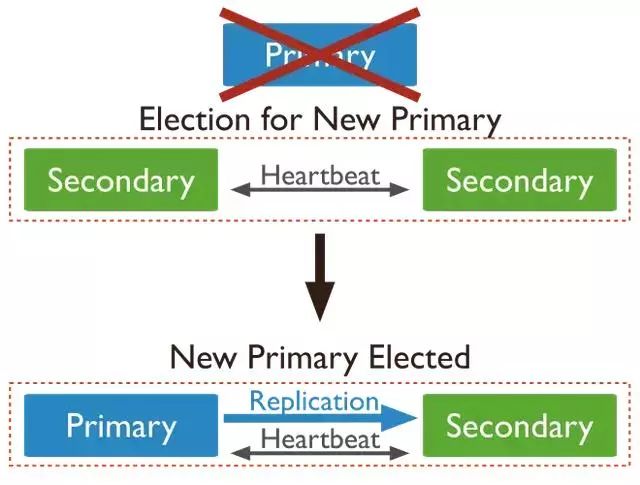
故障转移过程通常在一分钟内完成。副本集中的其他节点可能需要10到30秒来让确认主节点不可访问。在确认后将发起选举。选举的过程可能需要10到30秒。
读操作
默认情况下,用户会从主节点中读取数据,不过用户也可以通过设置发送读请求到从节点。异步制意味着从节点中的数据可能和主节点并不一致。
数据分片
数据分片是将数据分散存储在多个机器上。MongoDB使用分片技术来支持部署非常大的数据集,并提高系统的吞吐量。
单服务器会面临大量数据和高吞吐量的应用程序的挑战。比如,高频率的查询会耗尽服务器的CPU资源;大于系统内存的工作数据集会对磁盘的I/O造成很大压力。
有两种方式来应对系统数据的增长:垂直扩展和水平扩展。
垂直扩展包括增加单个服务器的能力,比如使用更强的CPU,添加更多内存,或者增加存储空间。现有技术的局限可能让单台机器无法应对某个给定的工作负载。另外,云服务商能够提供的硬件配置也有一定的上限。因此在实践中,垂直扩展能够应对的负载有上限。
水平扩展包括数据集的划分,和多台服务器分摊负载,水平扩展可以通过添加新的机器来提升处理能力。虽然单机的能力可能不是很强,但是每台机器都负责处理整体负载的一个子集,因此有能力提供比高速大容量服务器更高的效率。水平扩展提升系统的处理能力只需要添加新的服务器,这比提升高端服务器性能所需的成本要低。缺点是增加了基础设施部署和维护的复杂度。
MongoDB通过分片技术支持系统的水平扩展。
分片集群
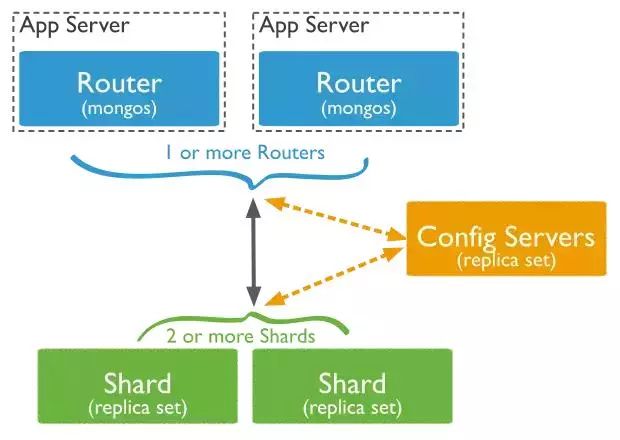
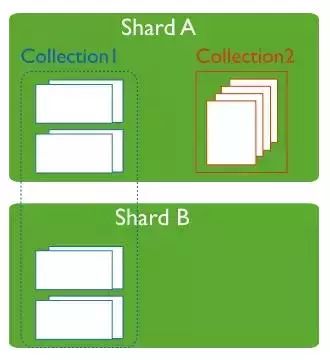
MongoDB的分片集群中有以下组件:
shard:每个shard都包含数据分片的一个子集。每个shard都可以部署为一个副本集
mongos:mongos作为查询路由,提供客户端应用程序和分片集群之间的接口
config servers:config servers存储集群中的元数据和配置数据。在Mongo3.4中,config server必须被部署为副本集。
下图展示了各个组件之间的交互。
Shard Keys
MongoDB使用shard key对collection的数据分片。shard key由一个不可变的字段或目标collection中每个文档都存在的字段组成。
需要在对collection分片的时候选择shard key。shard key之后不能更改。一个分片的collection只能有一个shard key。
要对一个非空collection分片,collection必须有一个由shard key开始的索引。对于空的collection,如果没有一个合适索引,MongoDB会创建索引。
shard key的选择会影响集群的性能,效率和可扩展性。shard key可能会成为集群的瓶颈,即使集群中的机器性能都很高。
chunks
MongoDB将数据分片到chunk中。依据选择的shard key,每个chunk大小都有下限和上限。
在集群中,MongoDB使用分片集群均衡器迁移各个chunk。均衡器试图实现在集群中chunk的均衡。
分片的优点
读/写
MongoDB在分片集群中,将读和写的负载分配到各个节点中,允许每个shard处理集群操作的一个子集。可以通过添加更多的shard横向扩展这种读写能力。
对于包括shard key的查询,mongos可以将查询定位到特定的shard。
存储性能
分片技术将数据分配到集群中的节点上,每个shard包含总数据集合的一个子集。随着数据集的增长,添加shard能够增加集群的存储容量。
高可用
即使在部分shard不可用的情况下,集群依然可以继续执行部分读/写操作。在挂掉的shard不可用期间,可用的shard的读写不受影响。
在生产环境中,shard应该部署为副本集,以提供数据冗余和可用性。
分片注意事项
在集群上实施分片需要仔细地规划,执行和维护。
仔细选择shard key,对于确保集群的性能和效率是必要的。在分片后不能改变shard key,也不能撤销分片。
分片有一定的操作要求和限制。
如果查询不包括shard key,mongos会广播操作,在集群中的shard中执行查询。这样的查询可能有较长耗时。
分片和非分片collection
一个数据库可能同时有分片的collection和非分片的collection。分片的collection是分区的,分布在集群的不同shard中。非分片的collection存储在主shard中。每个数据库都有自己的主shard。
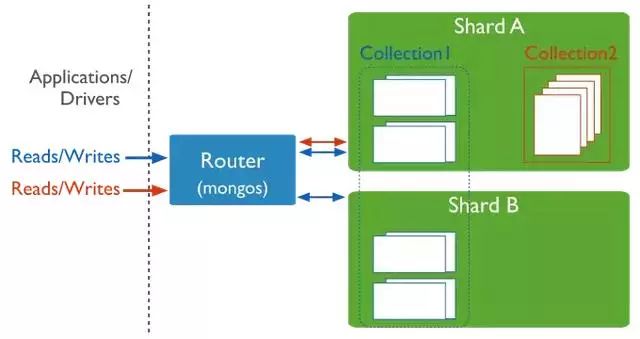
分片集群的连接
必须连接到mongos路由,来与分片集群中的collection交互。这种交互包括分片collection和非分片collection。客户端不允许直接连接到单独的shard来进行读写操作。
分片策略
MongoDB支持两种分片策略。
哈希分片
哈希分片是对shard key的值进行哈希运算后进行分片。每个chunk基于哈希后的值进行分配。
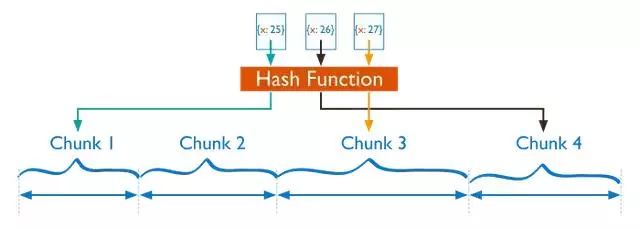
一个范围内的shard key可能很接近,但是hash后的结果很可能不在同一个chunk中。基于哈希的数据分布会形成更加均衡的数据分布,特别是在shard key单调变化的情况下。
但是,哈希分布意味着对范围查询不太可能定位到单个shard,这会导致广播操作。
范围分片
范围分片是将数据基于shard key的值进行切分。每个chunk基于shard key的值进行分配。
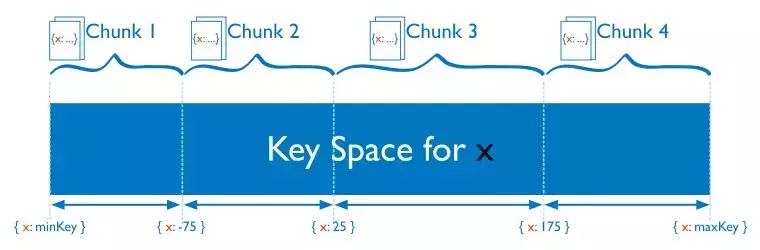
shard key某个范围内的值更可能分配在相同的chunk中,mongos会将请求导向只含有请求数据的shard中。
范围分片的效率取决于shard key。欠考虑的shard key会导致数据的分布不均,这会减少数据分片的优势或者导致性能瓶颈。
分片集群的区域
在分片集群中,可以基于shard key创建数据区域。可以把集群中的多个shard在同个区域中关联起来。一个shard可以和任意数量的非冲突区域关联起来。在平衡的集群中,MongoDB会将区域中的chunk迁移到区域里关联的shard中。
每个区域包括一个或多个范围的shard key。每个区域的覆盖范围总是包容它的下边界和排它的上界。
以上是关于阿里项目的高可用Mongodb集群部署的主要内容,如果未能解决你的问题,请参考以下文章