数据库评测报告MongoDB-3.2
Posted 运维+
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库评测报告MongoDB-3.2相关的知识,希望对你有一定的参考价值。
一、什么是MongoDB?
MongoDB是一个开源的,基于分布式的,面向文档存储的非关系型数据库,使用JSON风格来存储数据。其也是非关系型数据库当中功能最丰富、最像关系数据库的。MongoDB由C++编写,其名字来源于"Humongous"这个单词,其宗旨在于处理大量数据。
MongoDB作为如今新兴的Web框架---MEAN架构(MongoDB + Express +AngularJS + NodeJS)的重要组成部分,其如今的发展势头大有与传统Web框架(LAMP、LNMP)抢占市场主流框架的趋势。
MongoDB具有如下优势:
支持的数据结构非常松散,可存储复杂的数据类型;
支持多种操作系统上,提供多种编程语言的驱动程序;
支持的多种数据类型;
支持的查询语言非常强大;
弱一致性,更能保证用户的访问速度;
内置GridFS,支持大容量的存储;
内置Sharding;
文档结构的存储方式,能够更便捷的获取数据;
Wired Tiger引擎的使用,使得局部锁成为可能(新);
Wired Tiger引擎的使用,对数据进行压缩,减少了大量空间占用(新)。
看到MongoDB如此特性和优势,不免勾起了我们的好奇心。这一期的评测报告就着重针对MongoDB的读写性能的进行测试和分析,一起来揭秘一下如今MongoDB在市场上如此被推崇的原因。
二、MongoDB的性能如何?
1、Insert性能
MongoDB的Insert性能随着线程数(小于128)的增加而增加,当大于128时,Insert性能开始逐渐出现明显波动和下降;
当线程数量达到128时,MongoDB的Insert性能达到峰值,约为19万;
平均延迟随线程数量的增加而增加,且增加速度越来越快;
2、Read / Update性能 VS 线程数
① 百万级数据量(500万)
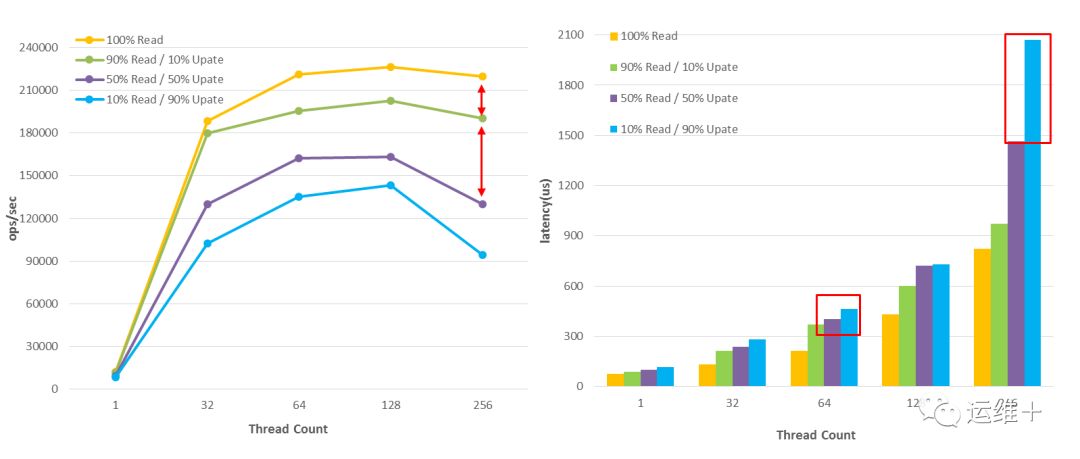
对百万级数据的操作,MongoDB读性能优于写性能,随着写的比重增加,吞吐率明显减少,且系统延迟明显增加;
只读、读多写少、读写混合、读少写多,这四个场景均在线程数达到128时达到峰值,分别约为23万、20万、16万、14万;
随着线程数的增加,写比重越大,其吞吐率波动性越大,越不稳定,且当线程数高于128时,吞吐率下降越明显,系统延迟增加越明显(即MongoDB读操作在数据量较少时稳定性更强);
对百万级数据的操作,当写比重超过50%时,吞吐率出现明显下降,且随线程数增加而越发明显。
② 千万级数据量(3000万)
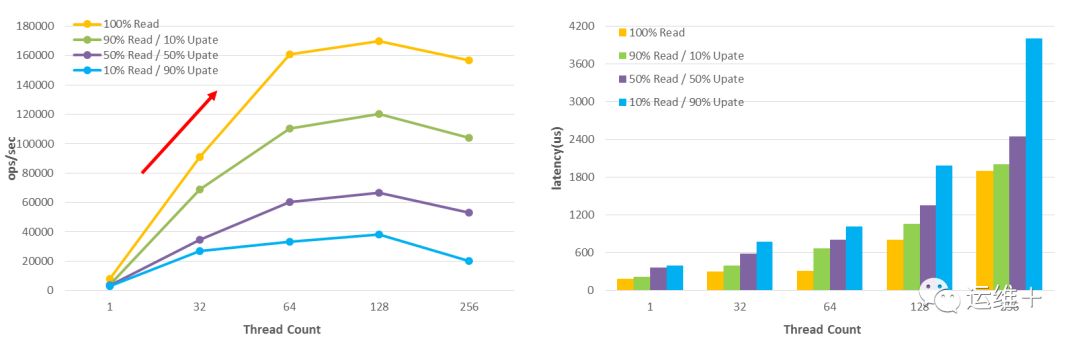
对千万级数据的操作,MongoDB读性能优于写性能,随着写的比重增加,吞吐率明显减少,且系统延迟明显增加;
只读、读多写少、读写混合、读少写多,这四个场景均在线程数达到128时达到峰值,分别约为17万、12万、7万、4万;
读写吞吐率均在线程数由1增加到64时,增长率最高。
③ 亿级数据量(1亿)
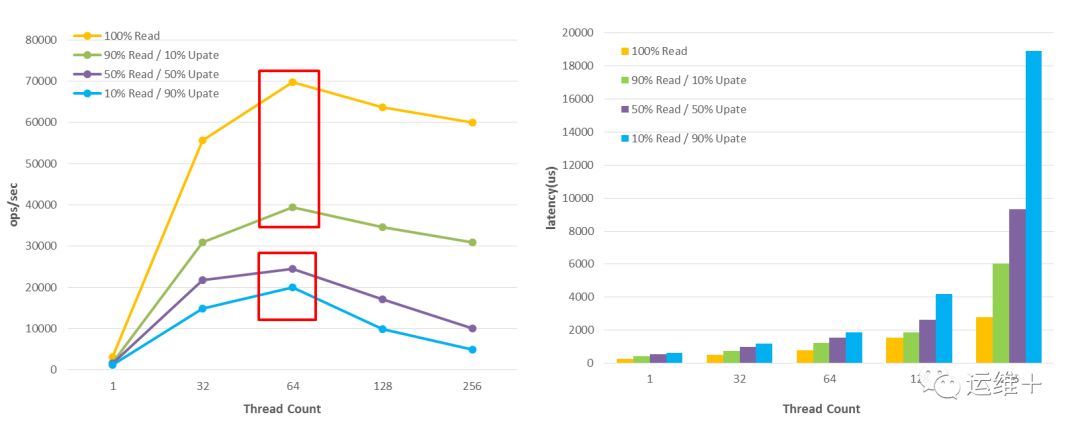
对亿级数据的操作,MongoDB读性能优于写性能,随着写的比重增加,吞吐率明显减少,且系统延迟明显增加;
只读、读多写少、读写混合、读少写多,这四个场景均在线程数达到64时达到峰值,分别约为7万、4万、2.5万、2万;
对亿级数据的操作,当写比重稍微增加,吞吐率直线下滑,并随线程数增加而越发明显;
当线程数高于64时,四个场景的吞吐率均出现明显下降。
3、Read / Update性能 VS 数据规模
①吞吐率
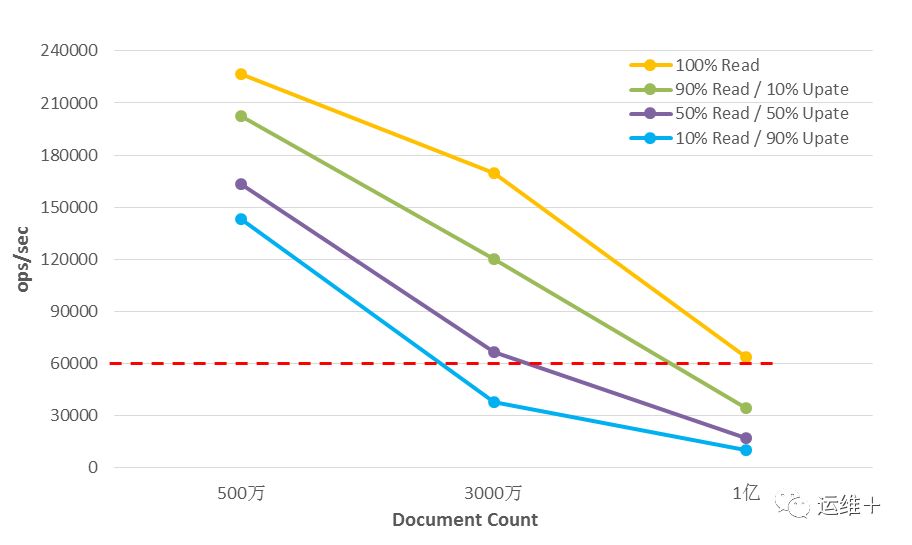
随着数据量的增加(百万级、千万级、亿级),MongoDB的读写吞吐率均下降;
在数据量达到亿级时,MongoDB读操作的吞吐率还能维持在较高的水平。
②系统延迟
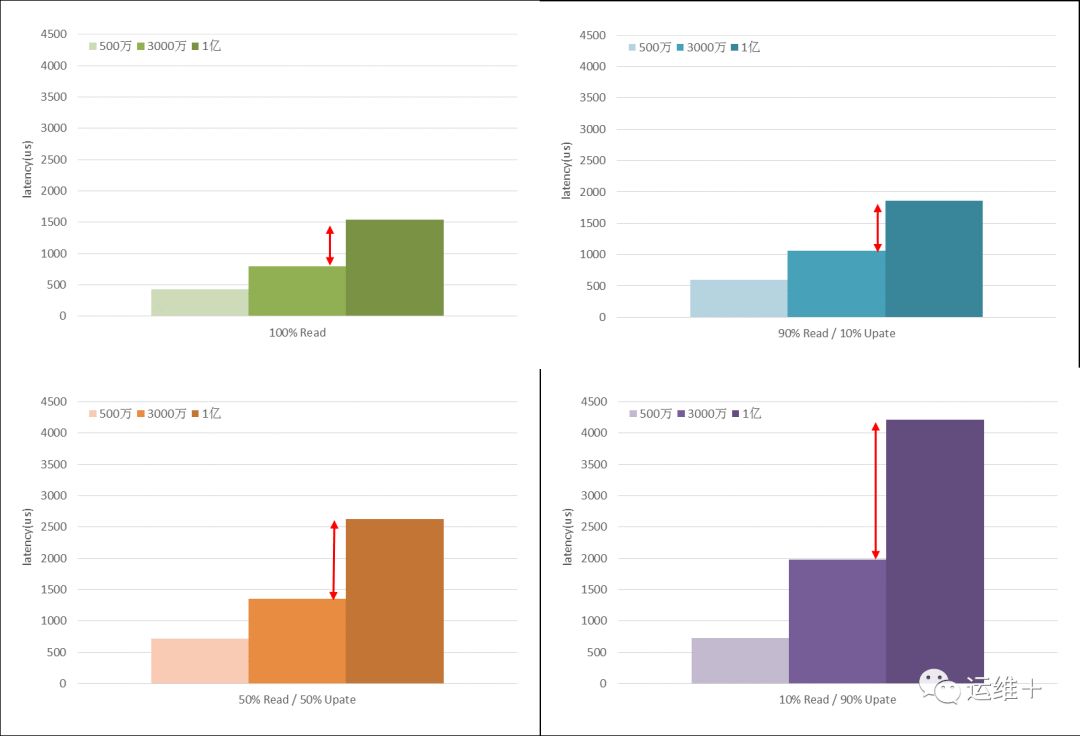
随着数据量的增加(百万级、千万级、亿级),MongoDB的读写延迟明显增加;
写操作是造成系统延迟的主要因素,并且随着数据量和写比重的增加,造成的延迟增加的影响会逐渐放大。
三、MongoDB的使用建议?
通过以上测试数据和分析说明,给出如下结论:
MongoDB读性能优于写性能(吞吐率、稳定性);
MongoDB在TS90上的针对中小数据量的读写,以128线程为最优,对于大数据量的读写,以64线程为最优;
MongoDB写操作对整体吞吐率的影响,随着数据量的增加而越发明显;
写操作比读操作更容易造成系统延迟,并且随着数据量的增大,造成的影响越发明显;
单个集合达到亿级数据量时,MongoDB的读写性能均有明显下降,设计集合时,应尽量将集合的文档数量控制在亿级以下。
【数据库评测报告】MongoDB的主要内容就是以上这些了(本测试只是针对小规模大数据进行了压力测试,对于大文件的测试以及在集群环境中的性能测试还在酝酿当中),测试在进行过程中由于网络条件、数据库配置等因素的影响,可能无法发挥出TS90机器的最大性能,但在一定程度上对于数据库选型具有参考价值。还想了解测试的参数和细节的朋友可以继续往下读。
四、环境配置包括哪些?
1、硬件环境
| 设备型号 | 配置描述 | CPU型号 |
| TS90 | 2个12核CPU,256G内存,12*800G SSD,万兆网卡 | E5-2670v3 |
2、软件环境
| 测设设备 | 数据库版本 |
| TS90 | MongoDB-3.2 |
3、测试细节
(1)测试工具
所谓工欲善其事,必先利其器,对于测试工具的选择会直接对测试的结果产生较大影响,一个好的测试首要要解决的必然是选择哪款测试工具。本次测试采用的测试工具是YCSB,肯定很多人会问,为什么NoSQL测试工具那么多,为什么会选择YCSB呢?这款性能测试工具的轻量级设计、多兼容性、支持多场景和多线程等特性都足够碾压其他测试工具的,最重要的是MongoDB官方测试所采用的工具就是YCSB。下面详细给大家介绍一下这款工具的原理和优势。
YCSB是Yahoo开发的一个专门用来对新一代数据库进行基准测试的工具。全名是Yahoo! Cloud Serving Benchmar。上图是YCSB的结构,可以看成是一个数据库客户端。暗色的模块是可以替换的,Workload Executor是产生应用负载的,DB Interface Layer是将特定数据库的API转为YCSB的API,用户可以自定义负载和数据库。
YCSB的包括以下几大特性:
支持常见的数据库读写操作,如插入,修改,删除及读取;
多线程支持,YCSB用Java实现,有很好的多线程支持;
灵活定义场景文件,可以通过参数灵活的指定测试场景;
数据请求分布方式多样,支持随机、Zipfian以及其他请求分布方式;
可扩展性强,可通过扩展Workload的方式来修改或者扩展YCSB的功能。
(2)测试流程
① 建立测试数据库database;
② 在数据库中建立结构相同的3个测试集合(Test_20、Test_80、Test_300);
③ 利用YCSB的S1场景向测试集合中分别插入一定数量的文档(500万、3000万、1亿);
④ 利用YCSB的S2~S5场景分别在3个测试集合上进行多线程测试;
⑤ 结果数据的分析。
(3)测试场景
| 场景名 | 场景介绍 | 场景配置 |
S1 |
插入 (100% insert) |
insertproportion=1 |
| S2 | 多读少写 (90% read/10% update) |
readproportion=0.9 updateproportion=0.1 |
| S3 | 读写均衡 (50% read/50% update) |
readproportion=0.5 updateproportion=0.5 |
| S4 | 多写少读 (10% read/90% update) |
readproportion=0.1 updateproportion=0.9 |
| S5 | 只读 (100% read) |
readproportion=1 |
(4)测试表结构
| 集合名 | 大小 | 相关信息 | 索引 | 文档数 |
| Test_20 | 20GB | 每个文档大小:2KB~5KB 安全设置:acknowledged 插入文档的顺序:哈希/随机 |
_id | 500万 |
| Test_80 | 80GB | 3000万 | ||
| Test_300 | 300GB | 1亿 |
以上是关于数据库评测报告MongoDB-3.2的主要内容,如果未能解决你的问题,请参考以下文章
如何使用用户名和密码连接到Java中的MongoDB 3.2?