容器里的MongoDB云数据库服务
Posted UCloud云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了容器里的MongoDB云数据库服务相关的知识,希望对你有一定的参考价值。
引 言
作为云计算服务中的重要一环,云数据库提供了可弹性伸缩的结构化、半结构化和非结构化数据的存储服务。用户可以根据自身业务状况,按需购买,一键部署,按需扩展。换句话说,用户可以直接省去中间一系列繁琐的资源调配、配置优化等工作,这样托管式的运维模式,为用户带来了极好的体验。
但是,云数据库服务对可用性和性能有极高的要求,这也正是用户最为关心的话题。UCloud提供的云数据库服务UDB(UCloud Database),完全兼容mysql和MongoDB协议,其中在构建高可用、高扩展性的MongoDB云数据库服务过程中,采用了Docker容器技术。本文将介绍Docker容器技术在MongoDB云数据库服务中的应用实践。
MongoDB云数据库服务
MongoDB是NoSQL领域非常优秀的面向文档的非关系型数据库,适用场景是非常的广泛,可以是业务类、日志类、监控类、元数据、文件存储等场景,普遍的特点是数据增长快,Schema多样。当单表的数据量达到TB级别时,关系数据库管理系统(RDBMS)很可能就力不从心。此外,单点压力和单点故障更是普遍存在的问题,还有成本控制和管理运维等问题。
面对这些问题,MongoDB云数据库服务提供了较好的解决方案。MongoDB不仅可以通过水平分片(sharding)来解决单点负载极限的问题,还可以通过副本集(replica set)解决高可用和读写分离等问题。另外,结合云平台优势,充分利用物理资源,降低集群部署的成本,也借助云平台,达到易部署、易管理的目的。具有高可用、高扩展性的MongoDB云数据库的典型分布式架构包括以下三类组件:
shardsvr
每个分片是一个副本集,集群可有1个至多个分片shardsvr,提供数据存储服务,存储整个集群的某部分数据。副本集按角色区分,可分为primary、secondary、arbiter,分别为主节点、从节点、仲裁节点。主节点可读写,从节点只读,仲裁节点参与auto-failover选举投票。通常一个副本集是一主一从一仲裁的结构,从节点也可以更多,建议是维持副本集总节点数为奇数。主节点一旦出现不可达情况,剩余节点自动选举出新主节点,实现auto-failover。可以为当前规模的集群新增分片数量,各分片自动均衡数据,实现水平扩展。
configsvr
集群可以有1个或者3个配置服务器configsvr,主要提供集群的元数据存储服务,记录集群数据分布。
mongos
mongos是整个集群的入口,提供查询的路由分发和结果聚合服务,集群可有1个或者多个路由服务器mongos。
图:UDB平台上MongoDB集群的架构图
为什么使用Docker
从我们的视角,云数据库服务需要克服多方面的问题,因为云化意味着面对的是多租户环境,需为之协调物理资源、设定资源配额;从成本控制来讲,我们希望能够充分利用物理机资源,到达降低成本的目的;由于每个DB实例行为不可预知 ,多租户环境下必须严格把控资源隔离,避免资源竞争,这就要求更高的多租户环境可控和安全;透明的云数据库服务,任何可能的物理故障都有可能随时发生,可运维和可移植就显得非常重要。
面对以上难题,虚拟机VM许是一种选择,但是对云数据库应用来讲,有比较大的局限性。所以,容器技术会是一种更好的选择,比如Docker。
相比虚拟机,Docker是一种轻量化虚拟化技术,轻量意味着占用资源少,损耗低,启动快,这对构建快速交付的运行时环境非常有利。
以Docker为代表的容器技术出现,使架构转向微服务的设计模式,微服务基本思路是将服务单元化和标准化,关注每个原子服务最基本功能。
MongoDB集群是典型的分布式系统,可利用容器封装干净的运行时环境,容器来封装微服务单元,即各类型的DB实例,容器之间保持互通,重组成完整的集群,提供完整的数据服务。所以,结合容器技术构建MongoDB集群是一种非常好的实践手段。
从多个角度来看, Docker对MongoDB云服务而言,存在互补,在众多方面是特性增强。
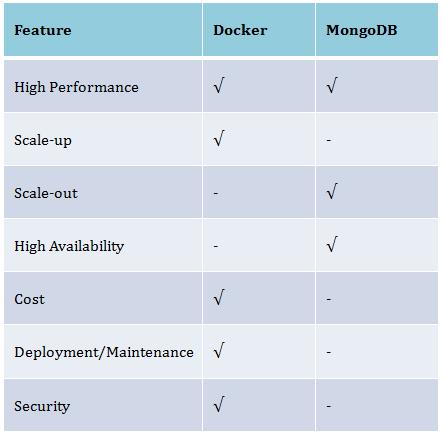
部署和运维
在UDB控制台上创建一个MongoDB实例,选择DB类别,选择物理(内存和磁盘)配置,由console通过 API调用向后端API-gateway发起,经过资源注册、订单、资源分配(包括ip、内存和磁盘)、实例化等过程后,在资源池中启动一个装载DB实例的容器。DB实例在内网暴露IP和port来提供访问,这也是访问DB的唯一方式。
图:集群实例分布效果图
通过最为简单的创建、组合两步,一个完整集群就呈现出来。后端按可用性来规避副本集内的节点部署在同台宿主机,每个Docker Engine上可以运行(起)多个容器。
图:集群部署示意图
我们在大规模部署Docker的生产环境的过程中,也总结了一些经验,分享如下:
Image
制作基础镜像,要求是干净、安全的,推荐使用官网的基础镜像;
使用Dockerfile或者其他工具,注意安装必要的工具链;
建议对Image有合理的版本迭代,逐步完善工具链,对运维和问题排查带来极大的便利。
操作系统
注意内核版本与Docker版本适配;
注意使用Cgroup默认挂载;
提高最大文件数限制,以避免DB连接数受限。
数据持久化
数据卷挂载;
为数据卷设置合理读写权限。
网络设置
自定义网桥,限制docker0;
内网建议按多租户隔离;
不作DB端口映射;
按需配置DNS。
安全加强
启动SELinux/GRSEC等安全机制;
启用能力机制,控制某些超级权限。
Docker Daemon防护
禁止宿主机的根目录映射;
禁止滥用root权限。
其中,网络设置、安全加强和Docker Daemon三点主要是针对安全方面的,安全性还是非常值得关注的。容器在虚拟网络层面已按多租户内网隔离,跨用户是无法访问的。此外,不提供途径访问容器,用户唯一可以访问的是DB服务。因为DB实例被严格限制在容器里,而且数据落地最终在外部设备,那么可以认为这样的容器它是轻容器,带IP+内存缓存,就很容易实现对DB实例在线扩容、缩容,或者在某些物理故障预警情况下,提前在线迁移。
此外,在保证服务的可靠性方面,多方面的监控、告警是非常必要的,建议从宿主机存活、网络连通性,Docker Daemon,容器存活和DB实例存活、网络联通性四个层次展开。一旦出现问题,可借助log进行诊断分析,如宿主机(/var/log/messages)、Docker(/var/log/docker)、DB系统日志和业务逻辑等日志。
结语
借助容器技术在多租户环境下,封装一个安全的DB运行时环境,做到资源限额和隔离,结合云平台,真正做到方便快捷地部署MongoDB集群。目前,UDB for MongoDB云数据库服务已经稳定运营达一年半,已有数千个容器在运行。希望本文提到的部署和运维经验,能为正在使用Docker或是即将使用Docker技术的朋友提供一些帮助。
以上是关于容器里的MongoDB云数据库服务的主要内容,如果未能解决你的问题,请参考以下文章