Spark在MongoDB上的读写操作
Posted Hadoop技术学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark在MongoDB上的读写操作相关的知识,希望对你有一定的参考价值。
1、首先Spark连接MongoDB库需要事先安装两个相应的jar包,这里下载的是mongo-spark-connector_2.11-2.2.5.jar包和mongo-java-driver-3.6.3.jar包,然后将jar包放在Spark安装目录的jars目录下(<Spark_home>/jars/)。每个节点都一样。
2、配置Saprk的配置文件,默认是<Spark_home>/conf目录下的spark-defaults.conf文件。
1
3、spark在MongoDB库的写操作
当需要将RDD数据集写入MongoDB时,需要先将RDD数据集转换成BSON文档。
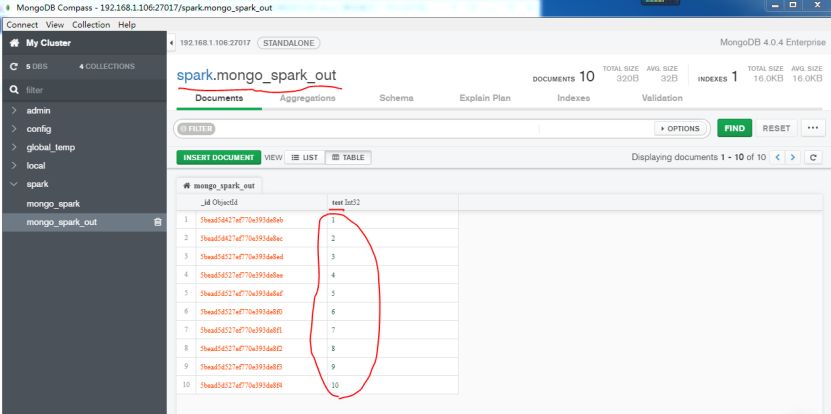
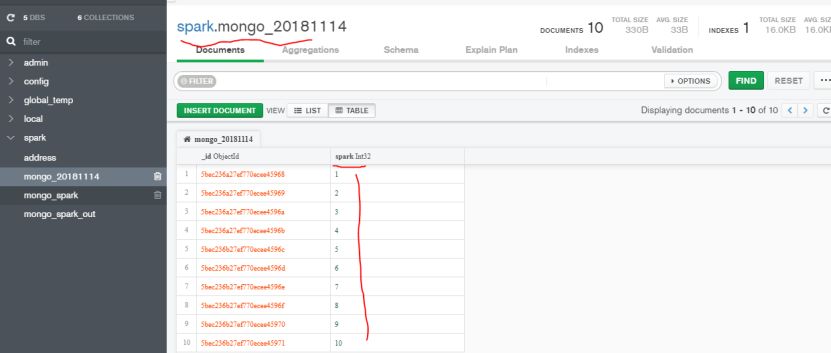
例子1,创建一个1到10的RDD数据并写入MongoDB集合。
import com.mongodb.spark._
import org.bson.Document
val document = sc.parallelize((1 to 10).map(i => Document.parse(s”{test:$i}”)))
MongoSpark.save(document)
由于此前已经在spark的配置文件中配置了MongoDB的默认输出库spark,默认输出集合是mongo_spark_out,所以上面代码执行结果可以直接查看mongo_spark_out集合。
如果用户想写入MongoDB另外的集合而不是在spark配置文件中默认的mongo_spark_out集合。则可以利用com.mongodb.spark.config包下的WriteConfig方法。
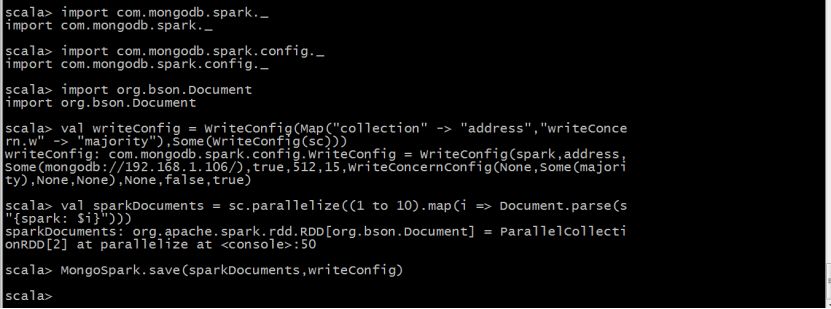
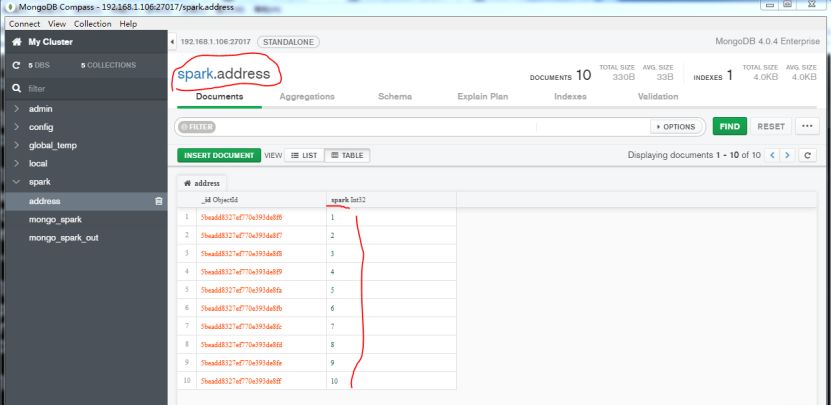
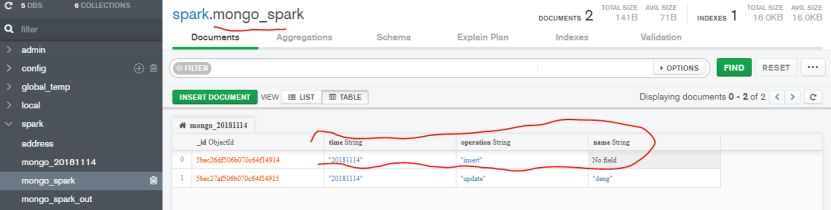
例子2:将上面例子,写入到MongoDB的address集合。
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.bson.Document
val writeConfig = WriteConfig(Map(“collection” -> “address”,”writeConcern.w” -> “majority”),Some(WriteConfig(sc)))
val sparkDocuments = sc.parallelize((1 to 10).map(i => Document.parse(s”{spark: $i}”)))
MongoSpark.save(sparkDocuments,writeConfig)
RDD有个隐式方法saveToMongoDB(),可以不带任何参数将文档保存到WriteConfig对象指定的集合中。
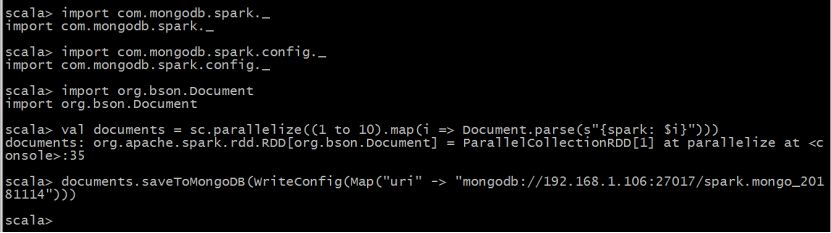
例子3:上面的例子2使用saveToMongoDB()方法可以用下面方式实现。
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.bson.Document
val documents = sc.parallelize((1 to 10).map(i => Document.parse(s"{spark: $i}")))
documents.saveToMongoDB(WriteConfig(Map("uri" -> "mongodb://192.168.1.106:27017/spark.mongo_20181114")))
4、spark在MongoDB上的读操作
通过前面了解spark可以通过MongoSpark.save方法和RDD的saveToMongoDB()实现对MongoDB数据库的写操作。而读操作则可以使用MongoSpark.load()方法和SparkContext对象的loadFromMongoDB()方法从特定的集合读取数据。
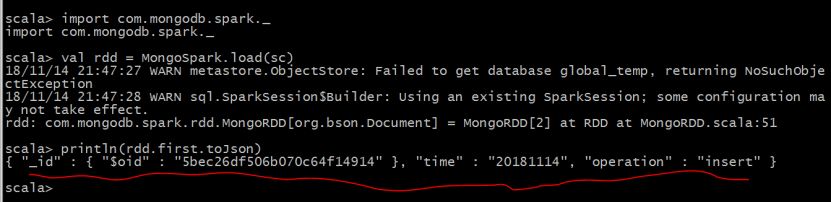
例子5:读取默认MongoDB集合mongo_spark中的第一个文档
import com.mongodb.spark._
val rdd = MongoSpark.load(sc)
println(rdd.first.toJson)
当需要读取MongoDB库上的特定数据库总的集合时,则可以使用ReadConfig()方法,用法和WriteConfig()方法相似。
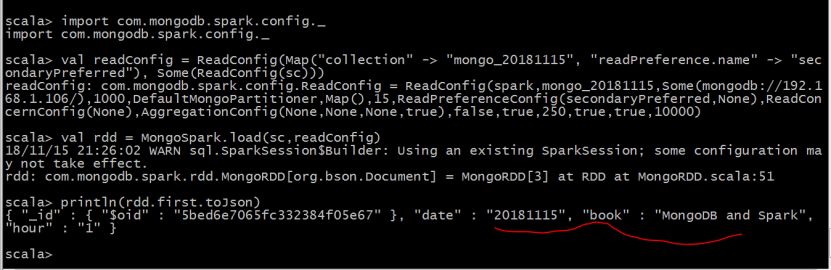
例子6:用loadFromMongoDB()方法读取spark库下的mongo_20181115集合的数据。
import com.mongodb.spark.config._
val readConfig = ReadConfig(Map("collection" -> "mongo_20181115", "readPreference.name" -> "secondaryPreferred"), Some(ReadConfig(sc)))
val rdd = MongoSpark.load(sc,readConfig)
println(rdd.first.toJson)
同样的,读操作有个loadFromMongoDB()方法可以读取uri指定的MongoDB库中集合。这个方法和saveToMongoDB()方法相似。不同的是loadFromMongoDB()是SparkContext对象的方法,而saveToMongoDB()方法是RDD对象的方法。
例子7:用loadFromMongoDB()方法实现例子6的读操作
import com.mongodb.spark.config._
import com.mongodb.spark._
val rdd = sc.loadFromMongoDB(ReadConfig(Map("uri" -> "mongodb://192.168.1.106:27017/spark.mongo_20181115")))
println(rdd.first.toJson)
以上是关于Spark在MongoDB上的读写操作的主要内容,如果未能解决你的问题,请参考以下文章