茶话小馆之MongoDB篇
Posted 云创数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了茶话小馆之MongoDB篇相关的知识,希望对你有一定的参考价值。
最近总会遇到一些关于MongoDB备份的问题, 为了方便大家的工作,小编收集了一些MongoDB的资料来和大家共享一下。
(一)、MongoDB的认识
1、什么是 MongoDB ?
MongoDB 是一个介于关系数据库和非关系数据库之间的开源产品,是最接近于关系型数据库的 NoSQL 数据库。它在轻量级JSON 交换基础之上进行了扩展,即称为 BSON 的方式来描述其无结构化的数据类型。尽管如此它同样可以存储较为复杂的数据类型。它和上一篇文章讲到的Redis有异曲同工之妙。虽然两者均为 NoSQL ,但是 MongoDB 相对于 Redis 而言,MongoDB 更像是传统的数据库。早些年我们是先有了 Relation Database (关系型数据库),然后出现了很多很复杂的query ,里面用到了很多嵌套,很多 join 操作。所以在设计数据库的时候,我们也考虑到了如何应用他们的关系,使得写 query 可以 database 效率达到最高。后来人们发现,不是每个系统,都需要如此复杂的关系型数据库。有些简单的网站,比如博客,比如社交网站,完全可以斩断数据库之间的一切关系。这样做带来的好处是,设计数据库变得更加简单, query 也变得更加简单。然后,query 消耗的时间可能也会变少。因为 query 简单了,少了许多消耗资源的 join 操作,速度自然会上去。正如所说的, query 简单了,很有以前 mysql 可以找到的东西,现在关系没了,通过 Mongo 找不到了。我们只能将几组数据都抓到本地,然后在本地做 join ,所以在这点上可能会消耗很多资源。这里我们可以发现。如何选择数据库,完全取决于你所需要处理的数据的模型,即 Data Model 。如果它们之间,关系错综复杂,千丝万缕,这个时候 MySQL 一定是首选。如果他们的关系并不是那么密切,那么, NoSQL 将会是利器。
MongoDB 和 Redis 一样均为 key-value 存储系统,它具有以下特点:
面向集合存储,易存储对象类型的数据。
模式自由。
支持动态查询。
支持完全索引,包含内部对象。
支持查询。
支持复制和故障恢复。
使用高效的二进制数据存储,包括大型对象(如视频等)。
自动处理碎片,以支持云计算层次的扩展性
支持
Python,php,Ruby,Java,C,C#,javascript,Perl及C++语言的驱动程序,社区中也提供了对Erlang及.NET等平台的驱动程序。文件存储格式为
BSON(一种JSON的扩展)。可通过网络访问。
2、MongoDB 与 MySQL 性能比较
像 MySQL 一样, MongoDB 提供了丰富的远远超出了简单的键值存储中提供的功能和功能。 MongoDB 具有查询语言,功能强大的辅助索引(包括文本搜索和地理空间),数据分析功能强大的聚合框架等。相比使用关系数据库而言,使用MongoDB ,您还可以使用如下表所示的这些功能,跨越更多样化的数据类型和数据规模。
MySQLMongoDB丰富的数据模型否是动态 Schema否是数据类型是是数据本地化否是字段更新是是易于编程否是复杂事务是否审计是是自动分片否是
MySQL 中的许多概念在 MongoDB 中具有相近的类比。本表概述了每个系统中的一些常见概念。
MySQLMongoDB表集合行文档列字段joins嵌入文档或者链接
3、应用范围和限制
MongoDB 的主要目标是在 key-value (键/值)存储方式(提供了高性能和高度伸缩性)以及传统的 RDBMS 系统(丰富的功能)架起一座桥梁,集两者的优势于一身。 MongoDB 适用范围如下:
网站数据:
Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。**缓存:**由于性能很高,
Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载。**大尺寸,低价值的数据:**使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
高伸缩性的场景:
Mongo非常适合由数十或数百台服务器组成的数据库。Mongo的路线图中已经包含对MapReduce引擎的内置支持。用于对象及 JSON 数据的存储:
Mongo的BSON数据格式非常适合文档化格式的存储及查询。
MongoDB 当然也会有以下场景的限制:
高度事物性的系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
传统的商业智能应用:针对特定问题的
BI数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。需要
SQL的问题。
(二)为什么需要MongoDB
-
MongoDB与MySQL的区别
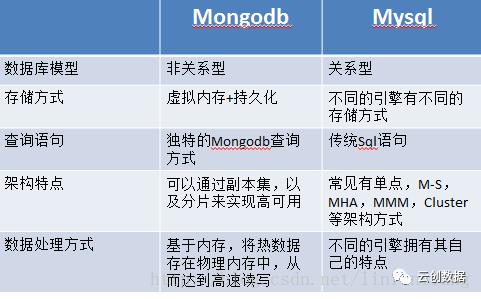


总体上讲:
由于MongoDB独特的数据处理方式,可以将热点数据加载到内存,故而对查询来讲,会非常快(当然也会非常消耗内存);同时由于采用了BSON的方式存储数据,故而对JSON格式数据具有非常好的支持性以及友好的表结构修改性,文档式的存储方式,数据友好可见;数据库的分片集群负载具有非常好的扩展性以及非常不错的自动故障转移(大赞)。
不足:数据库的查询采用了特有的查询方式,有一定的学习成本(不高);索引不咋滴;锁只能提供到collection级别,还做不到行级锁;没有事务机制(不能回滚啊);学习资料肯定没有MySQL的多。
MongoDB与Hadoop的区别
MongoDB侧重于对数据进行操作的应用系统,而Hadoop则侧重于对数据进行分析统计的应用。
MongoDB能够满足对数据库读写性能具有极高要求的应用场景(很消耗memory的),一般这些应用的响应延迟会要求控制在10ms以下,甚至更低。而Hadoop由于每一次的读写操作会包含大量数据(Hadoop更适合少次操作大批量数据的场景),通过聚集分析处理大量数据,这种分析一般都会走MapReduce,会造成很高的延迟(数分钟到数小时不等)不适合MongoDB的场景
如果业务中存在大量复杂的事务逻辑操作,则不要用MongoDB数据库
MongoDB能为我解决哪些问题
一般来讲,我会将MySQL中的部分表迁移到MongoDB中,主要是涉及到车辆历史轨迹以及温湿度数据等机器采集到的数据,而订单数据、客户数据等信息,仍然放到MySQL数据库中,主要是因为这两类数据实时采集,实时更新,会随着时间的推移,项目的扩大(PAAS服务),造成非常巨大的数据量,而一般MySQL在单表数据量超过500万后,性能就会下降的比较快,虽然可以通过分表的方式进行处理,但是随着时间的增长,仍然会给我带来比较大的麻烦(如查询等),这样,就不如将其放到MongoDB中存储,查询什么的都会比较方便,不过需要注意根据片键分片哦。
-
(三)Mongodb存储特性与内部原理
一、存储引擎(Storage)
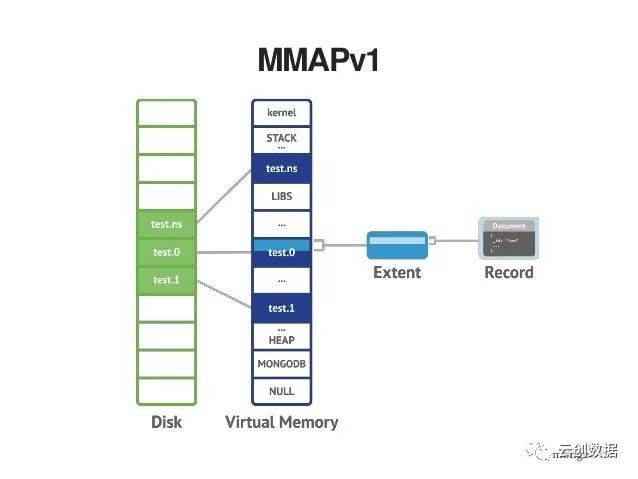
mongodb 3.0默认存储引擎为MMAPV1,还有一个新引擎wiredTiger可选,或许可以提高一定的性能。
mongodb中有多个databases,每个database可以创建多个collections,collection是底层数据分区(partition)的单位,每个collection都有多个底层的数据文件组成。(参见下文data files存储原理)
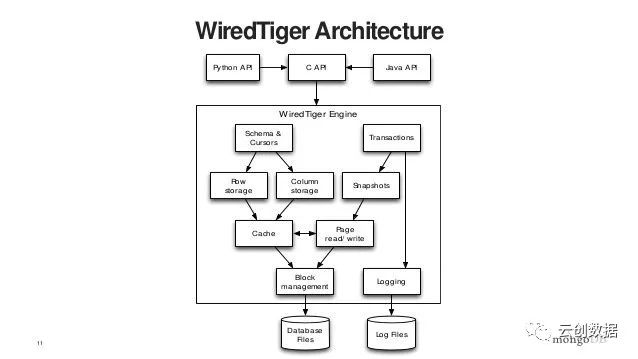
wiredTiger引擎:3.0新增引擎,官方宣称在read、insert和复杂的update下具有更高的性能。所以后续版本,我们建议使用wiredTiger。所有的write请求都基于“文档级别”的lock,因此多个客户端可以同时更新一个colleciton中的不同文档,这种更细颗粒度的lock,可以支撑更高的读写负载和并发量。因为对于production环境,更多的CPU可以有效提升wireTiger的性能,因为它是的IO是多线程的。
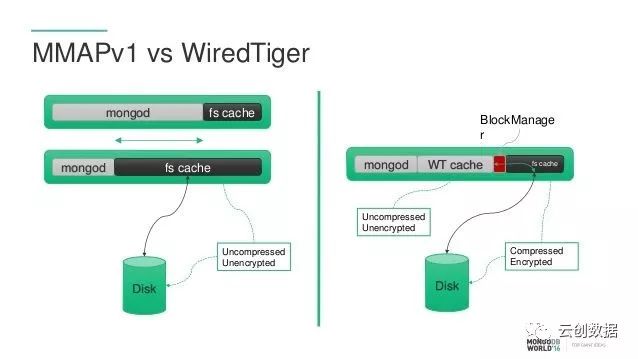
wiredTiger不像MMAPV1引擎那样尽可能的耗尽内存,它可以通过在配置文件中指定“cacheSizeGB”参数设定引擎使用的内存量,此内存用于缓存工作集数据(索引、namespace,未提交的write,query缓冲等)。

journal就是一个预写事务日志,来确保数据的持久性,wiredTiger每隔60秒(默认)或者待写入的数据达到2G时,mongodb将对journal文件提交一个checkpoint(检测点,将内存中的数据变更flush到磁盘中的数据文件中,并做一个标记点,表示此前的数据表示已经持久存储在了数据文件中,此后的数据变更存在于内存和journal日志)。对于write操作,首先被持久写入journal,然后在内存中保存变更数据,条件满足后提交一个新的检测点,即检测点之前的数据只是在journal中持久存储,但并没有在mongodb的数据文件中持久化,延迟持久化可以提升磁盘效率,如果在提交checkpoint之前,mongodb异常退出,此后再次启动可以根据journal日志恢复数据。journal日志默认每个100毫秒同步磁盘一次,每100M数据生成一个新的journal文件,journal默认使用了snappy压缩,检测点创建后,此前的journal日志即可清除。mongod可以禁用journal,这在一定程度上可以降低它带来的开支;对于单点mongod,关闭journal可能会在异常关闭时丢失checkpoint之间的数据(那些尚未提交到磁盘数据文件的数据);对于replica set架构,持久性的保证稍高,但仍然不能保证绝对的安全(比如replica set中所有节点几乎同时退出时)。
MMAPv1引擎:mongodb原生的存储引擎,比较简单,直接使用系统级的内存映射文件机制(memory mapped files),一直是mongodb的默认存储引擎,对于insert、read和in-place update(update不导致文档的size变大)性能较高;不过MMAPV1在lock的并发级别上,支持到collection级别,所以对于同一个collection同时只能有一个write操作执行,这一点相对于wiredTiger而言,在write并发性上就稍弱一些。对于production环境而言,较大的内存可以使此引擎更加高效,有效减少“page fault”频率,但是因为其并发级别的限制,多核CPU并不能使其受益。此引擎将不会使用到swap空间,但是对于wiredTiger而言需要一定的swap空间。(核心:对于大文件MAP操作,比较忌讳的就是在文件的中间修改数据,而且导致文件长度增长,这会涉及到索引引用的大面积调整)
为了确保数据的安全性,mongodb将所有的变更操作写入journal并间歇性的持久到磁盘上,对于实际数据文件将延迟写入,和wiredTiger一样journal也是用于数据恢复。所有的记录在磁盘上连续存储,当一个document尺寸变大时,mongodb需要重新分配一个新的记录(旧的record标记删除,新的记record在文件尾部重新分配空间),这意味着mongodb同时还需要更新此文档的索引(指向新的record的offset),与in-place update相比,将消耗更多的时间和存储开支。由此可见,如果你的mongodb的使用场景中有大量的这种update,那么或许MMAPv1引擎并不太适合,同时也反映出如果document没有索引,是无法保证document在read中的顺序(即自然顺序)。3.0之后,mongodb默认采用“Power of 2 Sized Allocations”,所以每个document对应的record将有实际数据和一些padding组成,这padding可以允许document的尺寸在update时适度的增长,以最小化重新分配record的可能性。此外重新分配空间,也会导致磁盘碎片(旧的record空间)。
Power of 2 Sized Allocations:默认情况下,MMAPv1中空间分配使用此策略,每个document的size是2的次幂,比如32、64、128、256...2MB,如果文档尺寸大于2MB,则空间为2MB的倍数(2M,4M,6M等)。这种策略有2种优势,首先那些删除或者update变大而产生的磁盘碎片空间(尺寸变大,意味着开辟新空间存储此document,旧的空间被mark为deleted)可以被其他insert重用,再者padding可以允许文档尺寸有限度的增长,而无需每次update变大都重新分配空间。此外,mongodb还提供了一个可选的“No padding Allocation”策略(即按照实际数据尺寸分配空间),如果你确信数据绝大多数情况下都是insert、in-place update,极少的delete,此策略将可以有效的节约磁盘空间,看起来数据更加紧凑,磁盘利用率也更高。
备注:mongodb 3.2+之后,默认的存储引擎为“wiredTiger”,大量优化了存储性能,建议升级到3.2+版本。

二、Capped Collections
一种特殊的collection,其尺寸大小是固定值,类似于一个可循环使用的buffer,如果空间被填满之后,新的插入将会覆盖最旧的文档,我们通常不会对Capped进行删除或者update操作,所以这种类型的collection能够支撑较高的write和read,通常情况下我们不需要对这种collection构建索引,因为insert是append(insert的数据保存是严格有序的)、read是iterator方式,几乎没有随机读;在replica set模式下,其oplog就是使用这种colleciton实现的。Capped Collection的设计目的就是用来保存“最近的”一定尺寸的document。

Capped Collection在语义上,类似于“FIFO”队列,而且是有界队列。适用于数据缓存,消息类型的存储。

Capped支持update,但是我们通常不建议,如果更新导致document的尺寸变大,操作将会失败,只能使用in-place update,而且还需要建立合适的索引。在capped中使用remove操作是允许的。autoIndex属性表示默认对_id字段建立索引,我们推荐这么做。在上文中我们提到了Tailable Cursor,就是为Capped而设计的,效果类似于“tail -f ”。
三、数据模型(Data Model)
上文已经描述过,mongodb是一个模式自由的NOSQL,不像其他RDBMS一样需要预先定义Schema而且所有的数据都“整齐划一”,mongodb的document是BSON格式,松散的,原则上说任何一个Colleciton都可以保存任意结构的document,甚至它们的格式千差万别,不过从应用角度考虑,包括业务数据分类和查询优化机制等,我们仍然建议每个colleciton中的document数据结构应该比较接近。
对于有些update,比如对array新增元素等,会导致document尺寸的增加,无论任何存储系统包括MYSQL、Hbase等,对于这种情况都需要额外的考虑,这归结于磁盘空间的分配是连续的(连续意味着读取性能将更高,存储文件空间通常是预分配固定尺寸,我们需要尽可能的利用磁盘IO的这种优势)。对于MMAPV1引擎,如果文档尺寸超过了原分配的空间(上文提到Power of 2 Allocate),mongodb将会重新分配新的空间来保存整个文档(旧文档空间回收,可以被后续的insert重用)。
document模型的设计与存储,需要兼顾应用的实际需要,否则可能会影响性能。mongodb支持内嵌document,即document中一个字段的值也是一个document,可以形成类似于RDBMS中的“one-to-one”、“one-to-many”,只需要对reference作为一个内嵌文档保存即可。这种情况就需要考虑mongodb存储引擎的机制了,如果你的内嵌文档(即reference文档)尺寸是动态的,比如一个user可以有多个card,因为card数量无法预估,这就会导致document的尺寸可能不断增加以至于超过“Power of 2 Allocate”,从而触发空间重新分配,带来性能开销,这种情况下,我们需要将内嵌文档单独保存到一个额外的collection中,作为一个或者多个document存储,比如把card列表保存在card collection中。“one-to-one”的情况也需要个别考虑,如果reference文档尺寸较小,可以内嵌,如果尺寸较大,建议单独存储。此外内嵌文档还有个优点就是write的原子性,如果使用reference的话,就无法保证了。
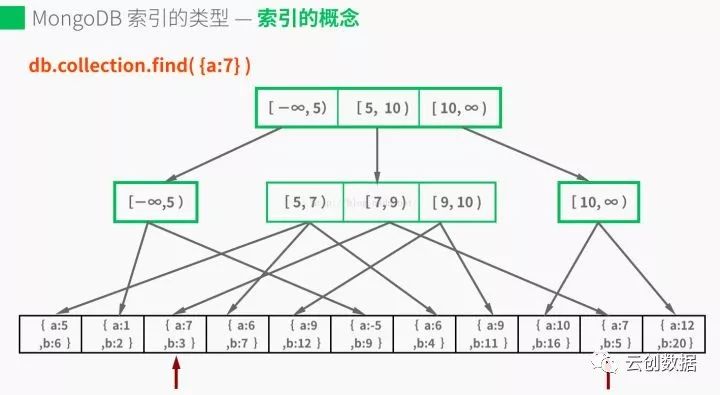
索引:提高查询性能,默认情况下_id字段会被创建唯一索引;因为索引不仅需要占用大量内存而且也会占用磁盘,所以我们需要建立有限个索引,而且最好不要建立重复索引;每个索引需要8KB的空间,同时update、insert操作会导致索引的调整,会稍微影响write的性能,索引只能使read操作收益,所以读写比高的应用可以考虑建立索引。
大集合拆分:比如一个用于存储log的collection,log分为有两种“dev”、“debug”,结果大致为{"log":"dev","content":"...."},{"log":"debug","content":"....."}。这两种日志的document个数比较接近,对于查询时,即使给log字段建立索引,这个索引也不是高效的,所以可以考虑将它们分别放在2个Collection中,比如:log_dev和log_debug。
数据生命周期管理:mongodb提供了expire机制,即可以指定文档保存的时长,过期后自动删除,即TTL特性,这个特性在很多场合将是非常有用的,比如“验证码保留15分钟有效期”、“消息保存7天”等等,mongodb会启动一个后台线程来删除那些过期的document。需要对一个日期字段创建“TTL索引”,比如插入一个文档:{"check_code":"101010",$currentDate:{"created":true}}},其中created字段默认值为系统时间Date;然后我们对created字段建立TTL索引。
我们向collection中insert文档时,created的时间为系统当前时间,其中在creatd字段上建立了“TTL”索引,索引TTL为15分钟,mongodb后台线程将会扫描并检测每条document的(created时间 + 15分钟)与当前时间比较,如果发现过期,则删除索引条目(连带删除document)。
某些情况下,我们可能需要实现“在某个指定的时刻过期”,我们只需要将上述文档和索引变通改造即可,即created指定为“目标时间”,expiredAfter指定为0。
四、架构模式
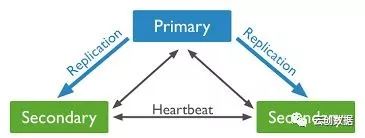
Replica set:复制集,mongodb的架构方式之一 ,通常是三个对等的节点构成一个“复制集”集群,有“primary”和secondary等多种角色(稍后详细介绍),其中primary负责读写请求,secondary可以负责读请求,这由配置决定,其中secondary紧跟primary并应用write操作;如果primay失效,则集群进行“多数派”选举,选举出新的primary,即failover机制,即HA架构。复制集解决了单点故障问题,也是mongodb垂直扩展的最小部署单位,当然sharding cluster中每个shard节点也可以使用Replica set提高数据可用性。
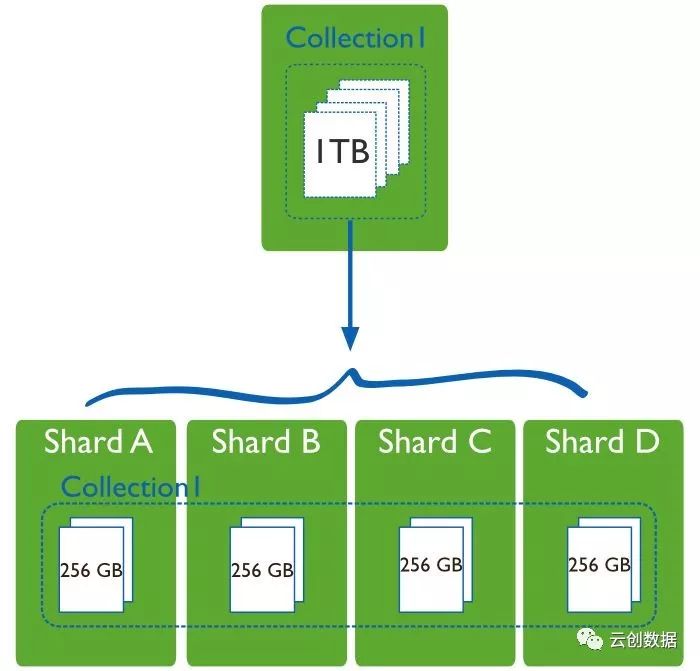
Sharding cluster:分片集群,数据水平扩展的手段之一;replica set这种架构的缺点就是“集群数据容量”受限于单个节点的磁盘大小,如果数据量不断增加,对它进行扩容将是非常苦难的事情,所以我们需要采用Sharding模式来解决这个问题。将整个collection的数据将根据sharding key被sharding到多个mongod节点上,即每个节点持有collection的一部分数据,这个集群持有全部数据,原则上sharding可以支撑数TB的数据。
系统配置:
建议mongodb部署在linux系统上,较高版本,选择合适的底层文件系统(ext4),开启合适的swap空间
无论是MMAPV1或者wiredTiger引擎,较大的内存总能带来直接收益。
对数据存储文件关闭“atime”(文件每次access都会更改这个时间值,表示文件最近被访问的时间),可以提升文件访问效率。
ulimit参数调整,这个在基于网络IO或者磁盘IO操作的应用中,通常都会调整,上调系统允许打开的文件个数(ulimit -n 65535)。
五、数据文件存储原理(Data Files storage,MMAPV1引擎)
1、Data Files
mongodb的数据将会保存在底层文件系统中,比如我们dbpath设定为“/data/db”目录,我们创建一个database为“test”,collection为“sample”,然后在此collection中插入数条documents。我们查看dbpath下生成的文件列表:
ls -lh
-rw------- 1 mongo mongo 16M 11 6 17:24 test.0
-rw------- 1 mongo mongo 32M 11 6 17:24 test.1
-rw------- 1 mongo mongo 64M 11 6 17:24 test.2
-rw------- 1 mongo mongo 128M 11 6 17:24 test.3
-rw------- 1 mongo mongo 256M 11 6 17:24 test.4
-rw------- 1 mongo mongo 512M 11 6 17:24 test.5
-rw------- 1 mongo mongo 512M 11 6 17:24 test.6
-rw------- 1 mongo mongo 16M 11 6 17:24 test.ns可以看到test这个数据库目前已经有6个数据文件(data files),每个文件以“database”的名字 + 序列数字组成,序列号从0开始,逐个递增,数据文件从16M开始,每次扩张一倍(16M、32M、64M、128M...),在默认情况下单个data file的最大尺寸为2G,如果设置了smallFiles属性(配置文件中)则最大限定为512M;mongodb中每个database最多支持16000个数据文件,即约32T,如果设置了smallFiles则单个database的最大数据量为8T。如果你的database中的数据文件很多,可以使用directoryPerDB配置项将每个db的数据文件放置在各自的目录中。当最后一个data file有数据写入后,mongodb将会立即预分配下一个data file,可以通过“--nopreallocate”启动命令参数来关闭此选项。
一个database中所有的collections以及索引信息会分散存储在多个数据文件中,即mongodb并没有像SQL数据库那样,每个表的数据、索引分别存储;数据分块的单位为extent(范围,区域),即一个data file中有多个extents组成,extent中可以保存collection数据或者indexes
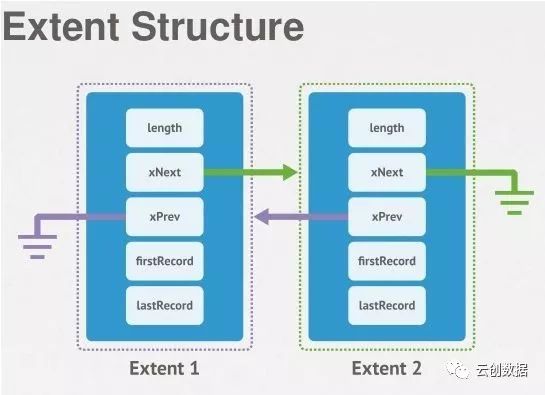
数据,一个extent只能保存同一个collection数据不同的collections数据分布在不同的extents中,indexes数据也保存在各自的extents中;最终,一个collection有一个或者多个extents构成,最小size为8K,最大可以为2G,依次增大;它们分散在多个data files中。对于一个data file而言,可能包含多个collection的数据,即由多个不同collections的extents、index extents混合构成。每个extent包含多条documents(或者index entries),每个extent的大小可能不相等,但一个extent不会跨越2个data files。

有人肯定疑问:一个collection中有哪些extents,这种信息mongodb存在哪里?在每个database的namespace文件中,比如test.ns文件中,每个collection只保存了第一个extent的位置信息,并不保存所有的extents列表,但每个extent都维护者一个链表关系,即每个extent都在其header信息中记录了此extent的上一个、下一个extent的位置信息,这样当对此collection进行scan操作时(比如全表扫描),可以提供很大的便利性。
我们可以通过db.stats()指令查看当前database中extents的信息:
> use test
switched to db test
> db.stats();
{
"db" : "test",
"collections" : 3, ##collection的个数
"objects" : 1000006, ##documents总条数
"avgObjSize" : 495.9974400153599, ##record的平均大小,单位byte
"dataSize" : 496000416, ##document所占空间的总量
"storageSize" : 629649408, ##
"numExtents" : 18, ##extents个数
"indexes" : 2,
"indexSize" : 108282944,
"fileSize" : 1006632960,
"nsSizeMB" : 16, ##namespace文件大小
"extentFreeList" : { ##尚未使用(已分配尚未使用、已删除但尚未被重用)的extent列表
"num" : 0,
"totalSize" : 0
},
"dataFileVersion" : {
"major" : 4,
"minor" : 22
},
"ok" : 1
列表信息中有几个字段简单介绍一下:
dataSize:documents所占的空间总量,mongodb将会为每个document分配一定空间用于保存数据,每个document所占空间包括“文档实际大小” + “padding”,对于MMAPV1引擎,mongodb默认采用了“Power of 2 Sized Allocations”策略,这也意味着通常会有padding,不过如果你的document不会被update(或者update为in-place方式,不会导致文档尺寸变大),可以在在createCollection是指定noPadding属性为true,这样dataSize的大小就是documents实际大小;当documents被删除后,将导致dataSize减小;不过如果在原有document的空间内(包括其padding空间)update(或者replace),则不会导致dataSize的变大,因为mongodb并没有分配任何新的document空间。
storageSize:所有collection的documents占用总空间,包括那些已经删除的documents所占的空间,为存储documents的extents所占空间总和。文档的删除或者收缩不会导致storageSize变小。
indexSize:所用collection的索引数据的大小,为存储indexes的extents所占空间的总和。
fileSize:为底层所有data files的大小总和,但不包括namespace文件。为storageSize、indexSize、以及一些尚未使用的空间等等。当删除database、collections时会导致此值变小。
此外,如果你想查看一个collection中extents的分配情况,可以使用
db.<collection名称>.stats(),结构与上述类似;如果你希望更细致的了解collection中extents的全部信息,则可以使用db.<collection名称>.validate(),此方法接收一个boolean值,表示是否查看明细,这个指令会scan全部的data files,因此比较耗时:
> db.sample.validate(true);
{
"ns" : "test.sample",
"datasize" : 496000000,
"nrecords" : 1000000,
"lastExtentSize" : 168742912,
"firstExtent" : "0:5000 ns:test.sample",
"lastExtent" : "3:a05f000 ns:test.sample",
"extentCount" : 16,
"extents" : [
{
"loc" : "0:5000",
"xnext" : "0:49000",
"xprev" : "null",
"nsdiag" : "test.sample",
"size" : 8192,
"firstRecord" : "0:50b0",
"lastRecord" : "0:6cb0"
},
...
]
...
}可以看到extents在逻辑上是链表形式,以及每个extent的数据量、以及所在data file的offset位置。
从上文中我们已经得知,删除document会导致磁盘碎片,有些update也会导致磁盘碎片,比如update导致文档尺寸变大,进而超过原来分配的空间;当有新的insert操作时,mongodb会检测现有的extents中是否合适的碎片空间可以被重用,如果有,则重用这些fragment,否则分配新的存储空间。磁盘碎片,对write操作有一定的性能影响,而且会导致磁盘空间浪费;如果你需要删除某个collection中大部分数据,则可以考虑将有效数据先转存到新的collection,然后直接drop()原有的collection。或者使用db.runCommand({compact: '<collection>'})。
如果你的database已经运行一段时间,数据已经有很大的磁盘碎片(storageSize与dataSize比较),可以通过mongodump将指定database的所有数据导出,然后将原有的db删除,再通过mongorestore指令将数据重新导入。(同compact,这种操作需要停机维护)
mongod中还有2个默认的database,系统级的,“admin”和“local”;它们的存储原理同上,其中“admin”用于存储“用户授权信息”,比如每个database中用户的role、权限等;“local”即为本地数据库,我们常说的oplog(replication架构中使用,类似与binlog)即保存在此数据库中。
2、Namespace文件
对于namespace文件,比如“test.ns”文件,默认大小为16M,此文件中主要用于保存“collection”、index的命名信息,比如collection的“属性”信息、每个索引的属性类型等,如果你的database中需要存储大量的collection(比如每一小时生成一个collection,在数据分析应用中),那么我们可以通过配置文件“nsSize”选项来指定。
3、journal文件
journal日志为mongodb提供了数据保障能力,它本质上与mysql binlog没有太大区别,用于当mongodb异常crash后,重启时进行数据恢复;这归结于mongodb的数据持久写入磁盘是滞后的。默认情况下,“journal”特性是开启的,特别在production环境中,我们没有理由来关闭它。(除非,数据丢失对应用而言,是无关紧要的)
一个mongodb实例中所有的databases共享journal文件。
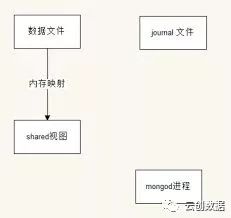
对于write操作而言,首先写入journal日志,然后将数据在内存中修改(mmap),此后后台线程间歇性的将内存中变更的数据flush到底层的data files中,时间间隔为60秒;write操作在journal文件中是有序的,为了提升性能,write将会首先写入journal日志的内存buffer中,当buffer数据达到100M或者每隔100毫秒,buffer中的数据将会flush到磁盘中的journal文件中;如果mongodb异常退出,将可能导致最多100M数据或者最近100ms内的数据丢失,flush磁盘的时间间隔由配置项“commitIntervalMs”决定,默认为100毫秒。mongodb之所以不能对每个write都将journal同步磁盘,这也是对性能的考虑,mysql的binlog也采用了类似的权衡方式。开启journal日志功能,将会导致write性能有所降低,可能降低5~30%,因为它直接加剧了磁盘的写入负载,我们可以将journal日志单独放置在其他磁盘驱动器中来提高写入并发能力(与data files分别使用不同的磁盘驱动器)。
如果你希望数据尽可能的不丢失,可以考虑:
减小commitIntervalMs的值
每个write指定“write concern”中指定“j”参数为true
最佳手段就是采用“replica set”架构模式,通过数据备份方式解决,同时还需要在“write concern”中指定“w”选项,且保障级别不低于“majority”。
参见mongodb复制集最终我们需要在“写入性能”和“数据一致性”两个方面权衡,即CAP理论。
根据write并发量,journal日志文件为1G,如果指定了smallFiles配置项,则最大为128M,和data files一样journal文件也采用了“preallocated”方式,journal日志保存在dbpath下“journal”子目录中,一般会有三个journal文件,每个journal文件格式类似于“j._<序列数字>”。并不是每次buffer flush都生成一个新的journal日志,而是当前journal文件即将满时会预创建一个新的文件,journal文件中保存了write操作的记录,每条记录中包含write操作内容之外,还包含一个“lsn”(last sequence number),表示此记录的ID;此外我们会发现在journal目录下,还有一个“lsn”文件,这个文件非常小,只保存了一个数字,当write变更的数据被flush到磁盘中的data files后,也意味着这些数据已经持久化了,那么它们在“异常恢复”时也不需要了,那么其对应的journal日志将可以删除,“lsn”文件中记录的就是write持久化的最后一个journal记录的ID,此ID之前的write操作已经被持久写入data files,此ID之前的journal在“异常恢复”时则不需要关注;如果某个journal文件中最大 ID小于“lsn”,则此journal可以被删除或者重用。
(四)本文很多内容转自于知乎网,感谢前辈们的无私分享。经了解关于和MongonDB兼容的备份软件并不是很多,哪位朋友相关的经验和知识,欢迎来交流切磋。
以上是关于茶话小馆之MongoDB篇的主要内容,如果未能解决你的问题,请参考以下文章