为什么我们选择了MongoDB?
Posted 51CTO技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么我们选择了MongoDB?相关的知识,希望对你有一定的参考价值。
我司是一家正处于高速发展,目前拥有数百万用户,年销售额近五十亿的社交电商公司。
为什么使用 MongoDB(选择数据的时候我们是怎么考虑的?)
MongoDB 架构(99.99% 高可用,晚上安心睡大觉!)
MongoDB 分片(海量数据应对之道!)
MongoDB 文档模型介绍(灵活!灵活!灵活!)
为什么使用 MongoDB
安全,稳定
高可用
高性能
数据规模
支持读写并发量
延迟与吞吐量
MongoDB 架构
MongoDB 自带多副本高可用,只需要合理的配置,就能避免单数据库节点故障导致服务的不可用。
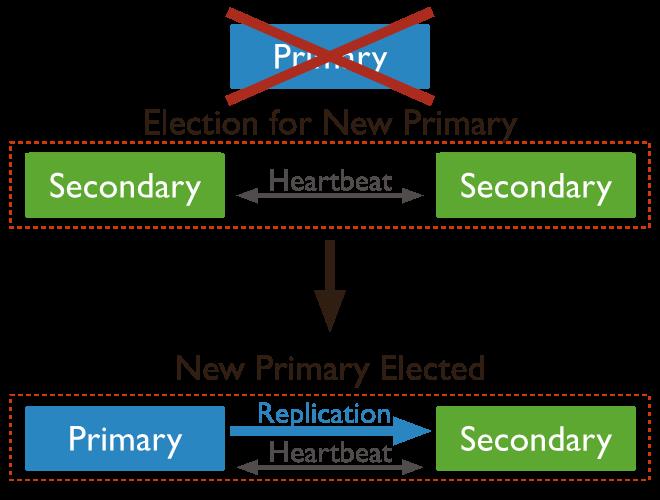
一个 Primary 主节点,主要接受来自 server 的读写。
两个 Secondary 从节点,用于同步来自 Primary 的数据。
raft 算法动画演示:
http://thesecretlivesofdata.com/raft/

上图是一个拥有 7 个可投票从节点,一个主节点,两个不可投票从节点。
{
"_id" : <num>,
"host" : <hostname:port>,
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 0, // 设置为0
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 0 // 设置为0
}
既然我们的数据库拥有至少超过三个节点(1Primary+2Secondary),Secondary 通过同步 Primary 的数据来保持一致性,那么当我们写操作的时候,如何保证数据安全的落盘呢?
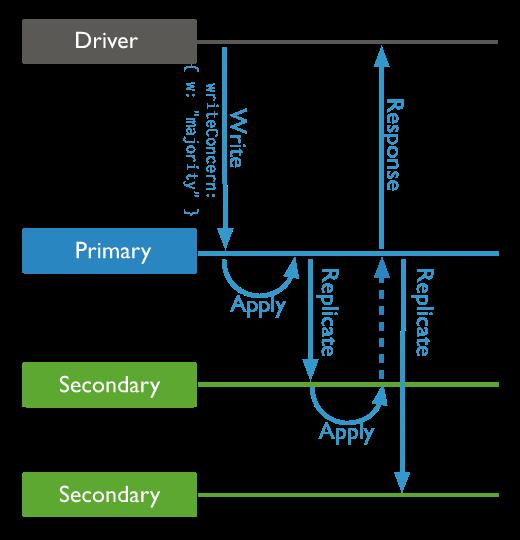
写 Primary 成功,返回客户端写成功,Secondary 还未同步 Primary 的时候,Primary 挂了,数据丢失!
写 Primary 成功,数据同步一个 Secondary 成功,返回客户端写成功。此时 Primary 挂了,数据不会丢失。但是恰好 Primary 与同步的 Secondary 同时挂了,数据丢失!
写 Primary 成功,数据同步两个 Secondary 成功,返回客户端写成功。此时 Primary 挂了,数据不会丢失。
第一种情况有风险会造成数据丢失。
第二种情况还是会出现数据丢失,但是数据丢失的概率大大降低。
第三种情况是最安全的做法,但是节点数目多了,同步非常耗时,用户需要等待的时间过长,一般不考虑。
MongoDB 在这里推荐折衷方案就是使用 Write Concern---在数据可靠性与效率之间的权衡!
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: "majority" , wtimeout: 5000 } } // 设置writeConcern为majority,超时时间为5000毫秒
)
MongoDB 分片
查询百万表和千万表甚至过亿的表效率相差很大,查询性能急剧恶化。
插入的时候创建索引可能会引起索引树的调整与页分裂。
例如将订单库分为在线库和离线库,近三个月是在线库,远期的订单数据放入离线库,这样在线库的数据就大大减少,数据库性能就得到了提升。
又例如当我们的用户量过多超过千万行记录,单表查询效率下降,我们将一张用户表拆成多张用户表,这个就是水平拆分。
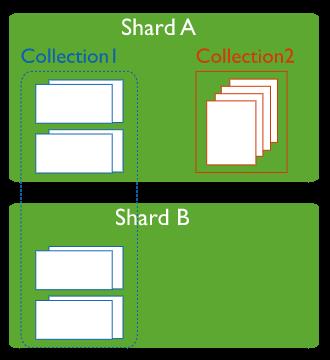
通过将同一个集合(Collection1)的数据按片键(shard keys)分到不同的分片(shard)上面,减少同一个数据文件上的数据量,已达到拆分数据规模的目的。
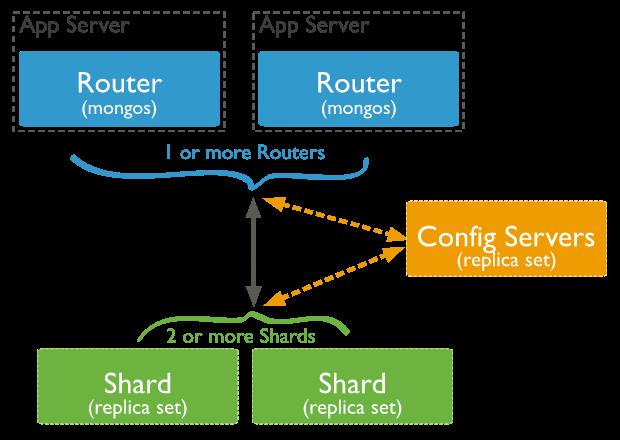
冷热数据,某个分片数据量过大。
数据总量大,分片集群的分片过大。
MongoDB 文档模型介绍
同一个集合中不同文档不一定需要有相同的字段,并且字段类型也可以不同。
在集合中改变文档的结构,例如增加一个字段,删除一个字段,或者改变一个字段的类型,只需要对该文档更新即可。
数据关系如下:
// patron document
{
_id: "joe",
name: "Joe Bookreader"
}
// address documents
{
patron_id: "joe", // reference to patron document
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
{
patron_id: "joe",
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
在 MongoDB 中我们可以这样进行设计:
{
"_id": "joe",
"name": "Joe Bookreader",
"addresses": [
{
"street": "123 Fake Street",
"city": "Faketon",
"state": "MA",
"zip": "12345"
},
{
"street": "1 Some Other Street",
"city": "Boston",
"state": "MA",
"zip": "12345"
}
]
}
总结
编辑:陶家龙
精彩文章推荐:
以上是关于为什么我们选择了MongoDB?的主要内容,如果未能解决你的问题,请参考以下文章
我们为什么放弃 MongoDB 和 MySQL,选择 TiDB