商城架构之mq和mongodb集群搭建
Posted 家园叮咚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了商城架构之mq和mongodb集群搭建相关的知识,希望对你有一定的参考价值。
1. rabbitmq高可用集群
在服务之间会采用mq进行消息通信,而rabbitmq本身也如同consul一样,如果只有一个节点那么就可能出现宕机的问题,并且基于mq的特点我们是可以在多个服 务之间使用同一个mq来相互通信,因此高可用的架构设计就必不可少
1.1. rabbitmq集群方案
1. 主备模式
一般在并发和数据量不高的情况下,这种模式非常的好用且简单。
也就是一个主/备方案,主节点提供读写,备用节点不提供读写。如果主节点挂了,就切换到备用节点,原来的备用节点升级为主节点提供读写服务,当原来的主 节点恢复运行后,原来的主节点就变成备用节点,和 activeMQ 利用 zookeeper 做主/备一样,也可以一主多备
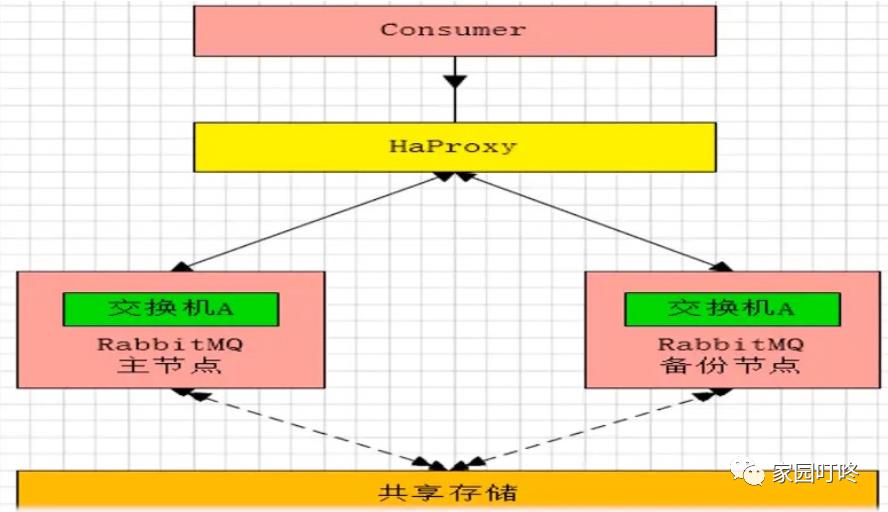
2. 远程模式
这是 rabbitMQ 比较早期的架构模型了,现在很少使用了
远程模式可以实现双活的一种模式,简称 shovel 模式,所谓的 shovel 就是把消息进行不同数据中心的复制工作,可以跨地域的让两个 MQ 集群互联,远距离通信 和复制
Shovel 就是我们可以把消息进行数据中心的复制工作,我们可以跨地域的让两个 MQ 集群互联。
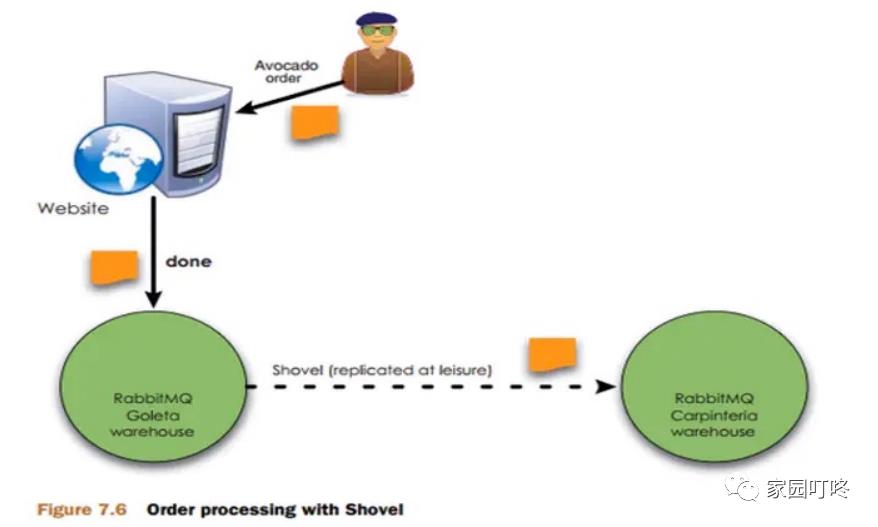
如图所示,有两个异地的 MQ 集群(可以是更多的集群),当用户在地区 1 这里下单了,系统发消息到 1 区的 MQ 服务器,发现 MQ 服务已超过设定的阈值,负 载过高,这条消息就会被转到 地区 2 的 MQ 服务器上,由 2 区的去执行后面的业务逻辑,相当于分摊我们的服务压力
在使用了 shovel 插件后,模型变成了近端同步确认,远端异步确认的方式,大大提高了订单确认速度,并且还能保证可靠性
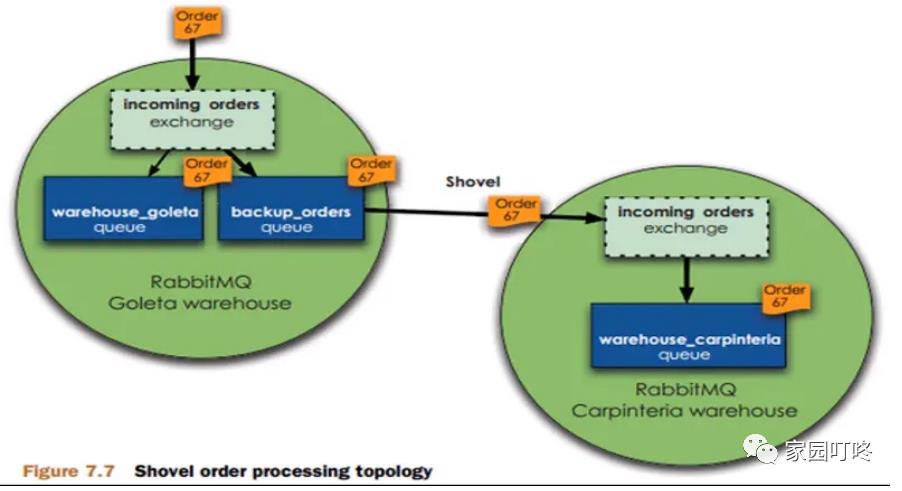
如上图所示,当我们的消息到达 exchange,它会判断当前的负载情况以及设定的阈值,如果负载不高就把消息放到我们正常的 warehouse_goleta 队列中,如果负 载过高了,就会放到 backup_orders 队列中。backup_orders 队列通过 shovel 插件与另外的 MQ 集群进行同步数据,把消息发到第二个 MQ 集群上。
3. 远程模式
非常经典的 mirror 镜像模式,保证 100% 数据不丢失。在实际工作中也是用得最多的,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群模式。
mirror 镜像队列,目的是为了保证 rabbitMQ 数据的高可靠性解决方案,主要就是实现数据的同步,一般来讲是 2 - 3 个节点实现数据同步。对于 100% 数据可靠性 解决方案,一般是采用 3 个节点。
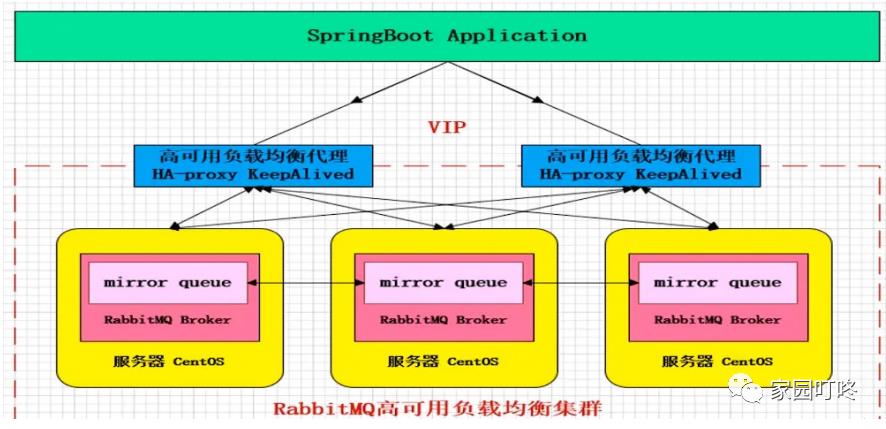
如上图所示,用 KeepAlived 做了 HA-Proxy 的高可用,然后有 3 个节点的 MQ 服务,消息发送到主节点上,主节点通过 mirror 队列把数据同步到其他的 MQ 节 点,这样来实现其高可靠。
4. 多活模式
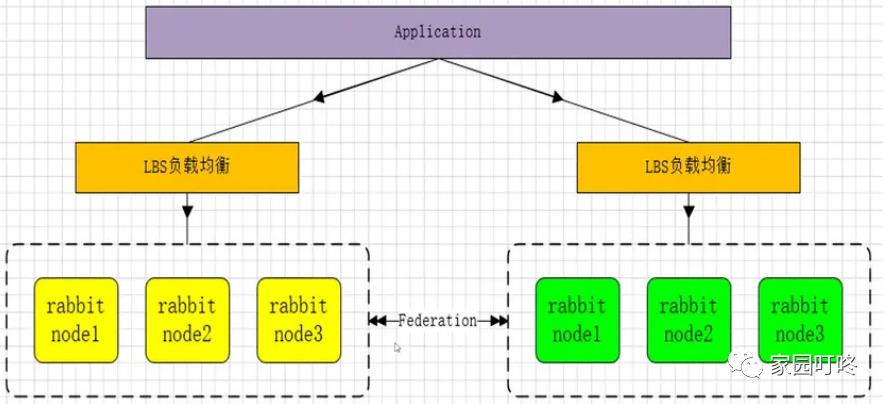
也是实现异地数据复制的主流模式,因为 shovel 模式配置比较复杂,所以一般来说,实现异地集群的都是采用这种双活 或者 多活模型来实现的。这种模式需要依 赖 rabbitMQ 的 federation 插件,可以实现持续的,可靠的 AMQP 数据通信,多活模式在实际配置与应用非常的简单。
rabbitMQ 部署架构采用双中心模式(多中心),那么在两套(或多套)数据中心各部署一套 rabbitMQ集群,各中心的rabbitMQ 服务除了需要为业务提供正常的消息服 务外,中心之间还需要实现部分队列消息共享。
多活集群架构如下:
拉取镜像
docker pull rabbitmq:3.7-management
备注 alpine系统存在问题
12. 构建rabbitmq镜像集群
参考资料
https://blog.51cto.com/11134648/2155934
https://www.jianshu.com/p/5b2879fba25b
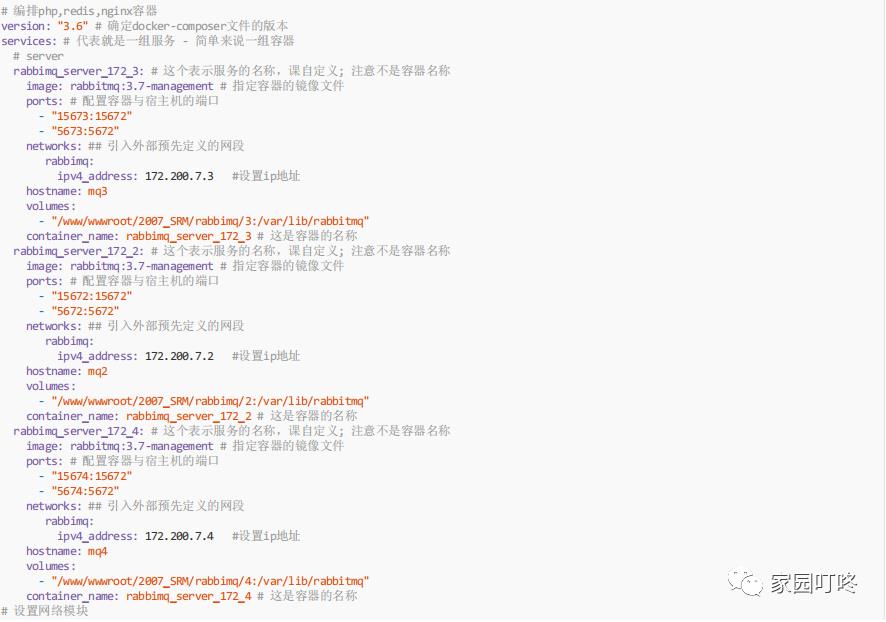
Rabbitmq的集群是依附于erlang的集群来工作的,所以必须先构建起erlang的集群景象。Erlang的集群中各节点是经由过程一个magic cookie来实现的,这个cookie存 放在/var/lib/rabbitmq/.erlang.cookie中,文件是400的权限。所以必须保证各节点cookie一致,不然节点之间就无法通信。
首先我们可以如下的方式构建
注意统一配置共享目录下的 .erlang.cookie 参数值如下
XXGQZIOGOIUETCEJIODM
这个参数值,并非固定值,而是基于erlang的cookie规则而编辑的,因此你也可以改为其他,最为重要的就是cookie一致
如下是docker-compose
然后再构建容器 docker-compose up -d
docker exec -it rabbimq_server_172_2 bash
docker exec -it rabbimq_server_172_4 bash
一起修改里面的hosts与hostname
hosts

hostname
mq2
mq3
mq4
因为容器关系,不能进行vi,所以只能上传cp修改

下一步配置rabbitmq在2,4节点中统一执行如下命令
root@mq2:/# rabbitmqctl stop_app
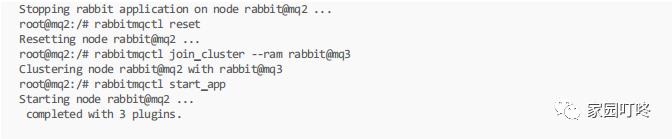
最后测试
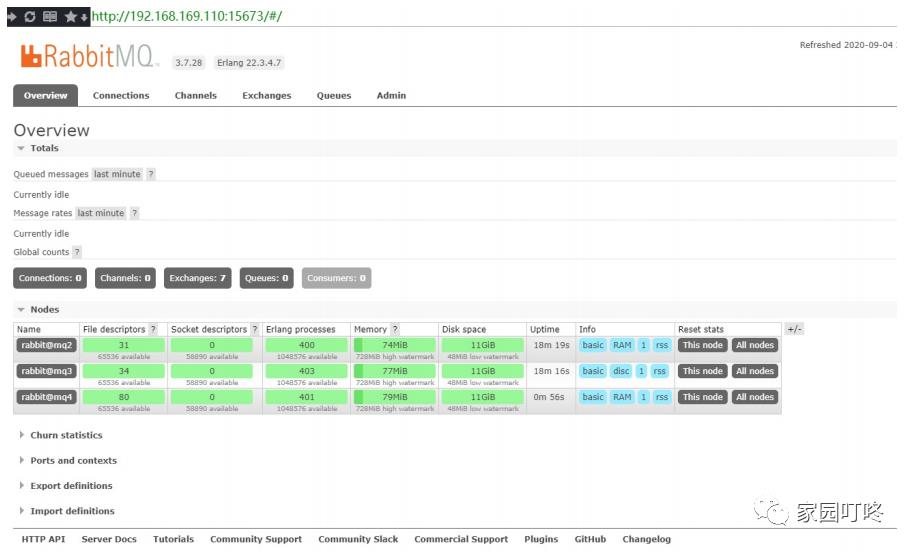
可以看到三个节点均正常运行
最后设置匹配的队列为高可用
注意:rabbitmq如果做高可用可能会性能降低,所以提供这样的功能来区分可以让一些对来不走高可用模式
1.3. 理解rabbitmq镜像集群通信过程
镜像集群模式特点
生产者向任一服务节点注册队列,该队列相关信息会同步到其他节点上
任一消费者向任一节点请求消费,可以直接获取到消费的消息,因为每个节点上都有相同的实际数据
任一节点宕机,不影响消息在其他节点上进行消费
1.4. haproxy实现rabbitmq负载均衡
1.4.1. haproxy介绍
1. HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在时下的硬件上,完全可以支持数以万计的 并发连 接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上
2. HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制 、系统调度器限制以及无处不在的锁限 制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户端(User-Space) 实现所有这些任务,所以没有这些问题。此模型的弊端 是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以 使每个CPU时间片(Cycle)做更多的工作。
3. HAProxy 支持连接拒绝 : 因为维护一个连接的打开的开销是很低的,有时我们很需要限制蠕蠕虫虫((attack bots)),,也也就就是是说说限限制制它它们们的的连连接接打打开开从从而而限限制制 它它们们的的危危害害。。这这个个已已经经为为一一个个陷陷于于小小型型DDoS的网站开发了而且已经拯救了很多站点,这个优点也是其它负载均衡器没有的。
3.4.2. haproxy与nginx对比
nginx
1. 工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构;
2. Nginx对网络的依赖比较小;
3. Nginx安装和配置比较简单,测试起来比较方便;
4. 也可以承担高的负载压力且稳定,一般能支撑超过1万次的并发;
5. Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点,不过其 中缺点就是不支持url来检测;
6. Nginx对请求的异步处理可以帮助节点服务器减轻负载;
8. 不支持Session的保持、对Big request header的支持不是很好,另外默认的只有Round-robin和IP-hash两种负载均衡算法。
haproxy
1. HAProxy是工作在网络7层之上。
2. 能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作
3. 支持url检测后端的服务器出问题的检测会有很好的帮助。
5. 单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度。
6. HAProxy可以对mysql进行负载均衡,对后端的DB节点进行检测和负载均衡。
以上是关于商城架构之mq和mongodb集群搭建的主要内容,如果未能解决你的问题,请参考以下文章