万亿级数据库MongoDB集群性能数十倍提升及机房多活容灾实践
Posted 架构师学习路线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万亿级数据库MongoDB集群性能数十倍提升及机房多活容灾实践相关的知识,希望对你有一定的参考价值。
分享目录
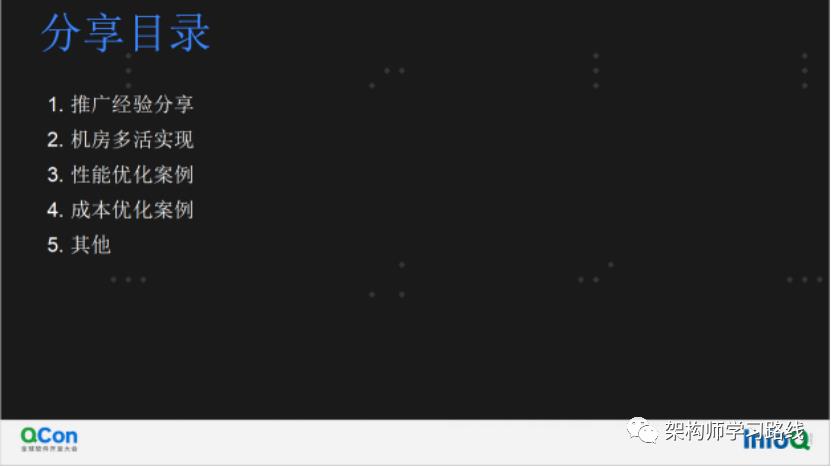
推广经验分享
机房多活实现
性能优化案例
成本优化案例
其他
分享主题一:如何把mongodb从淘汰边缘变为公司主流数据库?
背景:
入职前多个大数据量业务使用mongodb,使用中经常超时抖动
多个核心业务忍受不了抖动的痛苦,准备迁移回mysql。
mongodb口碑差,新业务想用不敢用。
入职1个月,业务迁移mongodb到公司其他数据库,mongodb总集群数减少15%

我做了啥?
从服务层优化、存储引擎优化、部署方式优化等方面入手,逐一解决抖业务抖动问题
总结各个集群抖动原因及优化方法,公司内部分享。
收集公司所有mongodb集群对应用户,成立mongodb用户群
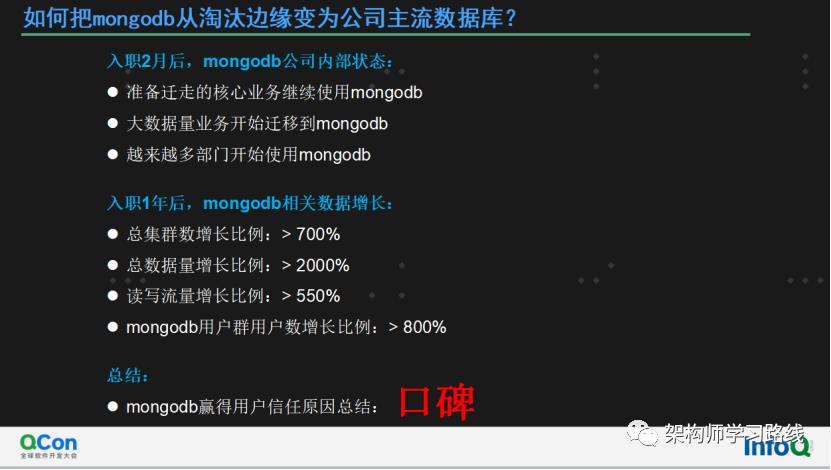
入职2月后,mongodb公司内部状态:
之前准备迁移到mysql的几个核心业务继续使用mongodb
对应业务负责人开始考虑把其他大数据量集群迁移到mongodb
越来越多的未使用过mongodb的部门开始使用mongodb
入职1年后,mongodb相关数据增长:
总集群数增长比例:> 700%
总数据量增长比例:> 2000%
读写流量增长比例:> 550%
mongodb用户群用户数增长比例:> 800%
总结:
mongodb赢得用户信任原因总结:口碑
分享主题二:当前国内对mongodb误解(丢数据、不安全、难维护)?
业务接入过程中经常咨询的几个问题:
误解一. 丢数据
误解二. 不安全,网上一堆说mongodb被黑客攻击,截图一堆新闻
误解三. DBA吐槽mongodb太难维护
误解原因:
mongodb本身很优秀,但是很多DBA和相应开发把控不住
国内系统性分析mongodb内核实现原理相关资料欠缺
网络社会以讹传讹,DBA或者相关开发自身把控不住演变为mongodb的锅
分享主题三:mongodb机房多活方案-实现成本、性能、一致性"三丰收"
传统社区mongodb双向同步方案(放弃该方案)
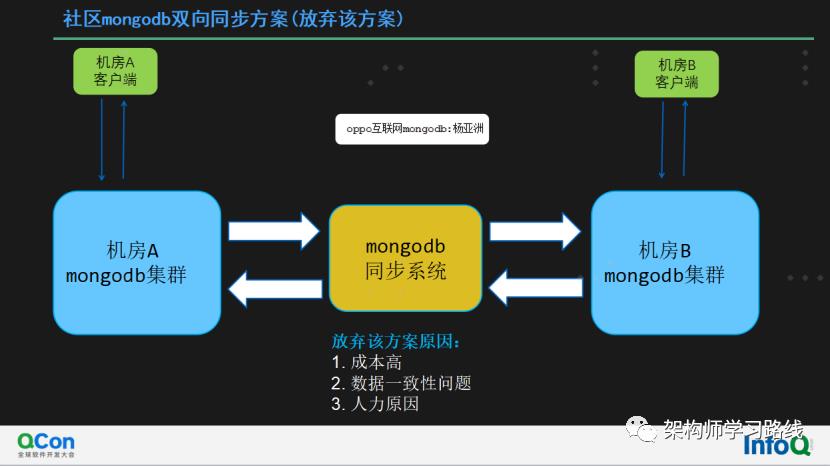
放弃该方案原因:
数据两份、集群两份、物理成本高。三机房、五机房等更多机房多活,成本及复杂性更高。
存在一致性问题,两地集群数据不一致,balance情况下尤为突出
由于人力原因,如果开源同步工具出现问题把控不在。
方案一:同城三机房多活方案(1mongod+1mongod+1mongod方式)
每个机房代理至少部署2个,保证业务访问代理高可用
如果某机房异常,并且该机房节点为主节点,借助mongodb天然的高可用机制,其他机房2个mongod实例会自动选举一个新节点为主节点。
客户端配置nearest就近访问,保证读走本机房节点。
弊端:如果是异地机房,B机房和C机房写存在跨机房写场景。如果A B C为同城机房,则没用该弊端,同城机房时延可以忽略。
方案二:同城两机房多活方案(2mongod+2mongod+1arbiter模式)
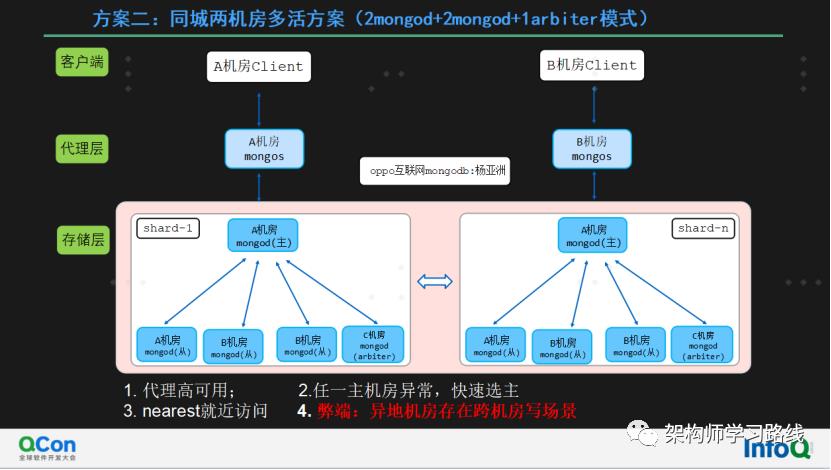
每个机房代理至少部署2个,保证业务访问代理高可用
如果机房A挂掉,则会在B机房mongod中重新选举一个新的主节点。arbiter选举节点不消耗资源
客户端配置nearest参数,保证读走本机房节点
弊端:如果是异地机房,B机房和C机房写存在跨机房写场景。如果A B 为同城机房,则没用该弊端,同城机房时延可以忽略。
方案三:异地三机房多活方案(1mongod+1mongod+1mongod方式)-解决跨机房写
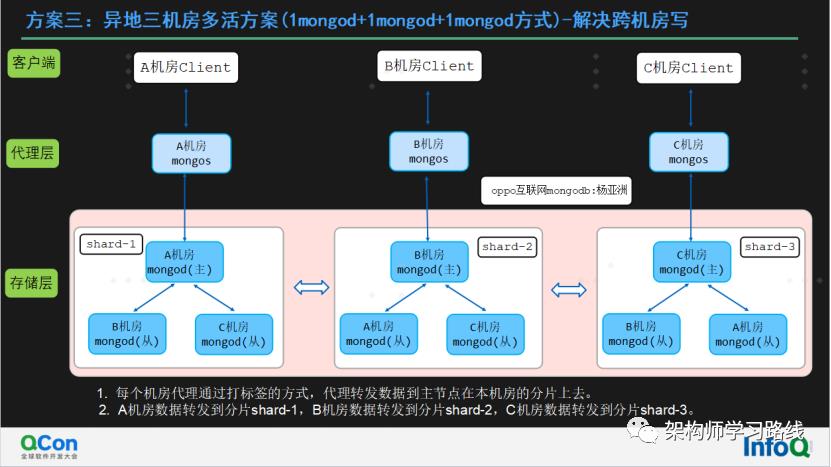
每个机房代理通过打标签的方式,代理转发数据到主节点在本机房的分片上去。
A机房数据通过标签识别转发到分片shard-1,B机房数据转发到分片shard-2,C机房数据转发到分片shard-3。
分享主题四:mongodb线程模型瓶颈及其优化方法
mongodb默认线程模型(一个链接一个线程)
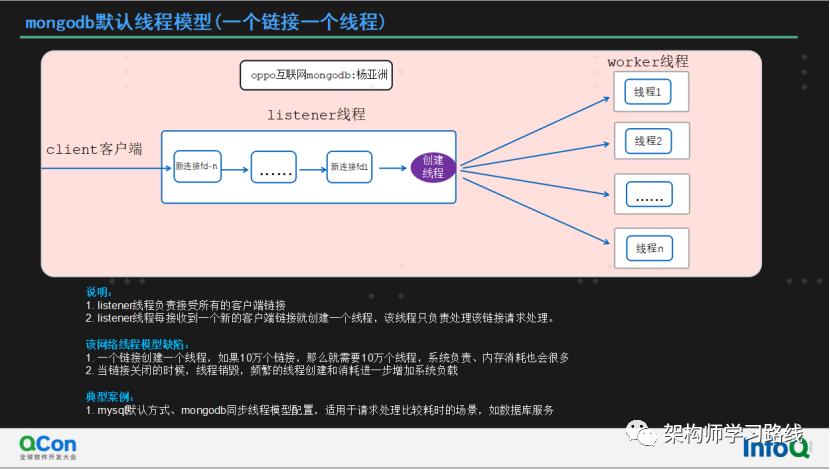
说明:
listener线程负责接受所有的客户端链接
listener线程每接收到一个新的客户端链接就创建一个线程,该线程只负责处理该链接请求处理。
该网络线程模型缺陷:
一个链接创建一个线程,如果10万个链接,那么就需要10万个线程,系统负责、内存消耗也会很多
当链接关闭的时候,线程销毁,频繁的线程创建和消耗进一步增加系统负载
典型案例:
mysql默认方式、mongodb同步线程模型配置,适用于请求处理比较耗时的场景,如数据库服务
mongodb默认线程模型(动态线程模型:单队列方式)
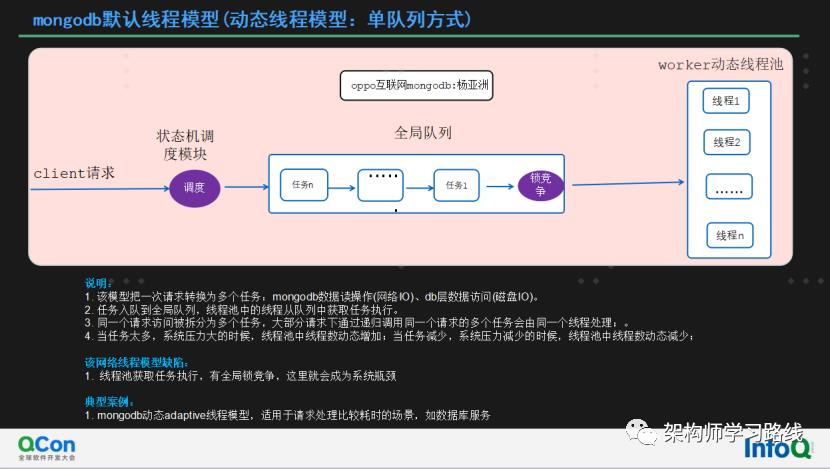
说明:
该模型把一次请求转换为多个任务:mongodb数据读操作(网络IO)、db层数据访问(磁盘IO)。
任务入队到全局队列,线程池中的线程从队列中获取任务执行。
同一个请求访问被拆分为多个任务,大部分情况下通过递归调用同一个请求的多个任务会由同一个线程处理;。
当任务太多,系统压力大的时候,线程池中线程数动态增加;当任务减少,系统压力减少的时候,线程池中线程数动态减少;
该网络线程模型缺陷:
线程池获取任务执行,有全局锁竞争,这里就会成为系统瓶颈
典型案例:
mongodb动态adaptive线程模型,适用于请求处理比较耗时的场景,如数据库服务
mongodb优化后线程模型(动态线程模型-多队列方式)
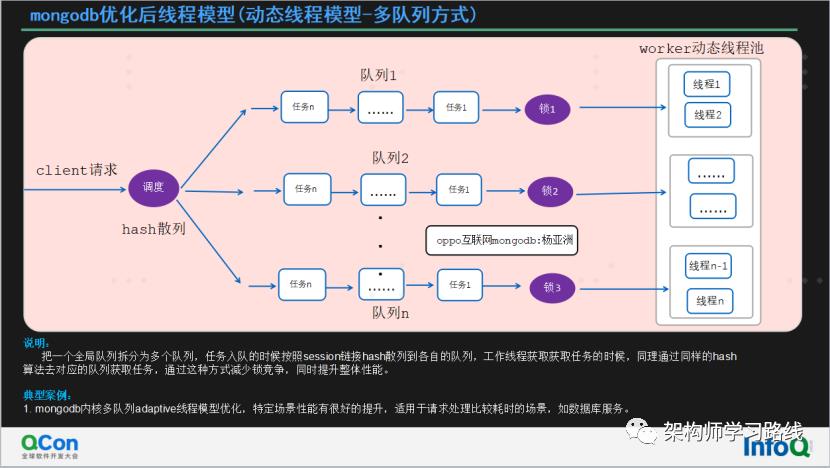
说明:
把一个全局队列拆分为多个队列,任务入队的时候按照session链接hash散列到各自的队列,工作线程获取获取任务的时候,同理通过同样的hash算法去对应的队列获取任务,通过这种方式减少锁竞争,同时提升整体性能。
典型案例:
mongodb内核多队列adaptive线程模型优化,特定场景性能有很好的提升,适用于请求处理比较耗时的场景,如数据库服务。
分享主题五:并行迁移-集群扩容速率N倍提升优化实践
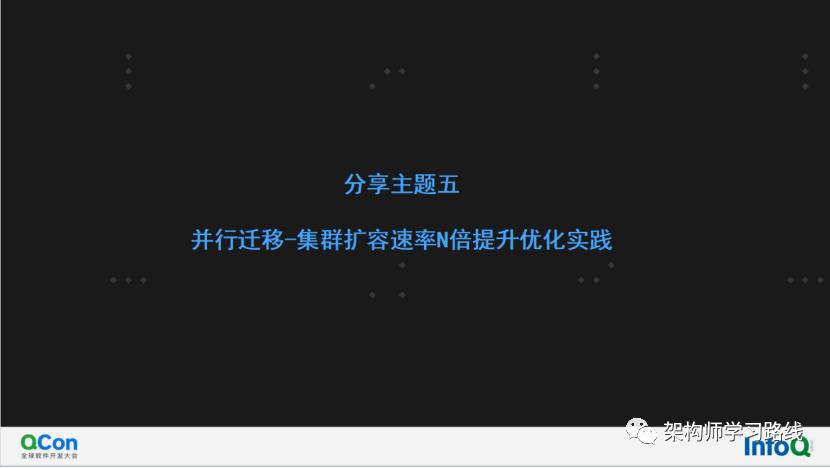
并行迁移-集群扩容速率N倍提升优化实践(高版本)
并行迁移过程(假设需要迁移的表名为:test, 从3节点扩容到6节点):
选取需要迁移的块,假设源集群有M分片,扩容新增N分片,则一般情况需要迁移的块=min(M,N)
迁移步骤:1. configServer-master选出需要迁移的块;2. config.locks表中id=test这条记录上锁;3.通知需要迁移的源分片开始迁移;4. 迁移完成后延时10s,重复1-4步骤实现持续性chunk数据迁移
并行迁移步骤:
说明:假设需要迁移的表名为test, 源分片数M,扩容后新增分片数N
configServer-master选出需要迁移的块,一般S=min(M, N),也就是M和N中的最小值;
config.locks表中获取id=test这条记录对应的分布式锁;
异步通知需要迁移的S个源分片开始迁移;
等待S个chunk迁移完成
迁移完成后延时10秒
重复步骤1-5
并行迁移瓶颈:
获取分布式锁时间太长,原因:config.locks表中id=test表的分布式锁可能被其他操作锁住
configServer异步通知源分片中的S个分片同时开始迁移数据到目的分片,任一个chunk迁移慢会拖累整个迁移过程。
本批次确认迁移完成后,还需要延时10s;一般SSD服务器,一个chunk迁移都在几百ms内完成。
优化方法:
避免其他操作占用分布式锁,例如splite我们可以关闭autoSplite功能,或者调大chunksize
configServer并行迁移不把多个分片的并行迁移放到同一个逻辑,而是放到各自的逻辑。
延时放到各自分片迁移逻辑里面控制,不受全局延时控制
分片延时可配置,支持实时动态命令行调整
分享主题六:性能优化案例
案例1.千亿级数据量mongodb集群性能数倍提升优化实践-背景
业务背景:
核心元数据
数据量千亿级
前期写多读少,后期读多写少
高峰期读写流量百万级
时延敏感
数据增长快,不定期扩容
同城多活集群
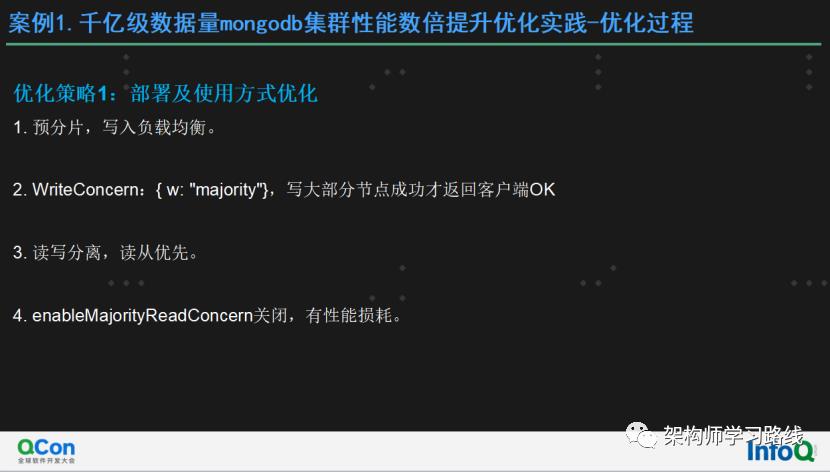
优化策略1:部署及使用方式优化
预分片,写入负载均衡。
WriteConcern:{ w: "majority"},写大部分节点成功才返回客户端OK
读写分离,读从优先。
enableMajorityReadConcern关闭,有性能损耗。
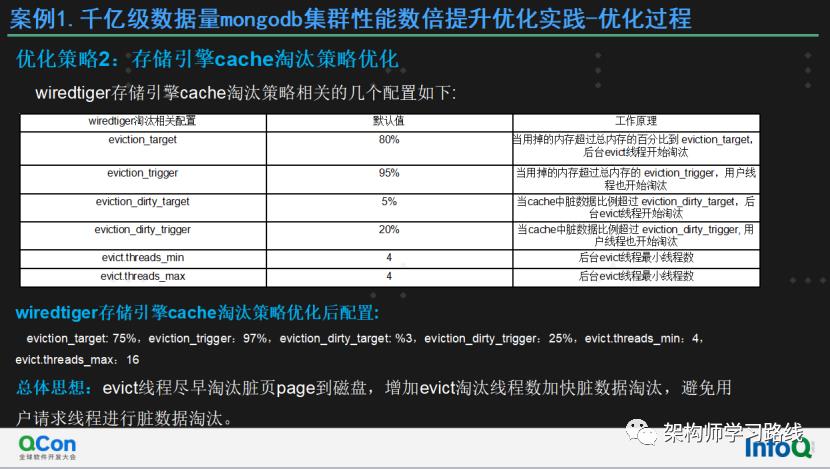
优化策略2:存储引擎cache淘汰策略优化
wiredtiger存储引擎cache淘汰策略相关的几个配置如下:
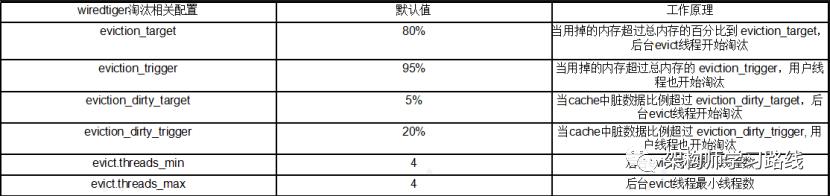
wiredtiger存储引擎cache淘汰策略优化后配置:
eviction_target: 75%,eviction_trigger:97%,eviction_dirty_target: %3,eviction_dirty_trigger:25%,evict.threads_min:4,evict.threads_max:16
总体思想:evict线程尽早淘汰脏页page到磁盘,增加evict淘汰线程数加快脏数据淘汰,避免用户请求线程进行脏数据淘汰。
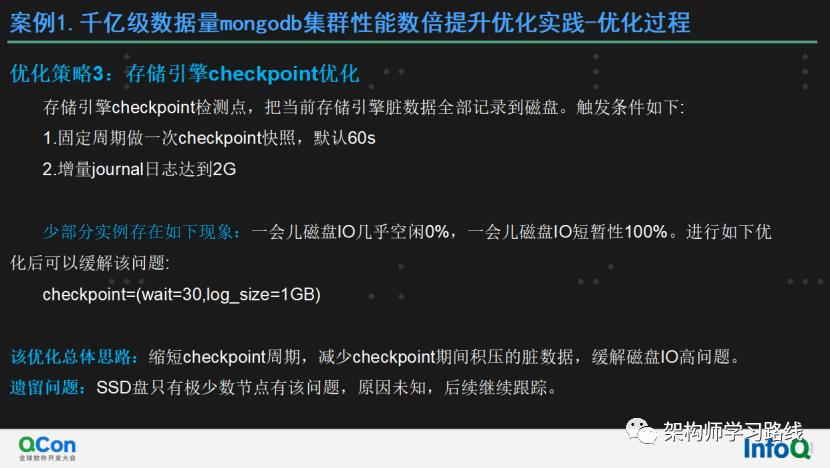
优化策略3:存储引擎checkpoint优化
存储引擎checkpoint检测点,把当前存储引擎脏数据全部记录到磁盘。触发条件如下:
固定周期做一次checkpoint快照,默认60s
增量journal日志达到2G
少部分实例存在如下现象:一会儿磁盘IO几乎空闲0%,一会儿磁盘IO短暂性100%。进行如下优化后可以缓解该问题:
checkpoint=(wait=30,log_size=1GB)
该优化总体思路:缩短checkpoint周期,减少checkpoint期间积压的脏数据,缓解磁盘IO高问题。
遗留问题:SSD盘只有极少数节点有该问题,原因未知,后续继续跟踪。
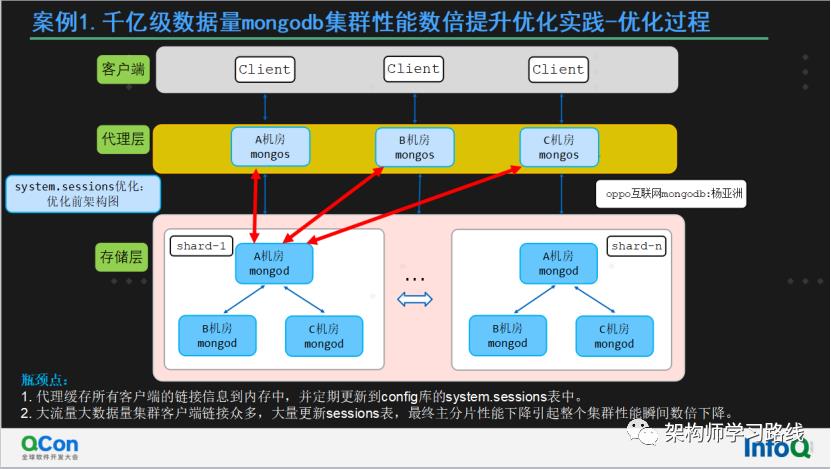
瓶颈点:
代理缓存所有客户端的链接信息到内存中,并定期更新到config库的system.sessions表中。
大流量大数据量集群客户端链接众多,大量更新sessions表,最终主分片性能下降引起整个集群性能瞬间数倍下降。
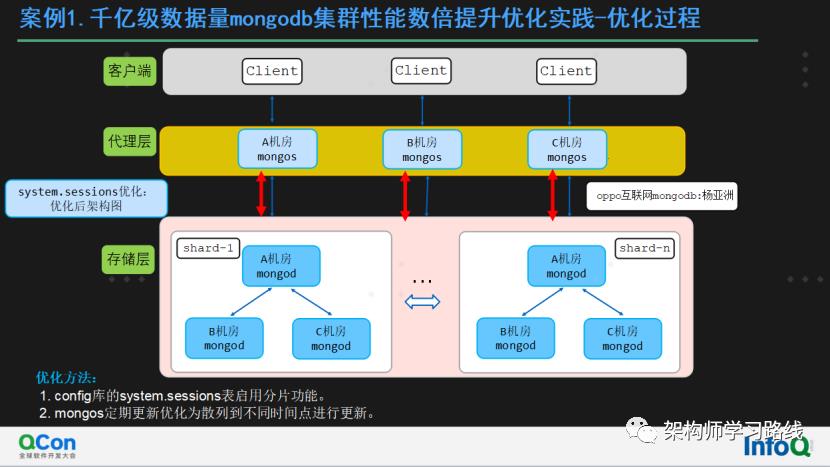
优化方法:
config库的system.sessions表启用分片功能。
mongos定期更新优化为散列到不同时间点进行更新。
优化策略4:
sharding集群system.session优化
该优化总体思路:
之前代理集中式更新单个分片,优化为散列到不同时间点更新多个分片。
该优化后system.sessions表更新引起的瞬间性能数倍降低和大量慢日志问题得到了解决。
优化策略5:tcmalloc内存优化
db.serverStatus().tcmalloc监控发现部分mongod实例pageheap、内存碎片等消耗过高。通过系统调用分析得出:内存碎片率、pageheap过高,会引起分配内存过程变慢,引起集群性能严重下降。
该优化总体思路:
借助gperftools三方库中tcmalloc内存管理模块,实时动态调整tcmalloc内存Release Rate,尽早释放内存,避免存储引擎获取cache过程阻塞变慢。
案例2.万亿级数据量mongodb集群性能数倍提升优化实践
业务背景:
集群存储离线数据
集群总数据量万亿级
前期主要为数据写入,要求万亿级数据几周内尽快全部写入集群
后期主要是读流量,单次查询数据条数比较多,要求快速返回
每隔一定时间周期(周为单位)会有持续性大量写入
优化策略1:基础性优化
分享主题六中读写分离、预分片、wiredtiger存储引擎优化、session优化、tcmalloc使用优化等基础性优化策略同样适用于该集群,具体详见《分享主题六:百万级高并发读写/千亿级数据量mongodb集群性能数倍提升优化实践》
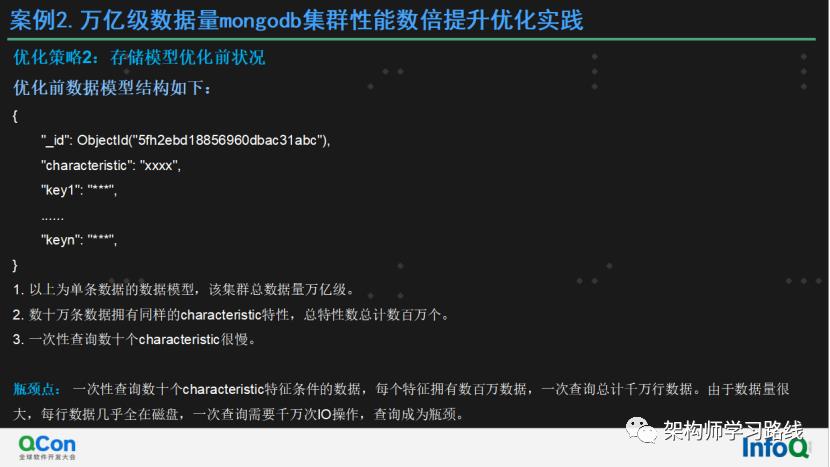
优化策略2:存储模型优化前状况
优化前数据模型结构如下:
1.{
2. "_id": ObjectId("5fh2ebd18856960dbac31abc"),
3. "characteristic": "xxxx",
4. "key1": "***",
5. ......
6. "keyn": "***",
7.}
以上为单条数据的数据模型,该集群总数据量万亿级。
数十万条数据拥有同样的characteristic特性,总特性数总计数百万个。
一次性查询数十个characteristic很慢。
瓶颈点: 一次性查询数十个characteristic特征条件的数据,每个特征拥有数百万数据,一次查询总计千万行数据。由于数据量很大,每行数据几乎全在磁盘,一次查询需要千万次IO操作,查询成为瓶颈。
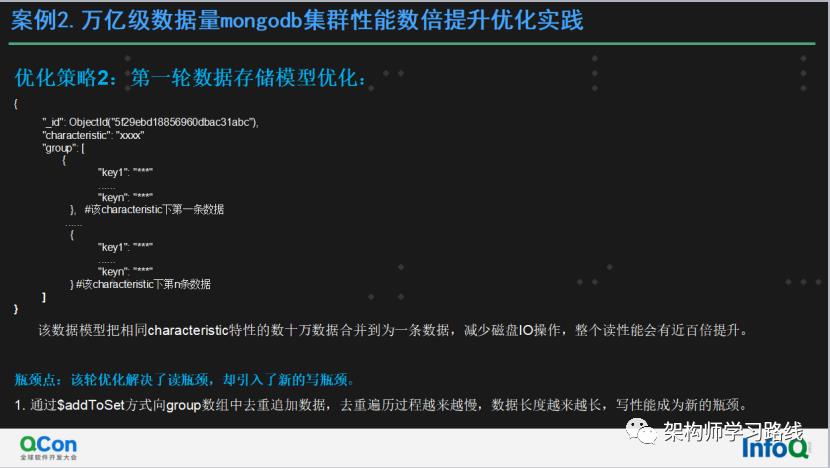
优化策略2:第一轮数据存储模型优化:
1.{
2. "_id": ObjectId("5f29ebd18856960dbac31abc"),
3. "characteristic": "xxxx"
4. "group": [
5. {
6. "key1": "***"
7. ......
8. "keyn": "***"
9. }, #该characteristic下第一条数据
10. ......
11. {
12. "key1": "***"
13. ......
14. "keyn": "***"
15. } #该characteristic下第n条数据
16. ]
17.} 该数据模型把相同characteristic特性的数十万数据合并到为一条数据,减少磁盘IO操作,整个读性能会有近百倍提升。
瓶颈点:该轮优化解决了读瓶颈,却引入了新的写瓶颈。
通过$addToSet方式向group数组中去重追加数据,数据长度越来越长,磁盘IO压力越来越大、写性能成为新的瓶颈。
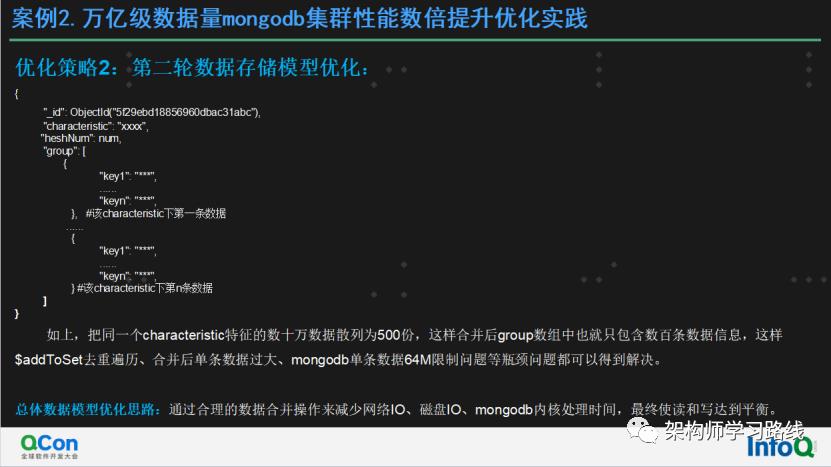
优化策略2:第二轮数据存储模型优化:
1.{
2. "_id": ObjectId("5f29ebd18856960dbac31abc"),
3. "characteristic": "xxxx",
4. "hashNum": num,
5. "group": [
6. {
7. "key1": "***",
8. ......
9. "keyn": "***",
10. }, #该characteristic下第一条数据
11. ......
12. {
13. "key1": "***",
14. ......
15. "keyn": "***",
16. } #该characteristic下第n条数据
17. ]
18.} 如上,把同一个characteristic特征的数十万/数百万数据散列为500份,这样合并后group数组中也就只包含数百条数据信息,这样合并后单条数据过大、mongodb单条数据64M限制问题、磁盘IO过高等瓶颈问题都可以得到解决。
总体数据模型优化思路:通过合理的数据合并操作来减少网络IO、磁盘IO、mongodb内核处理时间,最终使读和写达到平衡。
分享主题七:成本节省-记某服务千亿级数据迁移mongodb,百台SSD服务器节省优化实践

成本节省-千亿级数据迁移mongodb,百台SSD服务器节省优化实践
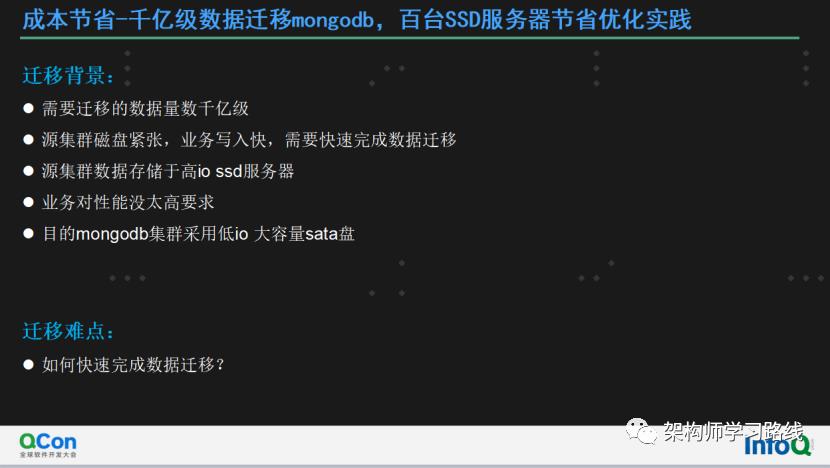
迁移背景:
需要迁移的数据量数千亿级
源集群磁盘紧张,业务写入快,需要快速完成数据迁移
源集群数据存储于高io ssd服务器
业务对性能没太高要求
目的mongodb集群采用低io 大容量sata盘
迁移难点:
如何快速完成数据迁移?
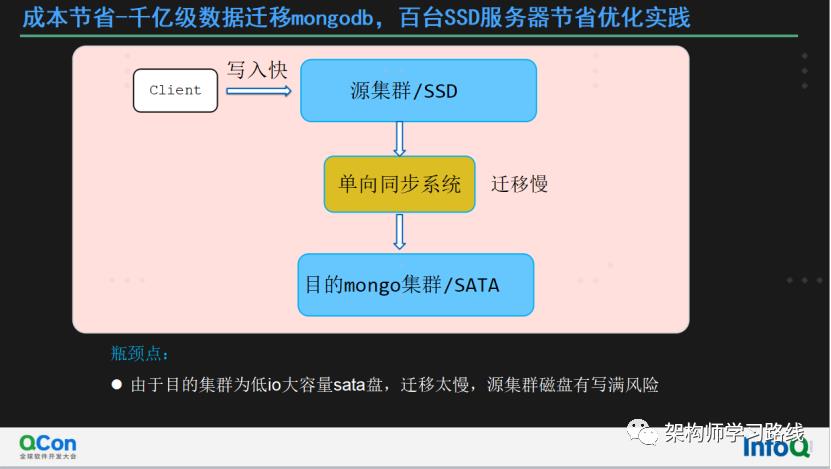
瓶颈点:
由于目的集群为低io大容量sata盘,迁移太慢,源集群磁盘有写满风险
优化策略:
同步数据到大容量SSD中转集群
拷贝中转集群数据到目标大容量SATA盘服务器
加载数据
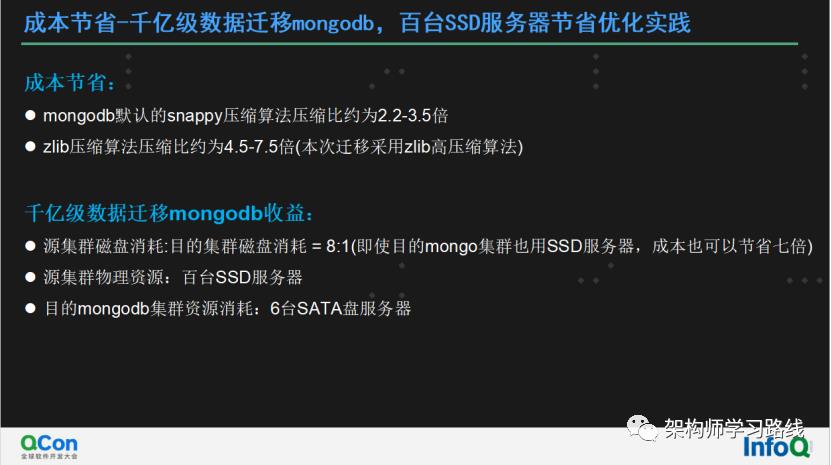
成本节省:
mongodb默认的snappy压缩算法压缩比约为2.2-3.5倍
zlib压缩算法压缩比约为4.5-7.5倍(本次迁移采用zlib高压缩算法)
千亿级数据迁移mongodb收益:
源集群磁盘消耗:目的集群磁盘消耗 = 8:1(即使目的mongo集群也用SSD服务器,成本也可以节省七倍)
源集群物理资源:百台SSD服务器
目的mongodb集群资源消耗:6台SATA盘服务器
分享主题八:展望-如何实现mongodb与SQL融合
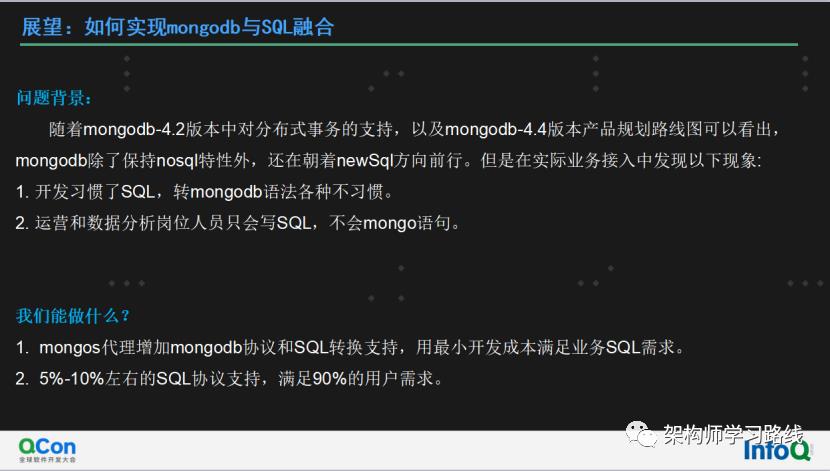
问题背景:
随着mongodb-4.2版本中对分布式事务的支持,以及mongodb-4.4版本产品规划路线图可以看出,mongodb除了保持nosql特性外,还在朝着newSql方向前行。但是在实际业务接入中发现以下现象:
开发习惯了SQL,转mongodb语法各种不习惯。
运营和数据分析岗位人员只会写SQL,不会mongo语句。
我们能做什么?
mongos代理增加mongodb协议和SQL转换支持,用最小开发成本满足业务SQL需求。
5%-10%左右的SQL协议支持,满足90%的用户需求。
分享主题九:其他-那些年我们踩过的坑
“那些年我们踩过的坑” :
实际业务接入mongodb数据库过程中,我们踩过很多坑,包括业务不合理使用、不合理运维、集群不合理配置、mongodb内核踩坑、误操作等,甚至出现过同一个核心业务几次抖动。
本次分享中集群优化只列举了主要的优化过程,实际优化过程比本次分享内容更加复杂,集群更多优化细节及数十例典型踩坑过程将逐步在Qconf平台、OPPO互联网、mongodb中文社区发布。
原文:https://my.oschina.net/u/4087916/blog/4907378


以上是关于万亿级数据库MongoDB集群性能数十倍提升及机房多活容灾实践的主要内容,如果未能解决你的问题,请参考以下文章