深入理解CAP理论和适用场景
Posted 大数据技术与架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解CAP理论和适用场景相关的知识,希望对你有一定的参考价值。
强同步复制,数据的写操作需要同步到主副本和所有的备副本,并且全部写入成功后,才返回成功状态。这样,当系统出现异常时,切换到其他任何一个备份副本时,数据是一致的。但是,强同步复制性能不好,而且可用性比较差。如果,在复制过程中,如果某个备份节点出现故障,这时,会阻塞数据的正常写服务。
异步复制,当数据写入操作成功后,当数据成功复制到主副本时,甚至还没复制时,写操作就返回成功状态。这样,异步复制的性别比较好,但是,当主备出现故障时可能出现数据丢失。
一致性:数据复制的时候,按照强一致性的方式进行数据复制。保证了在读操作总是能够读取到之前写入的数据,无论从那个主数据或者副本数据。
可用性:数据写入成功后,正在进行数据复制时,任何一个副本节点发生异常也不会影响此次写入操作。可以理解为,此时数据的复制采用的是弱一致性,数据的读写操作在单台机器发生故障的情况下仍然可以正常执行。
分区容错性:在服务实例发生异常时,分布式系统仍然能够满足一致性和可用性。
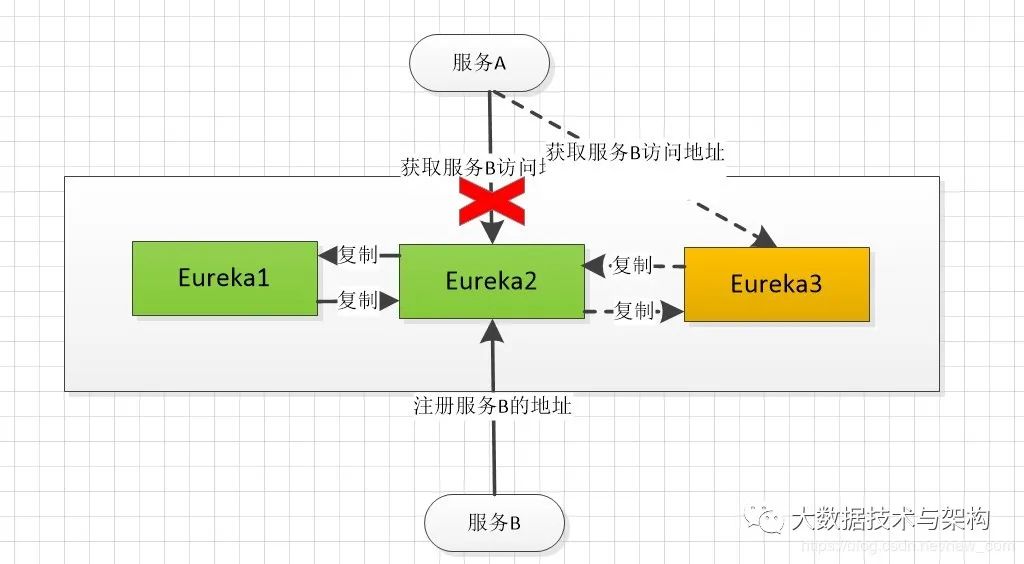
eureka服务注册与发现中心集群,在集群中,新增一个eureka实例时,集群中的实例是相互复制其注册的服务实例数据。示例如下:
mysql数据集群与redis集群,由于mysql和redis的数据复制都是采用的异步复制,所以mysql数据集群与redis集群都属于AP类型,在集群中获取数据时,会存在数据不一致的情况。
zookeeper服务注册与发现中心集,在集群中,包含一个Leader节点,其余全部为Follower 节点。Leader节点负责读和写操作,Follower 节点只负责读操作。当客户端向集群发出写请求时,写请求会转发到Leader节点,Leader写操作完成后,采用广播的形式,向其余Follower 节点复制数据,Follower节点也写成功,返回给客户端成功。流程如图:
数据库两阶段提交,第一阶段,事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交。第二阶段,事务协调器要求每个数据库提交数据。如果有任何一个数据库否决此次提交,那么所有数据库操作的数据都会回滚。
Kafka集群(ack=all的配置时),Kafka消息集群中,生产者生成消息时,采用ack=all的配置时,消息成功写入分区,以及其所有分区副本后才算写入成功。此时,消费者从集群中获取的数据都是一致的。
文章不错?点个【在看】吧! 以上是关于深入理解CAP理论和适用场景的主要内容,如果未能解决你的问题,请参考以下文章