haproxy代码框架分析
Posted 云开源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了haproxy代码框架分析相关的知识,希望对你有一定的参考价值。
1、概述
haproxy 是用于提供高可用性、负载均衡以及基于四层和七层网络的代理软件。和大多数网络模块一样,看不到haproxy很炫的流程和功能,但是它实时都在默默进行链路管理、报文分发,大部分场景下对其性能要求较高、差错容忍度较低。
关于性能,其官网描述列举了至少8个方向的优化措施,这使得haproxy进程本身的消耗比内核空间消耗低20倍以上。因此,在高端系统上haproxy的7层性能可能会超过硬件负载均衡设备。在健康检查方面除了支持tcp/http基本检查外,还能支持mysql等特殊应用的高级健康检查。
openstack架构里,有以下地方可能会用到haproxy做负载均衡:
1)控制节点的发往各个组件API的报文节点负载均衡;
2)作为neutron-lbaas的底层可选实现之一;
本次我们基于haproxy1.5版本源码及一些网络资料分析下haproxy的代码框架。框架上主要包括:主流程、调度管理、配置读取、session管理、统计管理、基础模块等。重点介绍下调度管理和session管理。

1.1 haproxy-systemd-wrapper

systemd 管理haproxy程序运行时我们至少会看到有3个相关进程在运行,如果跑N个实例,则会有N+2个相关进程。
root 19744 1 0 Feb15 ? 00:00:00 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid
haproxy 19745 19744 0 Feb15 ? 00:00:00 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
haproxy 19746 19745 0 Feb15 ? 00:04:45 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid –Ds
systemd管理haproxy是通过先启动haproxy-systemd-wrapper进程去启动和管理haproxy程序,warpper进程进行了一次fork操作,后续的haproxy内又会做一次fork。
另外,为了优雅重启haproxy, wrapper中守护SIGUSR2信号进行重启,并读取旧的pids。如果存在旧的pids,则启动时增加"-sf"选项,这样进入新的haproxy程序后会对向所有旧进程发出SIGUSR1信号,旧的harpoxy程序捕获SIGUSR1执行对应回调sig_soft_stop优雅退出。
1.2 haproxy代码主线
haproxy代码主线如下:
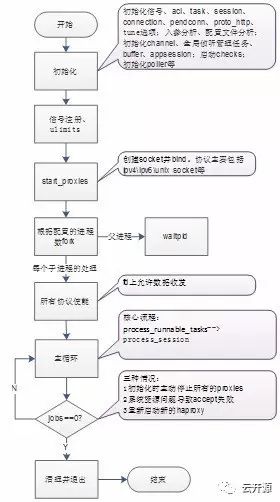
2、调度管理
2.1 run_poll_loop主循环
haproxy 的调度管理主要在run_poll_loop中循环实现。采用事件驱动模型显著降低了上下文切换的开销及内存占用。代码如下:
/* Runs the polling loop */
void run_poll_loop()
{
int next;
tv_update_date(0,1);
while (1) {
/* check if we caught some signals and process them */
signal_process_queue();
/* Check if we can expire some tasks */
wake_expired_tasks(&next);
/* Process a few tasks */
process_runnable_tasks(&next);
/* stop when there's nothing left to do */
if (jobs == 0)
break;
/* The poller will ensure it returns around <next> */
cur_poller.poll(&cur_poller, next);
fd_process_spec_events();
}
}
主循环的结构比较清晰,循环的执行下面的调用:
1. 处理信号队列
2. 唤醒超时任务
3. 处理可运行的任务
4. 检测是否结束循环
5. 执行 poll 处理 fd 的 IO 事件
6. 处理可能仍有 IO 事件的 fd
2.2 信号管理
haproxy 封装了自己的信号处理机制。接受到信号之后,将该信号放到信号队列中。signal_register_fct,signal_register_task接口提供了注册函数回调和任务类型回调两种方式。
在程序运行到signal_process_queue() 时处理所有位于信号队列中的信号。
void __signal_process_queue()
{
int sig, cur_pos = 0;
struct signal_descriptor *desc;
sigset_t old_sig;
/* block signal delivery during processing */
sigprocmask(SIG_SETMASK, &blocked_sig, &old_sig);
/* It is important that we scan the queue forwards so that we can
* catch any signal that would have been queued by another signal
* handler. That allows real signal handlers to redistribute signals
* to tasks subscribed to signal zero.
*/
for (cur_pos = 0; cur_pos < signal_queue_len; cur_pos++) {
sig = signal_queue[cur_pos];
desc = &signal_state[sig];
if (desc->count) {
struct sig_handler *sh, *shb;
list_for_each_entry_safe(sh, shb, &desc->handlers, list) {
if ((sh->flags & SIG_F_TYPE_FCT) && sh->handler)
((void (*)(struct sig_handler *))sh->handler)(sh);
else if ((sh->flags & SIG_F_TYPE_TASK) && sh->handler)
task_wakeup(sh->handler, sh->arg | TASK_WOKEN_SIGNAL);
}
desc->count = 0;
}
}
signal_queue_len = 0;
/* restore signal delivery */
sigprocmask(SIG_SETMASK, &old_sig, NULL);
}
信号注册时注册SIG_F_TYPE_FCT标识则直接调用信号回调处理;SIG_F_TYPE_TASK标识说明注册时回调函数是一个task指针,这时需要唤醒task,并指明任务状态为TASK_WOKEN_SIGNAL,此后对应处理函数将在task管理下处理。下面来看看task管理。
2.3 task管理
struct task {
struct eb32_node rq; /* ebtree node used to hold the task in the run queue */
unsigned short state; /* task state : bit field of TASK_* */
short nice; /* the task's current nice value from -1024 to +1024 */
unsigned int calls; /* number of times ->process() was called */
struct task * (*process)(struct task *t); /* the function which processes the task */
void *context; /* the task's context */
struct eb32_node wq; /* ebtree node used to hold the task in the wait queue */
int expire; /* next expiration date for this task, in ticks */
};
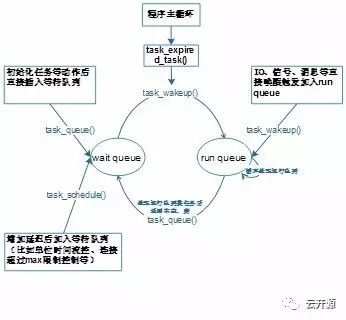
haproxy的调度最终都在task内回调处理,为提升性能,task的管理是采用ebtree树形队列方式,分为 wait queue和 run queue。wait queue 是需要等待一定时间的task 的集合,而 run queue 则代表需要立即执行的 task 的集合。
wake_expired_tasks()函数用来唤醒超时任务:就是检查wait queue 中那些超时的任务,并将其放到 run queue中。
process_runnable_tasks()函数则是处理位于run queue中的任务:对于TCP或者HTTP业务流量的处理,该函数最终通过调用 process_session 来完成,包括解析已经接收到的数据, 并执行一系列 load balance 的特性,但不负责从 socket 收发数据,数据收发由poll完成。同时,也会因为一些情况导致需要将当前的任务通过调用 task_queue 等接口放到 wait queue 中,实现上在任务回调处理时返回非空任务则会把任务重新加入wait queue。
haproxy 中用 jobs 记录当前要处理的任务总数, 如果 jobs 为 0 的话,通常意味着 haproxy 要退出了,因为连 listener 都要释放了。jobs 的数值通常在 process_session 时更新。
任务管理流转图如下:
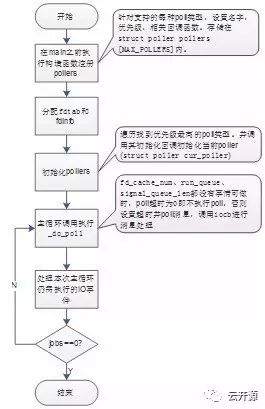
2.4 poll消息驱动
haproxy 启动阶段,会检测当前系统可以启用那种异步处理的机制,包括 select、poll、 epoll、kqueue 等,并注册对应 poller 的 poll 方法。同时,分配fdtab和fdinfo。
主循环中cur_poller.poll(&cur_poller, next);就是执行已经注册的poller 的poll 方法,主要功能就是获取所有活动的 fd,并调用对应的 handler,完成接受新建连接、数据收发等功能。
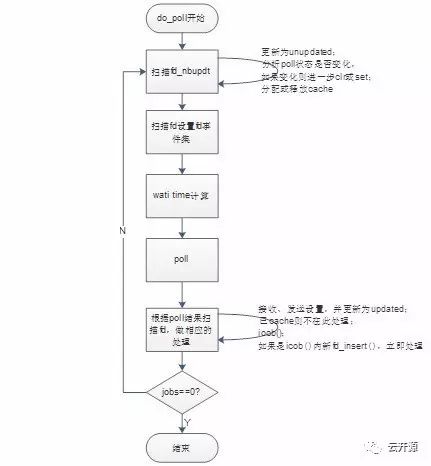
poller的poll方法执行时,程序会将某些符合条件以便再次执行 IO 处理的的fd放到 fd_cache中,之后fd_process_cached_events () 函数会再次执行这些fd的io handler。
主要流程如下:
细化下_do_poll的流程:
我们再来看下struct fdtab结构:
struct fdtab {
int (*iocb)(int fd); /* I/O handler, returns FD_WAIT_* */
void *owner; /* the connection or listener associated with this fd, NULL if closed */
unsigned int cache; /* position+1 in the FD cache. 0=not in cache. */
unsigned char state; /* FD state for read and write directions (2*3 bits) */
unsigned char ev; /* event seen in return of poll() : FD_POLL_* */
unsigned char new:1; /* 1 if this fd has just been created */
unsigned char updated:1; /* 1 if this fd is already in the update list */
unsigned char linger_risk:1; /* 1 if we must kill lingering before closing */
unsigned char cloned:1; /* 1 if a cloned socket, requires EPOLL_CTL_DEL on close */
};
每一个fdtab结构对应了一个fd的拥有者,回调,状态等。owner、iocb回调等在bind_listener时进行设置。其中state对应ACTIVE、READY、POLLED 3种基本状态,然后再与读写状态组合。
3、配置读取
配置选择和调优是使用haproxy过程中的一个较大的问题。本文不做具体的配置分析,简单说下配置实现,针对配置文件里的每个配置段进行注册,加入sections链表,在读取并分析完一行参数后根据链表查找cfg_section结构中调用对应的section_parser回调函数处理。之后把数据存入global、proxy等数据结构对应的存储空间。同时还会对各个配置session的协议侦听进行初始化cfg_parse_listen。sections链表和cfg_section结构如下:
struct list sections = LIST_HEAD_INIT(sections);
struct cfg_section {
struct list list;
char *section_name;
int (*section_parser)(const char *, int, char **, int);
};
4、session管理
4.1 什么是session
从逻辑节点角度讲,一个session包括了client,haproxy,server三个逻辑节点。一个tcp/http报文要被成功分析和转发需要有两条TCP 连接,一个是 client 到 haproxy,一个是 haproxy 到后端 server(后面的描述中我们会简化为C/H,H/S描述)。C/H建链终止于session_complete(),之后的H/S在process_session中由任务驱动调度和服务器建链并分析转发报文。
举个例子:假设我们在haproxy节点10.43.114.33上配了一个pcs的WEB页侦听
listen cluster 0.0.0.0:80
mode http
balance roundrobin
server webapp1 10.43.114.249:2224 weight 1 check inter 2000 rise 2 fall 3~
server webapp1 10.43.114.183:2224 weight 1 check inter 2000 rise 2 fall 3~
那么在我们访问WEB首页时可以使用http://10.43.114.33:80,访问后我们可以看到产生了6对12条链路,说明访问过程发送了6个报文请求,产生了6对链路,我们称之为6个session。
[root@localhost ~]# netstat -anp|grep haproxy
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 16574/haproxy
tcp 0 0 10.43.114.33:45512 10.43.114.249:2224 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:80 10.43.114.23:1954 ESTABLISHED 16574/haproxy
tcp 0 0 10.43.114.33:80 10.43.114.23:1949 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:45513 10.43.114.249:2224 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:80 10.43.114.23:1952 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:45515 10.43.114.249:2224 ESTABLISHED 16574/haproxy
tcp 0 0 10.43.114.33:80 10.43.114.23:1953 ESTABLISHED 16574/haproxy
tcp 0 0 10.43.114.33:45511 10.43.114.249:2224 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:45510 10.43.114.249:2224 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:80 10.43.114.23:1951 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:80
10.43.114.23:1950 ESTABLISHED 16436/haproxy
tcp 0 0 10.43.114.33:45514 10.43.114.249:2224 ESTABLISHED 16574/haproxy
4.2 session相关数据结构
session相关重要数据结构在实际代码中的作用和关系我们可以用下面的结构关系图来展示,结合前面的调度讲解和梳理出的数据结构关系再走读会事半功倍。
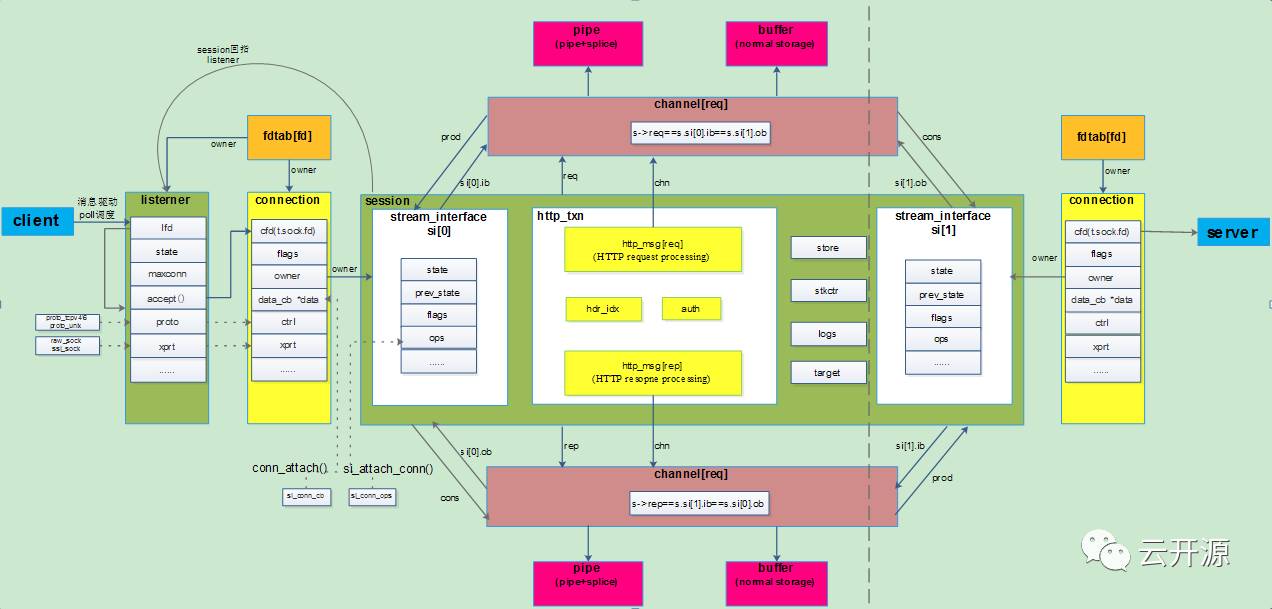
4.3 client-->harpoxy链路建链
我们先看下client-->harpoxy链路相关的初始化。
初始化处理 TCP 连接的方法
初始化处理 TCP 协议的相关数据结构,主要是和 socket 相关的方法的声明。包括tcpv4和tcpv6,下面是proto_tcpv4的初始化:
static struct protocol proto_tcpv4 = {
.name = "tcpv4",
.sock_domain = AF_INET,
.sock_type = SOCK_STREAM,
.sock_prot = IPPROTO_TCP,
.sock_family = AF_INET,
.sock_addrlen = sizeof(struct sockaddr_in),
.l3_addrlen = 32/8,
.accept = &listener_accept,
.connect = tcp_connect_server,
.bind = tcp_bind_listener,
.bind_all = tcp_bind_listeners,
.unbind_all = unbind_all_listeners,
.enable_all = enable_all_listeners,
.get_src = tcp_get_src,
.get_dst = tcp_get_dst,
.drain = tcp_drain,
.pause = tcp_pause_listener,
.listeners = LIST_HEAD_INIT(proto_tcpv4.listeners),
.nb_listeners = 0,
};
初始化 listeners
listeners,是用于负责处理监听相关的逻辑。他的初始化伴随在haproxy配置文件的解析过程。
1、proto层初始化
在 haproxy 解析 bind 配置的时候赋值给 listener 的 proto 成员,完成协议相关回调函数的挂接。以tcpv4为例,函数调用流程如下:
cfg_parse_listen—>
str2listener—>
tcpv4_add_listener—>
listener->proto = &proto_tcpv4;
这里初始化的是 listener 处理 socket 的一些方法。
2、绑定所有已注册协议上的 listeners
protocol_bind_all –>
proto->bind_all(遍历所有协议)
以tcpv4为例,实际调用了“proto层初始化”里的tcp_bind_listeners()-->tcp_bind_listener(),即完成了所有listners的socket,bind,listen过程。
3、启用所有已注册协议上的 listeners
把所有 listeners 的 fd 加到 poll lists 中,protocol_enable_all -> all registered protocol enable_all -> enable_all_listeners (tcpv4) -> enable_listener
protocol_enable_all –>
proto->enable_all(遍历所有协议)
以tcpv4为例,实际调用了“proto层初始化”里的enable_all_listeners ()-->enable_listener ()。
enable_listener()函数会将处于 LI_LISTEN 的 listener 的状态修改为 LI_READY,并调用 poll 的fd_want_recv方法, 指出该fd将接受数据。
4、会话层初始化
在配置检查时,完成listeners的会话层初始化。
check_config_validity-->
listener->accept = session_accept;
listener->frontend = curproxy; (解析 frontend 时,会执行赋值:curproxy->accept = frontend_accept)
listener->handler = process_session;
TCP 连接的处理流程
前面几个初始化分析,主要是为了搞清楚当请求到来时,处理过程中实际的函数调用关系。下面分析 TCP 连接的处理流程:
1、接受新建连接
我们以tcpv4 的accpet为例:
accept调用为listener->proto->accept;即调用挂载的listener_accept()。listener->proto->accept;
在tcp_bind_listener() 内bind、listen后挂载到fd的io回调事件上了:fdtab[fd].iocb = listener->proto->accept;
总结:当tcp层连接过来时,处于listen状态的fd在poll事件回调fdtab[fd].iocb(),最驱动终就是调用了listener_accept()建立TCP层链路。
2、accept 方法的三个层次
listener_accept()
负责在listen fd上接收新建 TCP 连接,并触发 listener 自己的 accept 方法 session_accept()。
run_poll_loop –>
cur_poller.poll –>
__do_poll –>
fdtab[fd].iocb(fd)---即 listener_accept—>
按照 global.tune.maxaccept 的设置尽量可能多执行系统调用 accept,然后再调用 l->accept(),即 listener 的 accept 方法 session_accept
session_accept()
负责创建 session,并作 session 成员的初步初始化,并调用 frontend 的 accept 方法 front_accetp()
frontend_accept()
该函数主要负责 session 前端的 TCP 连接的初始化,包括 socket 设置,log 设置,以及 session 部分成员的初始化。
主要流程:
设置 session 结构体的 log 成员
根据配置的情况,分别设置新建连接套接字的选项,包括 TCP_NODELAY/KEEPALIVE/LINGER/SNDBUF/RCVBUF 等等
如果 mode 是 http 的话,将 session 的 txn 成员做相关的设置和初始化。
C/H的链路建链状态跃迁比较简单,session_complete()建链完成后直接从SI_ST_INI—> SI_ST_EST。
si_reset(&s->si[0], t);
si_set_state(&s->si[0], SI_ST_EST);
4.4 harpoxy-->server链路建链
请求消息驱动poll调度的建链在session_complete()结束后完成了C/H部分的建链,同时在session_complete()内调用了设置了进一步处理函数t->process = l->handler;(即process_session),task_wakeup(t, TASK_WOKEN_INIT);之后由task调度process_session进行处理。首先要做的就是H/S的建链(包含了服务器的选择):
和server建链
第一次进入process_session后会进入下面SI_ST_INI状态处理流程循环执行完成本次服务器的选择及建链,调用了sess_update_stream_int(会被多次调用)、sess_prepare_conn_req、sess_establish。这儿会和C/H的建链一样,初始化并关联填写前面我们分析的那些数据结构定义的变量。
H/S 建链的stream_interface 的state主要跃迁流程如下:
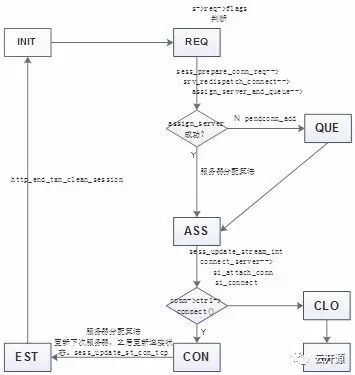
Server check
Server check是haproxy里针对每个侦听配置的服务器列表里的服务器做的check检测,server check和session链路走不同链路。
4.5 报文分析
这部分先简单说下,有机会再详细分析:
http 请求的处理
http 请求处理主要在process_session() 的resync_request label内完成。
http 请求应答处理
http 请求应答处理主要在process_session()的resync_response label内完成
5、统计管理
实现了一个统计各个流量、失败率等的实时网页。
6、基础模块
基础模块主要包括日志管理(Log)、内存管理(buffer)、弹性二叉树 (Ebtree )等。

以上是关于haproxy代码框架分析的主要内容,如果未能解决你的问题,请参考以下文章