Cassandra 初学者指南
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cassandra 初学者指南相关的知识,希望对你有一定的参考价值。
Apache Cassandra 是一种分布式非关系型数据库,具有高性能、可扩展、无中心化等特征。Cassandra 是适用于社交网络业务场景的数据库,适合实时事务处理和提供交互型数据。以 Amazon 完全分布式的 Dynamo 数据库作为基础,结合 Google BigTable 基于列族(Column Family)的数据模型,实现 P2P 去中心化的存储。
行列概念:一组包含名称值对的数据叫做行(Row),而每一组名称值对(Name/Value Pair)被称之为列(Column)。数据是以松散结构的多维哈希表存储在数据库中,所谓松散结构,是指每行数据可以有不同的列结构,如图所示:
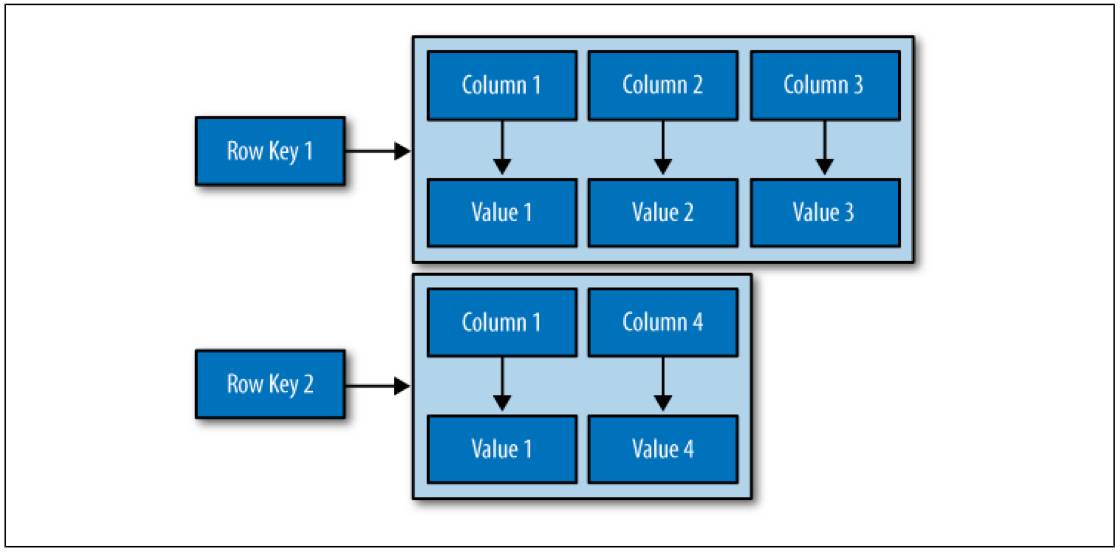
Super Column:可在列之间建立关联的超级列,支持往超级列中添加子列。
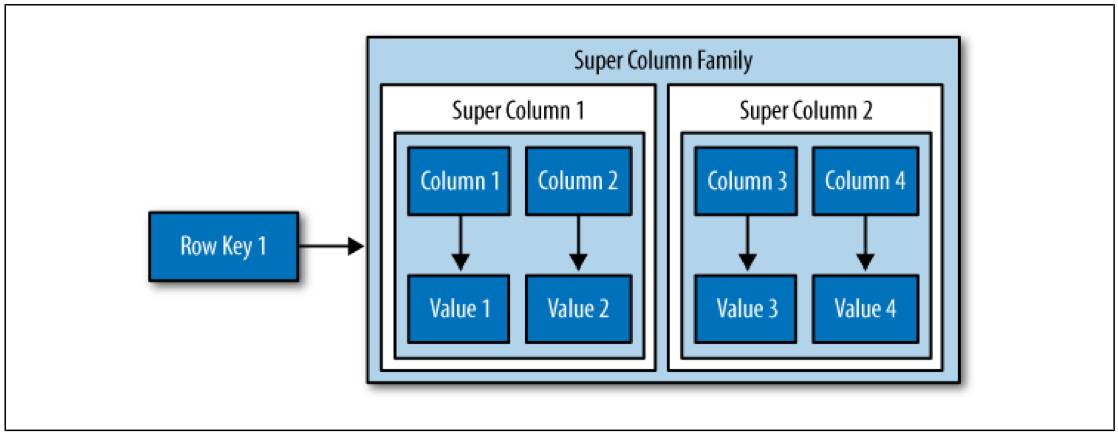
Keyspaces:键空间是 Cassandra 的数据容器,可以理解为关系型数据库中的数据库(Database)。对于一个 Keyspace 来说,包括定义每行数据的复制节点数目、定义在一致性哈希环中某个节点的替换策略、列族(Column Families)等多个概念。
列族:列的容器,它的结构像是一个四维哈希表,[Keyspace][ColumnFamily][Key][Column]。
列:一组键值对。
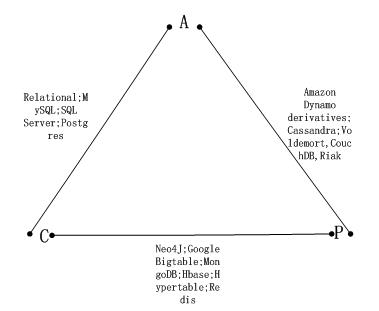
在 CAP 原则(又称 CAP 定理,指的是在一个分布式系统中,Consistency 一致性、Availability 可用性、Partition Tolerance 分区容错性,三者不可得兼)上,HBase 选择了 CP,Cassandra 则更倾向于 AP,但是其实 Cassandra 的一致性是可以调节的,并不是固定就是最终一致性。具体数据库对应的 CAP“站队”情况,大家可以看下面这张图:
V0.6:2010 年 4 月,成为 Apache 顶级项目之后的第一次发布版本。包含特性:
与 Hadoop 集成,允许通过 MapReduce 方式从 Cassandra 读取数据
集成行缓存,减轻 Cassandra 对于其他缓存技术的依赖
V0.7:2011 年 1 月,包含特性及优化点:
二级索引,允许在非主键字段上构建索引
支持规模较大的行设计,可以包含最多 20 亿个列
支持在线模式改变,包括在线集群环境下增加、重命名、移除 KeySpaces 和列家族
通过每一列的 TTL(time-to-live)特性可以设置列的过期时间
引入 NetworkTopologyStrategy,支持多数据中心部署,允许 KeySpace 跨数据中心的副本配置
配置文件从 XML 转为更可读的 YAML 格式
V0.8:2011 年 6 月,这是一次较大的升级发布,包含特性:
加入了一个新的数据类型 -Distributed counters,用于计数器的自增 引入 sstableloader 工具,支持批量导入数据
引入堆外行缓存,允许 JVM 堆内存以外的本地内存可供使用
允许多线程执行并行压缩,对 SSTable 的压缩能力进行限流
改进内存配置参数,允许更灵活地控制 memtables 的大小
V1.0:2012 年 10 月,该版本后很多厂商开始在生产环境使用 Cassandra。包含特性:
CQL 改进了几处,包括更改表和行的能力、支持计数和 TTL、获取计数等
压缩策略开始支持多种,提供了更快地读写速度支持
压缩 SSTable 文件,基于表级别进行配置
V1.1:2011 年 4 月,包含特性:
CQL3 增加 timeuuid 类型,支持采用组合主键方式创建表
支持“order by”进行数据排序
支持通过 cqlsh 工具导入和导出 CSV 文件
允许数据以表的形式存储在 SSD 或者磁盘上
Schema 以表的形式存储在 system
keyspace 允许配置缓存大小
引入基于行级别的隔离,防止在多个列被更新或写入的时候出现脏读现象
V1.2:2013 年 1 月,包含特性:
CQL3 新增集合类型(sets、lists、maps),新增二进制协议用于替换 Thrift
虚拟节点支持集群内跨节点分布数据,提升新增或替换节点时的性能
增加追踪方式,允许客户端查看节点之间的读和写交互过程
所有数据结构都被从 JVM 堆内存转移到了本地内存
V2.0:2015 年 6 月,这个版本具有里程碑意义,它不仅大规模提升了性能,而且解决了很多长达 5 年的技术债。包含特性:
新增支持 Paxos 协议的轻量级交易
CQL3 的改变包括针对 ALTER 命令的 DROP 语义支持,新增条件模式(IF EXISTS、IF NOTEXISTS),允许在主键字段上创建二级索引
运行时需要采用 Java7
引入针对写操作的触发机器,触发可以在任何 JVM 语言中实现
V3.0:2015 年 11 月,这个版本开始采用 Intel 发明的“tick-tock 发布模型”,即在短时间内对系统架构进行变更,所以 V3.0 版本对于 Cassandra 来说,做了一定程度上的架构变更,修复了之前的很多缺陷,更加适用于现代高性能、高可用性数据库需求。包含特性:
重写存储引擎代码,更加贴合 CQL 结构
新增物理视图(也叫全局索引)
正式基于 Java8 编译和运行
移除基于 Thrift 的命令行接口(CLI)
Cassandra 是无中心化的,每一个节点都可能担任临时协调者角色,也可能担任数据备份角色,这也意味着所有节点没有差异,也不会存在差异,因为所有行为都是按照规则约束的随机行为。
为了支持无中心化和分区容错,Cassandra 使用 gossip 协议允许每个节点追踪集群里其他节点的状态信息。
Gossip 协议(也叫八卦协议)通常假设在大型、无中心化的网络系统中容易出现网络故障,也被用于分布式数据库内的自动备份机制。本身它的名称就来源于人类的八卦行为,你可以和任何人交换互相感兴趣的信息。Gossip 比较适合在没有很高一致性要求的场景中用作信息的同步。信息达到同步的时间大概是 log(N),这个 N 表示节点的数量。Gossip 中的每个节点维护一组状态,状态可以用一个 key/value 对表示,还附带了一个版本号,版本号大的为更新的状态。
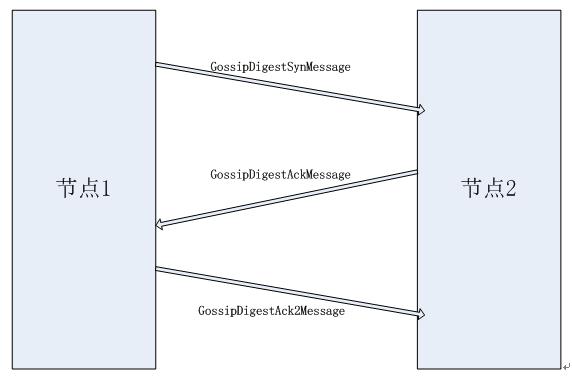
以下是 Gossip 的工作流程:
每一秒钟,gossiper 会随机选择集群中的一个节点并初始化 gossiper session。每一轮 gossip 需要三条信息。
gossip 初始器向它自己选择的朋友(其他节点)发送 GossipDigestSynMessage。
当这个朋友收到这条信息,返回一条 GossipDigestAckMessage。
当初始器从这个朋友收到 ack 信息,它会向这个朋友发送 GossipDigestAck2Messae 去完成一轮 gossip。
如果我们从代码层面来理解,Cassandra 源代码里通过 Gossiper 类实现 gossip 协议,Gossip 每秒都会自动运行,以下代码会定时启动 GossipTask 类,GossipTask 是位于 org.apche.cassandra.gms.Gossip 类下的一个内部类,这个类负责管理本地节点的 gossip。当一个服务节点启动后,这个类把自己注册到 Gossiper,用以接收终端状态信息。

GossipTask 在 Gossip 启动后并不会立即运行,阻塞在 listenGate 这个变量上,当 Gossip 服务调用 listen 时才开始运行,如下代码所示:

接下来,首先更新本节点的心跳版本号,如代码所示:

然后构造需要发送给其他节点的消息 gDigests,如代码所示:

接着,从存活节点中随机选择一个节点发送、从失效节点中随机选取一个发送。如果当前存活节点数小于种子数,向其中一个种子节点发送消息,如代码所示:
最后一步是检查节点状态,如果节点刚收到消息,还没有来得及处理(收到时间小于 1 秒内),那线程会睡眠 100ms,用于处理消息。
Cassandra 中,Token 是用来分区数据的关键。每个节点都有一个唯一的 Token,表明该节点分配的数据范围。节点的 Token 形成一个 Token 环。例如使用一致性 Hash 进行分区时,键值对将 genuine 一致性 Hash 值来判断数据应当属于哪个 Token。
根据分区策略的不同,Token 的类型和设置原则也有所不同。Cassandra(V3.10 版本)本身支持四种分区策略:
Murmur3Partitioner:这个是默认的分区器,它是根据 Row
Key 字段的 HashCode 来均匀分布的,这种策略提供了一种更快的哈希函数。
RandomPartitioner:这个分区器也是随机分区器,基本特性和 Murmur3Partitioner 类似,只是通过 MD5 计算哈希值,可用于安全性更高的场合。
ByteOrderedPartitioner:采用的是按照 Row Key 的字节数据来排序,这个分区器支持 Row Key 的范围查询。
OrderPreservingPartioner:这个分区器也是支持 Row Key 范围查询的。它采用的是 Row Key 的 UTF-8 编码方式来排序。
Cassandra 采用一个叫做 snitches(告密者)的办法决定集群内部每个节点的相对主机距离,用来决定哪一个节点被用来读和写。Snitches 收集整个网络拓扑信息,这样 cassandra 可以有效地路由请求。
当 Cassandra 发起一个读请求,它需要通过设定的一致性级别与几个备份交互。为了提供读请求的最大速度,Cassandra 选择一个单一的副本用于整个对象的查询,并且要求额外的副本执行 hash 值,用于确保拿到请求数据的最新版本。Snitch 的角色是去帮助确认哪个副本会最快地返回,并且这个副本需要包含查询的所有数据。
Cassandra 当前针对不同的网络架构方案已经提供了多种 Snitch 算法,每一个 snitch 实现了 IEndpointSnitch 接口。当前 Snitches 按实现分为三种:
SimpleSnitch:这种策略不能识别数据中心和机架信息,适合在单数据中心使用;
NetworkTopologySnitch:这种策略提供了网络拓扑结构,以便更高效地消息路由;
DynamicEndPointSnitch:这种策略可以记录节点之间通信时间间隔,记录节点之间的通信速度,从而达到动态选择最合适节点的目的。
这篇文章主要是针对 Cassandra 初学者,首先介绍了基本概念、关键定义,并对 Cassandra 直到 V3.0 版本的整个发布过程做了简短总结,接着重点针对无中心化实现机制,特别是通信消息机制、节点数据存储信息统计机制等做了一些讨论。受限于篇幅,后续会专门写一篇文章针对 Tombstones、Bloom Filters、SEDA 这三个概念进行深入解释。
作者介绍
今日荐文
测试已死?我看未必!
以上是关于Cassandra 初学者指南的主要内容,如果未能解决你的问题,请参考以下文章
DSE (Cassandra) - int 数据类型的范围搜索