每秒上百万次的跨数据中心写操作,Uber是如何使用Cassandra处理的?
Posted 互联网架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每秒上百万次的跨数据中心写操作,Uber是如何使用Cassandra处理的?相关的知识,希望对你有一定的参考价值。
相关阅读:


在现在这个时代开发者总是要做出许多艰难的选择。我们是不是该把程序全部署在云上?选哪个云?会不会太贵?怕不怕用上就脱离不开了?或者是不是该将云上和自建两种方式结合,精心打造出自己的混合型架构?或者还是为了避免由于没能达到50%毛利润的目标而被董事会纠结,索性不要上云,全部自建?
Uber的最终选择就是自建,甚至更进一步,他们是把两个非常强大的开源模块拼接在了一起,打造出了他们自己的系统。需要的就是一种让Cassandra和Mesos可以一起工作的方法,而这正是Uber做的。
对于Uber来说做这个决定并不是那么困难。他们现金流非常充裕,所以能够请得到顶尖的人才,可以获得所需要的最好资源,以此来创建、维护以及更新这样复杂的系统。

而且,如果你想让交通运输对于任何地方的任何人都非常可靠,你就要非常高效地利用自己的资源。所以才需要使用类似Mesos这样的数据中心操作系统。据统计数据显示,在相同的服务器集群上复用多种服务可以帮你节约30%的服务器,这也就是节约了成本。选择Mesos的原因也是因为Uber的需求已经是要运行上万台服务器的集群,而在当时Mesos是唯一被证实能满足这个需求的产品。Uber做的系统总是规模很大。
还有没有别的更有趣的发现?
可以在容器中运行有状态的服务。Uber发现把Cassandra直接运行在服务器上,与把它运行在用Mesos管理的容器中相比,两者几乎没有什么性能差别,只有5-10%的损耗。
性能看起来不错,平均读延迟13ms,写延迟25ms,99%的测试数据都很令人满意。
对他们最大的集群来说可以支持每秒超过一百万次写操作,以及数十万次读操作。
灵活性比性能更重要。在这样的架构下Uber获得了灵活性。在集群之间运行和分担负载都不在话下。
以下是谈话摘要:
系统最早期
在服务之间静态分配服务器。
比如,50台服务器供API专用,50台供存储用,等等,而且它们之间并不重合。
现在的系统
准备在Mesos上面运行所有的东西,包括Cassandra和Kafka之类的有状态的服务。
Mesos是一种数据中心操作系统,允许你针对数据中心来编程,就象是一个资源池一样。
在当时Mesos已被证实可以运行在数以万计的服务器上,这也是Uber的需求之一,所以他们才选了Mesos。现在Kubernetes可能也能符合这个要求。
Uber自己构建了名为Schemaless的基于mysql的分布式数据库,也就是说Cassandra和Schemaless将是Uber的两大存储选择。现有的基于Riak的系统都会迁移到Cassandra上。
单机服务器上可以运行不同种类的服务。
统计数据表示,在相同的服务器上复用服务可以让总的服务器需求减少30%。这个数字是Google用Borg做的实验中总结出来的。
比如,如果一种服务会消耗非常多的CPU,那它就可以和另一种使用非常多存储或内存的服务共处得很好,它们两个可以在相同的服务器上运行。就提高了服务器使用率。
Uber现在已经有了约20个Cassandra集群,计划在将来可能会有100个。
灵活性比性能更重要。你要能非常方便地管理这些集群,并在上面做各种操作。
为什么在容器中运行Cassandra,而不是直接在裸服务器上运行?
目标是存储几百个G的数据,还希望它们能跨数据中心在多台服务器之间复制。
也希望在不同的集群之间做到资源隔离和性能隔离。
在一个共享集群中达到上面所有目标是非常困难的。比如,如果你的Cassanra集群已经超过了1000个节点,那就难以扩展了,或者会在不同集群之间产生性能的干扰。
生产环境

Mesos背景知识
Mesos将CPU、内存和存储从物理服务器上抽象出来。
你将不再针对单台服务器,而是要针对一个资源池来编程。
线性扩展。可以运行在上万台服务器上。
高可用。使用ZooKeeper在配置好的复本内部做选举。
可以在Mesos容器内部运行Docker容器。
可插拔式资源隔离。Linux上有Cgroup来做内存和CPU的隔离器,还有Posix隔离器。这些都是不同的操作系统上做资源隔离的方法。
两级调度。Mesos代理把资源分配给不同的框架。框架再在内部调度自己的任务来使用这些资源。
Apache Cassandra背景知识

Mesosphere + Uber + Cassandra = Dcos-Cassandra-Service
Uber和Mesosphere合作写出了mesosphere/dcos-cassandra-service——一个自动化服务,可以很容易在Mesosphere的数据中心及操作系统上自动化部署服务。
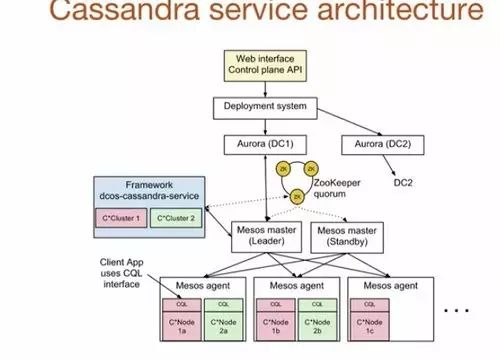
顶层是Web接口或控制层的API。你定好你需要多少个节点、需要多少个CPU、写好Cassandra配置,然后提交给控制层API即可。
Uber部署系统的底层是Aurora,它是专用于运行无状态服务的,用于启动dcos-cassandra-service框架。
在例子中dcos-cassandra-service框架有两个与主Mesos交互的集群。Uber在系统内使用了五个Mesos主,并用ZooKeeper完成选主操作。
ZooKeeper也用于存储框架元数据:哪些任务在运行、Cassandra的配置、集群健康状况等。
Mesos代理运行在集群的每一台服务器之上。代理向Mesos主提供资源,主再把它们分配给具体的请求者。框架可以接受或拒绝分配给它的资源。在一台机器上可能运行多个Cassandra节点。
用的是Mesos容器,而不是Docker容器。
要覆盖掉五个默认配置(storage_port, ssl_storage_port, native_transport_port,rpcs_port,jmx_port),这样就可以在一台机器上运行起多个容器了。
使用了持久卷,这样数据就可以保存在沙箱目录之外了。如果Cassandra出了故障崩溃了或者重启了,数据仍然在持久卷上,还可以恢复出来。
动态预订技术用于保证在重新启动一个失败了的任务时,是有资源可用的。
Cassandra服务操作
Cassandra有一个种子节点的概念,可以在新节点加入时启动一个进程来把数据迁移过去。在Mesos集群中创建了一种定制的种子提供者,在想自动替换Cassandra节点时可以启动它。
Cassandra集群中的节点数可以通过一个REST API来增加。它会启动新增节点,分给它种子节点,再启动其它的Cassandra守候进程。
所有Cassandra的配置参数都是可改的。用了API,死掉的节点就可以被替换掉。
要在副本之间修复数据并同步出去。修复是一个一个节点按主键去修的。这种操作不会影响性能。
清除操作会删掉不需要的数据。如果有新节点加入,部分数据被移到新节点上了,那旧节点上就要执行清除操作来删除已经移走了的数据。
多数据中心之间的数据复制可以通过框架配置。
多数据中心支持
每个数据中心都有单独安装的Mesos。
每个数据中心都有框架的独立实例。
框架之间会相互通信,并周期性地交换种子。
这就是所有Cassandra需要的东西。通过启动另一个数据中心的种子进程,节点就可以学到各个节点的拓扑、数据等。
在数据中心之间轮询ping延迟是77.8ms。
50%的异步复制延迟是44.69ms,95%是46.38ms,99%是47.44ms。
调度器执行
调度器执行被抽象成了计划、阶段和块等。调度计划下面有不同的阶段,一个阶段有不同的块。
调度器执行的第一阶段是同步,它会找到Mesos,了解都运行了什么。
还有部署阶段,会检查配置中的节点是不是都已经存在了,并按需要部署它们。
一个块表现为Cassandra的节点描述。
还有其它阶段:备份、恢复、清理、修复等,取决于调用的是什么REST服务。
集群可以以一分钟一个新节点的速度启动。
希望能优化到30秒启动一个新节点。
在Cassandra中不同的节点不能并行启动。
通过每个Mesos节点会分配2TB的磁盘空间,以及128GB的内存。每个容器分配100GB,每个Cassandra进程分配32GB堆空间(注意,这一点不太确定,细节可能有出入)。
用的是G1垃圾回收器,而不是CMS,不需要做什么调节就可以有非常好的延迟和性能。
裸服务器与用Mesos管理的集群之间的对比

-END-
欢迎关注“互联网架构师”,我们分享最有价值的互联网技术干货文章,助力您成为有思想的全栈架构师,我们只聊互联网、只聊架构,不聊其他!打造最有价值的架构师圈子和社区。
如想加群讨论学习,请点击右下角的“加群学习”菜单入群。
以上是关于每秒上百万次的跨数据中心写操作,Uber是如何使用Cassandra处理的?的主要内容,如果未能解决你的问题,请参考以下文章