数据库内核杂谈 - 数据库优化器(下)
Posted CTOA首席技术官领袖联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库内核杂谈 - 数据库优化器(下)相关的知识,希望对你有一定的参考价值。
作者简介:
顾仲贤,现任Facebook资深架构师
专注于数据库,分布式系统,数据密集型应用后端架构与开发。拥有多年分布式数据库内核开发经验。发表数十篇数据库最顶级期刊并申请获得多项专利。对搜索,即时通讯系统有深刻理解。爱设计爱架构,持续跟进互联网前沿技术。
个人经历: 2008年毕业于上海交大软件学院;12年,4年时间完成在美国加州大学戴维斯分校的学习并获得计算机硕士,博士学位;13-14年任Pivotal数据库核心研发团队资深工程师,开发开源数据库优化器Orca;共发表4篇相关论文(总引用近100)并获得相关专利;15-16年追随原Pivotal总监一同参与创立Datometry,任首席工程师,负责全球首家数据库虚拟化平台开发;17年至今就职于Facebook任资深架构师,领导重构搜索相关后端服务及数据管道; 管理即时通讯软件WhatsApp数据平台负责数据收集,整理,并提供后续应用。
◆ ◆ ◆ ◆ ◆
欢迎阅读新一期的数据库内核杂谈!上一期我们介绍了优化器的大概并且讲解了一系列通过语句重写来对查询进行优化的方法。文末也留了一个坑:当语句中涉及到多个表的join时,优化器该如何决定join的顺序(join ordering)来找到最优解呢?这期,我们接着这个话题往下说。
答案就是,优化器也只能尽力而为。上一期我们提到过n个表的join搜索空间高达4^n,理论上只有穷尽搜索空间,才能保证找到最优解。但即便有时间和能力穷尽搜索空间,也未必能找到最优解(此为后话,暂且不表)。因此优化器的主要职责是,在资源限制内,这里资源可以是计算资源或者优化时间,找到尽可能足够好的执行计划。
启发式算法(Heuristic approach)
4^n的搜索空间实在太大了,首先要做的就是,减小搜索空间。数据库的先贤们,想到了应用启发式算法(heuristic approach)来降低搜素空间。比如,最早的Volcano Optimizer里,就提出了对于Join-order,只考虑left-deep-tree,即所有的右子树必须是一个实体表。可能解释起来不太直观,对应下面三张不同的join-order的树形结构,就一目了然了。
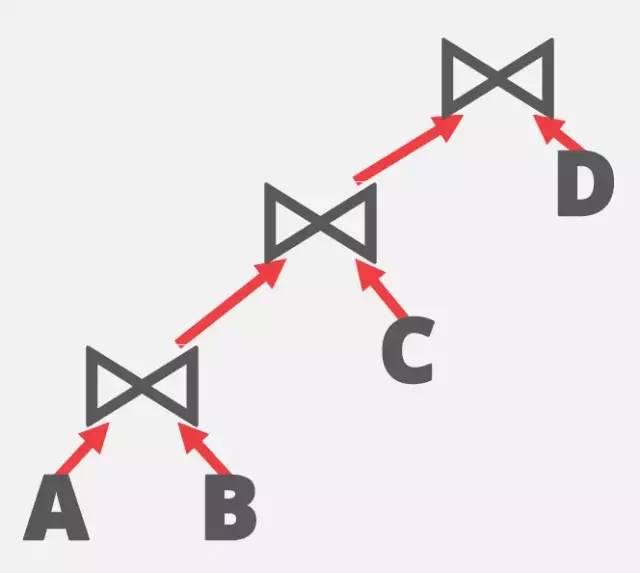
left-deep-tree
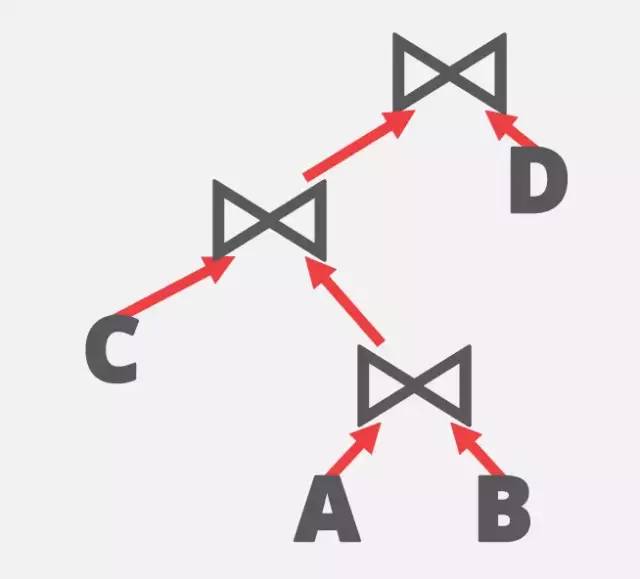
bushy-tree 1
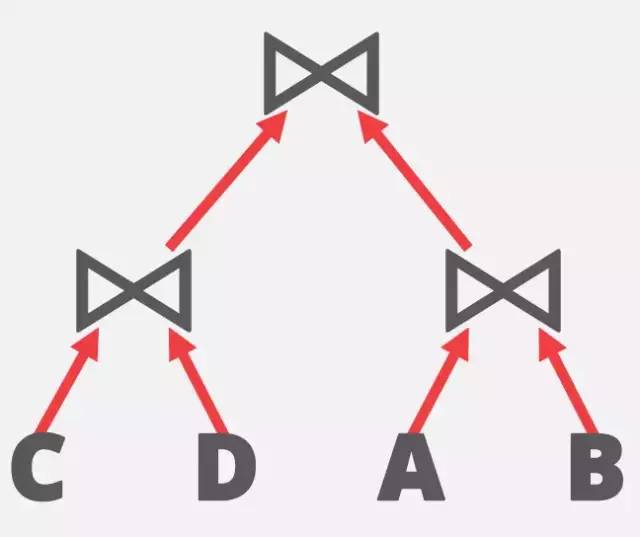
bushy-tree 2
其中图1就是left-deep-tree,图2和图3称为bushy-tree。那为什么只选择left-deep-tree?要知道,即使是left-deep-tree,搜素空间也有n!。我自己的理解是结构比较简单,执行计划也很直观:左边的表不断和右边的表join生成新的intermediate表(中间表),然后不断递归。在讲join实现的那章时,我们提到过,大部分情况下都会使用HashJoin。如果能够使得左边的result set一直很小,从而建立的Hash表能一直存放在内存中的话,对于全部右子树的表,只要进行一次全表扫描,即可得到最终结果。因此,右子树的table order就不是特别影响运行时间了(因为总是得至少进行一次全表扫描的)。这种情况下,已经算是很优的执行计划了。
说完了优点,再来看看left-deep-tree有什么不好的地方?那就是不能同时执行多个join。如果按图3中的bushy-tree 2,那A和B, C和D可以同时进行join。对于现在服务器配备多个CPU和大内存作为计算资源,考虑bushy tree,肯定是会有更多的优化可能的。反之,也可能因为早期的服务器并没有那么多计算资源,本来也并不考虑对一个SQL查询进行并行执行,因此采用left-deep-tree的heuristic,也就说得通了。
因此,left-deep-tree的join ordering优化关键在于能够让左边的结果集, 从一开始的叶节点以及后续的所有intermediate result越来越小,最好能一直fit in memory,这样就能保证所有的右子树表只需要进行一次全表扫描。要如何选择哪个表放在哪个位置呢?我们需要一些概率统计的知识。
Cardinality Estimation
Cardinality estimation,就是用来预测单个表的selection cardinality和2个表的join cardinality的技术。首先,简单介绍一些术语。
Selection cardinality: SC(P, R)
表示当predicate是P的时候,对于表R,最后大约会有多少条row输出。
举个例子,对于表student, 假设P为 major = 'CS', 相当于我们要计算下面这个SQL有多少row输出。
SELECT * FROM student WHERE major = 'CS';
要对输出进行预测,我们先要对表收集一些基本的元信息。有哪些信息呢?1)对于表student,首先需要知道总共有多少row;2)对于student表中的每个column,总共有多少个distinct value。你可能会想, 数据库是什么收集这些数据的呢?有些数据库会不定期地自动更新每个表以及每个column的统计信息,一般都还提供相关的语句来让数据库对某个表做元数据的统计:analyze TABLE语句。有了这两个信息,那我们怎么计算selection cardinality,再来看下面这个公式。
SC(P, R) = N_R * SEL(P, R)
这边SEL(P) 就是统计意义上每个row满足P的概率。那怎么计算SEL(P)呢。假设P很简单,只是单个column的equality,比如上述示例 major = 'CS'。基于distinct value的信息,我们假设V(major, student)总共有10个专业,在此基础上,我们进一步假设数据均匀分布,那major = 'CS'的概率就是10%, 即SEL(major = 'CS', student) = 10% 。如果N_R = 100。那我们就可以推算出SC(major = 'CS', student)约等于10条输出。是不是挺简单的,下面来看一些复杂的predicate的预测。
如果P并不是简单的equality join,比如 age != 30。假设 SEL(age = 30, student) = 90%, 可以通过negation推算出 SEL(age != 30, student) = 10%
如果P是age > 30呢?这时候就需要用到大于30的age还有多少个distinct value,我们假设age总共有10个distinct value,且大于30的还有4个值,再次基于数据均匀分布假设,就可以推算出SEL(age > 30, student) = 40%。
再来看更复杂一些的predicate,如牵涉多个column的。如果是P是age = 30 and major = 'CS'。这里,我们需要一个新的假设,朴素贝叶斯定理假设条件互相独立。则SEL(age = 30 ^ major = 'CS', student) = SEL(age = 30, student) * SEL(major = 'CS', student)。
如果predicate的condition是disjunction,如SEL(age = 30 V major = 'CS', student) = SEL(age = 30, student) + SEL(major = 'CS', student) - SEL(age = 30, student) * SEL(major = 'CS', student)。可以根据下图来推出这个公式:
disjunction
讲完了单个表的selection cardinality。那join cardinality呢?比如下面这句语句:
SEL * FROM R1, R2 WHERE R1.a = R2.a;
由于本人数学实在不好,就直接给出公式了:
JC(R1, R2, R1.a = R2.a) = N_R * N_S / max(V(a, R), V(a, S))
其中V(a, R)就是指对于表R中column a,一共有多少个distinct value。
刚刚我们通过示例讲解了许多计算selection cardinality和join cardinality的方法。但刚才所有的计算假设都是数据是均匀分布(uniformly distributed)。现实情况肯定不会这么容易,比如我们计算major = 'CS'的student,CS专业的学生肯定比其他专业学生要多一些。那有什么办法可以改进吗?另一种常见的对column的值分布进行统计的方法就是使用Histogram。Histogram呢,除了统计有哪些distinct value,还记录了这些value分别出现了几次,下图给出了一个Histogram统计的示例。
Histogram example
由于牵涉过多数学,我们就不展开了,有兴趣的同学可以参考wiki: https://en.wikipedia.org/wiki/Histogram.
Histogram通过存储更多的信息来统计更精确的数值分布。但很多情况下,统计并不需要那么精确。工程方面要在使用资源和准确性里找平衡。后来,又有大牛提出了HyperLogLog(https://en.wikipedia.org/wiki/HyperLogLog),是一种占用资源少,但能给出较为准确的近似结果的cardinality estimator。
总结一下,有了cardinality estimation,我们终于能预测哪两个表join后的cardinality比较小,可以用来决定join ordering了。但同时也发现,cardinality estimation给出的只是预测结果,这也是为什么文章开头的时候谈到,即使能够穷尽搜索空间,依然不一定能找到最优解的原因。因为预测的结果是有出入的,并且随着join变得更复杂, 层级越多,越往上的误差就越大。
Cardinality estimation仅仅是帮助决定了join ordering,相当于logical operator tree上,不同的表分别应该放在哪个位置。但对于每个logical operator,最后还需要变换成physical operator (物理算子)才算完成最终的优化。如,对于TableScan这个逻辑算子,它对应的physical operator有SequentialScan和IndexScan,应该用哪个?对于JoinOperator,到底是用NestedLoopJoin, SortMergeJoin,还是HashJoin呢?下面,我们介绍第二个关键技术。
Cost Model
Cost Model的主要思想是,对于每一个Physical operator,根据输入输出的cardinality,会被赋值一个cost(代价)。这个cost,通常情况下可以认为是执行这个operator需要的时间,当然也可以是计算资源。那如何计算这个cost呢?对于每个operator,都有一个cost formula(公式),这个公式根据输入输出的信息,最后能计算出这个operator的cost值。
还是配合示例来讲解:对于SequentialScan(全表扫描),它的cost formula我们定义成如下:
Cost = NumRowsInTable * RowWidth * SEQ_SCAN_UNIT_COST
解释一下这个公式,因为对于全表扫描,需要读取所有的row,因此读取时间大致正比于表的total row * 表的width。而最后的coeffficient SEQ_SCAN_UNIT_COST,可以想象成是一个虚拟的时间单位。
对于IndexScan呢?它的cost formula又长成什么样呢?区别于Sequential Scan,它不需要全表扫描,但对于从Index中读取满足条件的Row,需要回到原表中读取,相当于执行了random IO。因此,我们可以根据操作的实现,定义它cost formula如下:
Cost = SelectionCardinality * RowWidth * INDEX_SCAN_UNIT_COST
而这边,INDEX_SCAN_UNIT_COST可以认为是random IO的cost,所以它的值应该要比SEQ_SCAN_UNIT_COST要大很多。比如,我们假定SEQ_SCAN_UNIT_COST值为1,那INDEX_SCAN_UNIT_COST就可以设为100。先不管这样设是否准确。但有了cost formula的定义,我们就能计算每个physical operator在当前环境下的cost了。再来参考下面这个示例:
SELECT * FROM student WHERE major = 'CS';
现在假设,student表对major建有index,然后student表总共有10000个row,然后假定cardinality estimation给出的selection cardinality是500,即有500个CS学生。我们再假设width是10。分别把这些信息带入SequentialScan和IndexScan的公式可得:
SequentialScan Cost = 10000 * 10 * 1 = 100000
IndexScan Cost = 500 * 10 * 100 = 500000
在这种情况下,Optimizer就会选择SequentialScan。但如果查询语句变了,变为major = 'archaeology' (考古学),作为一个冷门专业,cardinality estimation预测只有10。再分别计算cost:
SequentialScan Cost = 10000 * 10 * 1 = 100000
IndexScan Cost = 10 * 10 * 100 = 10000
在上述情况下,optimizer就应该选择IndexScan。
那如何定义cost formula和coefficient的值呢?这确实是一个很难的问题。笔者曾经做过相关的research,cost formula是需要根据operator的实现来定义的。甚至一个operator,根据不同的执行环境,都会有不同的cost formula。cost formula意在去simulate真实执行下所花掉的时间。而对于coefficient,笔者当时提出的方法就是通过执行mini-benchmark来calibrate coefficient的值,因为不同的部署环境,网络条件和硬件资源,都会影响coefficient。当时对一些operator进行了测试,calibrate后,效果立竿见影,只可惜后来离开公司了,没能把这个research做完。
讲完了单个operator,我们再来看全局。对于一个logical operator tree,Optimizer要做的就是,当它变换成Physical operator tree后,所有的operator的cost相加(也可以是有权重的相加,假定多个operator可以并行执行,这边我们暂且不考虑这种复杂情况)后,使得total cost最小,这便是optimizer给出的最优physical execution plan。
你可能会觉得,似乎对于每一个logical operator, 选择哪一个physical operator是一个local optimization的问题。至少Scan operator看上去是这样的。其实并没那么简单。还记得我们说过index Scan带来的一个好处是什么吗?就是读取后的数据是有序的。有序是一个很好的属性,如果上层的operator对有序有需求,比如SortMergeJoin,或者SortGroupByAggregate,那原本需要排序的cost就被省去了。因此对于同一个operator,它的cost不仅仅和自己的cost formula相关,还和它的子节点的operator也相关。比如对于SortMergeJoin operator来说,它的两个子节点都是IndexScan, 或者是Sequential Scan会对它本身的cost产生影响,如果是sequential scan的话,排序的cost是需要计算在它的cost formula里的,但如果是index scan,那排序的cost就为0了。因此,计算每个operator的cost是一个global optimization的问题。假定,对每个operator,我们定义一个aggregated cost等于它本身的cost加上所有子节点的cost。那Optimizer要求解的就是使得root operator的aggregated cost最小的physical operator tree。是否有联想到什么算法了吗?global optimization? Bingo!就是dynamic programming。我觉得这可能是我工作中遇到的第一个真正使用DP解决的问题了吧:多阶段决策最优解模型;求解过程中需要多个决策阶段,每个决策阶段都会取决于最优子结构;并且,最优子结构属于重复子问题,因为会被多次使用到。上层无论是HashJoin或者是SortMergeJoin都会需要知道下层表的SequentialScan的cost是多少。因此我们需要memorize这个SequentialScan的cost。整个计算过程自顶向下递归,对于子问题memorize结果,最终我们就能计算出最小的root operator的aggregated cost, 以及它所对应的physical operator tree。这就是最后optimizer输出的physical execution plan。
总结
今天我们先从join ordering问题讲起,介绍了cardinality estimation技术,它通过预测selection cardinality和join cardinality来帮助决定join ordering。然后介绍了cost model来对每个对应的physical operator计算cost。最后通过dynamic programming来求解最小cost的physical operator tree,以此得到最终的physical execution plan。
终于,理论部分讲完了。这两期比较枯燥和深奥,但为了完整性,我觉得还是有必要的,今天就聊到这,下期再见。
以上是关于数据库内核杂谈 - 数据库优化器(下)的主要内容,如果未能解决你的问题,请参考以下文章