记实分享 | 自动化运维的基石:CMDB
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记实分享 | 自动化运维的基石:CMDB相关的知识,希望对你有一定的参考价值。
作者介绍

蒋君伟 广通软件 优云产品总监
IT运维领域的十年老兵,先后研发了网络管理、系统管理、CMDB、ITSM等产品,并成功建设了国内多个全国性的网络管理与运维管理项目。热衷于开源社区的技术推广与研究,喜欢捣鼓Emacs、Lisp与Python,实现过开源.Net SNMP协议栈,目前主要研究去中心化的大规模软件集群技术。
演讲正文


就像我们在过去看到的很多武侠书小说中描写的一样,每个侠客都有一个自己心目中的江湖,每个运维工程师也有他自己心目中的CMDB。你们理解的CMDB是什么呢?
台下回答1:对业务有价值的配置项目总和就是CMDB。
台下回答2:配置项属性以及配置项之间的关系,CMDB的建设往往不是独立的,服务于它的流程的。

我们整个运维领域技术是百花齐放的,我心目中的CMDB应该具备碎片整合的能力,能够把整个运维管理给盘活,把各个系统给打通,就像打通我们的任督二脉一样。
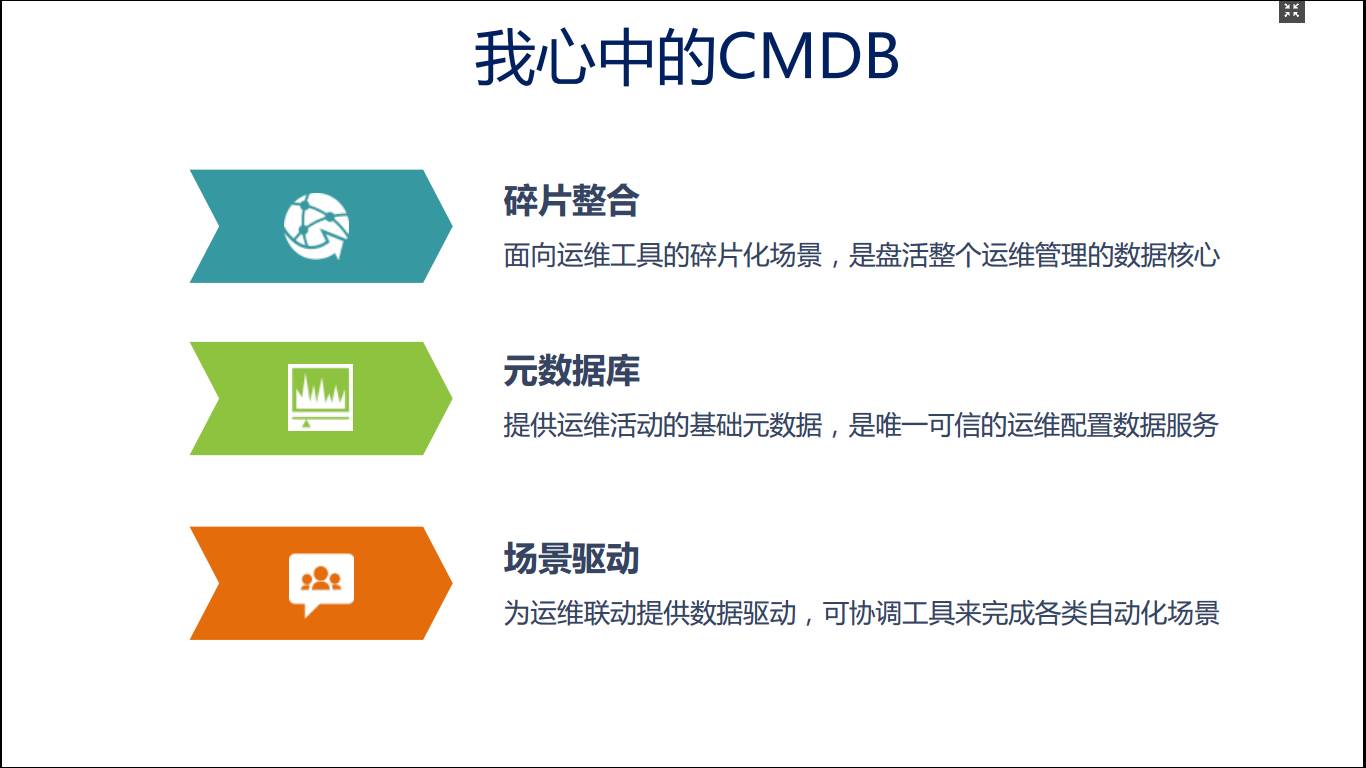
它应该是原数据,提供运维活动的基础信息;
它提供的数据也应该是可信的;
它应该是场景驱动,能够给运维的各种需求提供自动化场景支持;
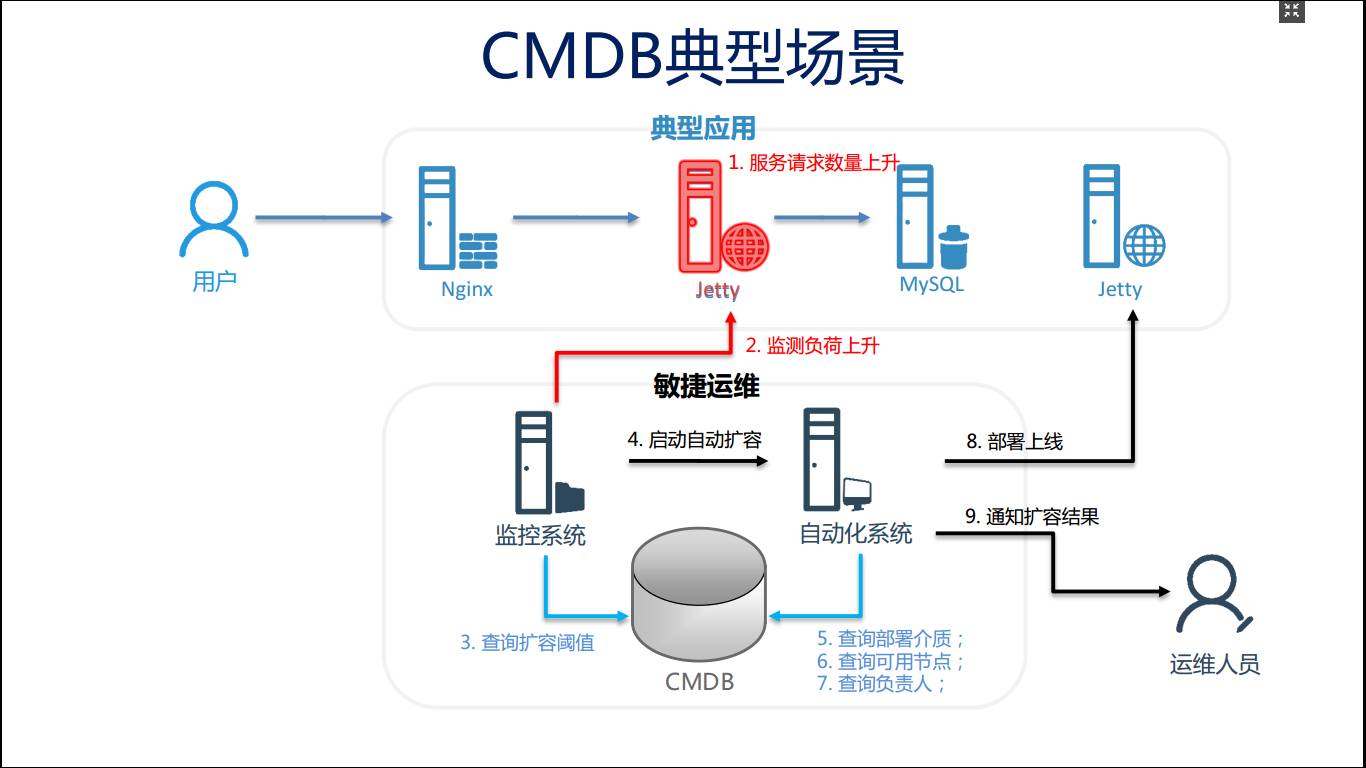
自动扩容和自动监测。nginx、Jetty、mysql,当用户的请求量增加的时候,服务请求的数量就会上升,监控系统马上会监测到负荷上升。
这个时候监控系统有一个问题需要决策:要不要去做弹性扩容?
这个时候可以通过CMDB去查扩容的阈值,并且启动自动化的系统去做扩容。
自动化系统里有很多信息是需要相互依赖的。比如说,它要知道扩容部署介质在哪里,有哪些可用的计算资源可以拿去扩容,同时做扩容的时候应该让哪些人知道,它最好还需要具备查询负责人信息的功能。
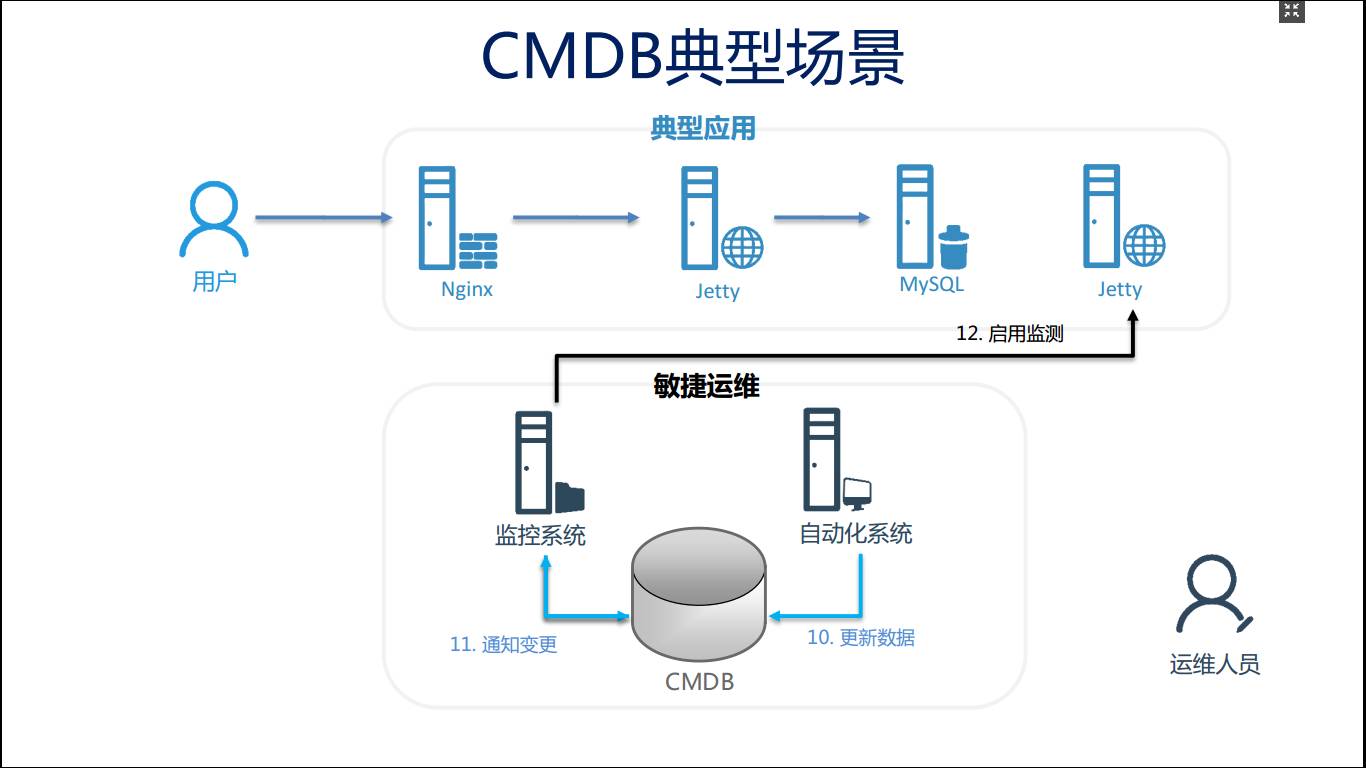
得到这三个信息之后,扩容这个Jetty,并且通知这个CMDB,通知到监控系统,监控系统立即将监控策略下发到新的节点。这样我们通过用CMDB就打通了监控系统和自动化系统。


很多客户为了建这个模型要不停地开会,多达两个星期。
原因:
建模的力度很难控制。大部分经常会犯的一个错误是“很多信息都想建模”,甚至有些客户连一个不重要的网络链路、内存条都会作为配置项,最后CMDB里产生了70%的数据是没有任何作用的。
缺少行业的参考。老外的思路跟我们国人有所不同,并且往往会做出一些很复杂的模型。
模型的调整很笨重。模型建好以后,由于CMDB系统做得不够灵活,模型的调整很笨重,经常有些CMDB是使用关系型数据库做的,最后导致想要做一些调整的时候经常要研发参与,做一次调整要两个人/日以上,在数据的录入阶段经常做调整,导致整个效率下降。

1. 目标驱动。持续迭代的方式推进,只实现当前目标需要的最小规模集合,只需要实现这个目标所需要的最小模型集合就够了。
2. 行业参考。寻求和借鉴行业最佳实践,我们很可能是拿到这个行业最后建设成功的模型。但是不仅仅是一下子学这个成功模型,就像“目标1”讲的一样,它应该是有一个演进路线,不要一口吃成一个胖子。
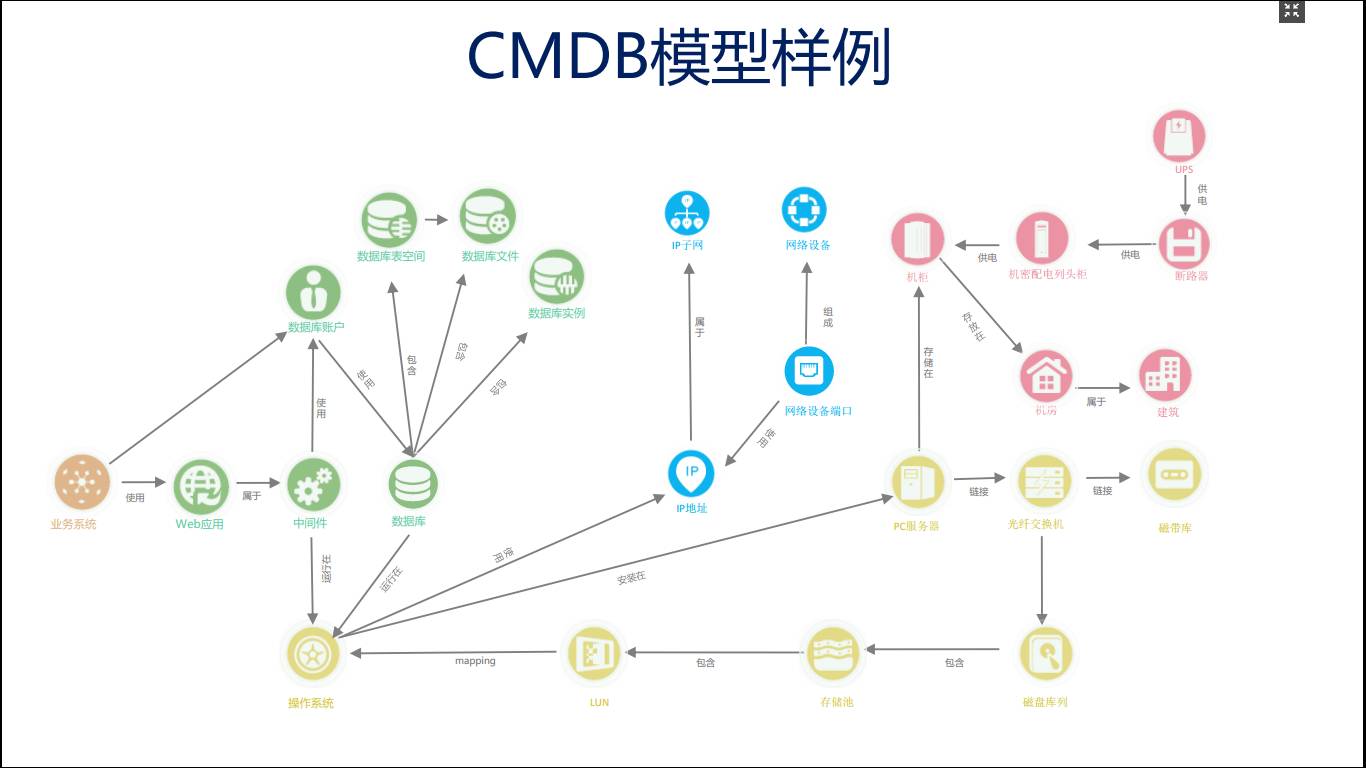
业务系统可能会依赖于其他的业务系统,业务系统的下一层需要图中的一些中间件,中间件数据库都是安装在下面一层的,比如说存储、服务器。
存储、服务器同时还会依赖网络的结构。
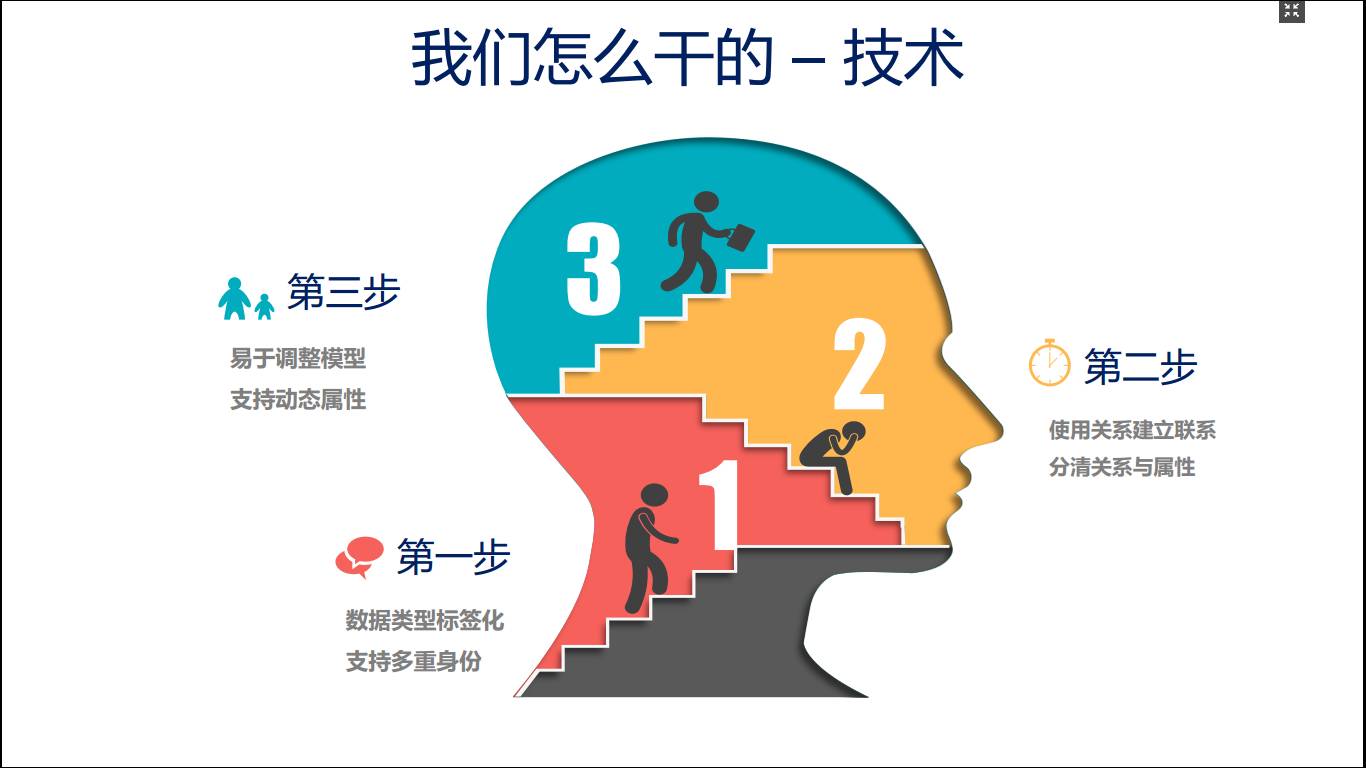
传统的CMDB往往是使用科学分类法的,给建模带来很大的挑战,有一些配置项就像动物界的四不象,放在这里不好,放在那里也不好。
第一步,数据类型要标签化,允许一个配置具备多重身份,给虚拟机打两个标签:计算资源、动态资源(通过哪个虚拟化云平台提供的)。
第二步,使用关系建立联系,分清关系与属性,在刚开始建模的时候搞不清楚后期配置项会有哪些联系,很多联系往往是你在用到了一些业务场景的时候才会出现。因此,我们应该建议大家尽量使用关系来建立联系。
第三步,整个技术层面要让CMDB易于调整模型,支持动态属性。

原因是:
人工录入,工作量很大,数据准确率低。
没有及时维护、数据过期。
数据来源多,存在冲突。
拿Windows2008来说,人为录入肯定就写一个Windows2008,但是自动化版本就会写一个内部版本号Windows6.1,这马上就出现冲突了。

确定定位。 确定CMDB作为唯一数据源,上下游数据不准确,应从CMDB为基础开始修正。
职权划定。 对于CMDB的配置项来说,比如谁提供的数据,谁就要负责维护数据,谁关心这个数据就应该订阅这个数据的变更,应该及时跟踪配置项数据变化的情况。
定期审查。 让团队对数据做一些定期的盘点,CMDB需要审查数据和生产环境是否符合。除了靠人,还需要靠一些自动化系统。
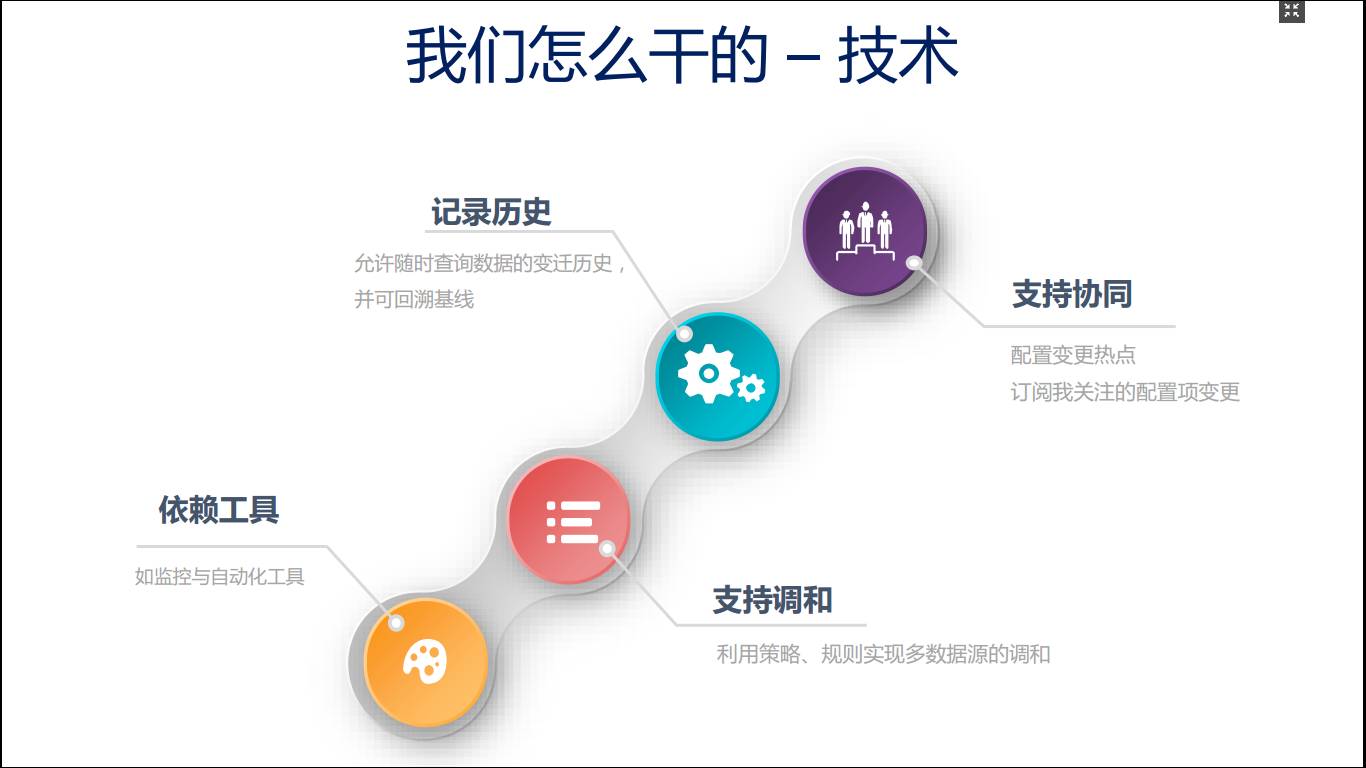
尽量依赖工具补充数据,而不要依赖人发现数据,工具是可信的,它的数据上一定要让它进来。
多个监控工具可能产生的一些数据是冲突的,这里要支持一些可以调和的规则,方便维护人员可以进行一些判断,比如说,Windows2008和Windows6.1冲突了,我应该可以看到这个数据分别是哪个系统提交上来的,我需要认可哪个数据,我可以做一个判断,系统应该能识别到这种规则。
记录变更历史,允许随时查询数据的变迁历史,并可回溯基线。
CMDB非常热的一件事是可视化和协同,通过可视化的手段,看到CMDB哪些配置上的变更是很多的,哪些配置被人使用和引用是很多的。支持配置项的变更通知。


1,有些客户为了上CMDB而CMDB,最后导致CMDB也只能当管个资源台站去使用,但是实际上我们更应该建设一个服务型的CMDB。
2,CMDB系统的开放性特别差,往往CMDB只能做成一个普通的数据库使用,提供的API也仅仅是读写的API。
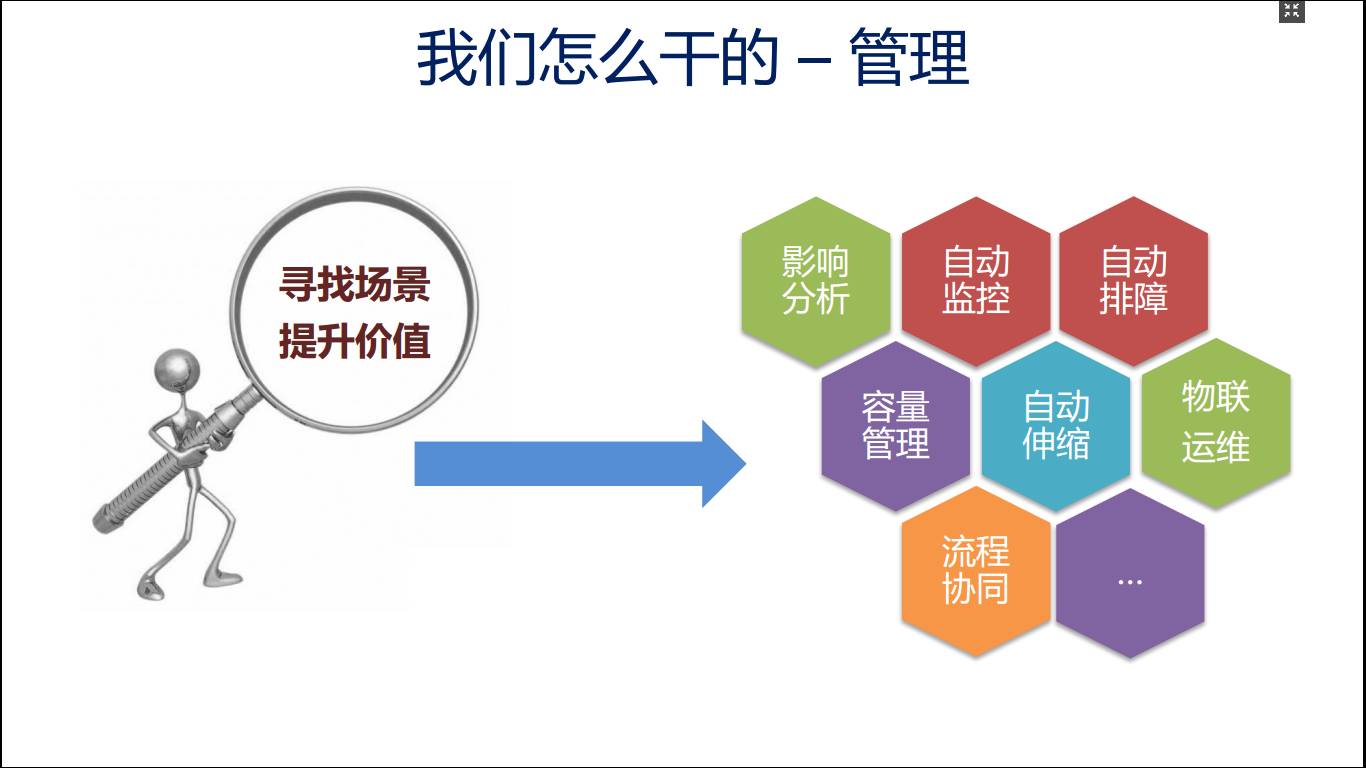
我们应该设法寻找CMDB的价值,把它提炼出来去使用。
影响分析:我们应该使用沙盘的方式,拿CMDB在沙盘上建立一次变更的演练,做变更的演练、故障的演练,能够发现问题;
自动键控: CMDB厂商变更的时候,让自动键控产生一些监测策略的下发;
同时可以做自动排障:容量管理,实现自动伸缩;
物联运维:我们可以把CMDB的数据做成二维码,进机房扫一下就能够知道这台机器最近谁做了变更,运维的历史是什么样的,这是非常有帮助的;
最后可以做流程协同、机房管理等等。
它应该具备关系推导能力,能够提取一些配置项跟哪些CMDB产生了关系,以及他们影响的方向;
支持全文检索,通过关键字就可以拉出匹配CMDB,并且用可视化的手段显示出来;
支持对第三方系统的通知;
支持事务沙箱,提交一批数据,让整批的数据形成完整的提交或者回滚;
版本对比,让我很方便地通过手机打开或者第三方系统打开;
WEB集成,大家经常用一些WA这样的命令去做一些页面的请求,CMDB的数据也非常适合用一些命令行去查询。
定义了最小可用的CMDB模型结构与规则,正确地维护起CMDB各类数据及其关系,提供开放友好的API服务,利用CMDB的数据玩转各种运维场景。
CMDB=模型+数据+API+场景,能消费起来的CMDB才是一个好的CMDB。
最后,非常感谢大家,谢谢!
以上是关于记实分享 | 自动化运维的基石:CMDB的主要内容,如果未能解决你的问题,请参考以下文章