去哪儿网的硬件自动化运维体系建设之路
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了去哪儿网的硬件自动化运维体系建设之路相关的知识,希望对你有一定的参考价值。

作者介绍

刘亮
去哪儿网高级运维开发工程师,分别在华中科技大学和中科院软件所进行本科和硕士学习,毕业后进入百度工作,主要围绕服务器工具研发,选型测试,交付流程优化等内容开展工作。14年底加入Qunar,负责硬件相关平台研发工作。目前主要集中在服务器自动化运维和网络设备自动化运维两个内容展开工作。
前言
很高兴在这儿分享一下我们去哪儿网在运维这一块的工作经验,我今天讲的题目是硬件自动化运维体系的介绍。今天我要讲的内容主要是分这四块:
背景概述
工作阐述
具体介绍
总结回顾
1、背景概述
首先说一下背景概况,我大致列了一下我们硬件的范畴。从数据中心机房的每一个机柜到最后每一个机柜上面具体的硬件设备,包括服务器、网络设备,具交换机路由器等等之类。这硬件范畴大致就是这四类了。

再更细一点,我们到每一个硬件设备,比如说服务器。

我们拆机看一看更细的力度,每一个硬件的配度包括CPU内存电源主管风扇等等,这些更细的配件也是我们运维的对象之一。我们的运维对象大到数据中心,小的到每一个硬件配电,这就是我们要谈的目标。
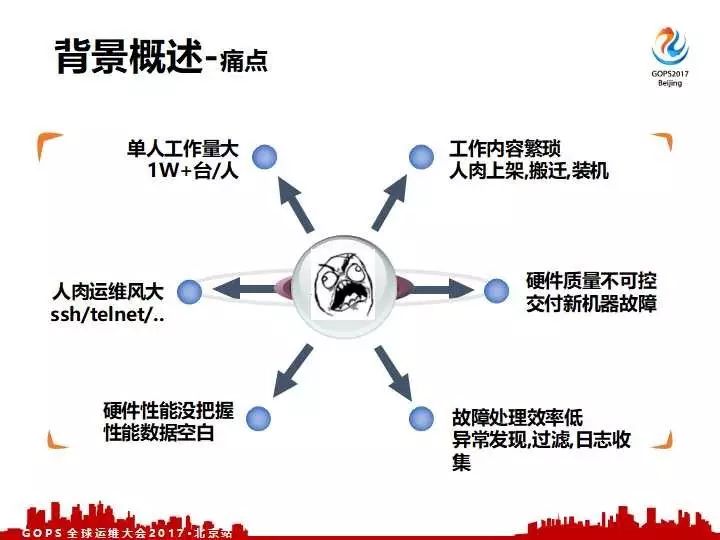
讲完了硬件我们就介绍一下没有做自动化之前,去哪儿网的痛点。首先面临的最大的一个问题,就是单人的运维工作量非常大,一个人负责上万台服务器的运维。其次每一台机器,我们运维工作都比较繁琐,包括上架、搬迁、装机、配置等等。
对于每一台硬件的质量我们是不可控的,批量到货的新机器质量是不是可靠,我们是没有办法来一台一台去检验。对于出现了故障的硬件我们的处理效率是很低的,包括筛选故障要对人肉的报修,其次对于线上业务出现异常,硬件性能是不是有问题,我们也是没有办法给他们一个确切的答复,因为我们在这一块硬件性能具体的数据上算是空白的。最后一个问题就是人肉运维风险很大,我们绝大部分都是直接登陆到机器上去跑命令和工具。

面对六大痛点我们要做自动化和智能化:第一个保证我们的运维安全,其次是保证硬件的质量可控,提高我们的硬件运维效率,最终达到降低我们运维成本的效果。
2、工作阐述
上面讲了一下我们的运维体系它是一个什么背景,它是在什么情况下我们要做自动化,接下来介绍一下我们运维的大致范畴。
第一个提一个核心的理念:硬件生命周期,管理对于不管是服务器还是网络设备等等。在我看来就是从选型、供货上架到最终报废下架是可以分为五个生命周期点。
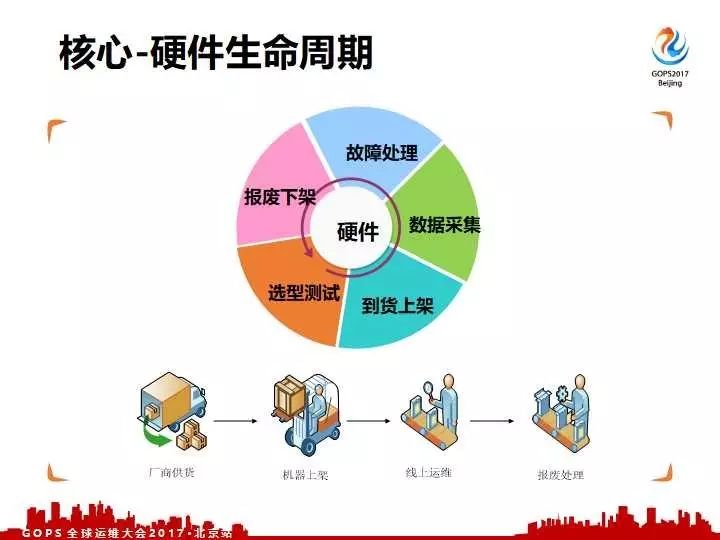
从开始选型测试-到货上架-数据采集展示,最后到我们的异常故障处理,实际上到我们的报废下架基本上分为这五个周期。我们运维的同学基本上都是围绕这五点展开,厂商供货到我们机器上架到我们线上运维下架处理。
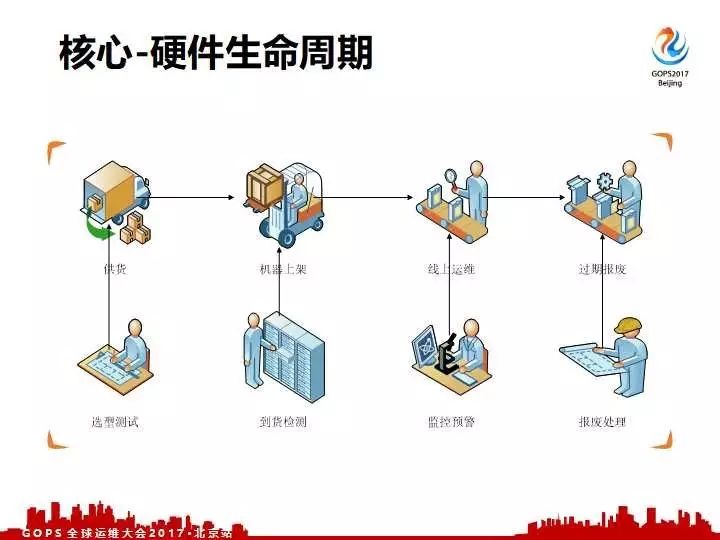
针对这四大块,我们分别可以做如下的工作来针对性的进行优化和测试到货检测,监控预警和报废处理。
3、具体介绍
大致介绍了一下我们围绕了哪一些内容来展开工作,现在对我们工作的一些具体实践细节来详细介绍一下。首先第一点我们的供货商每当有新的型号和新的硬件配置,会提前送给我们做测试。我们不得不面临一个残酷的现实就是供应商提供给我们的参考数据是有水分的。
往往供应商的数据会显示我们这一套新的硬件、新的型号可能有一个50%的提升,但实际上我们拿到样品测试的时候,往往可能就是5%。这不是一个很形象的比喻,但是大多数选型测试会碰到的一个,就是参考数据跟我们的实际测试数据是有较大的差距。

实际测试我们更看重什么呢?其实我们更看重的是一个性价比。

我们需要考虑一些细节了,比如说硬件的性能是不是越高越好?这不一定。比如说有的CPU性能非常高但是功耗也特别高,我们应用场景可能用不到那么高的性能。是不是每一个硬件越新它的性能越好呢?也不一定。我们要找到最适合我们应用场景的一个搭配,可能有的这个硬件并不一定要非常好甚至有的硬件它可能比较廉价,总之就是要找到合适的场景搭配。
再一个考虑一些其他的细节,我们在选型测试, bios 是不是设置最合适的呢? raid 卡、硬盘还有我们的系统是不是设置到呢,才有可能测试到真正的峰值情况。这中途免不了跟我们的供应商还有代理商要做一些交互,最终保证我们的实际测试是测到性价比最高的搭配,往往我们称这种搭配叫套餐。
总结一下就是我们的选型测试注重两个点。
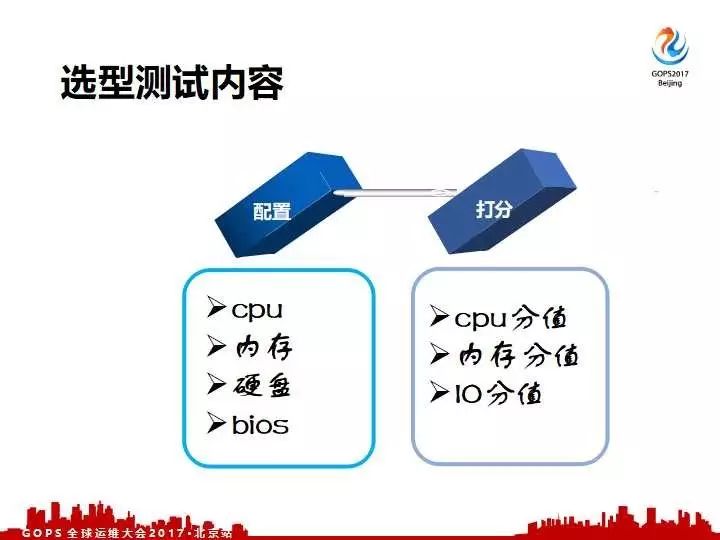
第一个点我们要获取选型测试的配置,我们要知道一台机器的核心配置,比如说CPU、内存、硬件、 bios 这都是基本的。第二点在获得这一套硬件配置之后,这一套硬件配置到底是什么水平?这都是虚的,真正落在实处的,这一套性能是不是有一个标准的峰值,就是打分系统。
这一套新的硬件套餐,我们可以给哪一些核心的关注点给他们评分,有一套稳定的科学评分系统给它做压测,必须获得我们需要关注的,比如说CPU分值、内存分值当然还有IO分值。最后对一套选型测试的机器,最终我们的产出其实就是一套配置对应的它的一套分值,这就是我们选型测试过程中的产出。
我们在选型测试定型之后,交给我们的采购下单,最后我们的供应商会批量供货,在供货过程中面对可能几百台、几千台,甚至一个星期上万台批量供货。我们的运维去核查或者随机抽查这都是不现实或者有隐患的。我总结一下批量新到货的机器可能要面临五大问题:
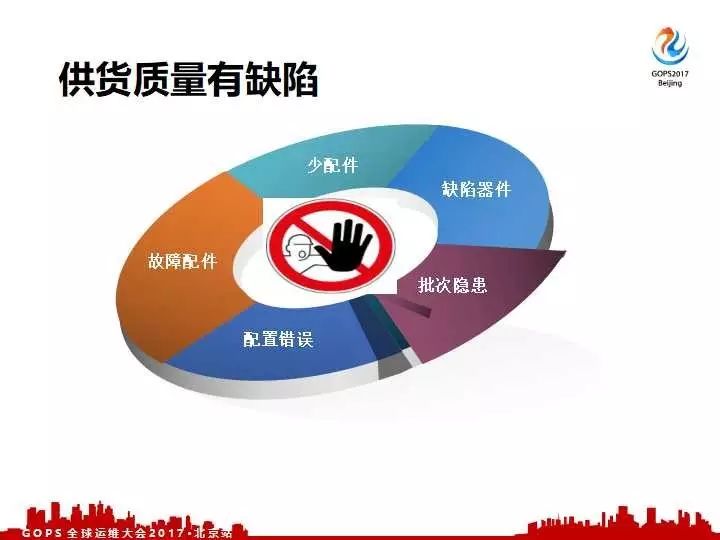
第一个少配件,可能由于工厂或者是说供应商的疏漏,会导致短斤缺两的硬件数量。再一个碰到有缺陷的元器件,我们配件的一些细小的元器件,由于天气的原因、工艺改进的原因会导致元器件有问题。
再一个就是机器批次隐患的,再一个就是收到的机器配置跟我们定型的配置它是不一样,配置是有问题的。最后一个新机器已经有故障,由于这运输过程中碰撞或者是搬迁或者是挪动,或者是人为非人为的因素导致硬件本身就已经有问题了。
面对这五大问题我们要保证我们供货的批次机器交付上线之前质量就是可靠。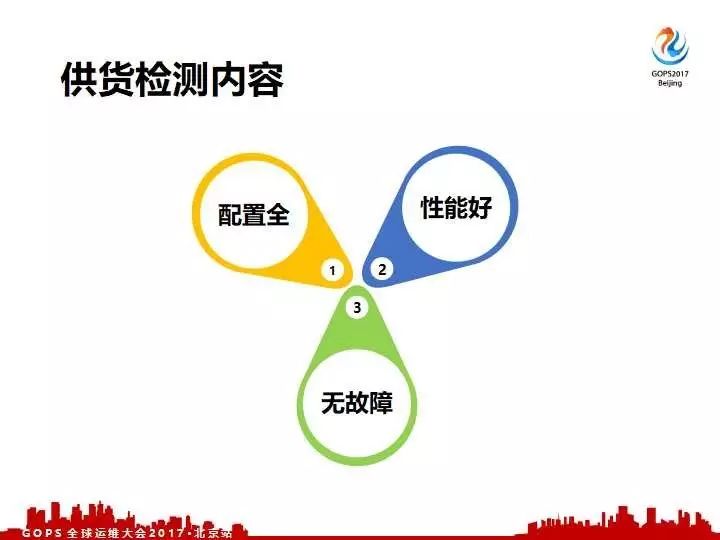
所以第一点配置跟我们测试定型配置是一模一样,再一个就是我们的性能要优异,不能因为一些问题导致机器实际性能达不到我们选型的要求。再一个就是要求我们的硬件没有故障,我们要保证这三点没问题才能交付应用使用。
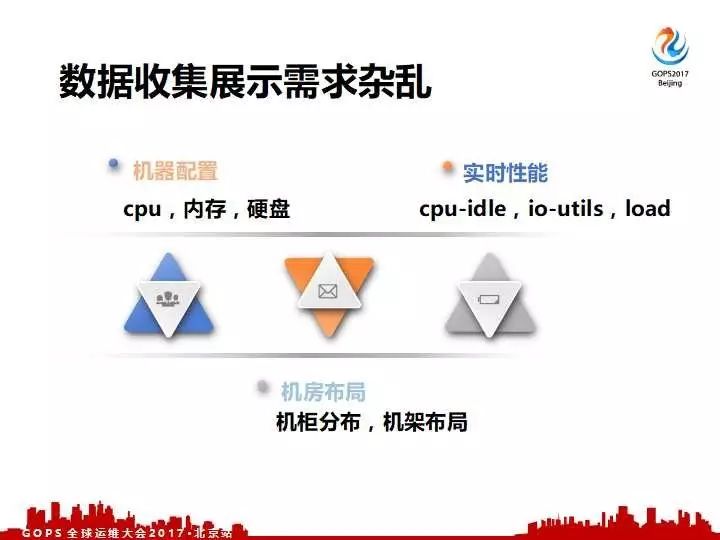
各个层次运维的需求数据,机房运维同学要求机房相关的数据,若干台机器在哪个机房、哪个机柜在几层,哪个机架上,每一个它的密度是怎么分布的?哪几个空位很大?再一个就是要求我们的机器运维知道机器的实际配置,机器厂商、型号,包括机器上有多少块CPU,CPU各个型号它的频率,它的物理核数等等,详细的信息机器运维同学需要知道,还有应用相关的需要知道。这机器在实际跑的时候,随着时序性能指标存在什么水平,是不是有CPU、IO使用率打满之类的。面对各种各样的数据需求我们就必须有一个完善的数据抓取、收集、展示的方案。
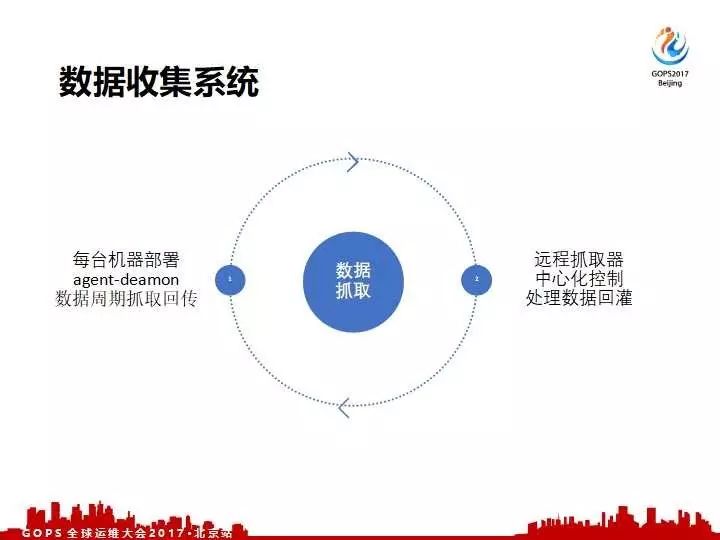
我们在具体实施的时候,是用一套互补的方案来解决数据抓取。一个本地抓取就是在每一台机器上抓取 Deamon 的数据周期回传给后端,同时对于一些通过这种方式无法抓取到的数据我们会通过远程抓取的,通过中心化的控制把我们的数据抓过来进行回灌。所以这一套互补的方式能够满足各个层次的需求。
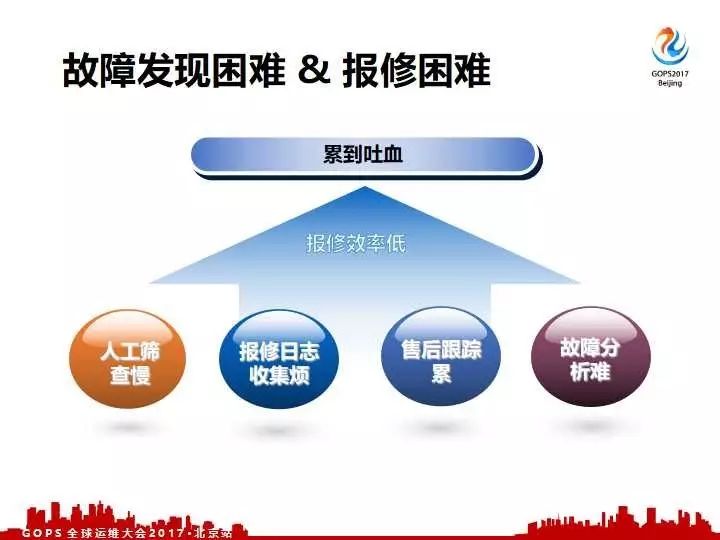
我们抓取到线上的实时数据,会面临着异常故障相关处理的问题。特别是我们服务器它是一个廉价的,是允许有故障的机器。因为我们提供7×24小时的线上高压力的服务,是不是线上会有大量的异常发现。我们之前是碰到几个问题,第一个就是我们每天有大量的异常报警发出来,这种大量的异常报警需要人为去筛,哪一些是真正需要马上报出来的,哪一些是需要我们关注并且需要人处理之后才报出来的,还有一部分是不需要关注的。
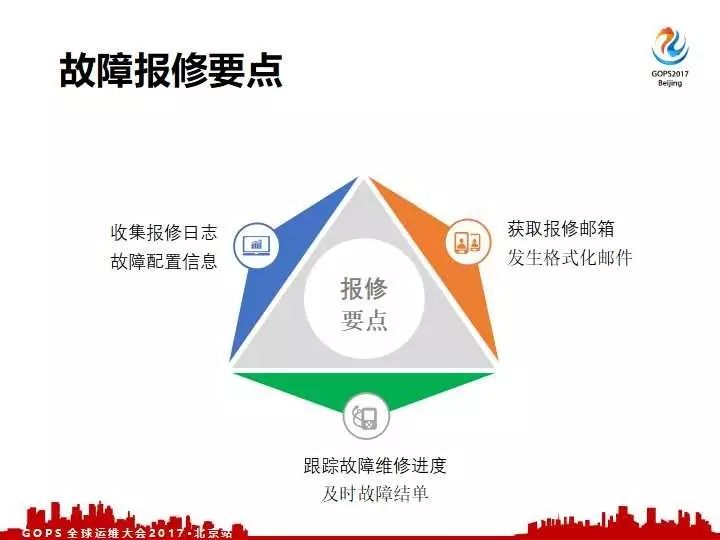
所以我们的人工筛查是非常慢,真正拿到了我们的故障机器之后报修也很麻烦的。因为去哪网是走代理商的方式,每一个代理商或者每一个供应商要求的报修日志格式都不一样,有的需要这种日志,有的需要那种日志。所以对于每一个报修的方案都需要找对应的方式去人工抓日志,生产格式化的邮件,当然包括一系列的信息,包括机器在那个机房在哪个机柜、机架,故障零件有SN的话我们都需要记录下来。这故障报出去之后,我们还需要跟业务线协调入室维修时间,对于维修不及时我们还要人工的提醒,把故障单进行结单,这些都是人工半人工的来做,都特别的耗时耗力,因此我们的指标同学累的不行。
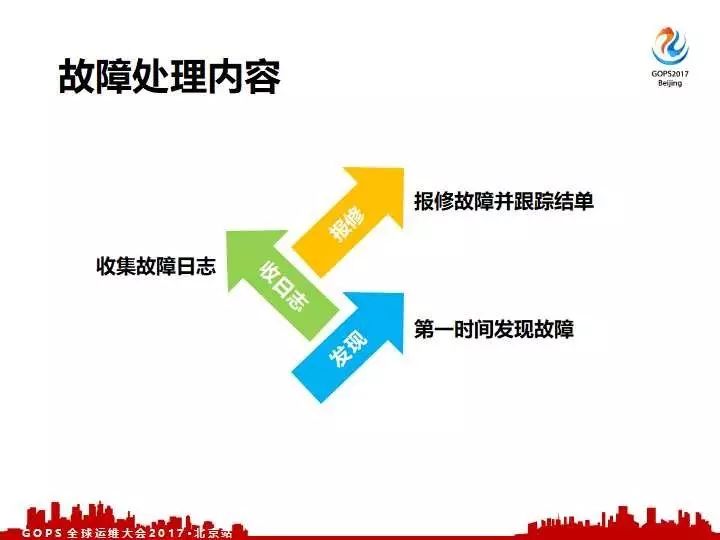
面对这么没有头绪的异常处理,我们是怎么来做的呢?首先先归纳一下具体要做哪一些点。第一个要及时的发现故障,对于大量的故障第一时间发现,什么是真正马上需要报修,什么是需要观察之后再处理的,什么是没有问题的。再一个就是发现故障之后我们要快速的收集故障日志,最后收集完日志之后我们需要报修故障并跟踪接单。如何快速高效的做到三点就是提升我们故障处理效率的关键。
下面介绍一下在实际线上运维中碰到的四个难点,我们要做哪一些事情来解决这些难点。
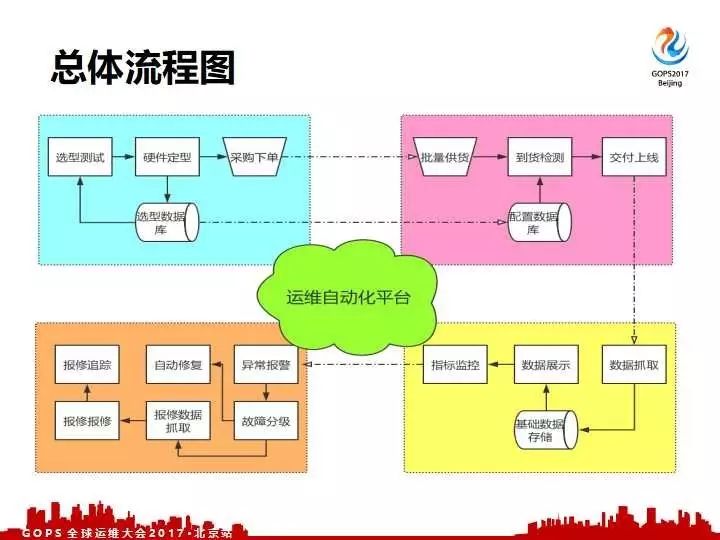
总结一下就是我们这四块:第一个选型测试获取定型数据,生成定型的标准,批量上架,对于每一台机器来抓取我们的数据,通过跟我们的标准匹配,没有问题交付之后自动的做数据抓取和展示。添加异常监控,最后对异常的数据做自动化的报修处理。这四块对于我们的内部运维平台实现了五大功能,就是前面反复提到的:选型测试、到货检测、数据抓取、故障报修,以及机房可视化,这五个主要的功能。
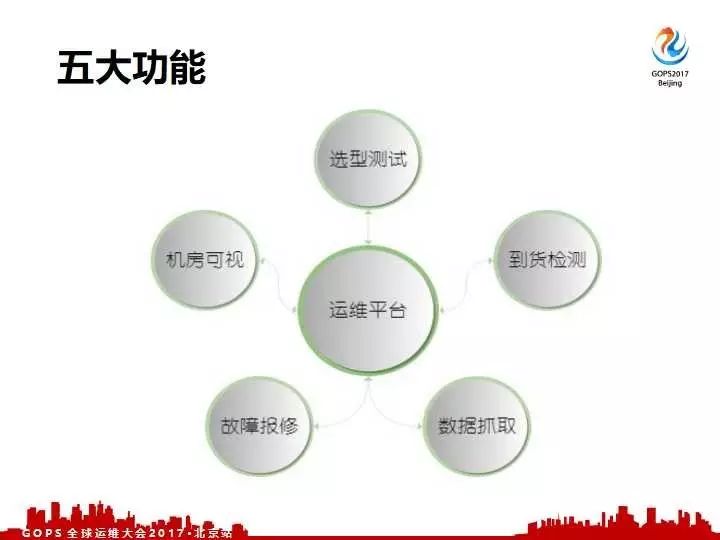
如何实现这五大功能呢?我们又面临了一个实现自动化需要知道的一些乱七八糟的数据问题,就是我们刚才也提到,哪些数据是我们运维需要知道的。
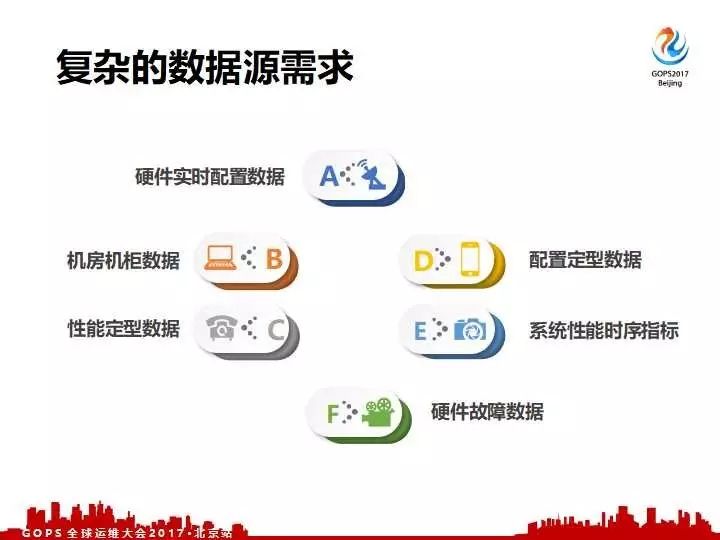
这一些数据是我们平台需要关注,包括硬件实际上是一个什么配置,包括机房、机柜相关的数据,还有包括选型测试定型的数据,还有定型的性能数据,还有硬件的故障数据,还有线上的系统时序化的指标数据等等。我们需要获得这一些数据,有了这一些数据之后通过我们的平台,才能提供上述五大功能。
这数据从哪来到哪去?我们首先介绍一下我们内部的 CMDB 。
这是我们硬件配置数据的存储,展示的一个平台。下面这截图大致展示了一下我们这平台是干什么,它记录了设备的状态,在线还是维修的状态,还是属于故障状态,还有类型,我们的内部包括实体机、虚拟机等等更多的状态。
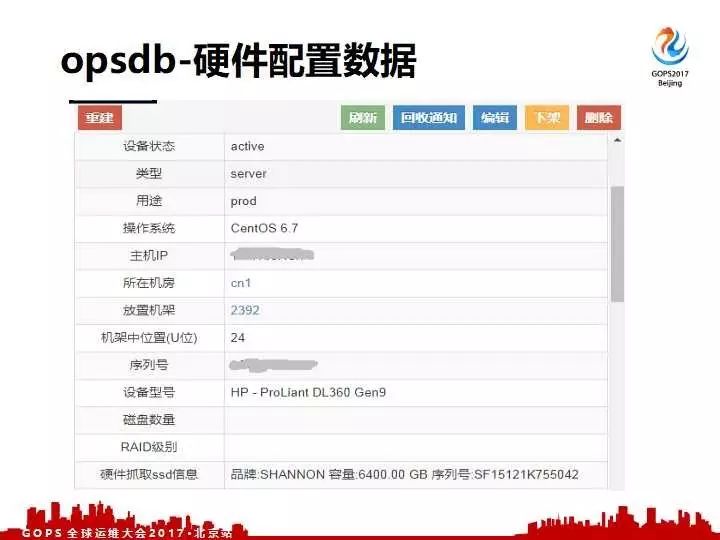
用途就是跟业务相关的,用途可能有测试的用途,有线上的用途,最后还有主机的IP在哪个机房在哪个机架,机器的序列号机器的类号。还有上面的RAID信息,硬盘的信息和SSD的信息,这些数据全部是在平台展示。这些数据在定型有人工录进去的,但是更多是通过我们的平台自动化抓取回灌进去的。当然说这些数据基本上就是硬件相关的,底层跟服务器相关的数据全部在这平台上展示。
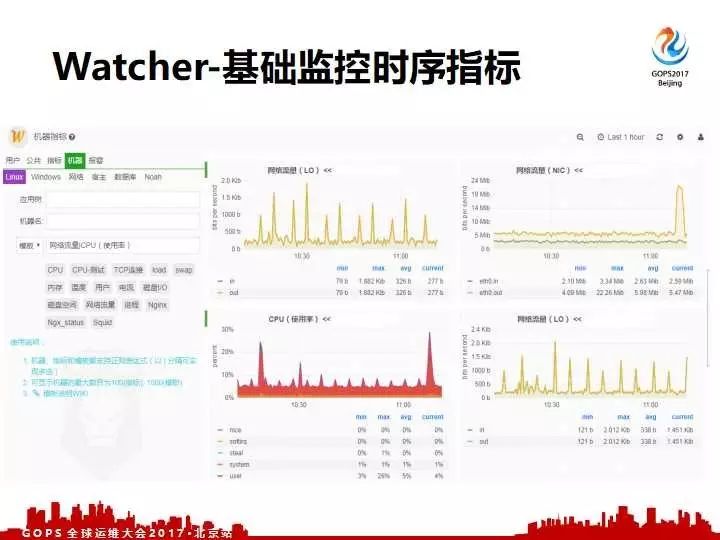
进入到第二个平台,我们内部叫 Watcher 。对于线上系统实时的时序化的收集、展示、管理。大家可以看到我们这系统上是记录了线上所有系统一个完整的时序指标的展示。我们可以收集到 windows 还有针对云的系统定制指标,包括数据库定制指标还有我们内部的 Docker 等相关的指标。对于每一个系统我们包含一些更详细的CGU、TCV还有等等。我们系统除了展示,还可以在上面配置监控,所以最终Opsdb、Watcher还有Hw-Platform的构成硬件生态圈。通过Opsdb设备基础数据的入口操作,用Watcher来做线上时序指标的入口,通过硬件的平台做一个有机的串联。
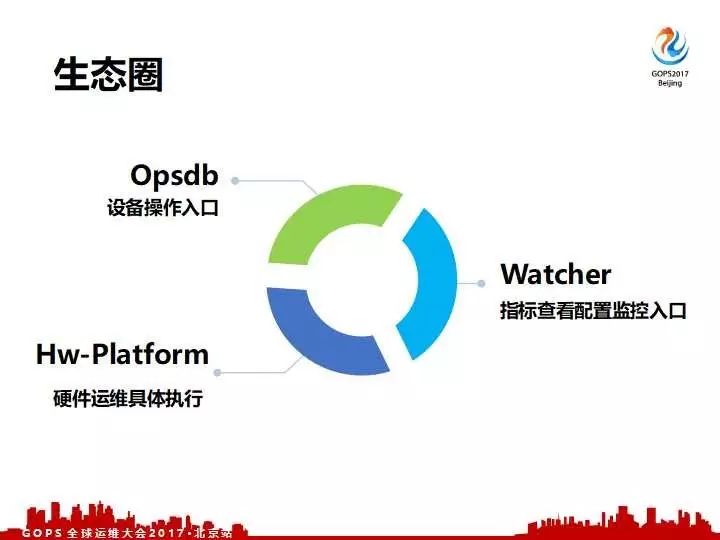
上面介绍完我们实现的一个目标,接下来就讲一讲实现的细节是怎么来做的。

第一个标题叫为什么要做硬件配置格式化统一,这就是说作为一个系统第一步面对的就是数据,数据从哪来?如果我们的供应商提供给我们的这些硬件,那可能会碰到从一套硬件搭配会有不同的服务器供应厂商,比如说戴尔、惠普、华为等等相关的,这厂商不一样,最后反应出真实的配置就不一样。
即使是一个硬件厂商配件,也会面临着不同的固定型号和不同的批次问题。作为一个极端的情况下,如我们的供应商的物件数据有问题的话,这数据也是有不同,所以面对一个实际情况就是线上面对的服务器或者是硬件,我们看到的就是乱七八糟的数据。可能有的时候这批次跟那个批次就少空格或者少字母。
碰到这么多乱七八糟格式的话,我们做自动化是没办法展开的,所以就需要对于硬件配置的格式化统一。

如果我们拿到同一套硬件配置,他们有统一的格式我们就能获取到相同的性能跟相同的供货配置,有了这一套东西我们才能做后面的一体化检测。
怎么来做这种格式化统一呢?有一个关键点,就是要有一套格式化的规则。什么叫格式化的规则呢?无论你是什么供应商什么配件供应商什么批次固定板,经过我们转化之后展现出来就是同一种型号的信息。我们实现的方式就是在每一台服务器上面部署了抓取工具,我们有一套规则,通过中心化管理和控制,工具定期从平台同步规则。
抓取到格式化的数据,回传到我们的后端进行二次处理,最后实现各种各样的服务器,只要是同一套硬件搭配,最后反应出来就是同一种格式,这格式化规则集是什么东西呢?我归纳了一下:硬件抓取的信息用什么工具跑什么命令,原始的数据按照什么格式来做切分,切分的数据最后转化成一个怎么样的输出格式,我们这一套规则集每一条都是这么来做的。

这是我们线上的一条规则集的实际案例,大家可以看到对于CPU,我们调了什么命令、跑了什么工具,每一个输出是按照什么关键字,按照什么符号来做切分,最后输出什么格式。通过这一套规则集我们线上实现的就是对于所有硬件的一个配置格式化输出的。
现在任何机器都有同一套硬件的配置,做到这前提之后,我们才能做成自动化。我们有一套标准,这一套标准从哪来?前面讲了从选型的时候,定型的时候就已经生成。通过这一套流程拿到线上的格式化配置。
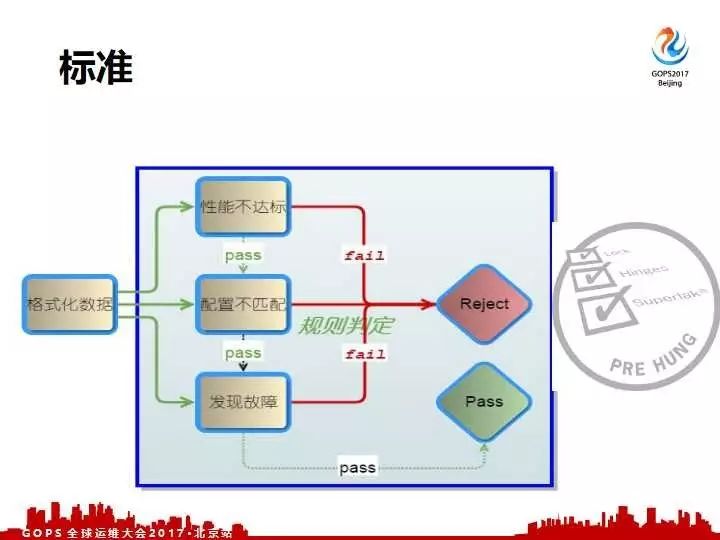
第一点拿到格式化数据之后首先匹配性能是不是达标,其次看看配置是不是和我们的标准是匹配的,最后一个检测一下硬件是不是有故障。这三点都没有问题,就直接交付给我们的业务线。如果任何一条有问题的话就直接报警做相关的处理,如果是故障我们自动化报修,如果是性能不达标我们又需要联系厂商,或者我们事先高效的做一下调优,如果配置不匹配的话我们直接就联系供应商来做相关的处理。

什么是检测标准,具体有三点:性能是不是达标、配置是不是匹配,是不是有故障。先讲一下性能达标和配置匹配,看实际配置跟我们的定型配置是一样。再一个就是性能是不是达标,性能在我们选型的时候已经生成了性能标准。到货批量抓取我们实际的性能,实际性能跟我们的标准是不是匹配,如果不匹配那就是有问题。
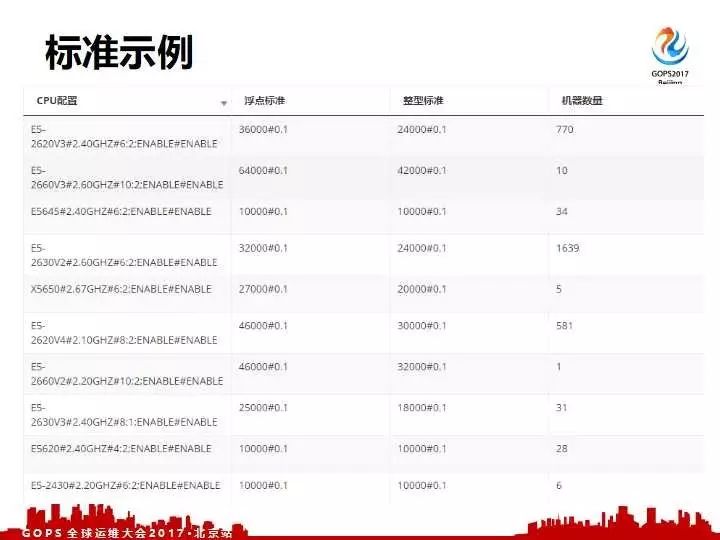
这是我们线上标准的一个案例了,我们的最左边一例就是格式化输出的例子。每一个CPU无论你是哪一年哪一个批次哪一个厂商,最后输出来都是一样的格式,这个浮点和选型的标准已经有了这标准。

我们现在讲一讲故障的事,这图是我统计了一下没做自动化之前,我们线上一个星期异常的统计,大致看了一下这异常一个星期会发8千多条。我们有一些开源的监控工具,这些工具做的大而全什么异常都报出来,但是这8千多个真正需要报修的只有几十条。我们的团队碰到这种异常轰炸,可能一天到晚就没事干就筛。

碰到这种问题,有两点应对措施。第一个屏蔽误报,怎么说呢?原有的报警工具它报警不足,这一部分提到有效性很低。8千多个异常只有几十条需要引起关注,其他的都是骚扰性的报警。再一个这些真正需要报警量很少,也不是说8千多条都是骚扰的,它也是可以做故障分级的。我这边大致分为三类,一类是 Critical ,需要立即报修。还有一类是 Warning ,还没到需要处理的一个级别。再一个就是没有问题的OK。
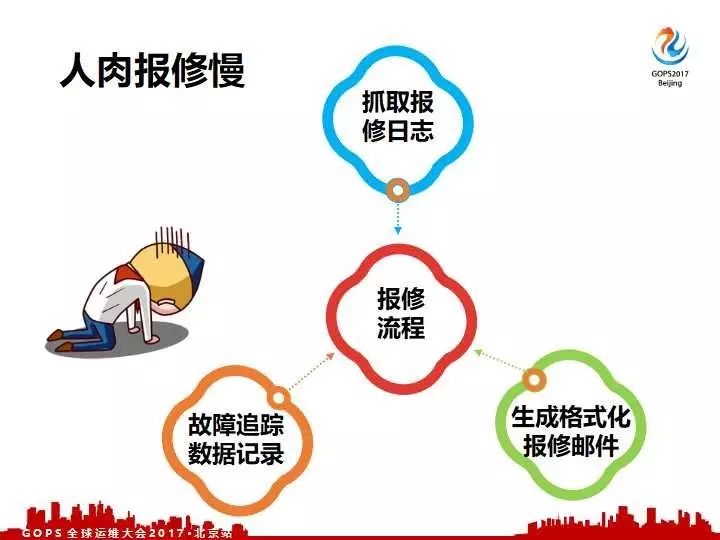
现在通过屏蔽报警,故障分级,我们拿到 Critical 。我们都需要做这三套,第一个抓取我们的日志,各个厂商、各个供应商要求的工具,最后包的格式都不一样,我们需要针对性的抓,我们需要登陆机器去抓。拿到日志之后我们需要通知厂商是哪一个机房、哪一个机柜哪一个机架到底是哪一个坏了,你要不写清楚很容易犯错误。
再一个是报出去之后我们也不能不管,你还得全程跟踪,你得督促他们赶紧入室来修。我们还得联系线上的业务下架服务,这故障是不是真正修好了也需要售后来跟踪的。总之即使你拿到百分之百的故障也不简单,如果是人肉来做的话也是很慢的。报修刚才也提到三个要点,要收日志要生成格式化邮件,最后一个我们要跟踪我们的报修的流程。
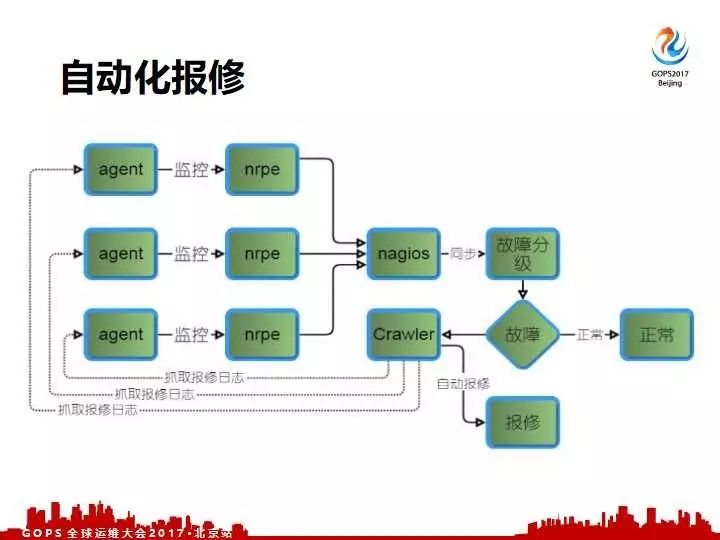
怎么来做这自动化呢?我们大致画了一个示意图,我们每一台机器人都有定制抓取的Agent,通过我们的平台做自动化故障分级,对于真正是故障的话,通过抓取集群自动的去从机器上相应的抓取,抓取到日志以后我们主动生成格式的邮件,对每一条进行自动化的跟踪。
这是我们线上已有的一个报修的数据展示,以周为单位的。我们每一个厂商、每一个型号、还有每一个配件,它的故障比例绘成一个饼图。最后这是每一个厂商有一个处理的平均周期,每一个厂商要花多长时间来结一个单子。我还提一点机房运维同学面临两个难题,第一个机房上下规划的时候,每一个机柜或者每一个机房它的分布的情况,他肯定是会选择能够最容纳这一批机器的位置来做布局。
再一个机房做监控巡检的同学比较关注的,机房的电流,机柜温度是不是正常?或者某一个片区机柜突然就全部报警,是不是空调坏了或者冷通道有问题?如果是人肉做这些事情可能就效率比较高了,你可能会要求外包,或者要求机房的人来做相关的事。但是现在做自动化之后,这种弹指之间就能使显得。

这图是什么?一个个格子代表我们一个机房里面的一个个机柜,有不同的颜色,有绿色、蓝色、黄色还有灰色等等,分别代表每一个实际的布局情况。我们这上面已经标注了有空调、有冷通道,每一个机柜相对的位置是跟实际机柜是一样。每一个绿色和蓝色分别代表机器的温度是正常,黄色是代表异常,再一个是我们的机柜如果是空白表明这些机柜就是空的什么都没有部署。如果这机柜是灰色代表我们这机器已经上架交换机但是还没有上架服务器。
每一个机柜呈现出的图是每一个机柜的正面虚拟视图。我们可以看到这机柜多高,每一个机位上放的是交换机还是服务器。服务器是哪个厂商?是惠普、戴尔还是联想还是浪潮的,我们都一目了然了。机柜的两边我们都有一些刻度、数据点,进去把鼠标移上去就能看到这机器过去一天它的温度、电流的走势。我们现在有了这平台,机房的相关同学应用起来效率跟以前是不可同日而语的。
4、总结回顾
上面具体介绍了我们相关的几块工作的实践,现在来总结一下,之前的选型测试就是当代理商供应商给了一些,大约就知道选一些什么东西。由于我们的人力、物力不够就没有办法做到每一种都去测一测。再一个是人工随机抽查的,我们不能一台一台的去走,所以经常碰到有遗漏,线上的业务反馈有问题,新机器也有问题。再一个是我们的故障人肉报修,大量的异常我们去筛,筛完了人肉报修。我们硬件相关的配置都是人肉去命名,这是我们的故障命名数据分析这一块是腐败。

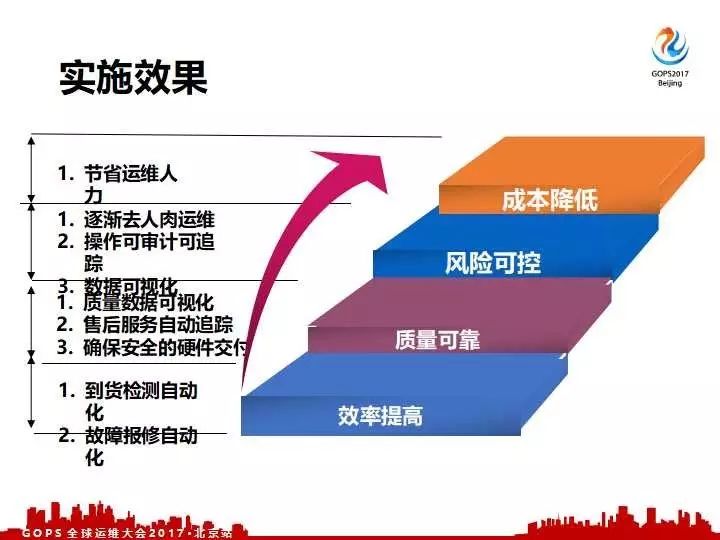
现在我们用了这一套自动化运维体系之后最大的好处基本上就是无人值守的,我们的选型还有我们的一体化检测和故障追踪都是自动进行,所以我们运维同学大大解放了,基本上就是他可以有更多的时间、精力去干一些其他的事。基本上达到了我们之前要求的效果,提高了效力,保证了质量可靠,控制了风险,最后大大降低了我们的运维的成本。
刚才介绍了一些具体实践,现在讲一下我们的实施难点,包括数据怎么抓、怎么分析,最后怎么来自动化的。里面无非就涉及到有三个难点:第一个就是抓取,因为我们的机器每天、每个星期都有大量的上架,怎么做到你不管上多少的机器,抓取扩展很容易做到一个自动的弹性线性的扩展,我们是用大了多块技术,最后一个我们的抓取虚机可以封装几十个,最后就是达到几百台、上千台的机器抓取,它的压缩效率是非常高的。

最后一个就是抓取系统,有很多做开发的同学知道,自己来实现HA是很麻烦。我来开发这一套东西我不会花时间、精力去干这事,因为我们团队里已经有成熟的像马拉松的 Mesos 平台我们就直接用。我们利用马拉松 Mesos 这一个框架,最后用 Docker 弹性的扩展,最后讲到 Celery 架构拆成各个独立的模块,每一个模块来用马拉松的 Mesos 来做一个HA,最后实现了异步抓取的集群。
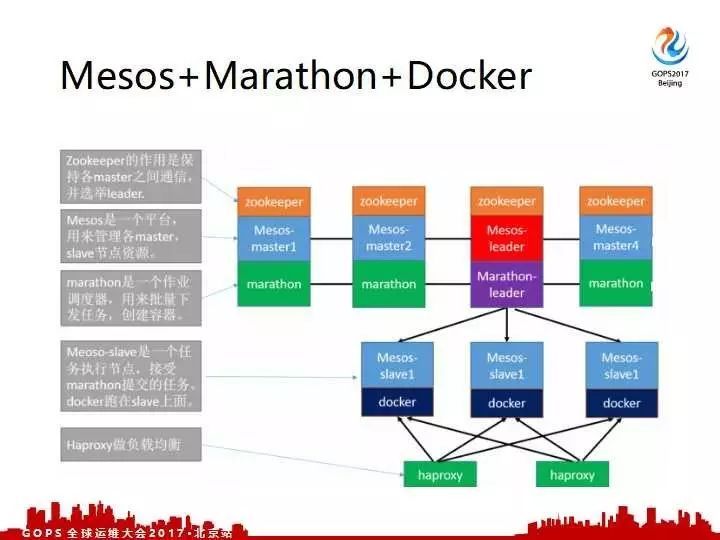
花几分钟介绍一下 Mesos 和 Marathon 和 Docker 。Docker 能做到很轻量,它比多进程有天然的优势。 Docker 它接受 Mesos 的管理, Mesos 每一个机器、每一个系统里跑一个,由 Mesos 搭载的 Marathon 框架的来进行调度。 Marathon 用来提供 Mesos 的一个操作接口,所以最终我们通过这个框架实施了HA五加弹性扩展,还有任务调动。
这是分布式调动任务集群的一个示意图。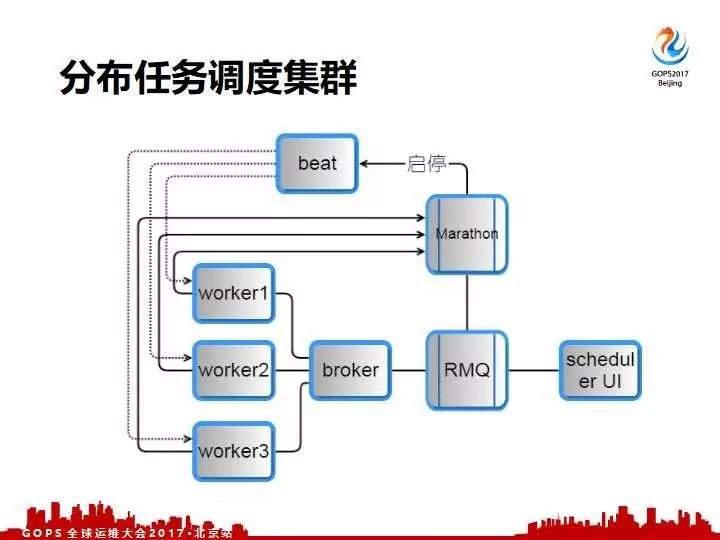
我们把 Beat 和 Worker 分开,真正通过MQ来做串联。前端自己写了一个调度的UI,所以当UI上面配置了变更之后也触发了马拉松,把变更在 Beat 和 Worker 生效,最后 Beat 跟 Worker 进行连接,所以保证这两个集群独立的解耦。
END
近期好文:
第八届全球运维大会
即 GOPS2017·上海站将于2017年11月17日-18日在上海举行
各种精彩等您发掘。
点击阅读原文关注活动官网
以上是关于去哪儿网的硬件自动化运维体系建设之路的主要内容,如果未能解决你的问题,请参考以下文章