大数据集群的自动化运维实现思路
Posted 知数堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据集群的自动化运维实现思路相关的知识,希望对你有一定的参考价值。
| 作者简介
王晓伟
知数堂《大数据实战就业》课程讲师
六年大数据相关工作经验
清华大学软件工程硕士
曾就职于网易、搜狗等互联网企业
从事大数据及数据仓库的开发管理工作
拥有丰富的数据平台建设、
及Hadoop生态系统组件优化经验
| 王老师往期公开课及试听视频:
1、第1期课程刚结课
(正式课试听视频:
https://pan.baidu.com/s/1yfgL5g7FGfjnhas1CtoAWA)
2、往期公开课:
本周四晚,欢迎来知数堂体验王晓伟老师的公开课
分享主题:《mysql与数据仓库如何进行数据交互》
分享时间:2018年7月12日,20:30-22:00
微信扫码、戳下方链接,或“阅读原文”报名预约吧
https://ke.qq.com/course/314213
摘 要
IT公司的数据平台是支撑大规模数据处理、数据决策支持的重要基础设施,随着大数据及人工智能技术的发展,大数据集群规模变得越来越大。然而,如何快速、高效的管理好成千上万台的大数据集群成为了很多大数据工程师的奋斗目标,设计实现合理的自动化运维系统将使大数据集群的管理事半功倍。
本文将从大数据集群面临的挑战、自动化运维系统的设计原则、工具选择等方面阐述大数据集群的自动化运维实现思路。
大数据集群面临的挑战
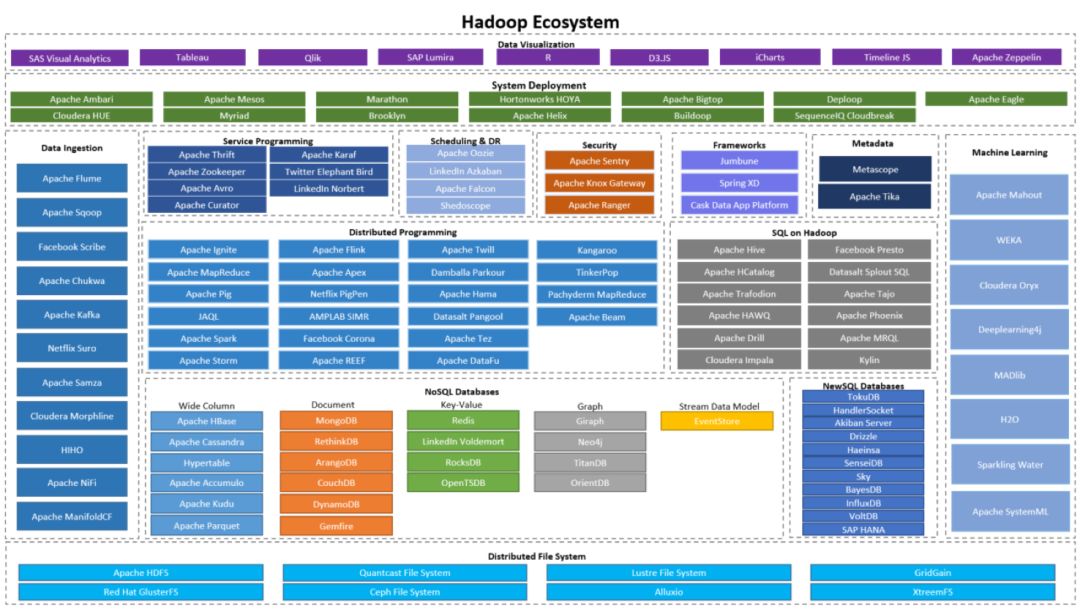
Hadoop生态系统组件:
1、服务器规模大
由于海量数据的存储需求,大数据集群通常服务器规模比较大,例如,阿里巴巴云梯Hadoop集群、腾讯TDW系统单个集群均超过5000台的服务器,几百台至上千台服务器规模的集群非常普遍,集群规模的增长对故障响应、跨机房容灾等方面提出了更高的需求。
2、组件之间的依赖关系复杂
大数据集群通常需要部署多个框架,Hadoop生态系统包含了分布式存储、分布式就算、NoSQL系统、实时计算、流式计算、数据仓库等各个组件,以Hadoop本身为例,YARN及Hbase依赖HDFS系统,而HDFS系统又包括Namenode、SecondaryNamenode、Datanode等不同的角色,各个角色之间的启动也有依赖顺序关系。
3、 横向/纵向扩展需求多
从横向扩展来看,大数据集群通常需要随着数据量的增长而进行集群的扩容,从纵向扩展来看,每个公司的不同产品、不同业务线需要部署多个不同的集群。
4、故障处理频繁
由于集群规模大,服务器多,大数据集群的硬件故障、系统故障等问题发生频繁,以我曾经负责的大数据集群来看,总计三千台服务器,超过6万块硬盘,每周更换的损坏磁盘在40块左右,这种故障频率对传统的故障处理流程带来了挑战,亟须建立自动化的故障处理方式来简化工作量。
为什么大数据平台更适合自动化运维?
1、软件体系高度标准化
目前,IT公司的的大数据平台普遍采用Hadoop生态系统各个组件,开源产品的工具设计更注重通用性、标准化等方面的要求,因此,在软件的自动构建(普遍采用Maven工具)、API、测试用例(普遍实现了单元测试)、指标监控(http接口)等均具比各类自研系统更加规范。
2、服务器配置高度收敛
尽管大数据集群的规模大,但是集群在达到一定规模后,服务器的配置趋向于收敛特性,即大量的服务器的硬件、系统、部署的软件均是一致的,这就为自动化运维系统的设计带来了巨大优势。
自动化运维系统设计原则
1、标准化
自动化前提是标准化,在实现系统自动化之前,应该对操作流程进行一次完善的标准化
2、高可用
大数据系统往往都是高可用的系统,为了提升整个系统的稳定性和可用性,自动化运维系统也需要设计成高可用,避免因为自动化运维系统的故障导致大数据平台出现无法服务的情况。
3、幂等性
简单来说,幂等性指的是一个操作多次执行所产生的影响均与一次执行的影响相同。在大数据系统架构中,经常存在部分失败的情况,需要多次运行相同的部署命令,这就需要系统在重复执行的情况下,不会出现异常。
4、可回滚
所有自动化操作均需涉及为可回滚,任何一种改变操作,都应该保留相应的数据、代码、日志,并做合理备份,保证在任何一个步骤出现问题的时候,自动化运维系统可以实现回滚至之前的状态。
5、高效率
大数据系统集群可以达到成千上万台服务器的规模,一次操作需要在短时间内完成所有服务器的覆盖,因此自动化系统的运行效率需要提高,一般需设计可配置的并发运行数,达到对上线效率的要求。
实现路径
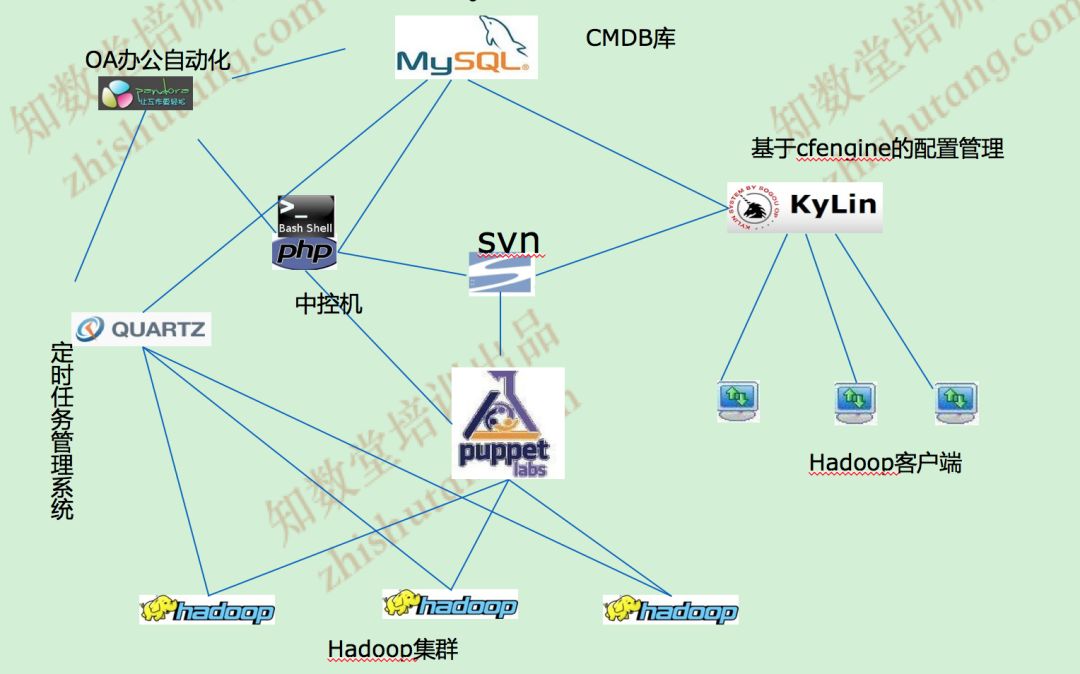
典型的大数据平台自动化运维系统,应该包含OA系统(实现页面操作、工作流管理)、CMDB(配置管理数据库)、配置管理工具、堡垒机(中控机)、定时任务系统、持续集成系统等。
Hadoop自动化运维系统典型架构:
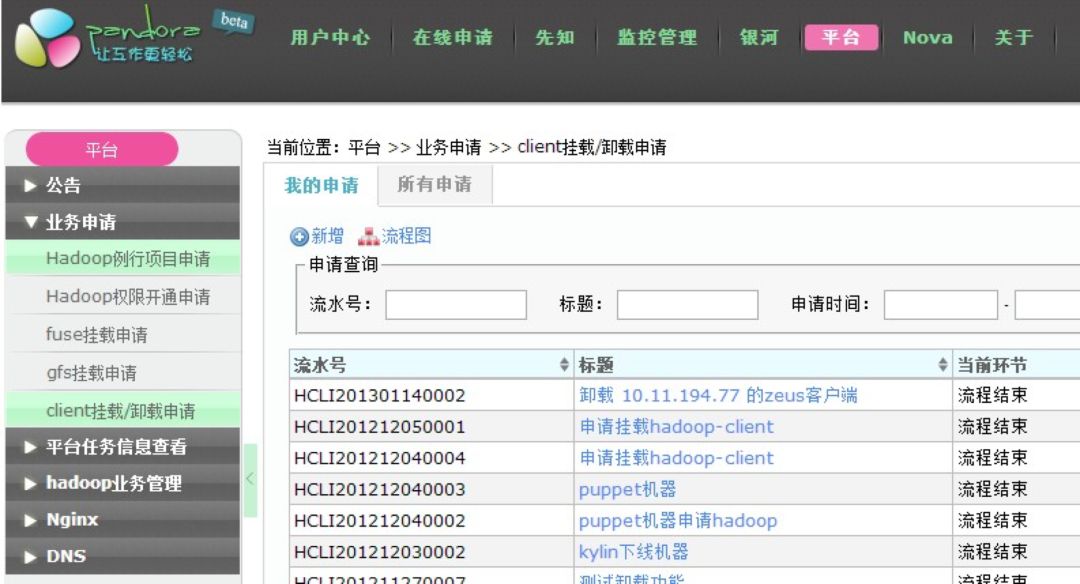
OA自动化系统页面:
自动化运维工具选择
1、Ansible
Ansible是目前github上最受欢迎的开源自动化工具,使用Python语言开发,与Puppet、Slat等工具相比,Ansible无需在被管理的机器安装agent,而是通过ssh进行管理,Ansible的更加的简单易用并且功能强大。
2、Puppet
puppet是一种Linux、Unix平台的集中配置管理系统,基于C / S架构,使用ruby语言,可管理配置文件、用户、cron任务、软件包、系统服务等。puppet把这些系统实体称之为资源,puppet的设计目标是简化对这些资源的管理以及妥善处理资源间的依赖关系。
3、SaltStack
SaltStack是一个服务器基础架构集中化管理平台,具备配置管理、远程执行、监控等功能。SaltStack基于Python语言实现,结合轻量级消息队列(ZeroMQ)与Python第三方模块(Pyzmq、PyCrypto、Pyjinjia2、python-msgpack和PyYAML等)构建。
通过部署SaltStack环境,可以在实现:在成千上万台服务器上做到批量执行命令;根据不同业务特性进行配置集中化管理、分发文件、采集服务器数据、操作系统基础及软件包管理等。
综上所述,Ansible是目前Devops业界非常活跃的工具,在使用和部署上也非常方便(仅需安装控制端,无需部署agent),在小批量的集群上建议使用Ansible。如果集群规模较大(超过1000台)且对运行速度要求更高,可以考虑Salt和Puppet(对Python做二次开发选用Salt,熟悉Ruby则可选择Puppet)。





知数堂
叶金荣与吴炳锡联合打造
领跑IT精英培训
行业资深专家强强联合,倾心定制
MySQL实战/MySQL优化/MongoDB实战/
大数据实战 / Python/ SQL优化
数门精品课程
紧随技术发展趋势,定期优化培训教案
融入大量生产案例,贴合企业一线需求
社群陪伴学习,一次报名,可学1年
DBA、开发工程师必修课
上千位学员已华丽转身,薪资翻番,职位提升
改变已悄然发生,你还在等什么?

扫码下载知数堂精品课程试听视频
(MySQL 实战/优化、MongoDB实战、大数据实战、
Python开发,及SQL优化等课程)
密码:hg3h

以上是关于大数据集群的自动化运维实现思路的主要内容,如果未能解决你的问题,请参考以下文章