阿里巴巴:云上应用自动化运维管理的最佳实践 | 活动通知
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里巴巴:云上应用自动化运维管理的最佳实践 | 活动通知相关的知识,希望对你有一定的参考价值。
随着云计算技术普及,基于云服务的应用以及云原生应用的规模化运维管理成为一个新的技术难题。本主题将探讨基础云资源、云原生应用以及无服务器应用的自动化运维技术。
本议题将介绍阿里巴巴在云战略中的智能化实践。如何通过自动化和智能化手段运营大规模集群,如何在计划内变更稳定性及异常处理方面应用智能算法辅助决策,提高大规模集群稳定性并降低运营成本。
从单机到多机,单数据中心到多数据中心,IT基础设施规模化管理成为降低日常运营成本的重要手段,整个的自主优化,我们把数据化结合自动化、智能化的方法,最终达到持续学习优化的过程。
随着云技术成为主流,基础设施规模不断增加。从业界来讲,单数据中心最大是10万规模,单集群在万级规模 。在阿里最开始构建云的基础生态时,我们面对的问题就是如何高效管理大规模数据中心中软硬件,同时数据中心的形态从自建机房也包括到边缘机房,规模以百的单位持续增长,单一集群规模也越来越大。
当整个管理服务器的规模超过十万量级,很多从前不太明显的问题会被放大,比如硬件的故障和不可靠性。硬件级别的故障例如存储的静默数据丢失,这个故障在业界来说普遍认为是硬件故障,但大规模场景下单机硬件故障出现概率会增大,需要从软件层面解决这个问题。
基础设施主要着眼于三方面:

第一、规模
在进入了云时代随着阿里巴巴的业务类型越来越多,基础设施管理的资源规模越来越大,任何小的问题都将会被放大。我们进行分层处理,在处理大规模基础设施层面的团队,不会把业务的复杂性带进来虚拟化技术屏蔽,着重于基础软件层面的管理,这样问题域确定,问题会定位非常明确。
第二、安全
防止操作故障,规模大了以后,任何小的问题都会被放大。随着规模的增长,不能从系统上防止这些事情,光靠流程是很难保证的。
第三、效率
聚焦在提升效率,需要考虑如何控制节奏,我们将集群变更模式分为两类:一种是计划内,主要关键点是灰度模型,具体的服务实现自己所需要的策略,我们把所有的服务作为服务巩固把模型实现出来,把整个计划内的风险控制得非常低。另外一种异常处理,在大部分环境下可以积累数据进行更优化的判断,保障变更的稳定性。”接下来我们会介绍在这两个领域里的用机器学习的方法提高处理效果。
面对现实
可用性方面,硬件系统和软件的问题是不可避免的。由于依赖关系的传递,传统软件架构越到上层服务,可用性会越低,这时候需要在系统架构层面设计的时候把强依赖尽量消除,降低基础设施或服务对上层服务的可用性影响。
比如我们管理的这些系统,并不强依赖底层基础管理系统,每台机器上的单机功能是没有依赖的,运维管控的服务可用性不影响业务系统的可用性。同时运维管控自身通过基于paxos的分布式模式来提高服务的可用性。
变更效率方面,这是很难控制的。最早开始的时候做基础变更,一般是想要快,但是发现上面的业务特别复杂的时候,怎么知道会不会有影响呢?这时候最后的思路是这样的,我们引入一套反向协议,跟上层的软件层定义协议,让他们告诉我们。
比如要把某个服务器下掉,它对服务有什么影响是它来告诉我的,这样来解决效率的问题。相当于把所有的影响让每一层都看到,用全自动的方式来解决这个问题。
可维护性,人为失误是无法避免的,我们把所有的基础变化都变成配置,期望所有的变化是由程序来计算的,程序计算出来的可靠性比人高得多。任何一个线上的配置,要一个人描述,只是看最终描述的环境中是不是合理的状态就够了。
整个技术演进,把运维系统和某些技术有一些耦合限制在控制集群,比如说当着眼于操作系统级别的关键的内核技术,我们对它是有一定的依赖,基本上不超过10台机器的规模,在服务迭代时不会影响其他的服务。
我们从脚本、工具运维时代发展到现在的自动化平台时代,随着业务发展及规模化,对于人的决策要求更高,同时风险也越大。
因此我们开始借助于机器学习、算法优化等方式来应用智能化场景防止人为决策失误问题的发生,把很多的决策慢慢地从人的决策移到由程序来决策的方式从而提高效能。

计划行为的智能决策
业界很多的领域里都在做通过业务方式,描述整个环境目标状态,然后决定要如何达到。另外是变更的范围,要影响哪些范围,最早是靠人决定的,但是随着业务的比较,有些时候这些事情没有那么简单,比如升级一个版本,这个版本只在某个特定的情况产生,以前是靠人拉数据,算出来再填回去,这样看起来很机械。灰度策略,1%、5%、10%、100%,如果按照比例测算,很可能某个大用户就受影响了。
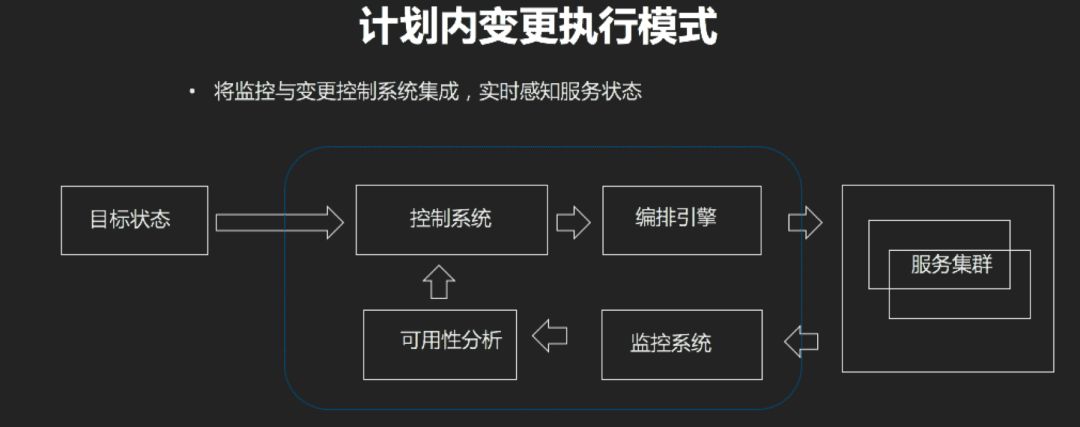
我们把目标状态定义为控制系统变成纯粹接收目标状态的要求,比如管理几万台机器,这些信息都要告诉你,自己还要梳理。
以前部署了某个软件的什么机型什么版本的机器,需要某个软件到什么版本,就直接接受请求,把请求翻译到编排引擎里,在编排里算出来整个过程是什么样的,然后再跟服务集群的服务有个交互,会问他要做这样的事情,应该怎么做比较合理,他会告诉我一个结果,我会根据结果得到最终的结论,按照这个结论批次批次地做。
每批次做的时候,我们会根据监控系统的结果,你自己去关心哪些状态,比如说是关心状态、性能、容量,你把这些汇报出来,我们做可行性分析,在一定时间是符合的,我们就进行下一批次,这样来做所有的过程。
整个过程的结果是不太需要人工干预的。我们做了很多关联性的分析,我们会把整个的服务可用性做分析,比如他认为自己没有问题,但是他影响到别人了。

菅骁翔
阿里巴巴基础设施事业部 资深专家
演讲主题《云上应用自动化运维管理最佳实践》
个人介绍:
阿里巴巴资深技术专家,现负责集群自动化运维、云监控等基础产品研发,长期致力于中间件、虚拟化、软件定义数据中心以及云计算基础设施的技术研发。
4月12日-13日的深圳
第十二届 GOPS 全球运维大会即将举行
部分日程
讲师天团
联系我们
票务咨询:
曾女士 130 2108 5119(微信同号)
李女士 130 2108 2989(微信同号)
商务合作:
刘女士 158 0111 5386(微信同号)
程女士 130 7118 2180(微信同号)
扫码立即报名
历届全球运维大会回顾:
点击阅读原文,访问活动官网
以上是关于阿里巴巴:云上应用自动化运维管理的最佳实践 | 活动通知的主要内容,如果未能解决你的问题,请参考以下文章
数云运维总监陈延宗:基于阿里云计算巢,数云CRM一键云上交付