针对Sharding DB的单点故障,合理构建HA架构
Posted 数据和云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了针对Sharding DB的单点故障,合理构建HA架构相关的知识,希望对你有一定的参考价值。
作者简介

何剑敏
Oracle ACS华南区售后团队,首席技术工程师。多年从事第一线的数据库运维工作,有丰富项目经验、维护经验和调优经验,专注于数据库的整体运维。
sharding database最大的特点是可以横向扩展。但是横向扩展不是RAC的横向扩展,纯sharding db是没有HA架构的。即一个shardcat db,多个shard node db。无论是谁down了,都会造成不可用。我们从上往下捋一下,看看哪里有单点故障,这个单点可以通过什么方式解决。
我们知道,sharding的架构大致如下,
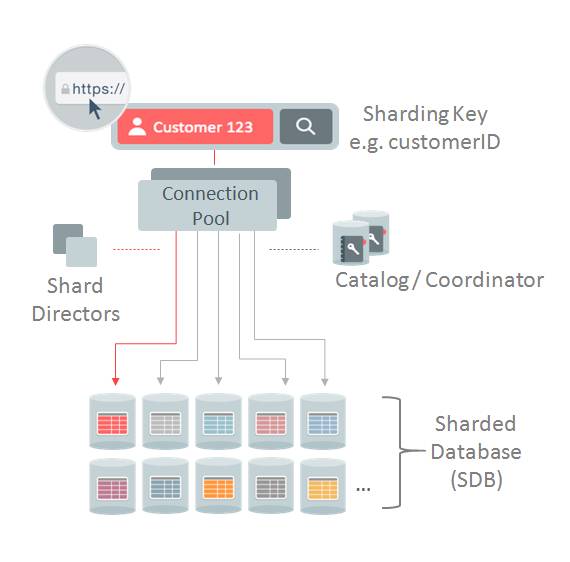
1connection pool
从应用端发起之后,往下是connection pool,这个connection pool,指的是Oracle Integrated connections pools (UCP, OCI, ODP.NET, JDBC)。这个connection pool,不在本文的讨论范围内,这个是涉及到中间件的高可用问题。
往下是shard director(gsm)和shardcat数据库。这涉及到一个路由的分类。直接路由(direct route)还是代理路由(proxy route)
直接路由
直接路由是基于sharding key,在connection pool中的connect阶段就实现了。如果在connection pool(以下以UCP为例)有缓存,缓存着sharding key的range,和shard以及chunk的mapping关系,所以直接忽略shard director,直接到某个shard,node;
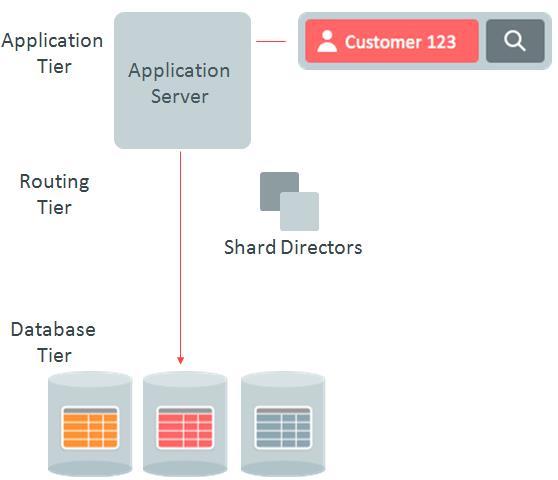
如果在UCP中没有缓存,则到shard director中找一次,再去shard node。且下一次执行的时候,由于已经缓存,就不再需要去shard director中找了。
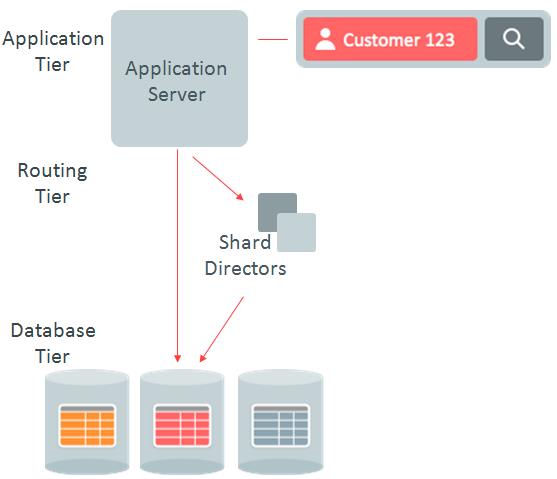
在直接路由模式下,当连接请求是包含sharding key的,即UCP的连接可以使用sharding相关的API,如pds.createShardingKeyBuilder() 和pds.createConnectionBuilder() ,相关的操作就直接去对应的数据库分片了。
代理路由
代理路由模式是不基于sharding key的访问,或者是需要查询multi shard的数据,那就需要coordinator database,也就是shardcat数据库。应用就需要通过shardcat数据库,才能找到对应的shard node。
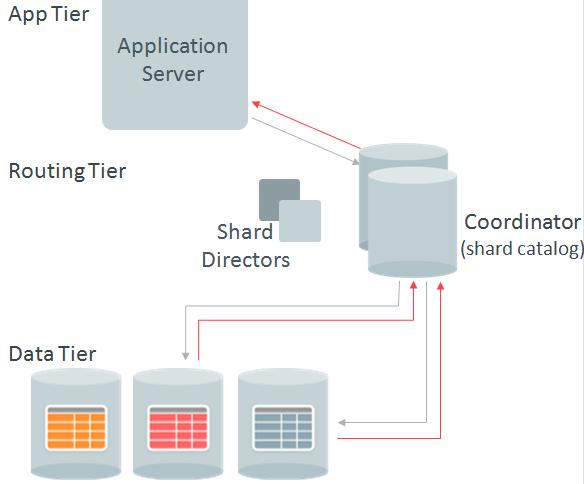
所以说,对于直接路由模式,我们有可能出现的问题,是shard director进程挂了。对于这个问题的解决,我们可以设置多个shard director,每个region最多可以设置5个shard director。shard director的功能,类似于向listener,你可以认为它是一个region listener。接受来自某一个区域的连接,然后进行路由。
对于代理模式,我们需要经过shardcat数据库,那么就可以使用到shardcat数据库的高可用方案了。如ADG,如RAC。在sharding的高可用方案中,我们是优先考虑ADG,再考虑RAC。
另外提一下,由于如果不是multi shard的查询,就不经过shardcat数据库,所以如果shardcat down了,但是如果只有某个分片的transaction,那么也是不受到影响的。
3shard node
再往下,就是shard node了,每个shard node包含分片数据,当一个shard node挂掉的时候,shard table的其他分片,即使是活的,也是无法查询这个shard table。
所以,我们要对shard node建立ADG,且启用FSFO。(我会写另外一个文章,介绍如何deploy带ADG的shard node)。如果不用ADG,那么OGG也是另外一种高可用的方案。此外,还有RAC,也避免一个shard node主机挂掉,注意,只是防止主机挂掉,不能防止存储挂掉。如果要防止存储挂掉,还是要建ADG。(这也是为什么sharding的最佳实践,是建立ADG,而RAC方案只是optional)
但是由于ADG的FSFO切换影响较大,因此最好的方式,还是RAC+ADG,即如果一个shard node的一个机器挂了,那么在RAC架构下,还有另外一台机器能顶住,不会有问题。如果2个节点都挂了,才FSFO切换到standby。
所以,sharding的HA最佳实践,应该是如下的:
有2个区域(region),每个region有2个或以上的gsm(shard director),然后shardcat数据库有ADG(可以再加RAC),后面的shard node也是要做ADG+FSFO(可以再加RAC)。
如何加入"云和恩墨大讲堂"微信群
关注本微信(OraNews)回复关键字获取
2016OTC,第六届Oracle技术嘉年华PPT;
2016DTCC, 2016数据库大会PPT;
DBALife,"DBA的一天"精品海报大图;
12cArch,“Oracle 12c体系结构”精品海报;
DBA01,《Oracle DBA手记》第一本下载;
YunHe,“云和恩墨大讲堂”案例文档下载;
以上是关于针对Sharding DB的单点故障,合理构建HA架构的主要内容,如果未能解决你的问题,请参考以下文章
HDFS HA之手动高可用故障转移配置自动高可用故障转移配置配置YARN-HA集群