如何使用容器实现生产级别的MongoDB sharding集群的一键交付
Posted 云技术实践
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用容器实现生产级别的MongoDB sharding集群的一键交付相关的知识,希望对你有一定的参考价值。
作者介绍
魏世江
希云联合创始人、CTO,负责基于Docker的自动化服务管理平台的后端研发工作。擅长Docker相关技术、PasS平台架构及企业自动化运维系统的设计及开发。创业之前在新浪SAE平台任技术经理,从09年SAE立项至13年下半年的四年多时间里,一直负责SAEPasS平台各种基于Web的服务管理系统的设计及开发,在DevOps方面积累了丰富的经验。Docker引擎代码贡献者,在Docker开源项目中代码贡献量全球排名50名左右。
开篇
Mongo在很早就支持了replication set和sharding集群。经过了这么多年的沉淀,Mongo集群的成熟度已经非常稳定,被大量公司用到自己的生产环境下。如何使用容器技术来实现Mongo集群的一键式交付部署,屏蔽底层实现的细节,是很多人关心的话题。
本文将给大家介绍基于进程的容器技术实现Mongo sharding集群的一键部署,充分展现了容器的强大威力。
什么是Mongo sharding集群
Mongo(mongodb.com)作为流行的文档数据库,有很多有趣的特性,比如内置failover、支持文件存储、支持mapreduce以及可以在服务器端直接运行js脚本,当然我们今天最关心的是它内置的sharding功能。分布式系统的设计向来具有很高的挑战,在最近一些年,随着互联网的发展,分布式的实践逐步开始得到推广和重视。
如果要深入了解Mongo sharding的原理,参考:
集群编排规划
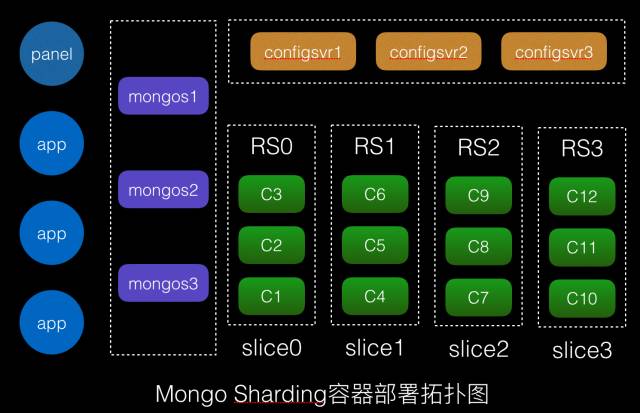
mongo集群涉及到多个服务,包括:
configdb, sharding集群的中心配置,是一个replicaset集群,监听在27019端口
mongos, 作为sharding集群的访问和管理入口,监听在27017端口
mongo slices,数据分片节点
mongo replicaset,每个数据分片是一个replicaset集群,用于保障没有单点,并提供自动failover能力
mongo express, mongodb的管理dashboard
拓扑图
本次部署,configdb3台,mongo数据节点12台,分成4个分片,每个分片1主2从
首先准备mongo镜像
Mongo官方已经提供了Mongo 3.2的镜像,可以用来作为Mongo集群的镜像.为了减少后续维护工作,我们尽可能不构建自己的镜像。
下面我们按照mongo sharding官方的部署文档,一步步编排集群。
部署的顺序是:configdb -> mongos -> mongo-replicaset/mongo-slices -> mongo-express
部署mongo configdb
准备configdb的配置文件
# cat mongo-config.confsystemLog:
verbosity: 0operationProfiling:
slowOpThresholdMs: 3000processManagement:
fork: falsestorage:
dbPath: /data/db
journal:
enabled: true
engine: wiredTiger
replication:
replSetName: {{.ReplSetName}}
sharding:
clusterRole: configsvr
net:
port: 27019准备 configdb集群的初始化js脚本
# cat configdb-init.js{{ $s := service "mongo-configsvr" }}
config = {
_id : "{{.ReplSetName}}",
members : [
{{range $c := $s.Containers }}{_id : {{$c.Seq}}, host: "{{$c.Domain}}:27019"},{{end}}
]
}
rs.initiate(config)
rs.status()开始编排configdb服务
第一步 创建模版
第二步 选择mongo镜像,指定cmd
第三步 设置容器参数,关联配置文件
第四步 健康检查策略
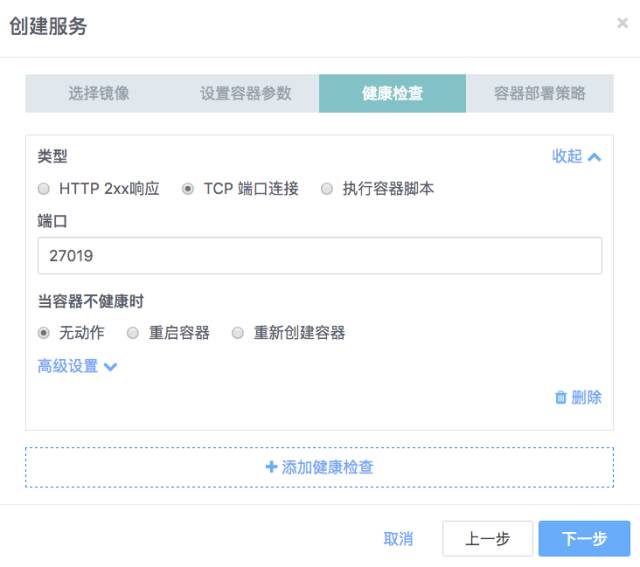
第五步 设置部署策略,默认部署容器数量
初始化configdb为replicaset集群
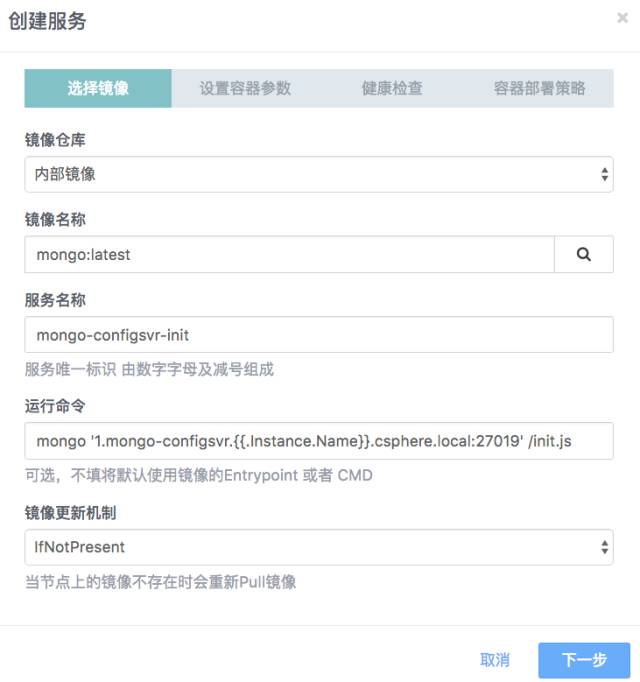
我们通过添加一个one-off的服务configsvr-init,该服务执行初始化动作后将会自动退出
第一步 选择mongo镜像,指定cmd
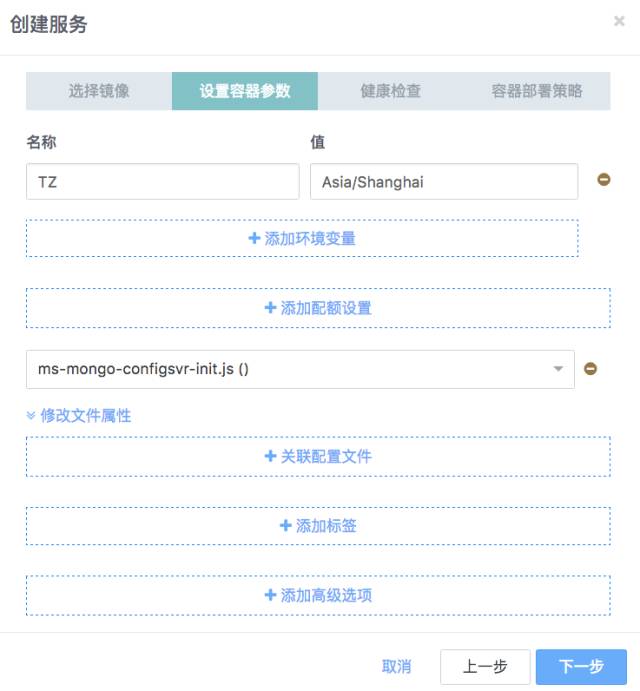
第二步 设置容器参数,关联js脚本
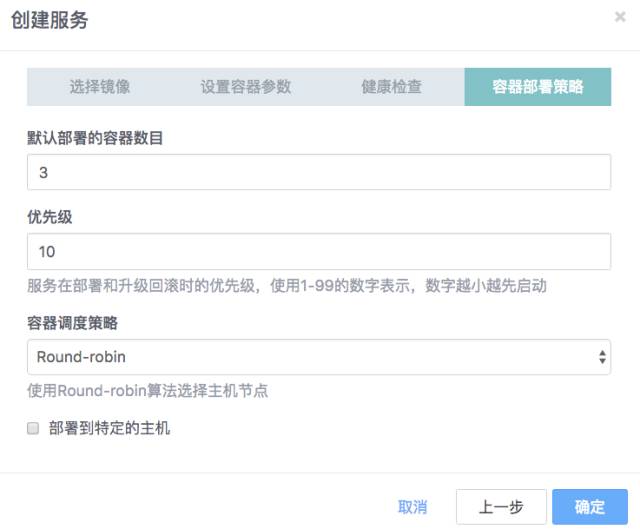
第三步 设置部署策略,优先级数字设为11(configdb优先级10)
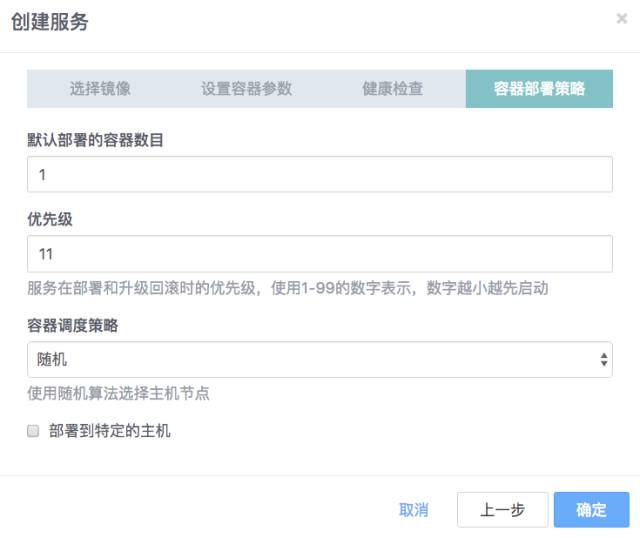
至此,configdb的编排算是完成了。我们接下来编排mongos服务
准备mongos配置文件
# cat mongos.confreplication:
localPingThresholdMs: 2000{{ $port := .CfgPort }}
{{$s := service "mongo-configsvr"}}
sharding:
configDB: {{.ReplSetName}}/{{range $i,$c := $s.Containers}}{{if ne $i 0}},{{end}}{{$c.Domain}}:{{$port}}{{end}}mongo的配置文件我们一般放到/etc/下
编排mongos模版
第一步 选择镜像,指定cmd参数

注意cmd里执行的是mongos
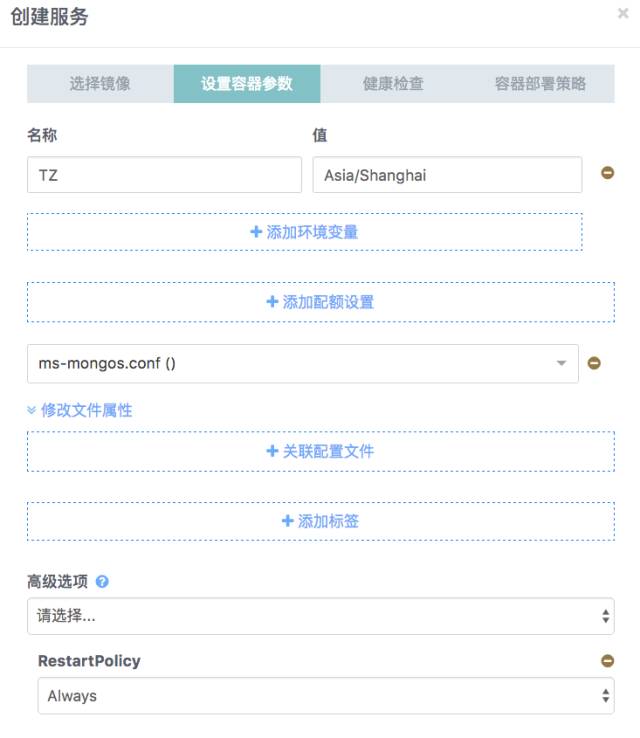
第二步 设置容器参数,关联mongos配置
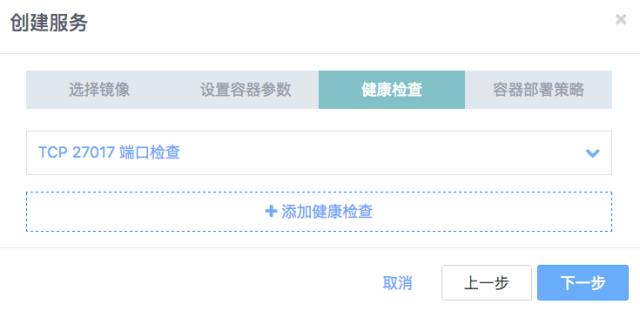
第三步 健康检查
第四步 设置部署策略,注意优先级
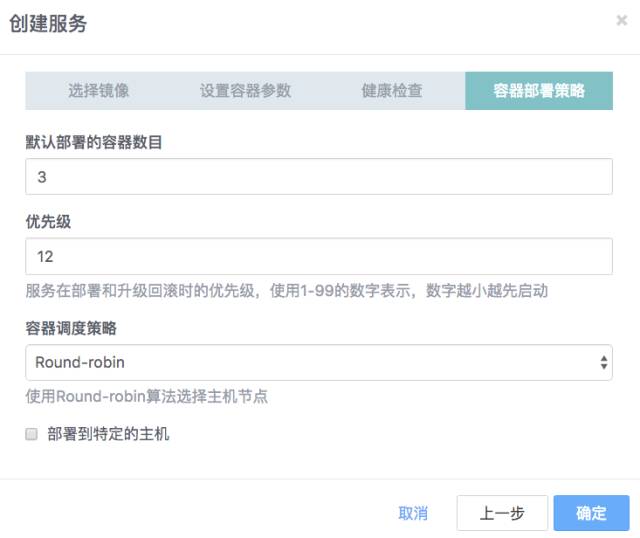
mongos必须在configdb集群初始化后运行, 接下来我们开始编排mongo的数据节点服务,这是集群中最复杂的部分
准备shard节点的配置文件
cat mongo-shard.conf
systemLog:
verbosity: 0operationProfiling:
slowOpThresholdMs: 3000processManagement:
fork: falsestorage:
dbPath: /data/db
journal:
enabled: true
engine: wiredTiger
{{ $num := (parseInt .REPLICA_NUM) |add 1 }}
{{ $cn := (parseInt .Container.Seq) |subtract 1 }}
{{ $rsn := $cn |divide $num }}
replication:
replSetName: RS{{$rsn}}变量REPLICA_NUM表示每个主有几个从,默认为2
这里将123个容器编为RS0,456编为RS1,789编为RS2,10,11,12编为RS3
编排mongo shard服务
第一步 添加mongo镜像,指定cmd参数
第二步 设置参数,关联配置
第三步 健康检查

第四步 设置部署

有了上面的数据节点后,我们发现,还没有初始化replset,也没有将每个replset加入到sharding里,下面我们来做shard初始化工作
初始化sharding集群
#!/bin/bash
set -e
{{$s := service "mongo"}}
{{$n := (parseInt .REPLICA_NUM) |add 1}}
{{$slices := $s.ContainerNum |divide $n}}
{{$port := .Port}}
echo begin to init replica set ...
for i in {0..{{$slices |subtract 1}}}; do
bn=$(( $i * {{$n}} + 1 ))
en=$(( $bn + {{.REPLICA_NUM}} ))
RS_NODE=
RS_NODE_CONFIG=
ii=$bn
while [ $ii -le $en ]; do
RS_NODE=$RS_NODE$ii.mongo.{{.Instance.Name}}.csphere.local:{{$port}},
RS_NODE_CONFIG=$RS_NODE_CONFIG"{_id:$ii, host: \"$ii.mongo.{{.Instance.Name}}.csphere.local:{{$port}}\"},"
ii=$(($ii + 1))
done
RS_NODES=$(echo $RS_NODE|sed 's/,$//')
RS_NODES_CONFIG=$(echo $RS_NODE_CONFIG|sed 's/,$//')
cat > /tmp/RS$i.js <<EOF
config = {
_id : "RS$i",
members : [
$RS_NODES_CONFIG
]
}
rs.initiate(config)
rs.status()
EOF
## connect to 0.mongo/3.mongo...
begin_mongo=$bn.mongo.{{.Instance.Name}}.csphere.local
mongo $begin_mongo /tmp/RS$i.js
sleep 3
j=0
while [ $j -lt 10 ]; do
mongo $begin_mongo --eval "rs.status()" | grep PRIMARY && break
j=$(($j + 1))
sleep 2
done
if [ $j -eq 10 ]; then
echo RS$i initianized failed
exit 1
fi
echo RS$i initinized ok
echo begin to add RS$i to sharding ...
mongo --eval "sh.addShard(\"RS${i}/$RS_NODES\")" 1.mongos.{{.Instance.Name}}.csphere.local
done上面的脚本稍微有点复杂,基本逻辑就是,先初始化每个replicaset集群RS0..RS3,并将每个RS加入到sharding集群当作分片slices。具体可以参考上面的部署拓扑图。
开始编排shard-init服务
该服务是one-off执行
第一步 添加镜像,指定cmd为init.sh
第二步 设置参数,同步脚本init.sh

第三步 设置部署优先级
到这里mongo sharding集群的编排工作基本就完成了。接下来我们为mongo服务添加一个可视化面板,方便我们的使用
编排mongo-express服务
第一步 添加mongo express镜像
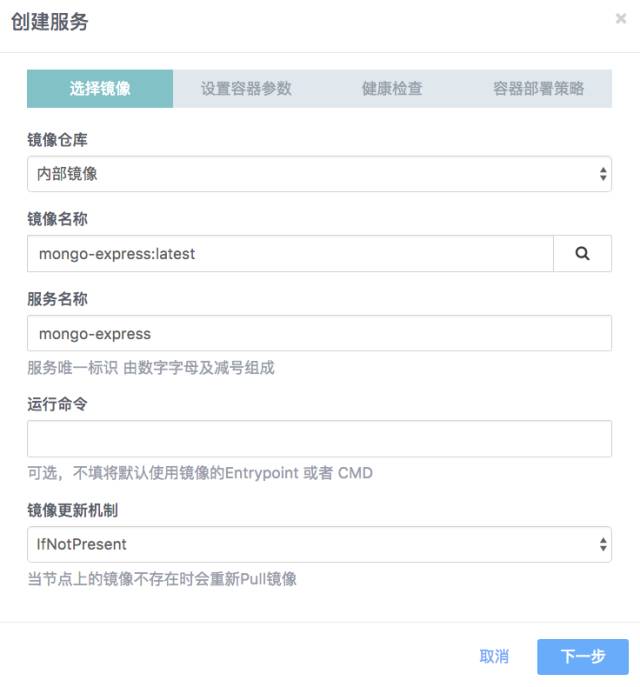
第二步 设置环境变量
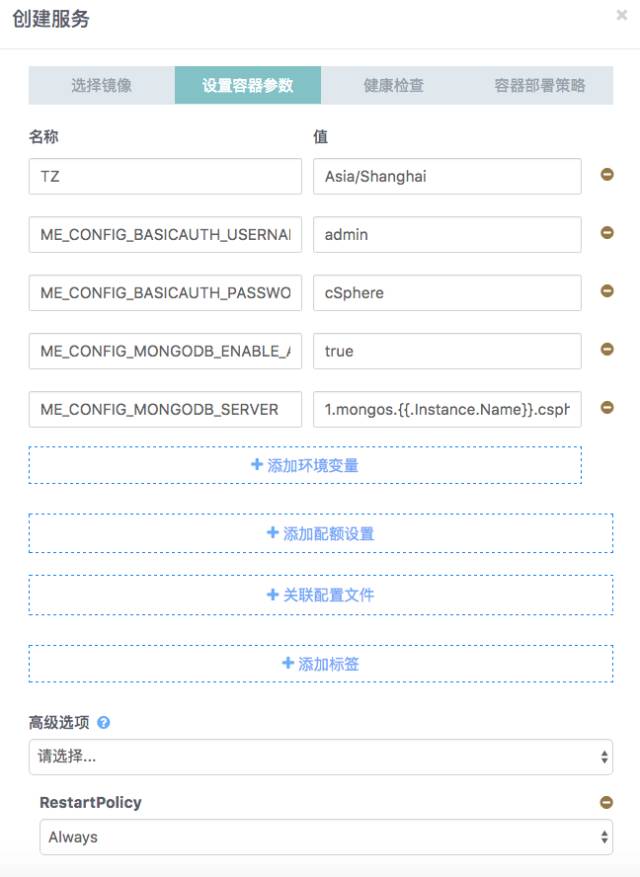
第三步 健康检查
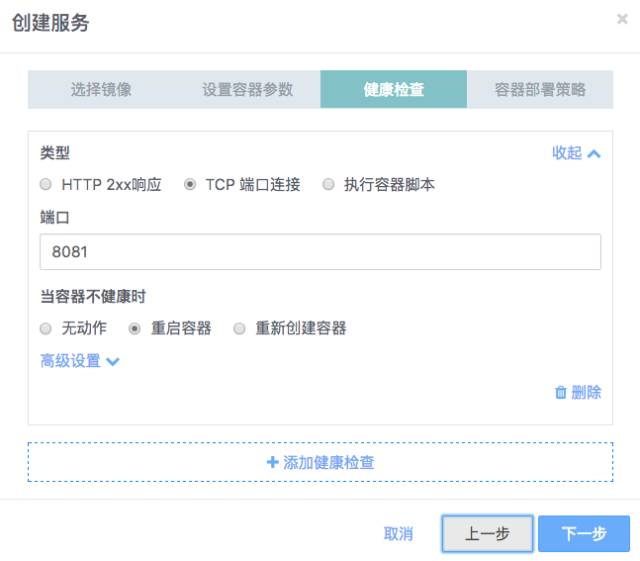
第四步 设置部署优先级
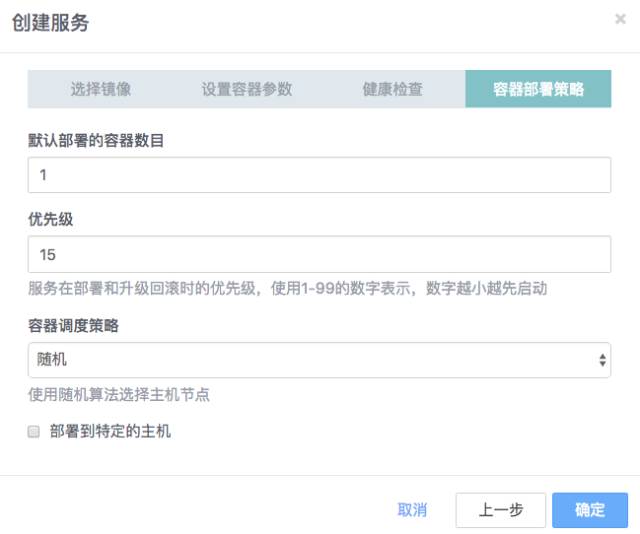
至此,编排工作全部完成。下面我们来测试刚才的工作成果。。
部署测试
点击部署,生成一个应用实例,我们命名为m。
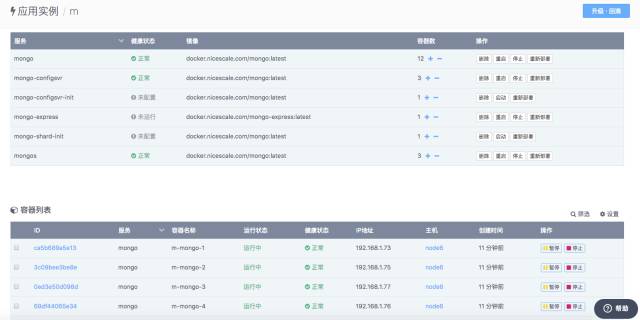
我们看一下shard-init的初始化输出: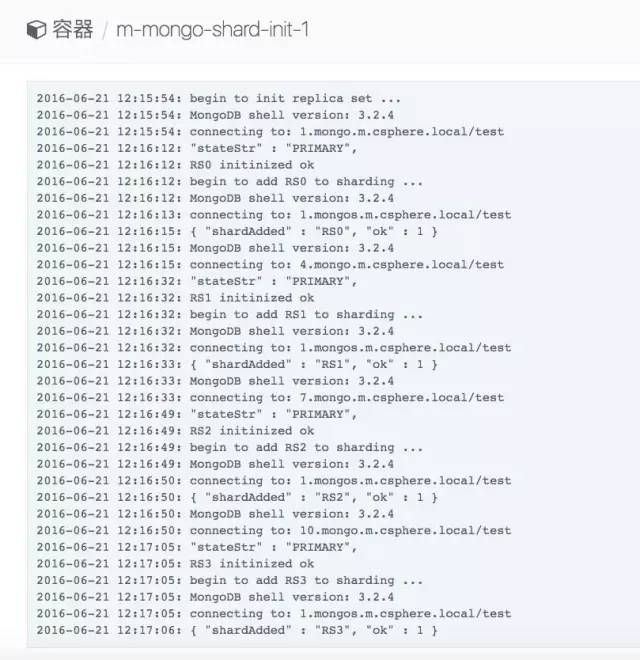
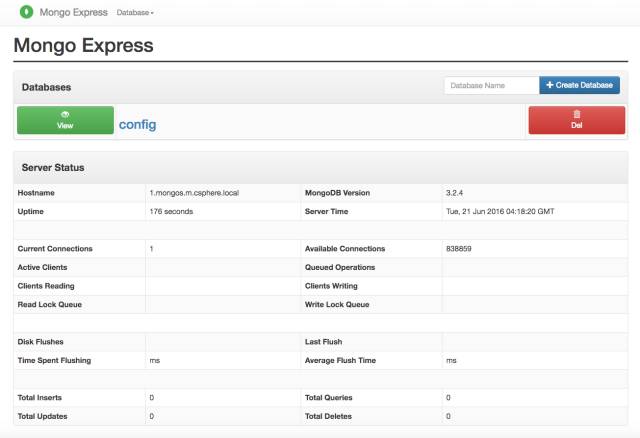
我们看一下面板express的输出:
这是mongo express的首页,可以查看到该mongos上的访问概括
我们查看config这个db下表里的数据,特别是和集群配置有关的:
mongos表: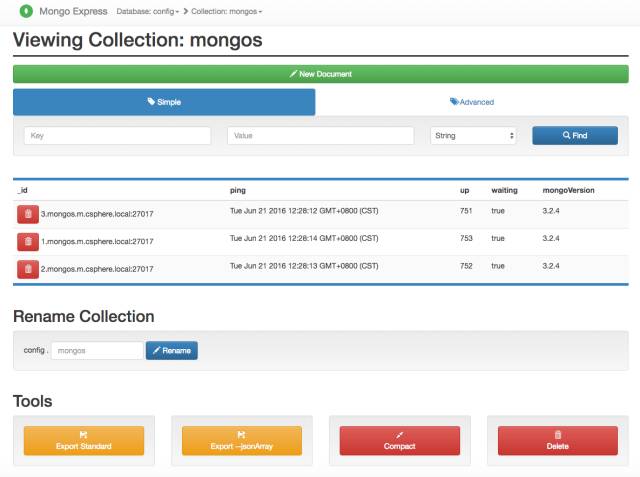
有哪些分片呢?我们看到了RS0 RS1 RS2 RS3:
我们可以创建一个名为csphere的db试试:
后续,可以参考mongo文档,在开发中,设置您的sharding key等。更进一步的mongodb管理,请参考官方文档。
总结
从mongodb集群的自动化交付看整个编排过程,我们发现背后的魔法关键是:DISCOVERY ALL,发现所有的东西并使之具有可编程特性。
Q&A
Q1: 你好 目前这个的实际应用情况如何?有何挑战?
A1: 实际测试运行良好。挑战在于编排过程,背后的discovery能力能否满足自动化的能力。在实际生产中,可以优化您的配置文件,如挑战timeout等,或日志的loglevel
Q2: 模板文件通过什么语言进行渲染,通过什么流程发现启动容器的信息?
A2: 希云cSphere平台背后有一套强大的配置模版引擎,golang模版。平台的协调中心可以发现各种参数并进行可编程去应对自动化挑战
Q3: 你好 mongodb群集性能瓶颈,监控指标你觉得最重要的是什么,扩容的时候要注意什么?
A3: mongo集群在使用上注意存储引擎的选择,在3.2之前是mmap,3.2已经调整,新的默认引擎能够更好的处理大数据量的问题。mongo的水平扩展本身很好,注意mongos代理部署的多一点,避免流量从单个mongos流入流出
QQ 2群:131961942,加入密码大写KVM
千人VMWare技术交流群:494084329,加入密码小写vm
OpenStack开发纯技术群: 334605713 加入密码nova
Cloudstack纯技术交流群:515249455密码cs
桌面云行业讨论: 484979056 加入密码大写VDI
以上是关于如何使用容器实现生产级别的MongoDB sharding集群的一键交付的主要内容,如果未能解决你的问题,请参考以下文章
如何使用容器实现生产级别的MongoDB sharding集群的一键交付
如何利用容器实现生产级别的redis sharding集群的一键交付
如何用容器实现生产级Redis sharding集群一键交付