干货分享记一次使用ShardingJdbc切分数据库表的SpringBoot工程实践
Posted 苏研大云人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货分享记一次使用ShardingJdbc切分数据库表的SpringBoot工程实践相关的知识,希望对你有一定的参考价值。

从之前的那篇《大型分布式业务平台数据库优化方法》(下)文章可见,水平切分数据库表是关系型数据库面对单表千万级别乃至上亿数据规模的一种有效解决方案。光有理论知识还不够,想要真正地在生产环境中来解决单表数据量过大的问题,还需要亲自动手实践下。本文主要将业界知名的开源分库分表中间件—ShardingJdbc集成至SpringBoot工程中,利用ShardingJdbc的数据库切分能力来实现库表水平切分和扩展的目标,提高分布式系统整体的并发量,解决数据库中的单表因数据量过大而带来得各种瓶颈和影响(本文所述的ShardingJdbc中间件以其1.X版本为参考,2.X版本和1.X版本有较大区别,在后面的文章中会有介绍)。
01
分库分表中间件ShardingJdbc介绍
ShardingJdbc是当当开源的数据库水平切分的中间件,其代表了客户端类的分库分表技术框架(这一点与MyCat不同,MyCat本质上是一种数据库代理)。ShardingJdbc定位为轻量级数据库驱动,由客户端直连数据库,以jar包形式提供服务,未使用中间层,无需额外部署,无其他依赖,业务系统开发人员与数据库运维人员无需改变原有的开发与运维方式。因此ShardingJdbc即为增强版的JDBC驱动,可以实现旧代码迁移零成本的目标。
下面的是ShardingJdbc的架构图:
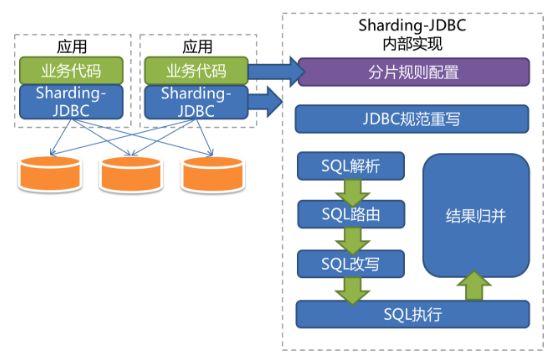
从上面的架构图中,可以看出ShardingJdbc与业务工程集成起来十分方便与快捷,同时其提供的分片规则配置、SQL解析、SQL改写、SQL路由、SQL执行以及结果归并等强大的功能,使得业务开发人员无需在这些方面花费较大多的精力,而可以更加专注于业务流程的开发。其主要的特点如下:
(1)分片规则配置
ShardingJdbc的分片逻辑非常灵活,支持分片策略自定义、复数分片键、多运算符分片等功能。
(2)JDBC规范重写
ShardingJdbc中间件对标准JDBC规范的重写思路是针对DataSource、Connection、Statement、PreparedStatement和ResultSet五个核心接口封装,将多个JDBC实现类集合(如:mysql JDBC实现/DBCP JDBC实现等)纳入ShardingJdbc实现类管理。
(3)SQL解析
SQL解析作为分库分表类中间件框架的核心之一,其性能和兼容性是最重要的衡量指标。目前常见的SQL解析器主要有fdb/jsqlparser和Druid。在ShardingJdbc1.5.0之前的版本是采用解析速度相对最快的Druid作为SQL解析器。ShardingJdbc在1.5.0.M1 正式发布时,将SQL解析引擎从Druid替换成了自研的。新引擎仅解析分片上下文,对于 SQL 采用“半理解”理念,进一步提升性能和兼容性,同时降低了代码复杂度。
(4)SQL改写
这里一部分是将分表的逻辑表名称替换为实际真实的分表名称。另一部分是根据SQL解析结果替换一些在分片环境中不正确的功能。其中,1.5.0之前的版本,SQL改写是在SQL路由之前完成的,而在1.5.x中调整为SQL路由之后,因为SQL改写可以根据路由至单库表还是多库表而进行进一步优化。
(5)SQL路由
SQL路由是指根据分片规则配置,将待执行的SQL定位至真正的DB数据源。
(6)SQL执行
这里指的是路由至真实的DB数据源后,ShardingJdbc将采用多线程并发执行SQL,并完成对addBatch等批量方法的处理。
(7)结果归并
ShardingJdbc支持通遍历类、排序类、聚合类和分组类四种结果并归方式。普通遍历类最为简单,只需按顺序遍历ResultSet的集合即可。排序类结果则将结果先排序再输出,因为各分库的分片结果均按照各自条件完成排序,所以采用归并排序算法整合最终结果。聚合类分为3种类型,比较型、累加型和平均值型。分组类相对最为复杂,需要将所有的ResultSet结果放入内存,使用Map-Reduce算法分组,最后根据排序和聚合条件做相关处理。最为消耗内存,损失性能的地方就是这里了,可以考虑使用limit合理的限制分组数据大小。
02
在Spring Boot中实践ShardingJdbc
本节将主要详细介绍在SpringBoot工程中如何集成ShardingJdbc这款切分库表的中间件,并使用其完成对库表的切分/路由,以及在业务开发中的使用。
版本环境
Spring Boot 1.4.1.RELEASE、Druid 1.0.12、JDK 1.8
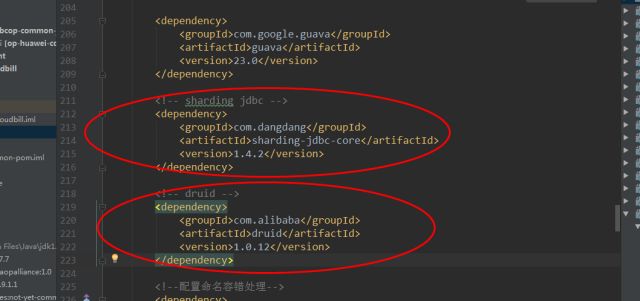
在SpringBoot工程中添加ShardingJdbc的pom依赖
因为当当开源了ShardingJdbc的源码,我们可以通过maven仓库来获得jar包依赖。当访问http://mvnrepository.com/artifact/com.dangdang/sharding-jdbc-core(该链接为1.X版本的)选择自己项目需要的版本(在本次集成中选择的版本为1.4.2),点击进入后复制maven内容到pom.xml内即可。同时,这里需要注意的是在ShardingJdbc 1.5.0.M1正式发布以前,SQL解析引擎仍然是采用阿里的Druid数据源连接池,还需要在Pom中引入Druid的依赖(版本为1.0.12),此外需要保证ShardingJdbc与Druid版本相对应,否则在执行SQL解析时候会导致ShardingJdbc的运行时异常。Pom文件的引入如下图所示:
在SpringBoot工程中的yaml文件配置
在MySql数据库中创建相应的分库和分表后,需要在SpringBoot工程中的yaml配置文件(或property配置文件)中完成对分库数据源的配置,具体如下:
###分库0配置,具体的ip/host:port和数据库用户名和密码根据实际填写
testShardingDB0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://{ip}:{port} /res_test_cloud_bill_sharding0?useUnicode=true&characterEncoding=utf-8
username: xxxxxx
password: xxxxxx
max-idle: 500
max-active: 100
min-idle: 50
initial-size: 50
validation-query: SELECT 1
max-wait: -1
test-on-borrow: true
test-on-return: true
test-while-idle: true
num-tests-per-eviction-run: 3
time-between-eviction-runs-millis: 30000
min-evictable-idle-time-millis: 18000000
removeAbandoned: true
removeAbandonedTimeout: 180
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: false
maxPoolPreparedStatementPerConnectionSize: -1
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
###分库1配置,具体的ip/host:port和数据库用户名和密码根据实际填写
testShardingDB1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql:// {ip}:{port}/res_test_cloud_bill_sharding1?useUnicode=true&characterEncoding=utf-8
username: xxxxxx
password: xxxxxx
max-idle: 500
max-active: 100
min-idle: 50
initial-size: 50
validation-query: SELECT 1
max-wait: -1
test-on-borrow: true
test-on-return: true
test-while-idle: true
num-tests-per-eviction-run: 3
time-between-eviction-runs-millis: 30000
min-evictable-idle-time-millis: 18000000
removeAbandoned: true
removeAbandonedTimeout: 180
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: false
maxPoolPreparedStatementPerConnectionSize: -1
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
ShardingJdbc分库分表的Bean配置
引入了ShardingJdbc中间件后,在SpringBoot工程中可以通过配置Bean来初始化分库分表的数据源,其中需要设置逻辑表与实际分表的映射关系和分库分表的ID路由策略。
@Configuration
@MapperScan(basePackages = "com.chinamobile.bcop.test.sharding.xxxxxxxx", sqlSessionTemplateRef = "shardingSqlSessionTemplate")
public class MybatisTestShardingConfig {
@Bean(name = "testShardingDB0")
@ConfigurationProperties(prefix = "spring.datasource.tesetShardingDB0")
public DataSource testShardingDataSource0(){
return new DruidDataSource();
}
@Bean(name = "testShardingDB1")
@ConfigurationProperties(prefix = "spring.datasource.testShardingDB1")
public DataSource testShardingDataSource1(){
return new DruidDataSource();
}
@Bean(name = "dataSourceRule")
public DataSourceRule dataSourceRule(@Qualifier("testShardingDB0") DataSource ds0, @Qualifier("testShardingDB1") DataSource ds1){
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("shardingDataSource0", ds0);
dataSourceMap.put("shardingDataSource1", ds1);
return new DataSourceRule(dataSourceMap, "shardingDataSource0");
}
@Bean(name = "shardingRule")
public ShardingRule shardingRule(@Qualifier("dataSourceRule")DataSourceRule dataSourceRule){
//表策略
//设置分表映射,将test_msg_queue_bill_record_0~test_msg_queue_bill_record_4
// 几个实际的表映射到test_msg_queue_bill_record逻辑表
//0~4几个表是真实的表,test_msg_queue_bill_record是个虚拟不存在的表,只是供使用
TableRule orderTableRule = TableRule.builder(
"test_msg_queue_bill_record")
.actualTables(Arrays.asList(
"test_msg_queue_bill_record_0",
"test_msg_queue_bill_record_1",
"test_msg_queue_bill_record_2",
"test_msg_queue_bill_record_3",
"test_msg_queue_bill_record_4"))
.dataSourceRule(dataSourceRule)
.build();
//绑定表策略,在查询时会使用主表策略计算路由的数据源,因此需要约定绑定表策略的表的规则需要一致,可以一定程度提高效率
List<BindingTableRule> bindingTableRules = new ArrayList<BindingTableRule>();
bindingTableRules.add(new BindingTableRule(Arrays.asList(orderTableRule)));
return ShardingRule.builder()
.dataSourceRule(dataSourceRule) .tableRules(Arrays.asList(orderTableRule))
.bindingTableRules(bindingTableRules)
.databaseShardingStrategy(new DatabaseShardingStrategy("CUSTOMER_ID", new CustomizedDbShardingStrategy()))
.tableShardingStrategy(new TableShardingStrategy("USER_ID", new CustomizedTableShardingStrategy()))
.build();
}
@Bean(name = "testShardingDataSource")
public DataSource shardingDataSource(@Qualifier("shardingRule")ShardingRule shardingRule){
return ShardingDataSourceFactory.createDataSource(shardingRule);
}
//需要手动声明配置事务
@Bean(name = "testShardingTransactionManager")
public DataSourceTransactionManager transactitonManager(@Qualifier("testShardingDataSource") DataSource dataSource){
return new DataSourceTransactionManager(dataSource);
}
//MyBatis SqlSessionFactory/SqlSessionTemplate/MybatisDAO的Bean初始化省略
//……..
在本文的示例中,按照业务要求先对原来的单库单表进行拆分,由原来的单库单表—test_msg_queue_bill_record,分成两个库的多表(每个库中均有test_msg_queue_bill_record0~test_msg_queue_bill_record4五个分表,这里只是示例,在真实的业务场景下需要根据业务数据的总体容量来设定分库分表的规模,究竟是分5个库每个库5表,还是分10个库每个库10表来满足业务要求)。由上面的分库分表配置Bean的代码可见,使用Druid连接池初始化两个分库的数据源后设置ShardingJdbc数据源的分片规则。其中,test_msg_queue_bill_record表为逻辑表,分别与test_msg_queue_bill_record0~test_msg_queue_bill_record4的实际分表名建立映射。如果执行的SQL为“select * from test_msg_queue_bill_record” 就能遍历查完hw_msg_queue_bill_record0~4五个分表。最后,在设置切分规则时候,分别以customerId和userId作为切分数据库和切分数据表的路由规则。根据上面的配置可以得到下面的分库分表逻辑视图:
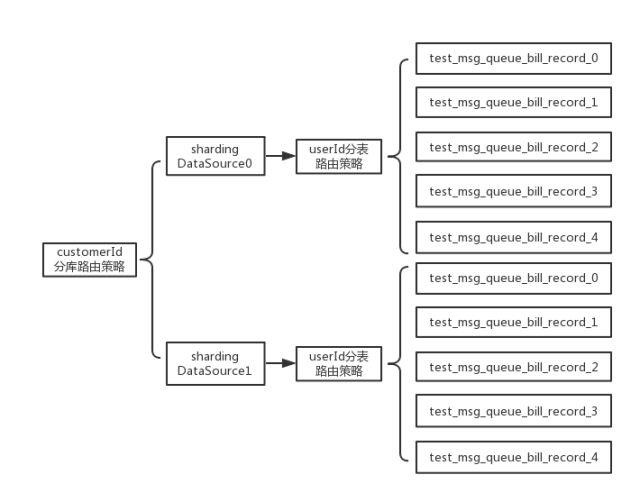
具体的库表分片路由策略
ShardingJdbc对分片路由策略完全采用开放式的,将这一部分的控制权交给业务侧开发人员手中。业务开发人员可以根据具体业务的需求,设置灵活的分库分表路由策略。在上一节的示例代码中,可以看到在设置分库分表规则的时候有两个比较显著的类——CustomizedDbShardingStrategy和CustomizedTableShardingStrategy。正是这两个类完成了自定义的库表的自定义分片路由策略,CustomizedDbShardingStrategy的示例代码如下:
public class CustomizedDbShardingStrategy implements SingleKeyDatabaseShardingAlgorithm<String> {
@Override
public String doEqualSharding(Collection<String> databaseNames, ShardingValue<String> shardingValue) {
//在这里设置具体的条件为“=”的分库策略
//code here
}
@Override
public Collection<String> doInSharding(Collection<String> databaseNames, ShardingValue<String> shardingValue) {
//在这里设置具体SQL语句条件为“In”的分库策略
//code here
}
@Override
public Collection<String> doBetweenSharding(Collection<String> databaseNames, ShardingValue<String> shardingValue) {
//在这里设置具体的SQL语句条件为“between”的分库策略
//code here
}
CustomizedTableShardingStrategy的示例代码如下:
public class CustomizedTableShardingStrategy implements SingleKeyTableShardingAlgorithm<String> {
@Override
public String doEqualSharding(Collection<String> tableNames, ShardingValue<String> shardingValue) {
//在这里设置具体的条件为“=”的分表策略
//code here
}
@Override
public Collection<String> doInSharding(Collection<String> tableNames, ShardingValue<String> shardingValue) {
//在这里设置具体SQL语句条件为“In”的分表策略
//code here
}
@Override
public Collection<String> doBetweenSharding(Collection<String> tableNames, ShardingValue<String> shardingValue) {
//在这里设置具体的SQL语句条件为“between”的分表策略
//code here
}
先看分库表路由策略中的doEqualSharding方法,比如对于SQL语句—“Insert into test_msg_queue_bill_record(CUSTOMER_ID,USER_ID,xxxx1,xxxx2……)values(‘test_custid_111111’,’test_userid_22222’,’xxxx1’,’xxxx2’……)”,doEqualSharding方法中的形参databaseNames为分库的名称(比如shardingDataSource0数据源对应的实际分库名称为res_test_cloud_bill_sharding0),shardingValue为分库的键值(在前一节分库分表Bean配置中设定),也就是对应该SQL语句中的“test_custid_111111”,我们可以在doEqualSharding方法中设置适合业务需求的键值分片路由规则,比如以“test_custid_111111”的哈希值作为分片路由规则来选择该插入SQL究竟应该路由至实际的哪个分库的哪个分表来执行。而另外的两个方法,doInSharding和doBetweenSharding则是作用在SQL条件为“Between”和“In”的语句上。
分布式主键生成
对于传统的数据表设计而言,主键自增都是基本需求。对MySQL而言,分库分表之后,不同表生成全局唯一主键是较为头疼的问题。因为同一个逻辑表所对应的不同实际分表之间的自增键是无法感知,这样会造成有部分分表的主键值重复。我们当然可以通过分表的约束规则来达到数据不重复,但是这需要引入额外的方法来解决重复性问题。
目前,有许多第三方技术方案可以解决该问题,比如flickr的全局主键生成方案和uuid的全局主键生成方案。ShardingJdbc在设计之初也有考虑过这个问题,提供了自己的实现方案,其分布式全局ID自动生成器可以根据时间偏移量、工作进程id和同一毫秒的自增量来生成一个64位的Long型数值以保证其全局唯一性。
在工程中需要在pom中添加依赖如下:
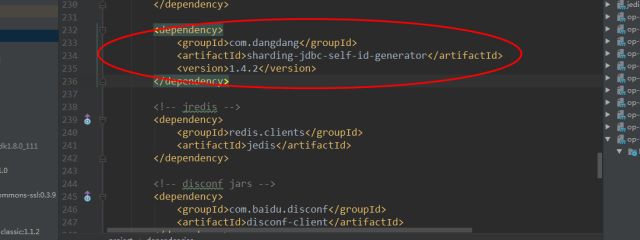
在配置中需要完成对其Bean对象的初始化,具体代码如下:
@Bean(name = "shardingIdGenerator")
public IdGenerator getIdGenerator() {
return new CommonSelfIdGenerator();
}
使用ShardingJdbc编写自定义的Dao
经过上面几节内容后,这一节就可以使用配置后的ShardingJdbc所对应的MybatisDao来完成一些业务的应用了。
public abstract class AbstractResBillShardingDao {
@Qualifier(value = "hwShardingMyBatisDao")
@Autowired
protected IMybatisDAO mybatisShardingDao;
@Qualifier(value = "shardingIdGenerator")
@Autowired
private IdGenerator idGenerator;
public <T extends BillRecord> int shardingInsertRows (List<T> resBillRecordList, String resType) {
int resultRowNum = 0;
try {
String shardingInsertSqlMapper = MyBatisMapperMapping.ResBatchInsertMapper.getBatchInsertMapperByTypeCode(resType);
if(StringUtils.isEmpty(shardingInsertSqlMapper)) {
log.info("无法匹配到对应的sqlmapper的statement,直接返回,无法匹配的资源类型为:{}",resType);
return resultRowNum;
}
for(BillRecord msgQueueBillRecord:resBillRecordList) {
//设置分布式id主键msgQueueBillRecord.setId(idGenerator.generateId().longValue());
resultRowNum+=mybatisShardingDao.insert(shardingInsertSqlMapper, msgQueueBillRecord);
}
} catch (Exception ex) {
log.error("批量插入数据出现异常", ex);
}
return resultRowNum;
}
}
可以看到在这个Dao的类中,批量插入方法—shardingInsertBills,通过自动注入的mybatisShardingDao和idGenerator来完成对数据记录的切分插入,这里需要注意ShardingJdbc目前尚未支持批量插入的SQL语句,因此需要在代码中自己完成遍历数据集合后的单行插入,这里idGenerator用于生成每个待插入记录的全局唯一健值。工程运行的截图日志如下:
03
使用ShardingJdbc的限制
ShardingJdbc中间件并非是万能,它还是有一些SQL和JDCB接口的使用限制,其最大的使用限制在于如下几点:
(1)对于DataSource接口不支持超时相关的操作。
(2)对于Connection接口不支持存储过程、游标、函数、savePoint、自定义类型映射等。
(3)对于Statement和PreparedStatement接口,不支持返回多结果集的语句和国际化操作。
(4)对于ResultSet接口,不支持对于结果集指针位置判断;不支持通过非next方法改变结果指针位置;不支持修改结果集内容。
(5)SQL语句限制:不支持HAVING;不支持OR,UNION 和 UNION ALL;不支持特殊INSERT,尤其是是批量插入的SQL语句;不支持DISTINCT聚合;不支持dual虚拟表;不支持SELECT LAST_INSERT_ID();不支持CASE WHEN。
04
总结
本文主要介绍了如何在Spring Boot工程中完成数据库切分中间件—ShardingJdbc集成以及如何进行分库分表配置、库表分片路由策略设置和分布式主键生成关键点的阐述。限于笔者的才疏学浅,对本文内容可能还有理解不到位的地方,如有阐述不合理之处还望留言一起探讨。
END
往期精选
1.
2.
3.
以上是关于干货分享记一次使用ShardingJdbc切分数据库表的SpringBoot工程实践的主要内容,如果未能解决你的问题,请参考以下文章
西安校区面试经验独家分享记一次外包公司Java工程师面试过程