集成 Proxy 与 DB Mesh,Sharding-JDBC 3.0 将“Sharding”做到极致
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集成 Proxy 与 DB Mesh,Sharding-JDBC 3.0 将“Sharding”做到极致相关的知识,希望对你有一定的参考价值。
提
起数据库中间件,我们可以很自然地联想到 OneProxy、TDSQL、Sharding-JDBC 与 MyCat 等知名项目。在众多的数据库中间件实现技术中,通常存在两种架构模式:
一种是 Proxy 架构(服务端架构),它独立部署,与应用分开,对不同数据库进行统一代理,以集群形式对数据库流量进行集中式管理与监控;
另一种模式是客户端架构,常见形式是对 JDBC 进行修改与扩展,也就是中间件与应用不分开部署,在应用层对数据源进行管控。
这两种模式都有各自的优势与弱处,比如:
Proxy 架构因其统一代理数据库,所以便于维护,且可以解决连接数问题,但它要求中间层集群,会有硬件成本开销,同时中间层的数据进行合并,也需要考虑隔离机制;
客户端架构,因为不需要中间层集群,应用是直连数据库的,所以使它性能更高,同时也没有了 Proxy 架构的弱势,但是直连数据库,中间件与应用耦合在一起,使得管理监控和升级维护比较麻烦。可以说二者是相互对立的形式。
Sharding-JDBC 分布式数据库中间件,顾名思义,它是基于 JDBC 的。它被定义为轻量级 Java 框架,使用客户端直连数据库,以 jar 包形式提供服务,对 ORM 透明,完全兼容 JDBC 和各种 ORM 框架。它在 Java 的 JDBC 层以对业务应用零侵入的方式额外提供数据分片、读写分离、柔性事务和分布式治理能力。
更进一步来说,Sharding-JDBC 是基于客户端的架构模式,这也就导致它带上了前边提到的那些问题,于是很多不是 Java 开发背景的工程师吐槽“为什么 Sharding-JDBC 是一个应用层的框架,而不是独立部署的 Proxy?”
在今年年初接受开源中国专访的时候,谈及 Sharding-JDBC 的发展计划,项目创建者张亮就解释过:“一个很重要的原因就是它的前身 dd-rdb 是当当内部的 Java 应用框架。”
历史遗留问题比较麻烦,但是张亮表示,未来的 Sharding-JDBC 将会变得多元化,除了提供 Proxy 版本,还将支持 Agent:
未来 Sharding-JDBC 也会多样化,将提供 Proxy 的版本。另外除了 Proxy,也会提供 Agent 版本。所谓的 Agent 版本与现在流行的 Service Mesh 模式较为相似,Service Mesh 通过 Sidecar 去代理和管控流量,而 Sharding-JDBC 希望通过同样的 Sidecar 的方式代理和管控 SQL,以做到非侵入和跨语言的 Database Mesh。
如今,Sharding-JDBC 集成 Sharding-Proxy 与 Sharding-Sidecar,以全新项目 Sharding-Sphere 的形式重新出发,重磅发布。
在 Sharding-Sphere 中,之前的发展计划被具体成了对应的子项目,Sharding-Proxy 是 “Sharding-JDBC 的 Proxy 版本”,Sharding-Sidecar 成为 “Sharding-JDBC 的 Agent 版本”,二者与 Sharding-JDBC 基础的集成,希望以全套方案去弥补 Proxy 与客户端架构的不足,将对数据库的数据分片、读写分离、柔性事务与数据治理做到极致。开源中国借此机会采访了项目负责人张亮,请他分享了此次重大更新的具体细节,以下是对话实录。
嘉宾介绍
张亮,京东金融数据研发负责人。
热爱开源,目前主导两个开源项目 Elastic-Job 和 Sharding-Sphere(Sharding-JDBC)。擅长以 Java 为主的分布式架构以及以 Kubernetes 和 Mesos 为主的云平台方向,推崇优雅代码,对如何写出具有展现力的代码有较多研究。
目前主要精力投入在将 Sharding-Sphere 打造为业界一流的金融级数据解决方案上。

问答

1、现在 Sharding-JDBC 项目是个什么情况?包括版本、团队和目前的研发进度等信息。
Sharding-JDBC 自2016年1月开源至今,一直处于高速发展中,目前为止已经发布了28个版本迭代。目前已经有52家公司明确声明正在使用 Sharding-JDBC 作为其数据库中间件。
随着 Sharding-JDBC 的逐渐推广,京东金融、当当、甜橙金融均已组建了全职的团队,并在同一个社区进行开发和维护。同时,有很多社区的活跃者在持续不断地贡献代码,提供着非常有价值的 pull request。
Sharding-JDBC 的主要版本是1.x和2.x,两个版本的 API 区别不大,1.x关注重点在于数据分片,2.x的关注重点在于数据治理。目前发布的3.x版本,同时也已经整合到了一个全新的项目 Sharding-Sphere 中,更加关注以多样化的方式支持更多的使用场景。
2、介绍一下整合后的项目 Sharding-Sphere 的基本信息,包括它整体的功能定位、市场定位等。
Sharding-Sphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
它与 NoSQL 和 NewSQL 并非是互斥的,而是并存的关系。NoSQL 和 NewSQL 作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。关系型数据库当今依然占有巨大市场,未来也难于撼动,因此,我们目前阶段更加关注的不是颠覆原有的技术,而是在原有的基础上进行增量。
Sharding-Sphere 包含三个子项目:Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar。它主要用于透明化分布式数据库所带来的 SQL、事务以及治理方面的相关复杂度,让用户像使用一个数据库一样管理和使用散落在系统各个部分的数据库。
它并非一个产品,而是由三个独立产品所组成的分布式数据库生态圈,用户可以根据自己的场景选择 Sharding-JDBC、Sharding-Proxy 或是 Sharding-Sidecar,也可以混合使用。Sharding-Sphere 的三个产品都以同一套核心代码提供数据分片、读写分离、柔性事务以及数据治理能力。
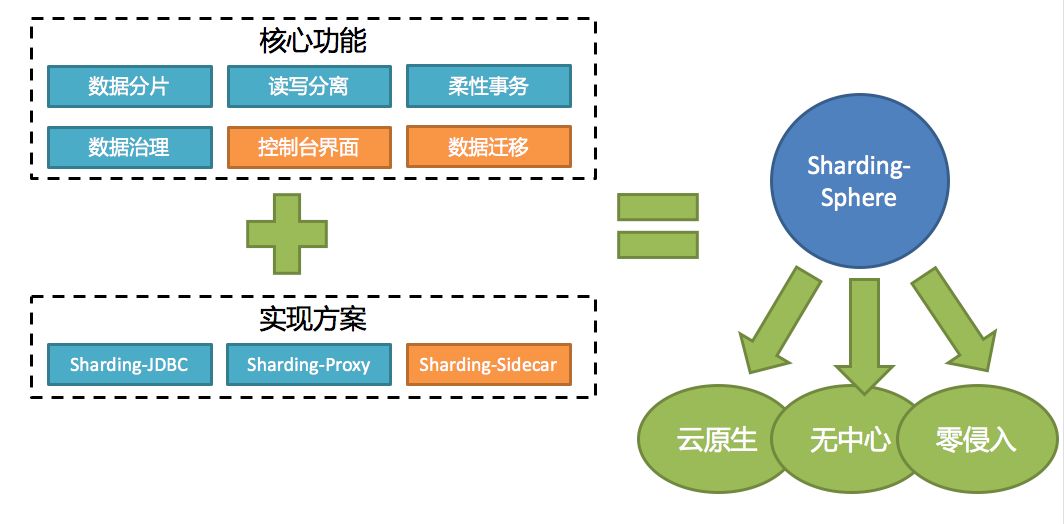
Sharding-Sphere 定位于金融云服务,未来将会作为京东金融云对外的数据库云提供服务,也是未来京东金融云对外输出的核心产品。
3、介绍一下将 Sharding-JDBC 整合到新项目 Sharding-Sphere 的原因是什么?以及其它的一些背景、思考。
仅通过改写 JDBC 层进行数据分片,难于支持更加多样化的场景,如: Java 之外的异构语言、数据库管理端命令行和 UI,等。为了支撑这些应用场景,我们开发了基于 mysql 代理端的 Proxy 版本,而原有的 JDBC 版本也得以保留,给用户的多样化场景提供更多选择。
我们无法放弃过去两年多 Sharding-JDBC 的影响力所带来的累积,因此,我们保留了 “Sharding” 这个关键词。而且,对于分布式数据库中间件来说,无论是分库分表、柔性事务还是数据治理,“Sharding” 是这一切的起源。
我们将原有的 Sharding-JDBC,新开发的 Sharding-Proxy 以及正在孵化中的 Sharding-Sidecar 一起组成了一个生态圈,并将其命名为 Sharding-Sphere,即 Sharding 圈。
Sharding-Sphere 三个子项目的对比如下图所示:
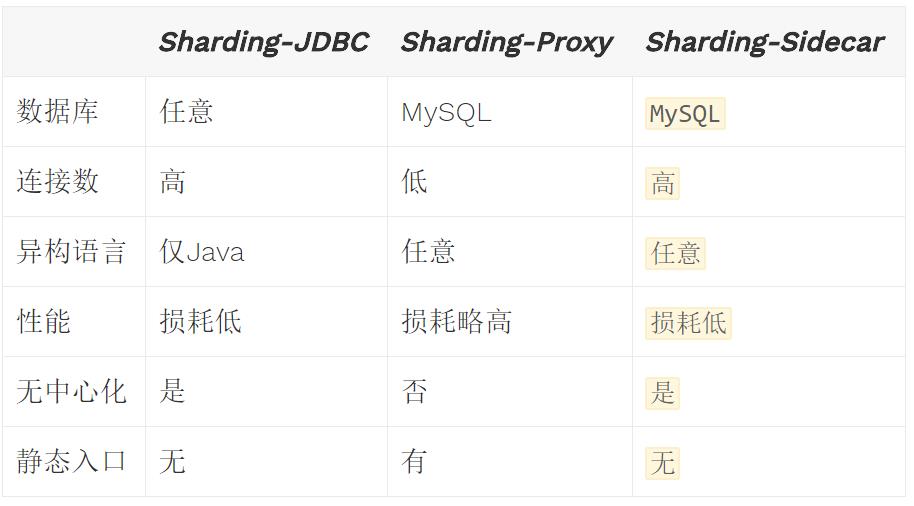
它们之间即可以独立使用,也可以相互配合,以不同的架构模型、不同的切入点,实现相同的功能目标,而其核心功能,如数据分片、读写分离、柔性事务等,都是同一套实现代码。
举个例子,对于仅使用 Java 为开发技术栈的场景,Sharding-JDBC 对各种 Java 的 ORM 框架支持度非常高,开发人员可以非常便利地将数据分片能力引入到现有的系统中,并将其部署至线上环境运行,而 DBA 可以通过部署一个 Sharding-Proxy 实例,对数据进行查询和管理。
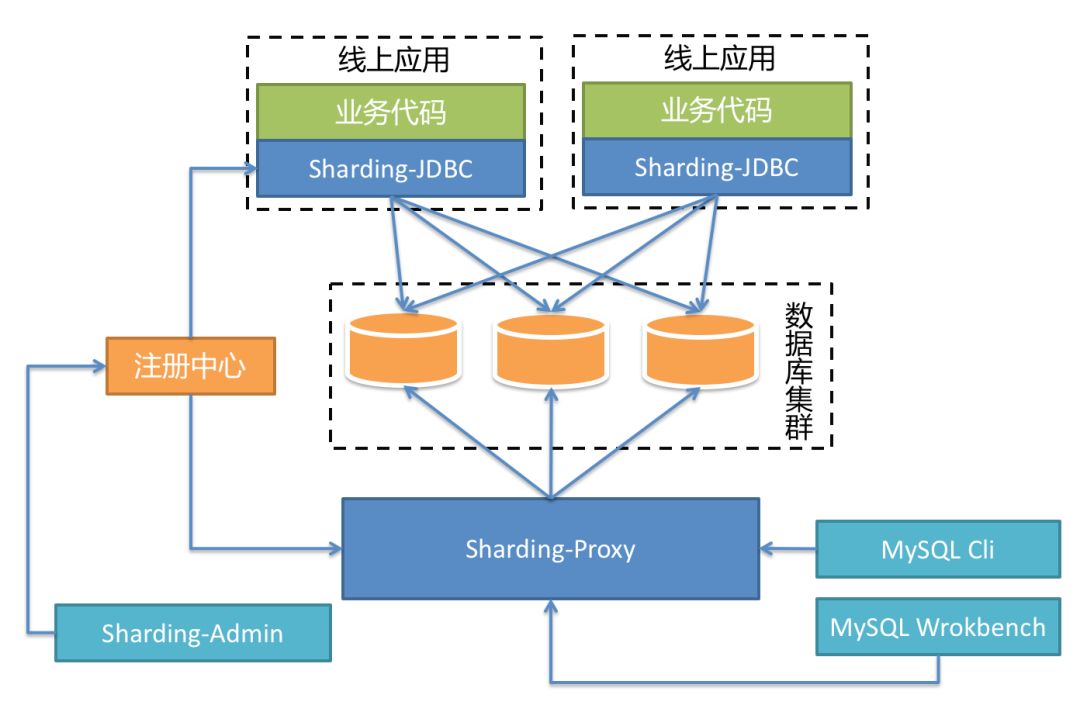
Sharding-Sphere 的各种组合,可以形成一套威力强大的分布式数据库体系。
4、Sharding-JDBC 是您在当当主导完成的,那它是属于个人项目还是公司项目?这对于现在将其作为一个模块整合到新项目 Sharding-Sphere 中有什么影响吗?
首先,非常感谢当当对开源一直以来秉承的开放态度,以及对 Sharding-JDBC 开源的大力支持。我们已经成立了 Sharding-JDBC(即 Sharding-Sphere)的 PMC(项目管理委员会),请参见:
http://shardingsphere.io/community/cn/organization/
Sharding-Sphere 既不属于某一公司,也不由个人掌控,而是一个完全社区性质的开源项目,PMC 成员以及贡献者也会随着项目的良性扩展而逐渐增加。
当前项目管理委员会包括了如下一些成员:
- 张亮,Java 技术和架构专家,京东
- 曹昊,当当高级架构师
- 吴晟,APM 和 tracing 专家,Apache SkyWalking 创建者 & PMC 成员
- 高洪涛,数据库和 APM 专家,Apache SkyWalking PMC 成员
Sharding-JDBC 作为 Sharding-Sphere 的一部分,也是完全按照社区的方式去运作的。
5、看到其中的 Sharding-Sidecar 模块,提供 Database Mesh ,很容易让人联想到最近正火的 Service Mesh ,那它们的相同与不同之处是什么呢?
Sharding-Sidecar 的优势在于对 Kubernetes 和 Mesos 的云原生支持。Sharding-Sidecar 目前还在孵化中,它的核心理念—— Database Mesh 的灵感确实来自于 Service Mesh。
Database Mesh 使用一个啮合层,将散落在系统各个角落中的数据库统一治理起来。通过啮合层集中在一起的应用与数据库之间的交互网络,就像蜘蛛网一样复杂而有序。从这一点来看,Database Mesh 的概念与 Service Mesh 如出一辙。
之所以称其为 Database Mesh,而非 Data Mesh,是因为它的首要目标并非啮合存储于数据库中的数据,而是啮合应用与数据库间的交互。
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效地梳理。使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
与 Service Mesh 的不同点在于其状态性以及 SQL 处理。
相比于服务,数据库是有状态的,无法像服务一样随意路由到对等节点,因此数据分片是一个重要的能力。相对来说,数据库实例的自动发现能力则不那么重要,原因也是数据库的有状态性,启动或停止一个新的数据库实例,往往意味着数据迁移。当然也可以采用多数据副本、读写分离、主库多写等方式进行进一步的处理。其它功能诸如对多从库的负载均衡、熔断、链路采集等,在数据库治理中也同样适用。
数据库需要使用 SQL 进行数据的访问与操作,为了达到最大的兼容性,数据库中间件同样需要采用 SQL 进行数据分片。分片是一个复杂的过程,如果希望做到对应用透明,业界常见的做法是针对 SQL 进行解析,并将其精准路由至相应的数据库中执行,最终将执行结果进行归并,以保证数据在分片的情况下逻辑仍然正确。
一个数据分片的核心流程是 SQL 解析 –> SQL路由 –> SQL改写 –> SQL执行 –> 结果归并。为了满足对遗留代码的零侵入,还需要对 SQL 的执行协议进行封装。比如,在代理端则需要模拟 MySQL 或其它相应数据库的通信协议;在 Java 客户端实现,则需要覆盖 JDBC 接口的相应方法。
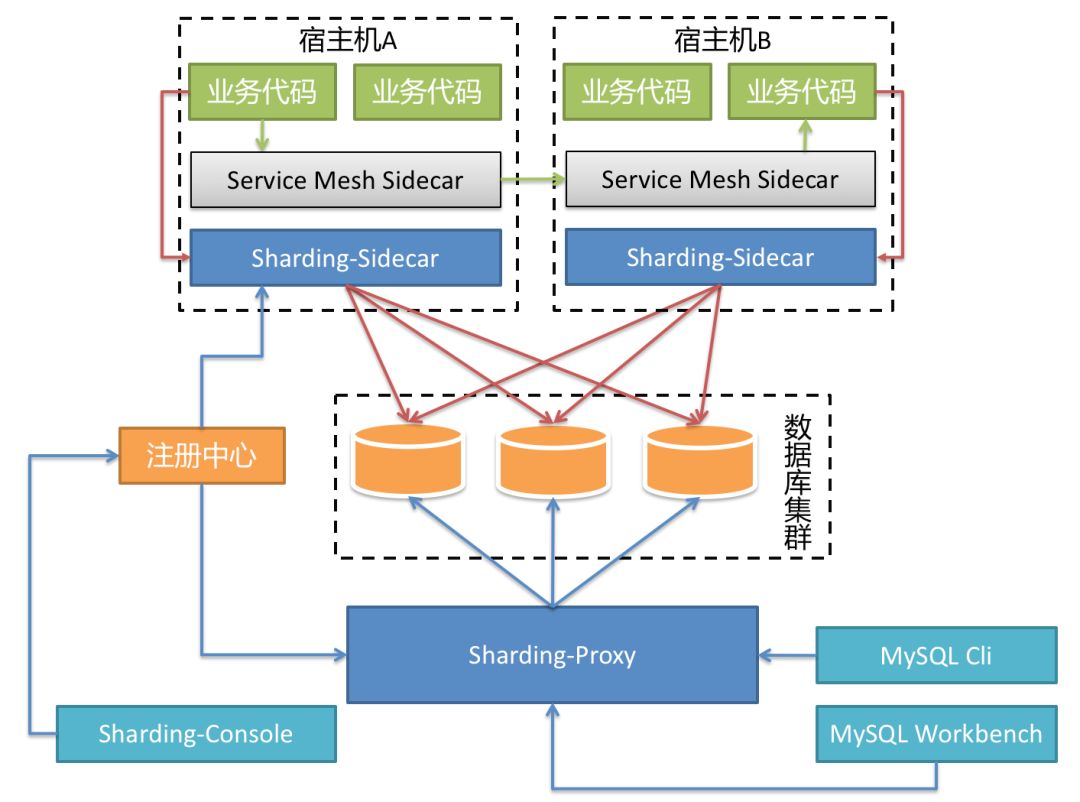
基于 Sharding-Sidecar 的 Database Mesh 与 Service Mesh 互不干扰,相得益彰。服务之间的交互由 Service Mesh Sidecar 接管,基于 SQL 的数据库访问由 Sharding-Sidecar 接管。对于业务应用来说,无论是 RPC 还是对数据库的访问,都无需关注其真实的物理部署结构,做到真正的零侵入。
由于 Sharding-Sidecar 是随着宿主机的生命周期创建和消亡的,因此,它并非静态 IP,而是完全动态和弹性的存在,整个系统中并无任何中心节点的存在。对于数据运维等操作,仍然可以通过启动一个 Sharding-Proxy 的进程作为静态 IP 的入口,通过各种命令行或 UI 客户端进行操作。
之前接受采访的时候我也提到过:
“2.x 我们将目光放在了微服务开发框架之上,增加了治理、配置动态化等功能。虽然当今微服务概念火热,Spring Cloud 等微服务框架也受到很多关注,但在数据层面,并没有一套行之有效的配套方案,希望 Sharding-JDBC 可以弥补这一领域的缺失。”
现在的 Sharding-Sidecar、Database Mesh 模式的设计,算是对之前这个想法的一个实际行动吧。
6、Sharding-JDBC 在这个新项目中作为一个子项目有做针对性的功能增删或者更新吗?具体是怎么样?
由于 Sharding-Sphere 使用的是同一套内核,因此,内核的提升也会让 Sharding-JDBC 同时带来提升。
Sharding-JDBC 并未进行任何删减,仍然保留原有全部功能,同时,Sharding-Sphere 内核提供了在 Sharding-JDBC 2.x时呼声非常高的对 OR 以及批量 INSERT 语句(INSERT INTO tbl_name (col1, col2, …) VALUES (?, ?,….), (?, ?,….))的支持。
7、对于 Sharding-JDBC 的这种重大变革,技术、管理与运营等方面遇到的最大的难点是什么?
面对这样的重大变革,虽然在技术和管理上都存在一定的挑战,但遇到的最大的难点是运营方面。在 Sharding-JDBC 有一定群众基础的前提下,如何能够平滑地过渡是我们面临的最大挑战。
我们曾经尝试不改动 Sharding-JDBC 这个名字,而是将原有的 Sharding-JDBC 改名为 Sharding-JDBC-Driver,将 Proxy 版本命名为 Sharding-JDBC-Server,Sidecar 版本命名为 Sharding-JDBC-Sidecar;或者干脆将其改名为一个完全中立的名称。
但几经权衡,还是选择了沿用关键词并修改命名范围的方案。技术方面,则是增加了大量与 NIO 和 Netty 相关的工作。
8、Sharding-Sphere 在内部研发了多久了?目前有哪些实践呢?效果如何?
Sharding-Sphere 从今年2月份开始在京东金融内部研发,由于沿用之前的分片核心模块,因此仅用一周就完成了基本的可用版本,余下的工作是设计的调整与性能的优化。
目前 Sharding-Proxy 已在京东金融内部小规模使用,但最终目的仍然是提供一个可供云上用户使用的对外开放版本。
9、能否透露一下 Sharding-Sphere 接下来的计划。
Sharding-Sphere 下一步的计划主要体现在内核提升、开发新功能以及涵盖范围的扩展三个方面。
内核提升
内核提升主要是指 SQL 兼容性提升。在新发布的3.x版本中,由于 OR 和批量 INSERT 的支持,SQL 的兼容性已经有了一些提升,接下来会继续对之前不支持的 DISTINCT、HAVING 与 UNION 等 SQL 语法进行支持。
新功能开发
新功能开发主要集中在柔性事务、数据迁移和治理界面这三方面。
- 柔性事务
Sharding-JDBC 虽然支持最大努力送达型的柔性事务,但无法回滚,而传统的 TCC 事务则需要业务方实现相关接口,增加了落地难度。因此,Sharding-Sphere 会将精力投入到开发一个既让业务方无感知,又可以支持回滚的柔性事务解决方案。
目前能够透露的细节是,Sharding-Sphere 可以将 INSERT 与 DELETE 语句自由转换,在回滚时逆向语句进行操作。UPDATE 语句则采用记录数据日志的方式供回滚时取回当前状态。
- 数据迁移
自动化数据迁移是困扰着很多团队的问题。虽然使用静态预分片方式可以规避数据迁移,但并不是所有的场景都适合使用该策略。Sharding-Sphere 计划开发双写 –> 比对 –> 切换 -> 清理流程的自动化数据迁移模块。
- 治理界面
治理界面将提供可视化的统计、监控和操作界面。
涵盖范围
涵盖范围的扩展主要包括 Sidecar 的开发和其它数据库协议的支持。
Sidecar 模块作为 Database Mesh 的重要实践,也将于下半年列入开发计划。
另外,Sharding-Proxy 模块目前仅支持 MySQL,我们希望由社区的朋友共同参与,提供基于 PostgreSQL 协议的代理。
项目简介:

GitHub:https://github.com/sharding-sphere
码云:https://gitee.com/sharding-sphere

以上是关于集成 Proxy 与 DB Mesh,Sharding-JDBC 3.0 将“Sharding”做到极致的主要内容,如果未能解决你的问题,请参考以下文章
如何从 Service Fabric Mesh 连接到 Azure Cosmos DB