干货,sharding-jdbc
Posted Java入门到放弃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货,sharding-jdbc相关的知识,希望对你有一定的参考价值。
上一篇讲了一下分表的思路,有些朋友看了之后表示大概懂了,但是还是不知道怎么做。这回拿点干货出来。
照着sharding-jdbc,官方文档上的例子
copy到了idea上,该引入的包都引入,可以看到,这个方法呢,就是获取一个dataSource, 就是一个数据源。这个数据源可以用在大部分的orm框架。不列举了。我这里用的mybatis。
照着例子做,只有这一处是需要自己解决的。什么意思呢 看方法名可以猜到,用来设置默认的分库策略,还有默认的分表策略。需要自己写一个策略的类 实现 ShardingStrategyConfiguration接口。
其他的文档说明的很详细,就不再叙述了。
下面说一下我的应用。
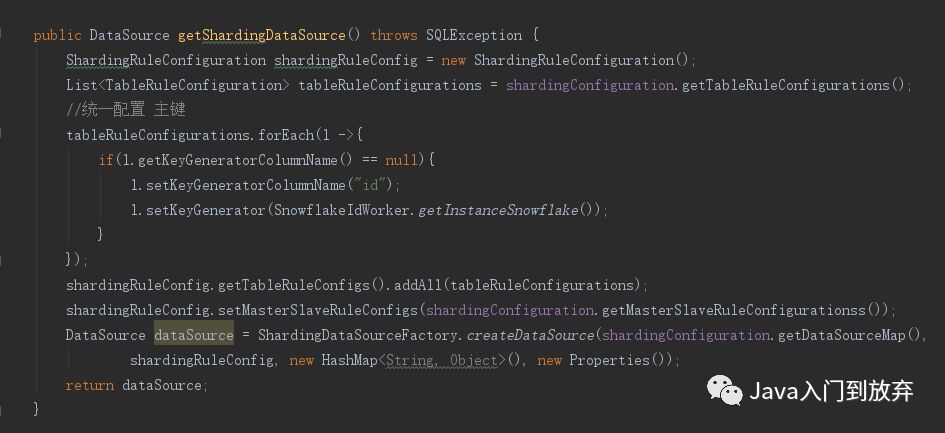
跟官网基本一致,多了一个主键的生成器,推特的雪花算法。先不细说
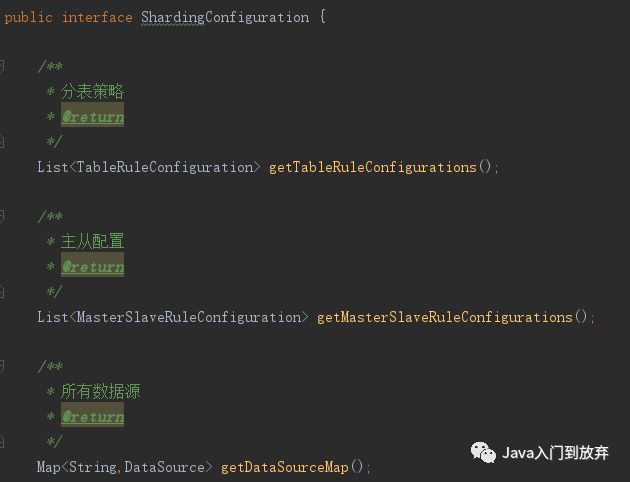
重点都在这个ShardingConfiguration里边了。
getDataSourceMap:数据源配置:主库,从库,各种库的数据源,都放在这个里边。。
getMasterSlaveRuleConfigurations:主从配置
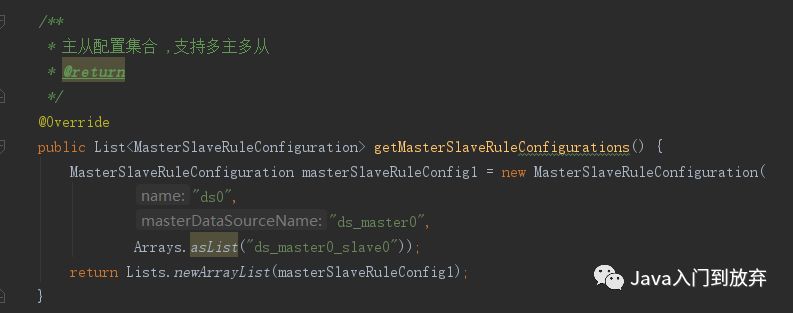
配置这个之后, sharding-jdbc就可以实现读写分离了。
重中之重getTableRuleConfigurations 所有分表策略的list 下边是order表的策略
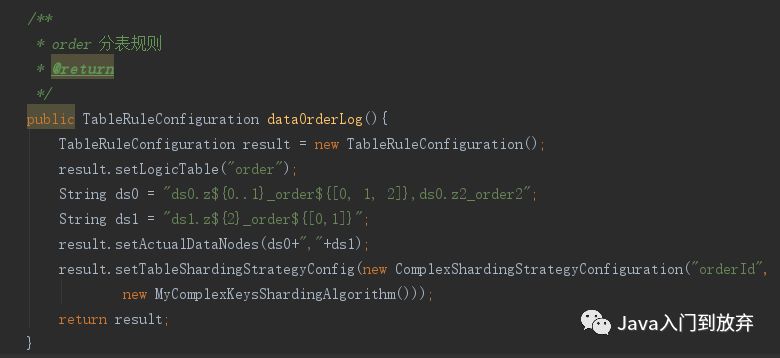
分组分库分表,ds0,ds1 分别是两个数据库的数据源名称
逻辑表:order
物理表:一共是9张,分了3个组。 每组三张表,分散在两个库上。
set了逻辑表和物理表之后,重中之重中之重来了(敲黑板了。)
按照orderId分表分表规则我选用了复合分表,其实对于单个字段来说用简单分表也是一样的。
实现了ComplexKeysShardingAlgorithm之后,需要重载doSharding方法
上边模拟配置分组信息,按照上一篇的思路
if(sqlStatement != null && sqlStatement instanceof InsertStatement){
Object[] keys = groupInfo.keySet().toArray();
Arrays.sort(keys);
String key = (String) keys[keys.length - 1];
List<String> maxGroupTables = group.get(key);
group.clear();
group.put(key,maxGroupTables);
}
group.forEach((k,v)->{
int i = value.hashCode();
String tableName = v.get(Math.abs(i % v.size()));
if(tables.contains(tableName)){
result.add(tableName);
}
});
如果是插入的话,获取最新扩容后的分组,然后在这个分组中,哈希求摩。确定表。
其他sql,则是所有分组,每个确定具体的表。
(睡觉的同学醒一醒了。下课了)这样基本大功告成。
细心的同学可能会发现一个问题。SQLStatement 这个参数哪来的。官方文档上也没有啊。没有这个怎么知道是不是插入操作呢??? 黑人问号脸??
留作课后作业吧。。。。。
我反正是整出来了。同学们自己研究去吧。
我是5毛,放弃java的路上有你有我。
以上是关于干货,sharding-jdbc的主要内容,如果未能解决你的问题,请参考以下文章