一Sharding Sphere 分库
Posted laughing Coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一Sharding Sphere 分库相关的知识,希望对你有一定的参考价值。
一、Apache ShardingSphere
官网:http://shardingsphere.apache.org/index_zh.html
1、Apache ShardingSphere 定位为关系型数据库中间件
2、它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。
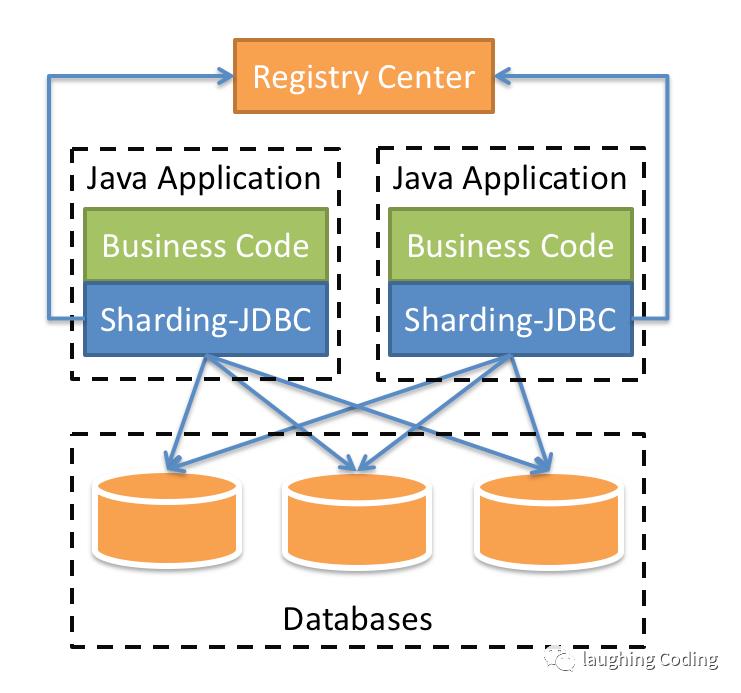
ShardingSphere-JDBC
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
支持任意实现 JDBC 规范的数据库,目前支持 mysql,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
ShardingSphere-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。目前提供 MySQL 和 PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
二、分库分表
当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
垂直分表
垂直分表实际上是列分割
将一个表按照字段分成多表,每个表存储其中一部分字段。
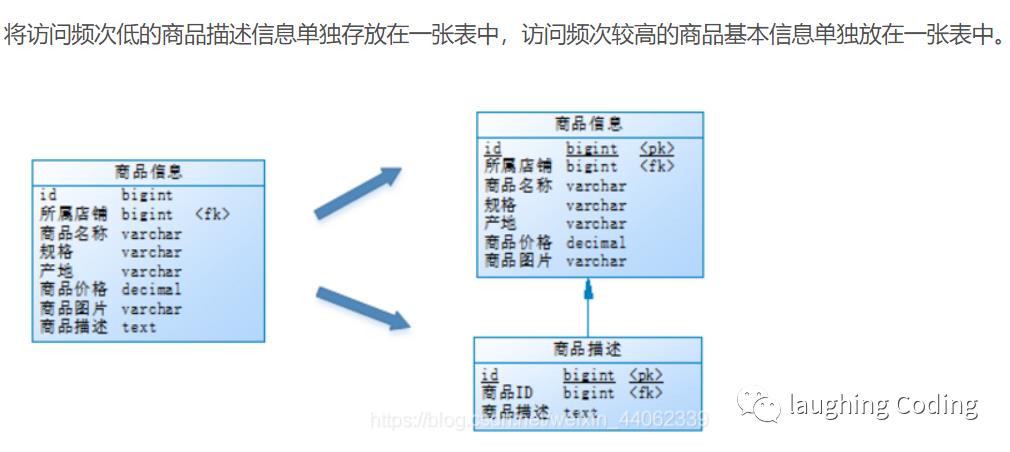
拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库
它的核心理念是专库专用。业务划分
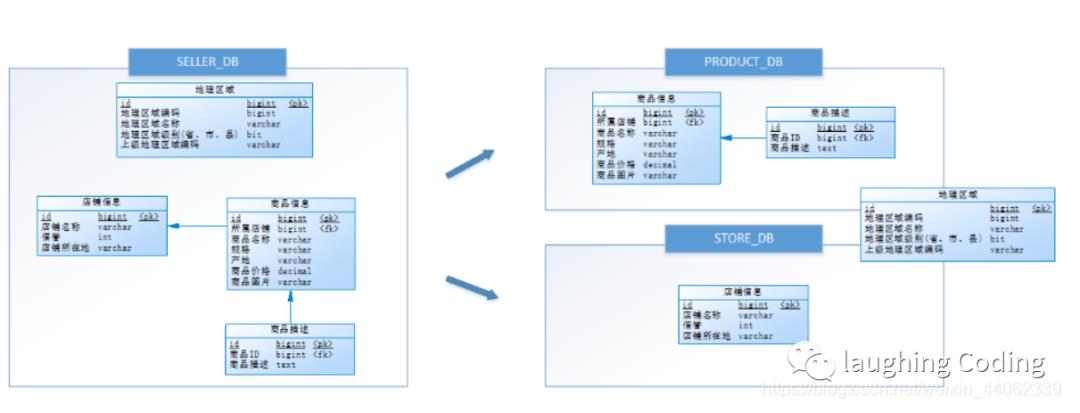
需要解决跨库带来的所有复杂问题。
水平分库
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
例如:将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中。
但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
三、ShardingSphere-JDBC 水平分表
ShardingSphere-JDBC简化对分库分表的业务操作。只用关心逻辑代码。
SPRINGBOOT集成 水平拆分
依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency>
建库建表
新建两个数据库sharding_1和sharding_2,两个数据库都增加两个user相同表,user_1和user_2

SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS = 0;-- ------------------------------ Table structure for user_1-- ----------------------------DROP TABLE IF EXISTS `user_1`;CREATE TABLE `user_1` (`id` bigint(11) NOT NULL,`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,`age` int(10) NULL DEFAULT NULL,`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = DYNAMIC;SET FOREIGN_KEY_CHECKS = 1;
错误解决
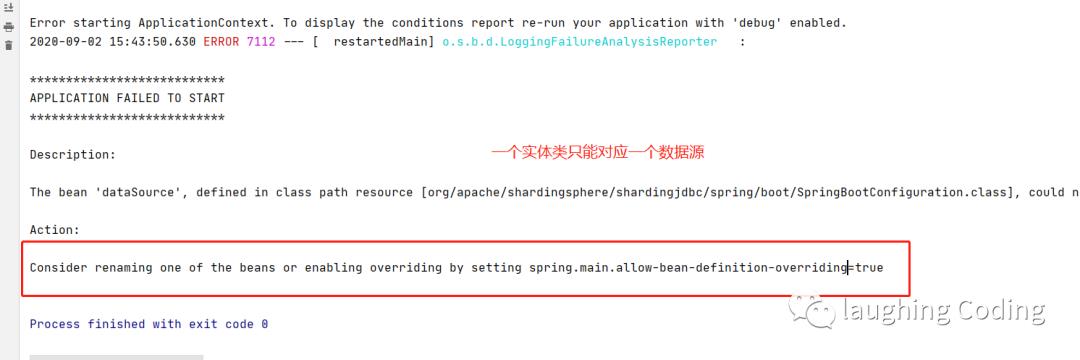
解决

配置文件
server:port: 8080spring:main:# 一个实体类可对应两张表: trueapplication:name: Sharding-Sphere-JDBC# sharding 多数据源配置shardingsphere:datasource:names: ds1ds1:type: com.alibaba.druid.pool.DruidDataSource: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/sharding_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaiusername: rootpassword: gwssi# 表配置sharding:tables:user:# 表名配置 user_1,user_2: ds1.user_$->{1..2}# 主键生成策略 SNOWFLAKE 雪花算法:column: idtype: SNOWFLAKE# 分片策略, id偶数user_1,id奇数user_2:inline:: id: user_$->{id % 2 + 1}# 显示sqlprops:sql:show: true# 开启mybatis-plus:configuration:: org.apache.ibatis.logging.stdout.StdOutImpl
spring.main.allow-bean-definition-overriding=truespring.shardingsphere.datasource.names=ds1spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/sharding_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaispring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=gwssispring.shardingsphere.sharding.tables.user.actual-data-nodes=ds1.user_$->{1..2}spring.shardingsphere.sharding.tables.user.key-generator.column=idspring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKEspring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 2 + 1}spring.shardingsphere.props.sql.show=true
业务代码
mybatis-plus写一个insert方法具体省略
/*** 奇、偶ID插入测试方法* @return*/("/insert/test/")private int insertTset() {User user = new User();user.setName("laughing");user.setAddress("xxxxxxx");user.setAge(10);return userService.addUser(user);}
分表效果
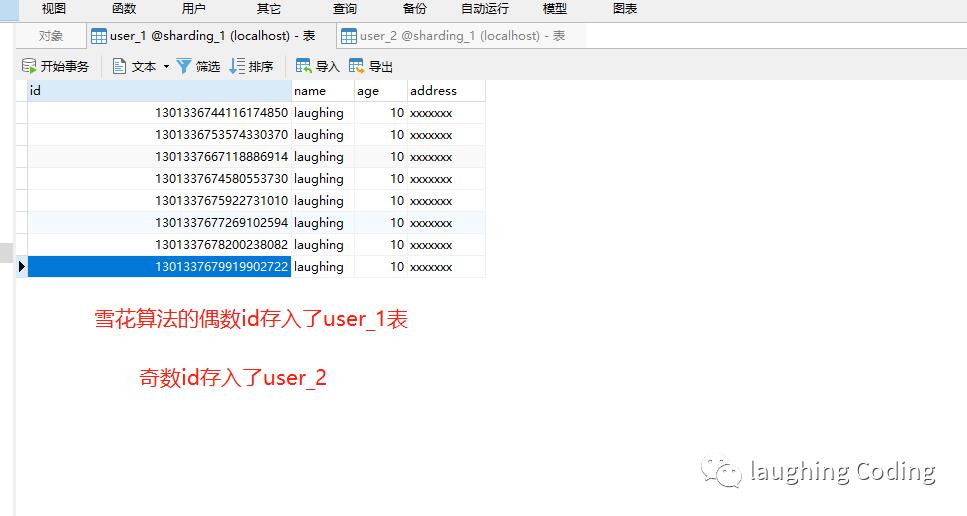
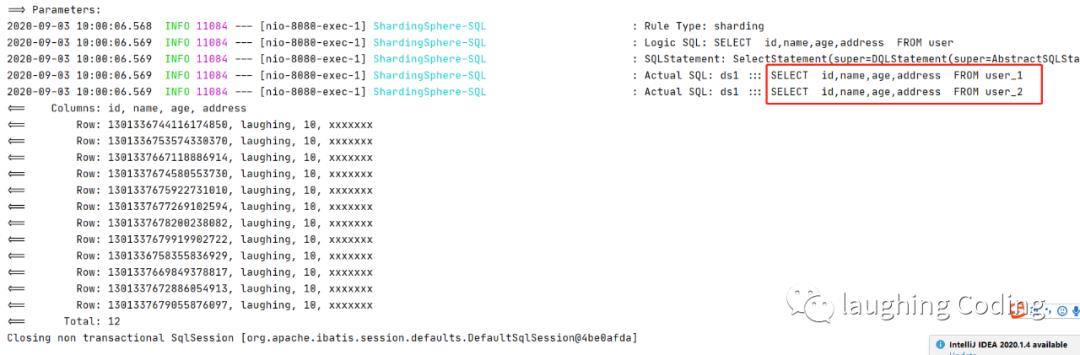
查询
效果和从一张表查询相同
四、ShardingSphere-JDBC 水平分库
配置
# 水平分库server:port: 8080spring:main:# 一个实体类可对应两张表: trueapplication:name: Sharding-Sphere-JDBC# sharding 多数据源配置shardingsphere:datasource:names: ds1,ds2ds1:type: com.alibaba.druid.pool.DruidDataSource: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/sharding_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaiusername: rootpassword: gwssids2:type: com.alibaba.druid.pool.DruidDataSource: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/sharding_2?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaiusername: rootpassword: gwssi# 表配置sharding:tables:user:# 多数据库 表名配置 user_1,user_2# 可以分库分表同时配置# actual-data-nodes: ds$->{1..2}.user_$->{1..2}# 只配置分库,用表user_1: ds$->{1..2}.user_1# 主键生成策略 SNOWFLAKE 雪花算法:column: idtype: SNOWFLAKE# 分片策略, id偶数sharding_1,id奇数sharding_2:inline:: id: ds$->{id % 2 + 1}# 显示sqlprops:sql:show: true# 开启mybatis-plus:configuration:: org.apache.ibatis.logging.stdout.StdOutImp
spring.main.allow-bean-definition-overriding=truespring.shardingsphere.datasource.names=ds1,ds2spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/sharding_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaispring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=gwssispring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds2.url=jdbc:mysql://127.0.0.1:3306/sharding_2?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaispring.shardingsphere.datasource.ds2.username=rootspring.shardingsphere.datasource.ds2.password=gwssispring.shardingsphere.sharding.tables.user.actual-data-nodes=ds$->{1..2}.user_1spring.shardingsphere.sharding.tables.user.key-generator.column=idspring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKEspring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=idspring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{id % 2 +1}spring.shardingsphere.props.sql.show=true
效果
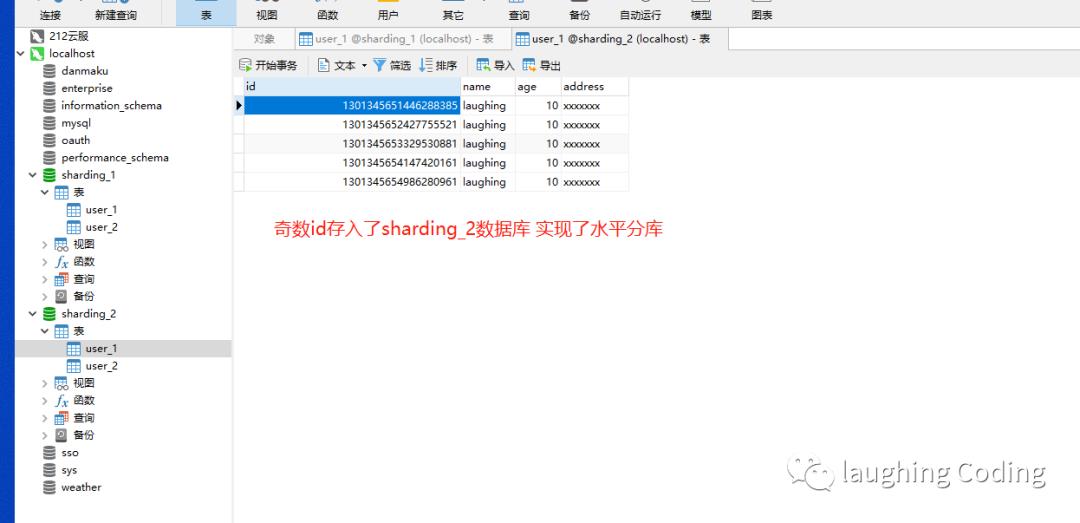
五、ShardingSphere-JDBC 垂直分库
垂直分库需要实现专库专用
我们可以用一个user的库,一个order的库来区分。
实际上就是用ShardingSphere配置两个数据源。
配置
spring.main.allow-bean-definition-overriding=truespring.shardingsphere.datasource.names=ds1,ds2spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/sharding_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaispring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=gwssispring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds2.url=jdbc:mysql://127.0.0.1:3306/sharding_order?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaispring.shardingsphere.datasource.ds2.username=rootspring.shardingsphere.datasource.ds2.password=gwssispring.shardingsphere.sharding.tables.user_order.actual-data-nodes=ds2.user_orderspring.shardingsphere.sharding.tables.user_order.key-generator.column=order_idspring.shardingsphere.sharding.tables.user_order.key-generator.type=SNOWFLAKEspring.shardingsphere.sharding.tables.user_order.table-strategy.inline.sharding-column=order_idspring.shardingsphere.sharding.tables.user_order.table-strategy.inline.algorithm-expression=user_orderspring.shardingsphere.sharding.tables.user.actual-data-nodes=ds1.user_1spring.shardingsphere.sharding.tables.user.key-generator.column=idspring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKEspring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_1spring.shardingsphere.props.sql.show=true
两个数据库的操作互不影响。
六、ShardingSphere-JDBC 公共表
存储固定数据的表,表数据很少发生变化,查询时候经常进行关联。
比如 在垂直分库的情况下,关联两个不同的数据库的两张表。
需要配置公共表,实现多数据源 统一增加删除。
# 配置 关联 公共表 实现多数据源 统一增加删除spring.shardingsphere.sharding.broadcast-tables=dict# 主键生成策略 SNOWFLAKE 雪花算法spring.shardingsphere.sharding.tables.dict.key-generator.column=dict_idspring.shardingsphere.sharding.tables.dict.key-generator.type=SNOWFLAKE
private int insertTset3() {Long userId = userService.getAll().get(0).getId();Long oderId = userOrderService.getAllOrder().get(0).getOrderId();Dict dict = new Dict();dict.setOrderId(userId);dict.setUserId(oderId);dict.setStatus("1");return dictService.insert(dict);}
以上是关于一Sharding Sphere 分库的主要内容,如果未能解决你的问题,请参考以下文章