在MySQL和PostgreSQL之外,为什么阿里要研发HybridDB数据库?
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在MySQL和PostgreSQL之外,为什么阿里要研发HybridDB数据库?相关的知识,希望对你有一定的参考价值。
编辑:木环
编者按
先来讲讲OLTP和OLAP

数据库领域中大家经常会看到两个词:OLTP及OLAP。
举例说明,比如进行一次交易,资金从A帐户转帐到B帐户,这整个过程就是一次交易事务。如果过程中有任何系统错误,交易会回滚A帐户中的金额都回恢到操作前的状态,这就是On-Line Transaction Processing联机事务处理过程(OLTP)的操作。在OLTP场景中用户并发操作量会很大,要求系统实时进行数据操作的响应,在查询时往往也是只会检索一条或几条明确的目标数据,以实现用户的业务交互。
OLAP意思是On-Line Analytical Processing联机分析处理,顾名思义就是主要针对于数据的分析汇总操作。如我们的业务系统中每天都需要出销售日报,这个操作需要对当天所有数据进行汇总,并需要进行计算,以得到全天收入、产品销售排名、分时段的销售量,甚至与过去30天及去年当天进行对比,这样的操作都属于OLAP。
业界早期使用数据时,尤其是OLTP场景下,通常选择非分布式的关系型数据库,如MySQL、SQLServer、Oracle、PostgreSQL即可满足大部份的需求。
OLAP中主流数据库遭遇瓶颈
在OLAP发展的早期,其操作并没有专门的数据库支撑,直接就与OLTP业务放在同一个数据库中完成。但随着业务量的增加,OLAP每次要分析的数据量越来越大,这样的分析操作执行时就会导致数据库的业务交易下降。因此业界开始将OLTP、OLAP拆分成两套不同的数据库进行处理,OLTP数据库中的数据通过ETL软件持续或定期抽取到OLAP数据库,让业务交易与报表分析进行分离。
而新的问题很快又到来了,联互网爆发后数据量也激增,OLTP的业务库可以保存比较少的数据量如3个月到半年,但OLAP的数据量将可能要保存几年甚至更多。单台服务服务的性能上限已经无法满足OLAP分析数据持续增加所带来的压力,因此催生出如阿里HybridDB这样的大规模并行处理(Massive Parallel Processing,MPP)分布式OLAP数据库。
新的分布式OLAP数据库
在提供HybridDB方案之前,我们会给用户提供如分库分表等处理方案,但这样的方案对于SQL查询内容不确定的OLAP业务并不友好。当用户需要进行多个数据表的组合操作时,由于数据需要跨服务器进行大规模的聚合,性能十分低下。
这个问题在HybridDB中也同样会出现,所幸的是,Greenplum Database开源项目中借助平行的数据扩展技术及interconnect的专用协议,通过自定义的网络协议有效地解决了网络瓶颈的问题。这也是我们选择基于Greenplum Database开源项目的原因之一。
MPP分布式OLAP数据库系统架构已经发展了有10多年之久,十分成熟,当前使用这类系统的企业都是中大型公司。OLAP是一个很大的市场,有别于如同EMR(Hadoop)的大数据分析市场,它要求海量数据的SQL查询在几分钟、几秒,甚至毫秒级返回结果,因此对于服务器、网络及数据库软件本身的架构都提出了很高的要求。
技术攻坚之路
生态:基于10年商业数据库建立的生态是宝贵的财富,让用户的使用变得更为便捷。 成熟:经过我们深度的压力测试(过程还是十分暴力的,在此不表^_^),我们验证了Greenplum本身的稳定性,同时GPDB提供丰富的SQL支持、编程接口易于进行扩展,这些都体现了她的成熟度。 开源:只有掌握源码才可以协助用户最快地解决问题,同时Greenplum基于PostgreSQL,基于这一点,用户可以使用统一的PostgreSQL的JDBC或.NET驱动开发OLTP及OLAP的软件,减少不同数据库协议之间的学习成本及研发复杂度。
揭秘HybridDB方案
HybridDB基于开源Greenplum Database(内核实际上就是PostgreSQL)项目的MPP分布式数据仓库,与PostgreSQL不同,HybridDB可以实现横向扩展,提供用户需要的百GB到百TB的高性能分析能力。
在阿里云官网上,HybridDB 归结在 “数据库” 和 “分析” 两个类目。阿里内部已经有业务开始使用 HybridDB ,主要是看重它对SQL的丰富支持,同时可以支持GIS数据类型及基于事务一致性的存储过程。
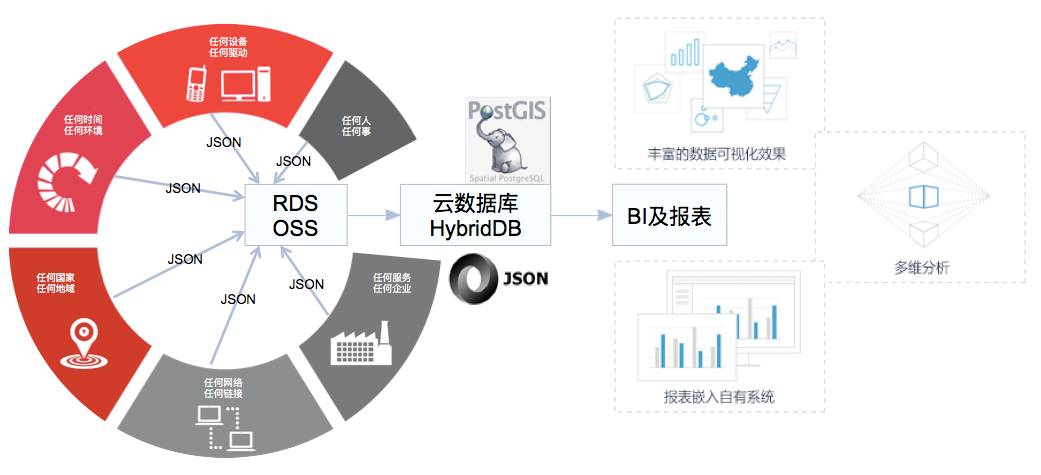
HybridDB最大的三个特色:
基于成熟的GPDB及PostgreSQL生态,软开发合作伙伴进行一次软件开发,即可在云上云下同样使用,免去迁移的烦恼,更容易实现混合云中的数据分析支持。
支持多种混合数据类型(多达23种)的SQL统一查询,包括:
传统数据类型:字符、数字、浮点、日期等;
非结构化数据:JSON、XML;
特殊功能数据类型:GIS地理信息数据、IPv4/v6网络数据、HyperLogLog预估分析数据。
支持混合的数据存储,包括:行存、列存、SSD/HDD本地存储、OSS云存储,未来更将支持“存储计算分离”,用户可以更为灵活在进行资源的购买及分配。
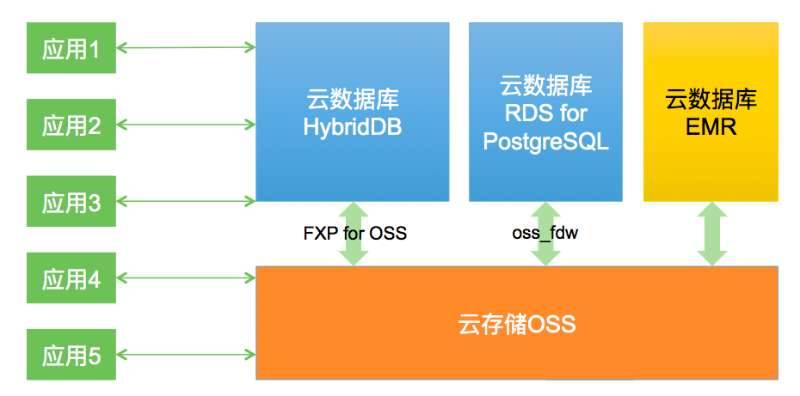
数据存储
高性能的数据分析是在本地存储完成的。OSS作为外部存储,HybridDB可以将OSS中的CSV格式化文本作为外部表进行数据查询,同时还可以对这些外部表进行写入操作。写入到OSS的数据可以提供给RDS for PostgreSQL或EMR等云数据库服务进行读取及处理,因此也同时实现了数据的无缝打通。
同时我们也将支持“存储计算分析”的模型,在这样模型上我们平时甚至可以只通过OSS进行数据的存储,当需要进行计算时再开启足够的计算节点进行数据分析处理,计算处理结束后关闭计算节点资源以节省使用成本。
HybridDB的幕后故事
在Greenplum Database的开源社区我们会有很多的合作,甚至我们已经在向开源社区提交新功能及patch。同时Greenplum也是PostgreSQL开源数据库生态重要的力量,我个人同时作为PostgreSQL中国社区及用户会的主席也当然会进行更多线上线下活动的支持。
商业合作
Greenplum背后的公司是Pivotal。所以同时也与Pivotal有更多的商业合作。阿里也会与Pivotal方面进行持续的接触,相信我们会有机会碰出绚丽的火花。
写在最后
长期以来国外开源社区都认为中国用户仅仅使用开源软件,但是贡献甚少。不过,随着阿里的发展,我们已经开始反哺开源社区并共同建立生态。几个月前,AliSQL的开源说明了阿里对开源业界的支持。HybridDB同样如此,虽然我们的版本才刚刚发布,但在版本研发的过程中已经开始向社区共享代码。
阿里云当前支持云数据库HybridDB,暂时没有计划去支持私有环境的Greenplum数据库。不过我们团队的大神德哥,会继续贡献他在使用Greenplum的经验心得。希望对大家有所帮助。
用户在线下可以使用Greenplum的开源数据库版本或商业版本,据我所了解也已经有很多数据库服务商开始提供Greenplum的技术支持,使用这个数据库的用户不需要再担心未来上云迁移的问题。同时,我们也会在未来结合PostgreSQL及HybridDB提供一系列的使用教学视频,让用户更快速地掌握产品的正确使用场景及方法。
作者简介
萧少聪,Postgres中国社区/中国用户会主席,阿里云计算有限公司 ApsaraDB云数据库产品专家。红帽认证RHCA架构师/EDB认证PostgreSQL数据库专家,参与的著作有《Linux系统案例精解》、《深入理解大数据》。在阿里主要负责PostgreSQL数据库产品线。
拥有多年开发、架构设计及项目管理经验,专注于开源Linux系统管理及Postgres数据库、优化、集群系统、云架构设计。
今日荐文
微信异步化改造实践:
8亿月活、万台机器背后的解决方案
喜欢我们的会点赞,爱我们的会分享!
以上是关于在MySQL和PostgreSQL之外,为什么阿里要研发HybridDB数据库?的主要内容,如果未能解决你的问题,请参考以下文章
阿里云数据库产品HybridDB简介——OLAP数据库,支持行列混合存储,基于数据库Greenplum的开源版本,并且吸收PostgreSQL精髓