如何遏制 PostgreSQL WAL 的疯狂增长
Posted 数据分析与开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何遏制 PostgreSQL WAL 的疯狂增长相关的知识,希望对你有一定的参考价值。
来源:skykiker
blog.chinaunix.net/uid-20726500-id-5766987.html
前言
PostgreSQL在写入频繁的场景中,可能会产生大量的WAL日志,而且WAL日志量远远超过实际更新的数据量。 我们可以把这种现象起个名字,叫做“WAL写放大”,造成WAL写放大的主要原因有2点。
在checkpoint之后第一次修改页面,需要在WAL中输出整个page,即全页写(full page writes)。全页写的目的是防止在意外宕机时出现的数据块部分写导致数据库无法恢复。
更新记录时如果新记录位置(ctid)发生变更,索引记录也要相应变更,这个变更也要记入WAL。更严重的是索引记录的变更又有可能导致索引页的全页写,进一步加剧了WAL写放大。
过量的WAL输出会对系统资源造成很大的消耗,因此需要进行适当的优化。
磁盘IO
WAL写入是顺序写,通常情况下硬盘对付WAL的顺序写入是绰绰有余的。所以一般可以忽略。网络IO
对局域网内的复制估计还不算问题,远程复制就难说了。磁盘空间
如果做WAL归档,需要的磁盘空间也是巨大的。
WAL记录的构成
每条WAL记录的构成大致如下:
src/include/access/xlogrecord.h:
* The overall layout of an XLOG record is:
* Fixed-size header (XLogRecord struct)
* XLogRecordBlockHeader struct
* XLogRecordBlockHeader struct
* ...
* XLogRecordDataHeader[Short|Long] struct
* block data
* block data
* ...
* main data
主要占空间是上面的”block data”,再往上的XLogRecordBlockHeader是”block data”的元数据。 一条WAL记录可能不涉及数据块,也可能涉及多个数据块,因此WAL记录中可能没有”block data”也可能有多个”block data”。
“block data”的内容可能是下面几种情况之一
full page image
如果是checkpoint之后第一次修改页面,则输出整个page的内容(即full page image,简称FPI)。但是page中没有数据的hole部分会被排除,如果设置了wal_compression = on还会对这page上的数据进行压缩。buffer data
不需要输出FPI时,就只输出page中指定的数据。full page image + buffer data
逻辑复制时,即使输出了FPI,也要输出指定的数据。
究竟”block data”中存的是什么内容,通过前面的XLogRecordBlockHeader中的fork_flags进行描述。这里的XLogRecordBlockHeader其实也只是个概括的说法,实际上后面还跟了一些其它的Header。完整的结构如下:
XLogRecordBlockHeader
XLogRecordBlockImageHeader (可选,包含FPI时存在)
XLogRecordBlockCompressHeader (可选,对FPI压缩时存在)
RelFileNode (可选,和之前的"block data"的file node不一样时才存在)
BlockNumber
下面以insert作为例子说明。
src/backend/access/heap/heapam.c:
Oid
heap_insert(Relation relation, HeapTuple tup, CommandId cid,
int options, BulkInsertState bistate)
{
...
xl_heap_insert xlrec;
xl_heap_header xlhdr;
...
xlrec.offnum = ItemPointerGetOffsetNumber(&heaptup->t_self);
...
XLogBeginInsert();
XLogRegisterData((char *) &xlrec, SizeOfHeapInsert); //1)记录tuple的位置到WAL记录里的"main data"。
xlhdr.t_infomask2 = heaptup->t_data->t_infomask2;
xlhdr.t_infomask = heaptup->t_data->t_infomask;
xlhdr.t_hoff = heaptup->t_data->t_hoff;
/*
* note we mark xlhdr as belonging to buffer; if XLogInsert decides to
* write the whole page to the xlog, we don't need to store
* xl_heap_header in the xlog.
*/
XLogRegisterBuffer(0, buffer, REGBUF_STANDARD | bufflags);
XLogRegisterBufData(0, (char *) &xlhdr, SizeOfHeapHeader);//2)记录tuple的head到WAL记录里的"block data"。
/* PG73FORMAT: write bitmap [+ padding] [+ oid] + data */
XLogRegisterBufData(0,
(char *) heaptup->t_data + SizeofHeapTupleHeader,
heaptup->t_len - SizeofHeapTupleHeader);//3)记录tuple的内容到WAL记录里的"block data"。
...
}
WAL的解析
PostgreSQL的安装目录下有个叫做pg_xlogdump的命令可以解析WAL文件,下面看一个例子。
-bash-4.1$ pg_xlogdump /pgsql/data/pg_xlog/0000000100000555000000D5 -b
...
rmgr: Heap len (rec/tot): 14/ 171, tx: 301170263, lsn: 555/D5005080, prev 555/D50030A0, desc: UPDATE off 30 xmax 301170263 ; new off 20 xmax 0
blkref #0: rel 1663/13269/54349226 fork main blk 1640350
blkref #1: rel 1663/13269/54349226 fork main blk 1174199
...
这条WAL记录的解释如下:
rmgr: Heap
PostgreSQL内部将WAL日志归类到20多种不同的资源管理器。这条WAL记录所属资源管理器为Heap,即堆表。除了Heap还有Btree,Transaction等。len (rec/tot): 14/ 171
WAL记录的总长度是171字节,其中main data部分是14字节(只计数main data可能并不合理,本文的后面会有说明)。tx: 301170263
事务号lsn: 555/D5005080
本WAL记录的LSNprev 555/D50030A0
上条WAL记录的LSNdesc: UPDATE off 30 xmax 301170263 ; new off 20 xmax 0
这是一条UPDATE类型的记录(每个资源管理器最多包含16种不同的WAL记录类型,),旧tuple在page中的位置为30(即ctid的后半部分),新tuple在page中的位置为20。blkref #0: rel 1663/13269/54349226 fork main blk 1640350
引用的第一个page(新tuple所在page)所属的堆表文件为1663/13269/54349226,块号为1640350(即ctid的前半部分)。通过oid2name可以查到是哪个堆表。
-bash-4.1$ oid2name -f 54349226
From database "postgres":
Filenode Table Name
----------------------------
54349226 pgbench_accounts
blkref #1: rel 1663/13269/54349226 fork main blk 1174199
引用的第二个page(旧tuple所在page)所属的堆表文件及块号
UPDATE语句除了产生UPDATE类型的WAL记录,实际上还会在前面产生一条LOCK记录,可选的还可能在后面产生若干索引更新的WAL记录。
-bash-4.1$ pg_xlogdump /pgsql/data/pg_xlog/0000000100000555000000D5 -b
...
rmgr: Heap len (rec/tot): 8/ 8135, tx: 301170263, lsn: 555/D50030A0, prev 555/D5001350, desc: LOCK off 30: xid 301170263: flags 0 LOCK_ONLY EXCL_LOCK
blkref #0: rel 1663/13269/54349226 fork main blk 1174199 (FPW); hole: offset: 268, length: 116
rmgr: Heap len (rec/tot): 14/ 171, tx: 301170263, lsn: 555/D5005080, prev 555/D50030A0, desc: UPDATE off 30 xmax 301170263 ; new off 20 xmax 0
blkref #0: rel 1663/13269/54349226 fork main blk 1640350
blkref #1: rel 1663/13269/54349226 fork main blk 1174199
...
上面的LOCK记录的例子中,第一个引用page里有PFW标识,表示包含FPI,这也是这条WAL记录长度很大的原因。 后面的hole: offset: 268, length: 116表示page中包含hole,以及这个hole的偏移位置和长度。 可以算出FPI的大小为8196-116=8080, WAL记录中除FPI以外的数据长度8135-8080=55。
WAL的统计
PostgreSQL 9.5以后的pg_xlogdump都带有统计功能,可以查看不同类型的WAL记录的数量,大小以及FPI的比例。例子如下:
postgres.conf配置
下面是一个未经特别优化的配置
shared_buffers = 32GB
checkpoint_completion_target = 0.9
checkpoint_timeout = 5min
min_wal_size = 1GB
max_wal_size = 4GB
full_page_writes = on
wal_log_hints = on
wal_level = replica
wal_keep_segments = 1000
测试
先手动执行checkpoint,再利用pgbench做一个10秒钟的压测
-bash-4.1$ psql -c "checkpoint;select pg_switch_xlog(),pg_current_xlog_location()"
pg_switch_xlog | pg_current_xlog_location
----------------+--------------------------
556/48000270 | 556/49000000
(1 row)
-bash-4.1$ pgbench -n -c 64 -j 64 -T 10
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: simple
number of clients: 64
number of threads: 64
duration: 10 s
number of transactions actually processed: 123535
latency average = 5.201 ms
tps = 12304.460572 (including connections establishing)
tps = 12317.916235 (excluding connections establishing)
-bash-4.1$ psql -c "select pg_current_xlog_location()"
pg_current_xlog_location
--------------------------
556/B8B40CA0
(1 row)
日志统计
统计压测期间产生的WAL
这个统计结果显示FPI的比例占到了98.10%。但是这个数据并不准确,因为上面的Record size只包含了WAL记录中”main data”的大小,Combined size则是”main data”与FPI的合计,漏掉了FPI以外的”block data”。 这是一个Bug,社区正在进行修复,参考BUG #14687
作为临时对策,可以在pg_xlogdump.c中新增了一行代码,重新计算Record size使之等于WAL总记录长度减去FPI的大小。为便于区分,修改后编译的二进制文件改名为pg_xlogdump_ex。
src/bin/pg_xlogdump/pg_xlogdump.c:
fpi_len = 0;
for (block_id = 0; block_id <= record->max_block_id; block_id++)
{
if (XLogRecHasBlockImage(record, block_id))
fpi_len += record->blocks[block_id].bimg_len;
}
rec_len = XLogRecGetTotalLen(record) - fpi_len;/* 新增这一行,重新计算rec_len */
修改后,重新统计WAL的结果如下:
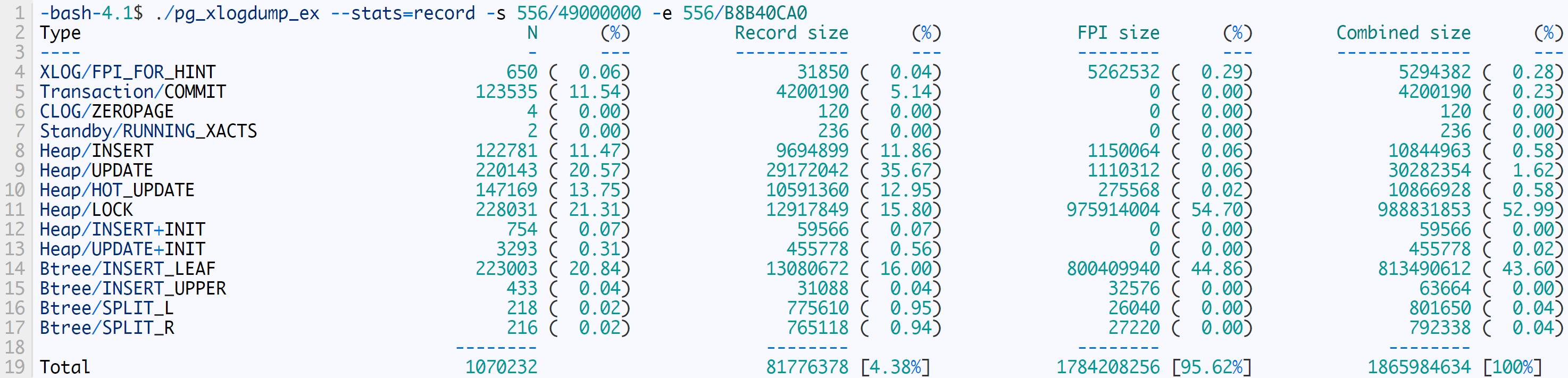
这上面可以看出,有95.62%的WAL空间都被FPI占据了(也就是说WAL至少被放大了20倍),这个比例是相当高的。
如果不修改pg_xlogdump的代码,也可以通过计算WAL距离的方式,算出准确的FPI比例。
postgres=# select pg_xlog_location_diff('556/B8B40CA0','556/49000000');
pg_xlog_location_diff
-----------------------
1874070688
(1 row)
postgres=# select 1784208256.0 / 1874070688;
?column?
------------------------
0.95204960379808256197
(1 row)
WAL的优化
在应用的写负载不变的情况下,减少WAL生成量主要有下面几种办法。
延长checkpoint时间间隔
FPI产生于checkpoint之后第一次变脏的page,在下次checkpoint到来之前,已经输出过PFI的page是不需要再次输出FPI的。因此checkpoint时间间隔越长,FPI产生的频度会越低。增大checkpoint_timeout和max_wal_size可以延长checkpoint时间间隔。增加HOT_UPDATE比例
普通的UPDATE经常需要更新2个数据块,并且可能还要更新索引page,这些又都有可能产生FPI。而HOT_UPDATE只修改1个数据块,需要写的WAL量也会相应减少。压缩
PostgreSQL9.5新增加了一个wal_compression参数,设为on可以对FPI进行压缩,削减WAL的大小。另外还可以在外部通过SSL/SSH的压缩功能减少主备间的通信流量,以及自定义归档脚本对归档的WAL进行压缩。关闭全页写
这是一个立竿见影但也很危险的办法,如果底层的文件系统或储存支持原子写可以考虑。因为很多部署环境都不具备安全的关闭全页写的条件,下文不对该方法做展开。
延长checkpoint时间
首先优化checkpoint相关参数
postgres.conf:
shared_buffers = 32GB
checkpoint_completion_target = 0.1
checkpoint_timeout = 60min
min_wal_size = 4GB
max_wal_size = 64GB
full_page_writes = on
wal_log_hints = on
wal_level = replica
wal_keep_segments = 1000
然后,手工发起一次checkpoint
-bash-4.1$ psql -c "checkpoint"
CHECKPOINT
再压测10w个事务,并连续测试10次
-bash-4.1$ psql -c "select pg_current_xlog_location()" ; pgbench -n -c 100 -j 100 -t 1000 ;psql -c "select pg_current_xlog_location()"
pg_current_xlog_location
--------------------------
558/47542B08
(1 row)
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: simple
number of clients: 100
number of threads: 100
number of transactions per client: 1000
number of transactions actually processed: 100000/100000
latency average = 7.771 ms
tps = 12868.123227 (including connections establishing)
tps = 12896.084970 (excluding connections establishing)
pg_current_xlog_location
--------------------------
558/A13DF908
(1 row)
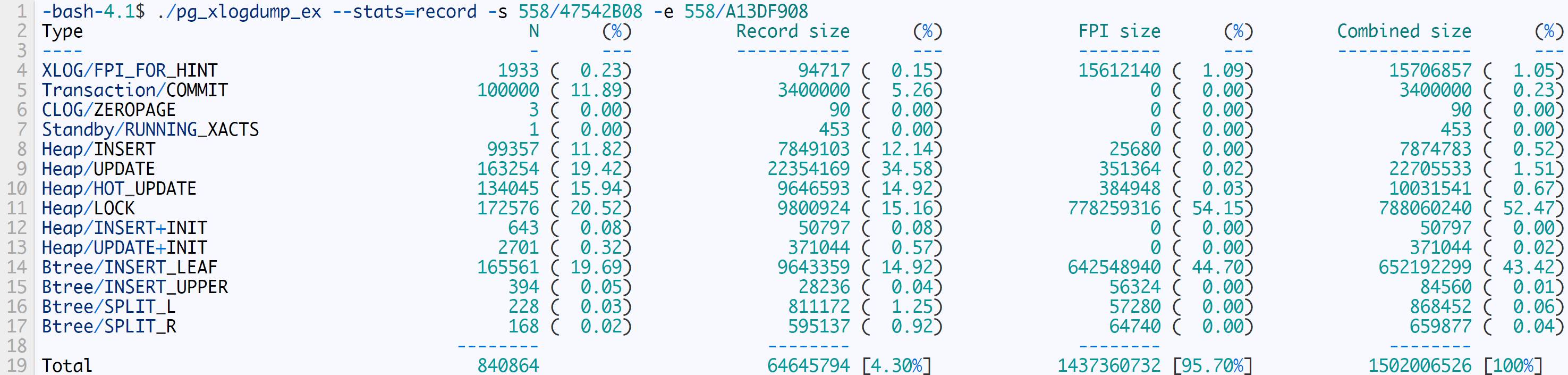
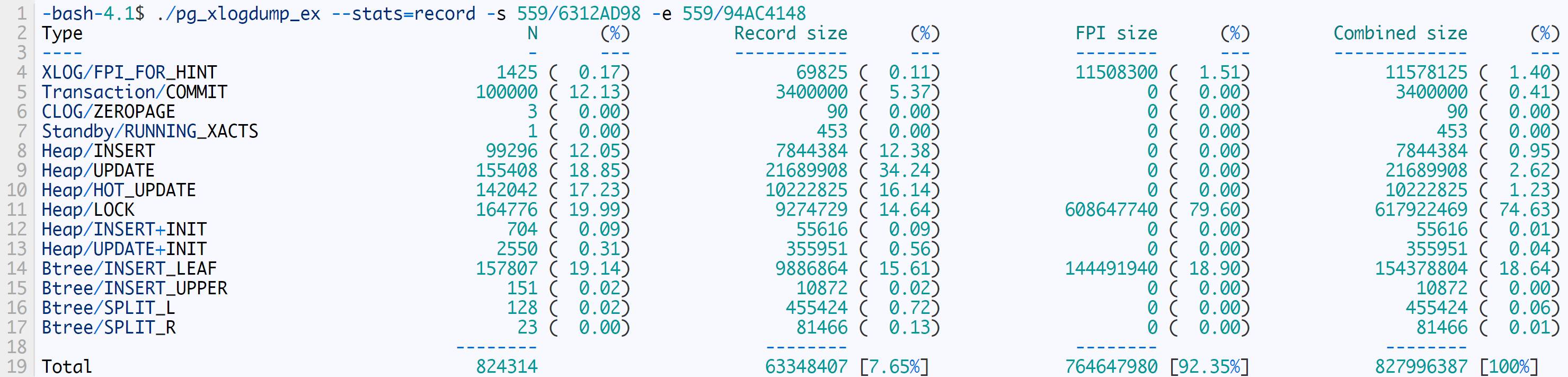
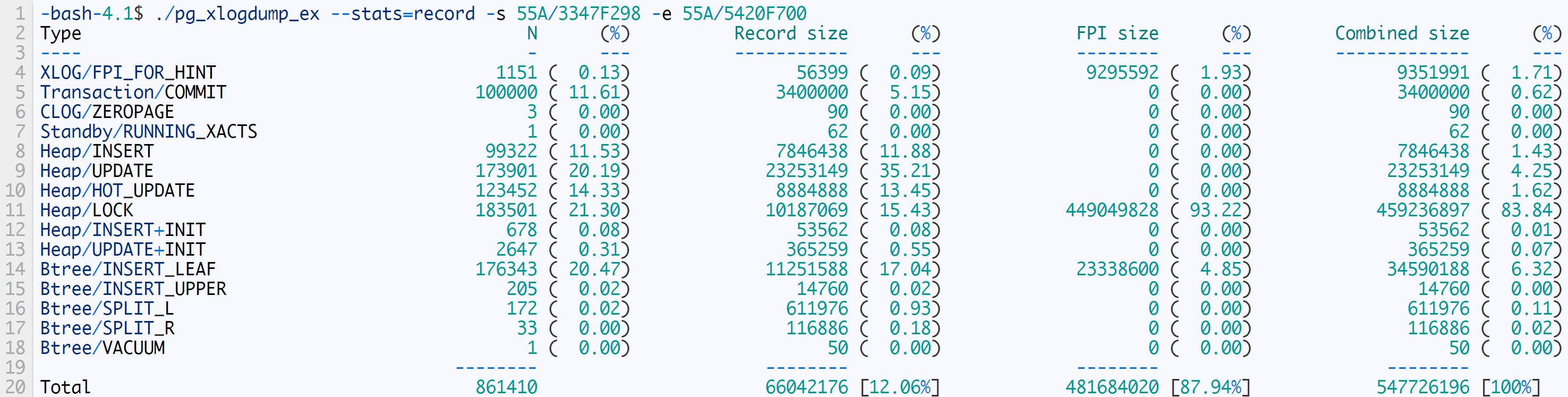
测试结果如下
第1次执行
第5次执行
第10次执行
汇总如下:
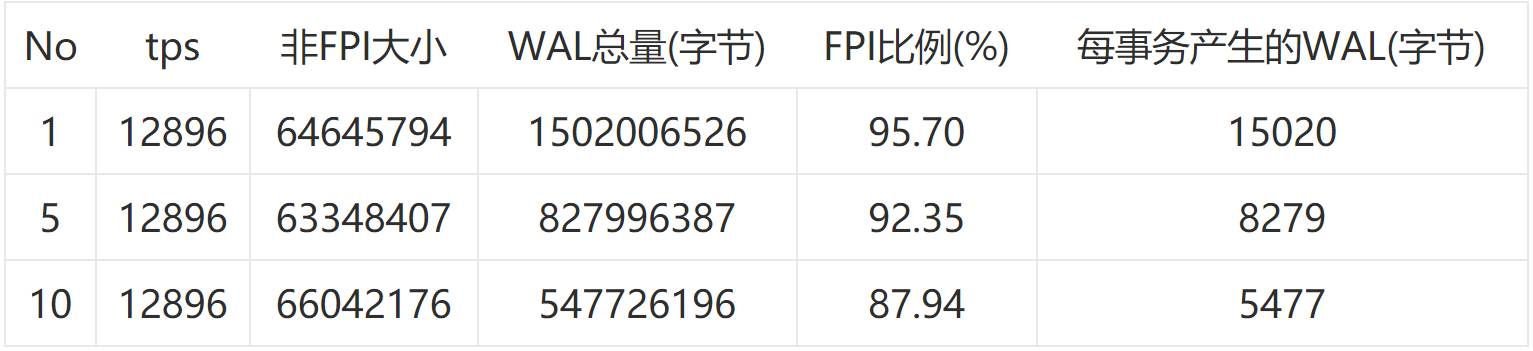
不难看出非FPI大小是相对固定的,FPI的大小越来越小,这也证实了延长checkpoint间隔对削减WAL大小的作用。
增加HOT_UPDATE比例
HOT_UPDATE比例过低的一个很常见的原因是更新频繁的表的fillfactor设置不恰当。fillfactor的默认值为100%,可以先将其调整为90%。
对于宽表,要进一步减小fillfactor使得至少可以保留一个tuple的空闲空间。可以查询pg_class系统表估算平均tuple大小,并算出合理的fillfactor值。
postgres=# select 1 - relpages/reltuples max_fillfactor from pg_class where relname='big_tb';
max_fillfactor
----------------------
0.69799901185770750988
(1 row)
再上面估算出的69%的基础上,可以把fillfactor再稍微设小一点,比如设成65% 。
在前面优化过的参数的基础上,先保持fillfactor=100不变,执行100w事务的压测
-bash-4.1$ psql -c "checkpoint;select pg_current_xlog_location()" ; pgbench -n -c 100 -j 100 -t 10000 ;psql -c "select pg_current_xlog_location()"
pg_current_xlog_location
--------------------------
55A/66715CC0
(1 row)
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: simple
number of clients: 100
number of threads: 100
number of transactions per client: 10000
number of transactions actually processed: 1000000/1000000
latency average = 7.943 ms
tps = 12589.895315 (including connections establishing)
tps = 12592.623734 (excluding connections establishing)
pg_current_xlog_location
--------------------------
55C/7C747F20
(1 row)
生成的WAL统计如下:
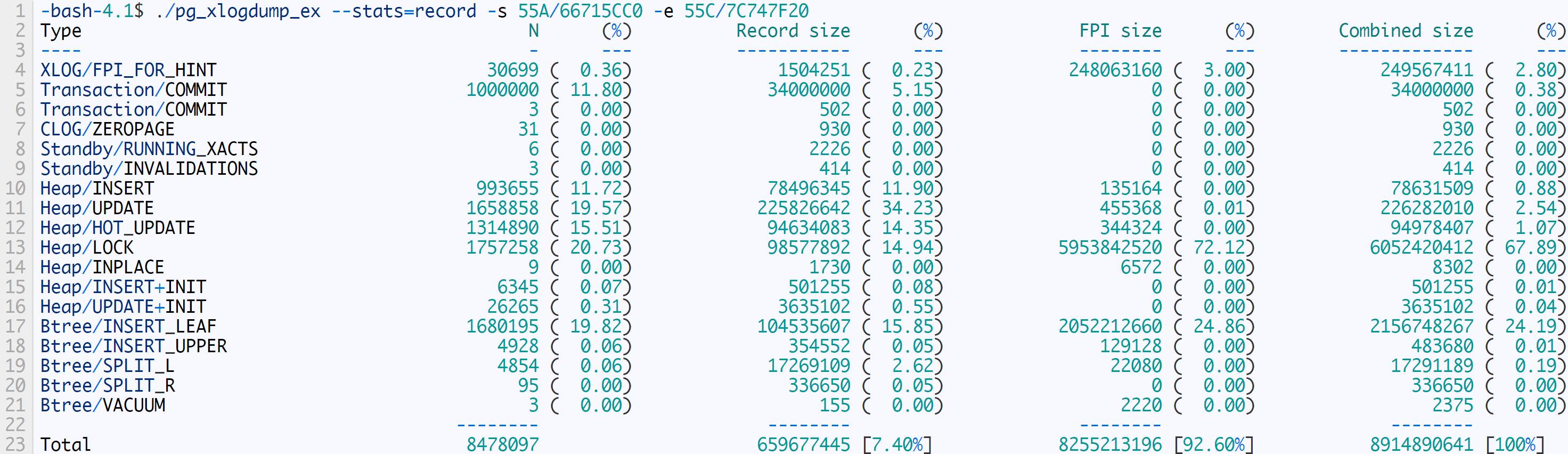
设置fillfactor=90
postgres=# alter table pgbench_accounts set (fillfactor=90);
ALTER TABLE
postgres=# vacuum full pgbench_accounts;
VACUUM
postgres=# alter table pgbench_tellers set (fillfactor=90);
ALTER TABLE
postgres=# vacuum full pgbench_tellers;
VACUUM
postgres=# alter table pgbench_branches set (fillfactor=90);
ALTER TABLE
postgres=# vacuum full pgbench_branches;
VACUUM
再次测试
-bash-4.1$ psql -c "checkpoint;select pg_current_xlog_location()" ; pgbench -n -c 100 -j 100 -t 10000 ;psql -c "select pg_current_xlog_location()"
pg_current_xlog_location
--------------------------
561/78BD2460
(1 row)
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: simple
number of clients: 100
number of threads: 100
number of transactions per client: 10000
number of transactions actually processed: 1000000/1000000
latency average = 7.570 ms
tps = 13210.665959 (including connections establishing)
tps = 13212.956814 (excluding connections establishing)
pg_current_xlog_location
--------------------------
562/F91436D8
(1 row)
生成的WAL统计如下:
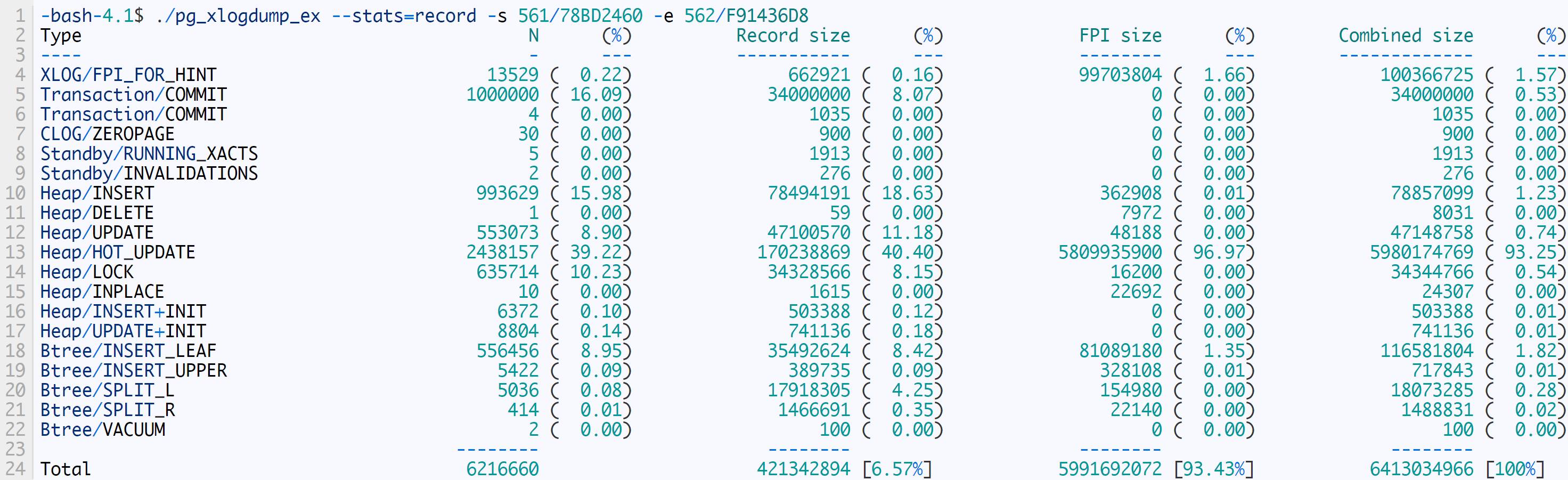
设置fillfactor=90后,生成的WAL量从8914890641减少到6413034966。
设置WAL压缩
修改postgres.conf,开启WAL压缩
wal_compression = on
再次测试
-bash-4.1$ psql -c "checkpoint;select pg_current_xlog_location()" ; pgbench -n -c 100 -j 100 -t 10000 ;psql -c "select pg_current_xlog_location()"
pg_current_xlog_location
--------------------------
562/F91B5978
(1 row)
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: simple
number of clients: 100
number of threads: 100
number of transactions per client: 10000
number of transactions actually processed: 1000000/1000000
latency average = 8.295 ms
tps = 12056.091399 (including connections establishing)
tps = 12059.453725 (excluding connections establishing)
pg_current_xlog_location
--------------------------
563/39880390
(1 row)
生成的WAL统计如下:
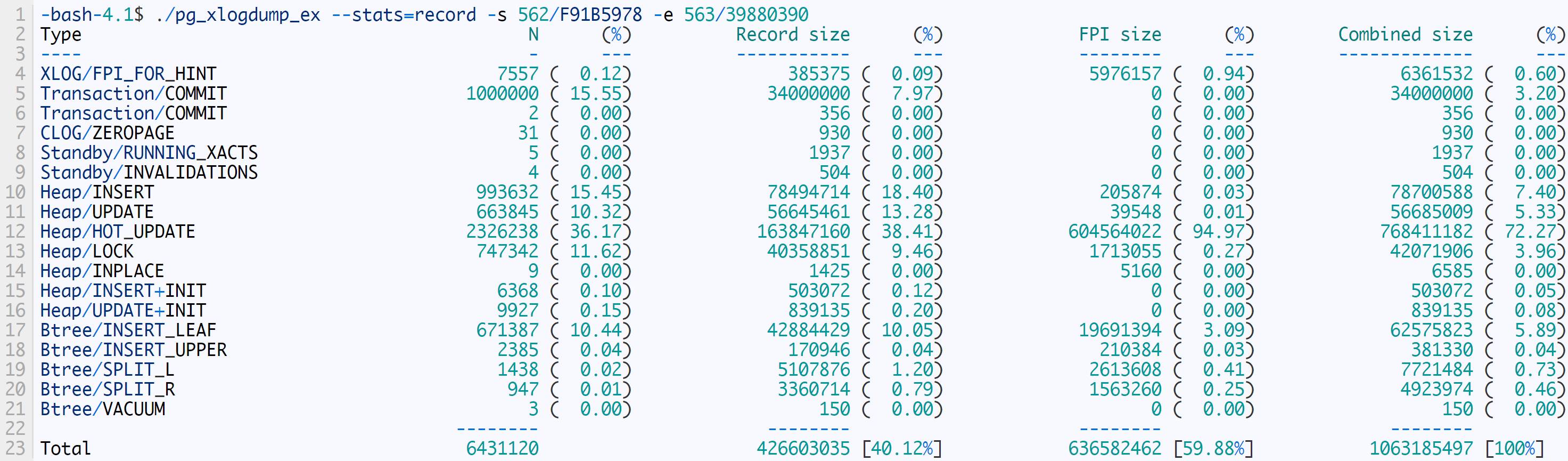
设置`wal_compression = on后,生成的WAL量从6413034966减少到1063185497。
优化结果汇总
仅仅调整wal_compression和fillfactor就削减了87%的WAL,这还没有算上延长checkpoint间隔带来的收益。
总结
PostgreSQL在未经优化的情况下,20倍甚至更高的WAL写放大是很常见的,适当的优化之后应该可以减少到3倍以下。引入SSL/SSH压缩或归档压缩等外部手段还可以进一步减少WAL的生成量。
如何判断是否需要优化WAL?
关于如何判断是否需要优化WAL,可以通过分析WAL,然后检查下面的条件,做一个粗略的判断:
FPI比例高于70%
HOT_UPDATE比例低于70%
以上仅仅是粗略的经验值,仅供参考。并且这个FPI比例可能不适用于低写负载的系统,低写负载的系统FPI比例一定非常高,但是,低写负载系统由于写操作少,因此FPI比例即使高一点也没太大影响。
优化WAL的副作用
前面用到了3种优化手段,如果设置不当,也会产生副作用,具体如下:
延长checkpoint时间间隔
导致crash恢复时间变长。crash恢复时需要回放的WAL日志量一般小于max_wal_size的一半,WAL回放速度(wal_compression=on时)一般是50MB/s~150MB/s之间。可以根据可容忍的最大crash恢复时间(有备机时,切备机可能比等待crash恢复更快),估算出允许的max_wal_size的最大值。调整fillfactor
过小的设置会浪费存储空间,这个不难理解。另外,对于频繁更新的表,即使把fillfactor设成100%,每个page里还是要有一部分空间被dead tuple占据,不会比设置一个合适的稍小的fillfactor更节省空间。设置wal_compression=on
需要额外占用CPU资源进行压缩,但根据实测的结果影响不大。
其他
去年Uber放出了一篇把PostgreSQL说得一无是处的文章《为什么Uber宣布从PostgreSQL切换到mysql?》给PostgreSQL带来了很大负面影响。Uber文章中提到了PG的几个问题,每一个都被描述成无法逾越的“巨坑”。但实际上这些问题中,除了“写放大”,其它几个问题要么是无关痛痒要么是随着PG的版本升级早就不存在了。至于“写放大”,也是有解的。Uber的文章里没有提到他们在优化WAL写入量上做过什么有益的尝试,并且他们使用的PostgreSQL 9.2也是不支持wal_compression的,因此推断他们PG数据库很可能一直运行在20倍以上WAL写放大的完全未优化状态下。
看完本文有收获?请转发分享给更多人
关注「数据库开发」,提升 DB 技能
以上是关于如何遏制 PostgreSQL WAL 的疯狂增长的主要内容,如果未能解决你的问题,请参考以下文章