微学堂PostgreSQL PITR 技术讲解
Posted ITPUB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微学堂PostgreSQL PITR 技术讲解相关的知识,希望对你有一定的参考价值。
李昊,山东瀚高基础软件股份有限公司产品测试与支持经理。日常主要负责PostgreSQL和HighGo Database产品相关测试及运维支持工作。
大家好,今天想跟大家分享的是postgresql数据库的PITR技术,主要是根据平日的使用,并结合了一些理论补充。
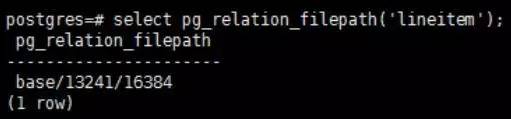
在介绍PITR技术之前,先对postgresql结构做下简单的说明,数据库服务器下的所有数据库是以ID进行标识,存放在初始化的data/base目录下,其实例与database是一对N的关系。同时,服务器下所有数据库的wal事务日志统一放在初始化的data/pg_xlog目录下,是不分库的,wal事务日志,大家可以理解为oracle中的online redo log,这个后面会有说明。因此,postgresql数据库无法分库分文件,进而进行一些类似oracle方面的精细的操作。
那么现在开始进入正题。PITR,Point-In-Time-Recovery,是postgresql数据库的增量备份恢复技术,类似于oracle的增量备份。pitr它的原理是利用:基础热备 + wal预写日志 + wal归档日志进行的备份恢复。结合刚刚的postgresql结构的说明,可以看出,PITR技术是作用于“服务器”级的,同时,postgresql中没有scn的概念,因此在进行PITR恢复时会将整个服务器,包括服务器的所有对象,恢复到指定时刻,而非某个具体的数据库对象。同样的,结合oracle中的完全与不完全恢复来说,在postgresql中,由于写wal与写归档是基于不同触发条件的进程,因此也会出现宕机时,wal未归档的情形,那么此时,就需要类似oracle的不完全恢复手段。
接下来,会逐步对wal事务日志、归档进行一些简单的说明,wal全称是write ahead log,是postgresql中的online redo log,是为了保证数据库中数据的一致性和事务的完整性而在PostgreSQL 7中引入的技术。它的中心思想是“先写日志后写数据”,即要保证对数据库文件的修改应放生在这些修改已经写入到日志之后,同时,在PostgreSQL 8.3以后又加入了WalWriter日志写进程,可以保证事务提交记录不是在提交时同步写入到磁盘,而是异步写入,这样就极大的减轻了I/O的压力。
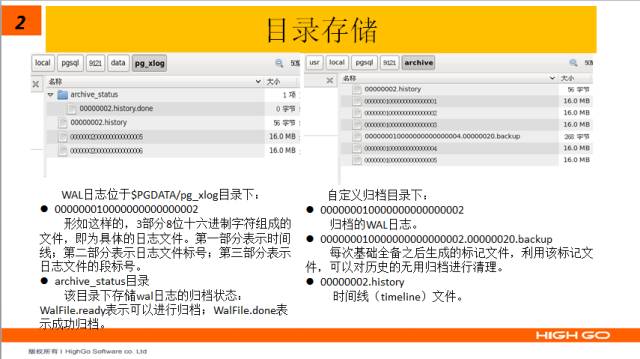
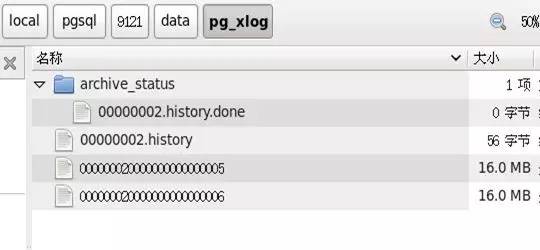
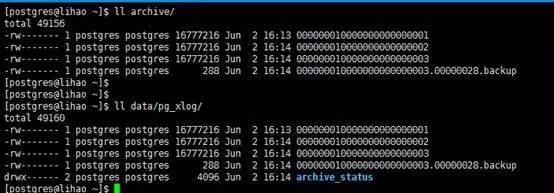
其中,pg_xlog目录就是wal的目录,它的上一级data目录就是初始化的服务器存储目录,在这个Pg_xlog目录下,大家可以看到一些类似于这样的文件:000000010000000000000002。
这种3部分8位十六进制字符组成的文件,即为具体的日志文件,其中,第一部分表示时间线 timeline,第二部分表示日志文件标号,第三部分表示日志文件的段标号。刚刚这个图片中的 .history文件,就是 timeline时间线文件,后面也会有说明,而这个目录下的archive_status目录,则存储wal日志的归档状态标记文件,.ready表示可以进行归档,.done则表示成功归档,同样的,类似于oracle,在postgresql中,当wal_buffer满了,或者有脏页需要交换时,会触发wal的写进程。
补充一下,在oracle中是手动commit,在postgresql中是自动commit。commit时,也会触发wal写,它的自动commit是指,不需要开启begin,输入命令,回车后,自动提交。当然,也可以手动开启begin事务,那么,接下来就对timeline文件(.history),及timeline进行一些说明。
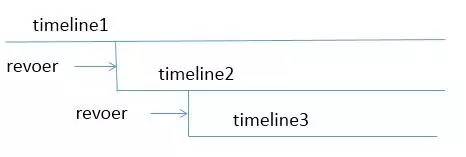
首先,说一下timeline,它在初始化完数据库之后,就标记为1,然后逐渐递增,当从归档中进行启动恢复时,会生成新的timeline,否则,会一直沿着原来的timeline走,如下图:
然后,当生成新的timeline时,就会在归档目录下,生成一个对应的时间线文件.history,这个文件内,以明文的形式记录:父时间线 | 分出时的日志文件 | 分出的时间。需要注意的是,history文件产生时,会立即进行归档,归档文件中会存在完成的时间线历史文件的序列,至于归档,在配置好数据库参数之后,其会自动进行归档。wal日志跟online redo log一样,其个数,也不是无限的,一般可以这么计算,(2+checkpoint_completion_target)*checkpoint_segment+1,缺省值计算为8.5,超过之后,也是会覆盖。上面计算公式中的两个参数,是数据库的配置参数,这里就不做说明了。
postgresql的归档,是自动进行归档,其是在data目录下的postgresql.conf文件中进行配置,如下:
archive_command = 'cp %p /usr/local/pgsql/archive/%f'
第三个参数就是归档命令,%p表示wal是的绝对路径+文件名,%f表示wal日志对应的归档文件命令,二者同名。配置完成之后,需要重启下数据库,而基础备份的过程如下:
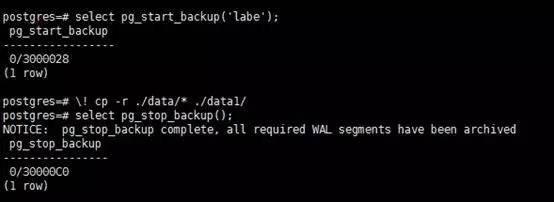
psql -c "select pg_start_backup('label');"
psql -c "select pg_stop_backup();"
psql是postgresql的客户端命令,类似与sqlplus,psql是postgresql的客户端命令,类似与sqlplus,两条select语句表示开启、关闭热备,其中的tar,就是进行备份,至此,postgresql的pitr备份,及一些说明就结束了,下面,结合使用,对完全、不完全恢复进行说明。
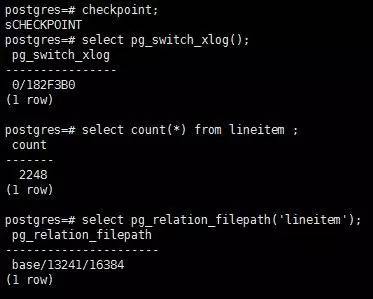
这是我自己的一个简单环境,安装及初始化在这就跳过了,直接进入主题,生成基础数据,创建lineitem表,手动checkpoint(写磁盘文件),并执行select pg_switch_xlog();切换下归档,调用insert脚本,预先插入2248条数据,再次checkpoint;switch_xlog,
如图:
此处进行基础备份,将data在线拷贝为data1,然后,查看此时的wal和归档。
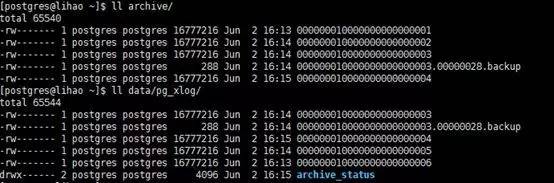
再次checkpoint;switch_xlog之后,wal比归档多两个。
将脏块刷入到wal了,然后,继续批量insert,任意时刻移除lineitem表的物理文件后中断insert。
并根据数据库日志,确认了再次执行的insert条数。
这里,我是先备份并清空了原日志之后,在继续进行的insert,
然后:
利用data1手动cp出data2,
利用现在的archive目录手动cp生成:archive1、archive2,并做了简单的配置。
之后,分别启动data1、data2并进行数据量验证,data1下:2248条(没有用到未归档的wal),进行了不完全恢复;data2下:5382条(利用了未归档的wal,2248+3134),进行了完全恢复。
其中,在恢复时,需要在data目录下,创建一个recovery.conf文件,主要写入:
restore_command = 'cp /home/postgres/archive/%f %p',这是转储命令。
recovery_target_time = ‘2016-06-02 12:12:12’,恢复到这个时间戳。
recovery_target_timeline = ‘2’,恢复到指定的timeline
recovery_target_timeline =
其中,target_time得是在timeline之前的时刻,之前做了次小实验,可以这么进行恢复。
A:关于pg_rewind,只是刚出来时使用了一下,不算是pitr, 个人认为它主要是根据checkpoint进行数据块比对, 然后当备库与主库不一致时, 进行比对同步的. 这是我的个人理解。
【微学堂】是由IT168打造的,面向广大IT人士的一档在线互动栏目。在这里,你能认识更多的朋友,分享更多的案例经验,学习更强的技术才能。
对系统运维、大数据、云计算、移动互联网……等IT领域有独特的见解~
E-mail:shixinlong@it168.com
以上是关于微学堂PostgreSQL PITR 技术讲解的主要内容,如果未能解决你的问题,请参考以下文章